

II.6.7. Построение ти по методу цепочек
Объем неиспользуемой памяти будет тем выше, чем больше информации хранится для каждого идентификатора. Этого недостатка можно избежать, если дополнить ТИ некоторой промежуточной хэш-таблицей. В ее ячейках храниться либо пустое значение, либо значение указателя на некоторую область памяти из основной ТИ. Тогда хэш-функция вычисляет адрес, по которому происходит обращение сначала к хэш-таблице, а потом через нее по найденному адресу — к самой ТИ. Если соответствующая ячейка ТИ пуста, то ячейка хэш-таблицы будет содержать пустое значение. Тогда вовсе не обязательно иметь в самой ТИ ячейку для каждого возможного значения хэш-функции, поэтому таблицу можно сделать динамической так, чтобы ее объем рос по мере заполнения. Такой подход позволяет получить 2 результа: во-первых, нет необходимости заполнять пустыми значениями ТИ — это можно сделать только для хэш-таблицы; во-вторых, каждому идентификатору будет соответствовать строго определенная ячейка в ТИ, т.е. в ней не будет пустых неиспользуемых ячеек. Пустые ячейки будут только в хэш-таблице, и объем неиспользуемой памяти не будет зависеть от объема информации, хранимой для каждого идентификатора. На основе такой схемы можно организовать ТИ с помощью хэш-функции .Метод называется метод цепочек. При этом методе для каждого элемента ТИ добавляется еще одно поле, в котором содержится ссылка на любой элемент таблицы. Первоначально это поле всегда пустое. Также необходимо иметь одну переменную, которая всегда указывает на свободную ячейку в ТИ. Первоначально она показывает на начало таблицы. При записи элементов в ТИ и их чтении используют соответствующий алгоритм.
На рисунке дано заполнение ТИ для примера, который уже был рассмотрен с использованием метода простейшего рехэширования
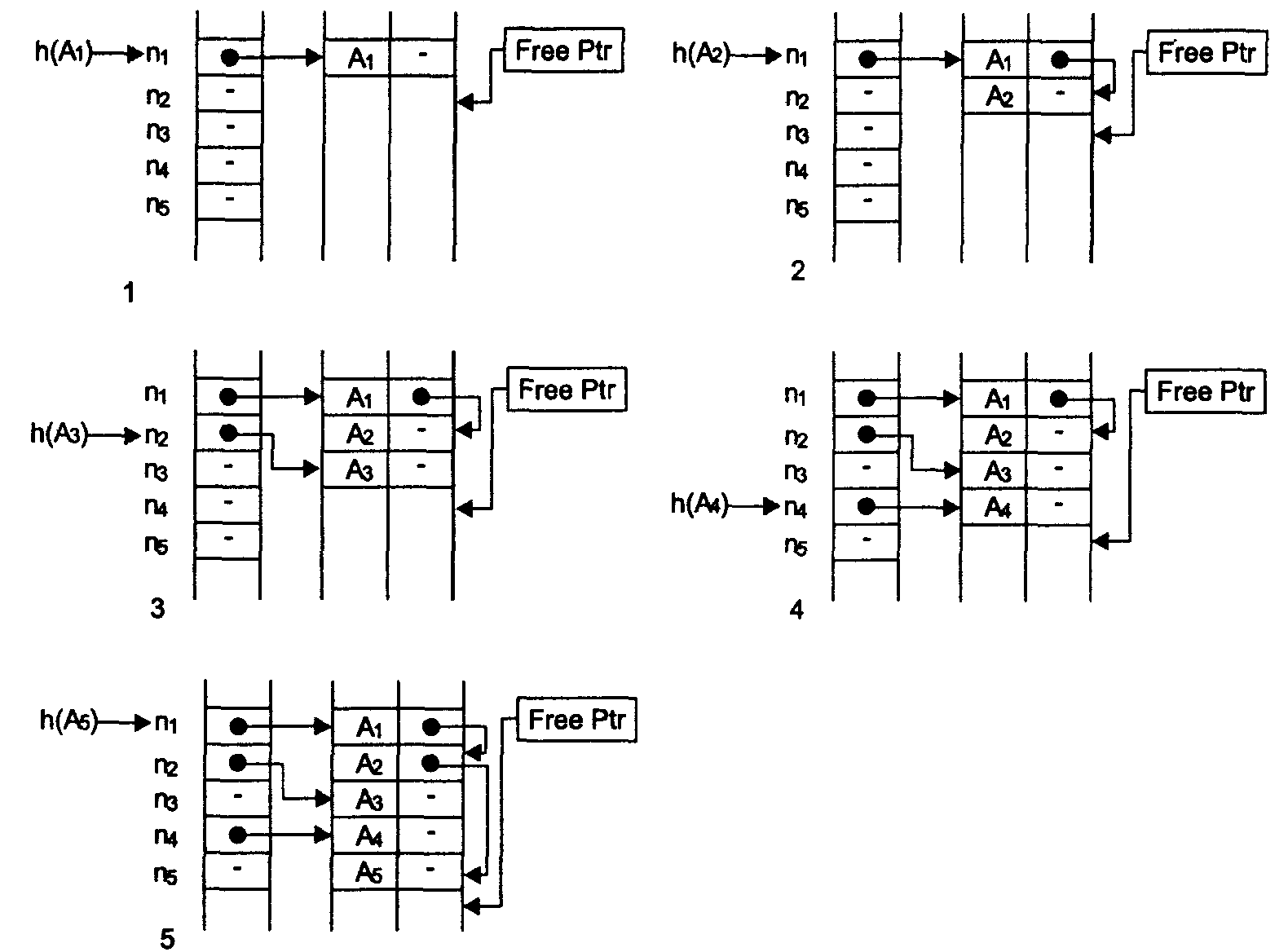
После размещения в таблице для поиска идентификатора A1 потребуется 1 сравнение, для А2 — 2 сравнения, для А3 — 1 сравнение, для А4 — 1 сравнение и для А5 — 3 сравнения.
Метод цепочек является очень эффективным средством организации ТИ. Среднее время размещения одного элемента и на поиск его в таблице зависит только от среднего числа коллизий, возникающих при вычислении хэш-функции. Метод экономно использует память, но требует организации работы с динамическими массивами данных
II.7. Лексические анализаторы
II.7.1. Назначение ла
Лексема (лексическая единица языка) — это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка.
Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и др. Состав возможных лексем для каждого конкретного языка является синтаксисом этого языка.
Лексический анализатор (или сканер ) — это часть компилятора, которая читает исходную программу и выделяет в ее тексте лексемы входного языка. Выходная информация передается для дальнейшей обработки компилятора. Есть причины, по которым в состав всех компиляторов включают ЛА.
1)Упрощается работа с текстом исходной программы на этапе синтаксического разбора. Сокращается объем обработанной информации, т.к. ЛА структурирует на поступ. на вход исходного текста программы и отбрасывает всю незначащую информацию.
2)Для выделения в тексте и разбора лексем можно применять простую эффективную и теоретически хорошо проработанную технику анализа, в то время, как на этапе СА конструкция исходного языка использует сложные алгоритмы разбора.
3)ЛА отделяет сложный по конструкции СА от работы с текстом исходной программы, структура которого может изменяться от версии входного языка.
При такой конструкции компилятора для перехода одной версии к другой нужно только перестроить простой ЛА.
ЛА исключает из текста исходной программы комментарии, незначащие пробелы, символы табуляции и перевода строки, а выделяет лексемы следующих типов: идентификаторы, строковый символьные числовые константы, ключевые служебные слова, знаки операций и разделителей. Результат работы ЛА – это перечень всех найденных в тексте исходной программы лексем, с учетом характеристик каждой лексемы. Этот перечень выполняется в виде таблиц, назыв. табл. лексем, в которой каждой лексеме соответствует уникальный условный код, зависящий от ее типа и дополнительной служебной информации. Кроме того, информация о некоторых лексемах, найденных в исходной программе, должна помещаться в ТИ. Таблица лексем (ТЛ) содержит весь текст исходной программы, обработанный ЛА. В нее входят все возможные типы лексем. Кроме того, любая лексема может встречаться в ней любое количество раз. ТИ содержит только определенные типы лексем. Это идентификаторы и константы. В нее не попадают такие лексемы, как ключевые служебные слова входного языка, знаки операций и разделители. Кроме того, каждая лексема может встречаться в ТИ только 1 раз. Лексемы в ТЛ обязательно располагаются в том же порядке, как в исходной программе, а в ТИ они располагаются в любом порядке, так, чтобы обеспечить удобство поиска.