

Литература к самостоятельной работе 2
Зуховицкий С.И., Авдеева Л.И. Линейное и выпуклое программирование. М: Наука, 1967. –460 с.
11.3. Разработка приложения “Статистический анализ данных”
Постановку задачи для этого приложения ограничим упрощенным статистическим анализом: вычислением средних значений признаков, стандартов (средне-квадратических отклонений от генерального среднего), матрицы коэффициентов корреляции и матрицы стандартов коэффициентов корреляции. Поясним эту задачу, обратившись к матрице на рис. 10.5. Теперь матрицу будем рассматривать не как таблицу коэффициентов, связывающих зависимые переменные y={Y1,…,YN} c независимыми переменными x={X1,…,XN} (см. предыдущую работу), а как таблицу объекты-свойства. Соответственно, в первом столбце листа Excel разместим идентификаторы объектов (например, их номера: 1 ,…, M), а в первой строке – идентификаторы свойств (например, X1 ,…, XN). Одна строка матрицы содержит значения свойств одного объекта, а один столбец – значения одного свойства для всех объектов.
Таблицы объекты-свойства часто применяются в различных предметных областях. Например, в геологии при поисках и разведке полезных ископаемых отбирают из массива горных пород M проб, а в каждой пробе химическими или физическими методами определяют содержания N компонентов (обычно M>N). По этим анализам судят о массиве горной породы. Аналогично тестируют продукцию металлургического комбината – выборочно отбирают образцы и подвергают их анализам на содержание железа, серы и других элементов. Статистически обработав результаты анализов образцов, судят о качестве целой партии продукции. Здесь важно понять, что в подобных ситуациях практически невозможно проанализировать весь массив горных пород или всю партию продукции - как говорят статистики, всю генеральную совокупность. Поэтому в таблицу объекты-свойства включают результаты анализов (измерений) для выборки из генеральной совокупности. По этой выборке находят средние значения Xjo каждого признака, характеризующие центр рассеяния значений признака и коэффициенты ковариации Sjk, характеризующие меру и форму рассеяния:
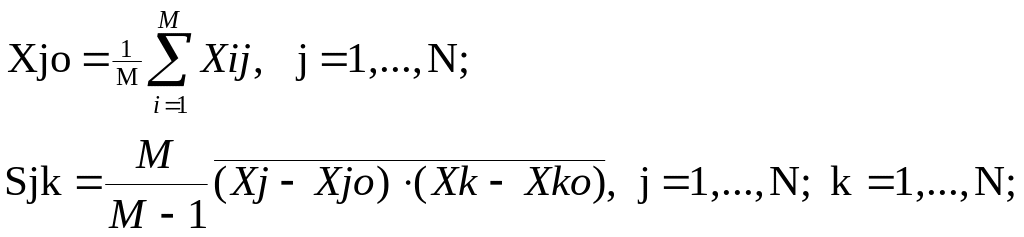
Коэффициент ковариации Sjk вычисляется так: берутся два столбца матрицы с номерами j и k , затем суммируются произведения отклонений i-ых элементов этих столбцов от своих средних, и накопленная сумма делится на M, полученное среднее значение произведения отклонений умножается на поправочный коэффициент M / (M-1). Этот коэффициент компенсирует занижение коэффициентов ковариации, которое произошло, т.к. вместо неизвестных генеральных средних в формуле использованы выборочные средние значения признаков.
Рассчитанную матрицу коэффициентов ковариации можно разместить на листе 2 книги Excel – так же, как на листе 1 размещена исходная матрица (см. рис. 10.5), только размерность ковариационной матрицы не M ∙ N , а N ∙ N , и идентификаторами строк и столбцов являются идентификаторы признаков (свойств) объектов. Средние значения надо разместить на листе 1 под соответствующими столбцами исходной матрицы, но пропустив одну строку. На листе 1 надо также разместить командную кнопку BTNSTAT с надписью (свойство Caption) Расчет статистик. В начало событийной процедуры BTNSTAT_Click надо включить определение M, N, копирование в массив CX идентификаторов признаков, а в двумерный массив A – матрицы (см. предыдущую работу и модуль, приведенный в подразделе 10.4 после рис. 10.5). После копирования данных в массивы, запрограммируйте вычисление средних значений признаков и матрицы ковариаций.
Диагональные элементы ковариационной матрицы называются дисперсиями. Корни квадратные из дисперсий Sjj называются стандартами sj, или средне-квадратическими отклонениями значений признаков от генеральных средних (от математических ожиданий значений признаков). Стандарты надо вычислить и разместить на листе Excel под средними значениями.
Часто между признаками наблюдаются связи: при переходе от объекта к объекту мы видим, что увеличение признака j , как правило, сопровождается увеличением признака k – это положительная корреляция. Если же при увеличении значения Xj значение Xk, как правило, уменьшается, то это корреляция отрицательная. Близость связи между двумя признаками j и k к линейной оценивается коэффициентом парной корреляции:
rjk = Sjk / (sj ∙ sk) , j=1,…, N, k=1,…, N.
Матрицу коэффициентов корреляции можно разместить на месте ковариационной матрицы, нормируя ее элементы на стандарты. Значения коэффициентов парной корреляции должны принадлежать интервалу [-1, 1 ].
Достоверность, или, как говорят статистики, значимость коэффициентов корреляции зависит от объема выборки. Если в выборку включить малое число проб, а рассеяние значений Xj и Xk велико, то коэффициент корреляции случайно может получиться большим или малым. Чтобы оценить значимость коэффициентов парной корреляции, вычисляют их стандарты:
![]() ,
j=1,…, N, k=1,…, N.
,
j=1,…, N, k=1,…, N.
Матрицу стандартов коэффициентов парной корреляции можно разместить на листе 3 книги Excel. С некоторым приближением о значимости коэффициентов корреляции судят так: если │ rjk │< s(rjk) , то корреляцию нельзя считать значимой.
При разработке рассматриваемого приложения наиболее трудным этапом является программирование вычисления коэффициента ковариации. Это вычисление целесообразно локализовать в функции
Function SJK ( j As Integer, k As Integer) As Double
К этой функции необходимо обратиться N∙N раз: цикл по j от 1 до N, а при каждом j цикл по k от 1 до N.
Методы статистического анализа данных полезно знать каждому специалисту. Эта работа знакомит с началами статистического анализа. Любознательные студенты могут, обратившись к литературе, расширить свои знания в этой области, а при желании – и само разработанное приложение, включив в него, например, вычисление коэффициентов асимметрии и эксцесса для каждого признака, коэффициентов уравнения регрессии, связывающего первый признак с остальными, и т.п.