

4.8 Lr(k)-аналізатори
У назві LR(k) символ L означає, що розбір здійснюється зліва направо, R – що будується праве породження у оберненому порядку, k – число вхідних символів, які можуть бути переглянуті для прийняття рішення про спосіб проведення розбору. Коли k опущено, мають на увазі 1.
LR-аналіз привабливий з кількох причин.
LR-аналізатори можуть бути побудовані для розпізнавання практично всіх конструкцій мов програмування.
Метод LR-аналізу – найбільш загальний метод ПЗ-аналізу без відкоту, який, крім того, може бути реалізований досить ефективно.
Найбільш відомі три методи побудови таблиць LR-аналізу для граматик. Перший метод, простий LR (simple LR, SLR), є найбільш легким в реалізації, але найменш потужним з них. Він не може побудувати таблицю для розбору деяких граматик, які успішно обробляються іншими методами. Другий метод, канонічний LR, – найбільш потужний, але він потребує найбільших ресурсів. Третій метод – метод з попереднім переглядом (lookahead LR, LALR) за потужністю і споживаними ресурсами займає проміжне положення. Метод LALR працює з більшістю граматик і може бути ефективно реалізованим.
Схематично структура LR-аналізатора зображена на рис.4.5.
LR-аналізатор складається з входу, виходу, стека, керуючої програми і таблиці синтаксичного аналізу, що складається з двох частин – дії (action) і переходу (goto). Керуюча програма одна й та сама для всіх аналізаторів, різні аналізатори розрізняються таблицями аналізу. Програма синтаксичного аналізу читає символи з вхідного буфера по одному за крок.
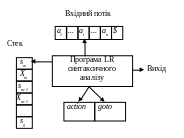
Рисунок 4.5 - Структура LR-аналізатора
У процесі аналізу використовується стек, у якому зберігаються рядки вигляду s0X1s1X2s2...Xmsm (sm знаходиться на вершині стека). Кожен Xi є символом граматики (термінальним або нетермінальним), а si – символ, який називається станом. Кожен символ стану виражає інформацію, що утримується в стеку нижче його, а комбінація символа стану на вершині стека і поточного вхідного символа використовується для індексації таблиці аналізу і визначає рішення про перенесення або згортання. При реалізації символи граматики не обов'язково повинні з’являтися в стеку. Однак їх використання зручне для спрощення розуміння поводження LR-аналізатора.
Таблиця аналізу складається з двох частин: дій (action) і переходів (goto). Керуюча програма синтаксичного аналізатора функціонує таким чином. Вона визначає sm, поточний стан на вершині стека і поточний вхідний символ ai. Потім програма звертається до action[sm,ai], елемента таблиці дій синтаксичного аналізу, який може мати одне з чотирьох значень:
перенесення s, де s – стан;
згортання у відповідності з продукцією A →β;
допуск;
помилку.
Функція goto одержує як аргументи стан і символ граматики і повертає новий стан.
Конфігурація LR аналізатора – це пара, перший компонент якої – вміст стека, а другий – непереглянута частина вхідного потоку (s0X1s1X2s2...Xmsm, aiai+1 ... an$). Ця конфігурація відповідає правосентенціальній формі X1X2...Xmaiai+1 ... an.
Префікси правосентенціальних форм, що можуть з’явитися у стеку аналізатора, називаються активними префіксами.
Активний префікс – це такий префікс правосентенціальної форми, що не переходить праву границю основи цієї форми.
Черговий крок синтаксичного аналізатора визначається поточним вхідним символом ai і символом стану на вершині стека sm відповідно до значення елемента таблиці дій action[sm,ai]. Конфігурації, що виходять після кожного з чотирьох типів дій, такі.
1 Якщо action[sm,ai] = “перенесення s”, то синтаксичний аналізатор виконує перенесення, переходячи у конфігурацію (s0X1s1X2s2...Xmsmais, ai+1 ... an$). Синтаксичний аналізатор переносить у стек поточний вхідний символ ai і черговий стан s, який визначається значенням action[sm,ai]; поточним вхідним станом стає ai+1.
2 Якщо action[sm,ai] = “згортання A→β”, синтаксичний аналізатор виконує згортання, переходячи у конфігурацію (s0X1s1X2s2...Xm-rsm-rAs, ai+1 ... an$), де s=goto[sm-r,A], а r – довжина β, правої частини продукції. Тут синтаксичний аналізатор спочатку видаляє із стека 2r символів (r символів стану і r символів граматики), так що на вершині виявляється стан sm-r. Потім аналізатор поміщає в стек A (ліву частину продукції) і s – вміст елемента таблиці goto[sm-r,A]. Поточний вхідний символ не змінюється. Для LR-аналізаторів послідовність символів Xm-r+1 ... Xm , що видаляються із стека, завжди відповідає β – правій частині продукції згортання.
3 Якщо action[sm, ai] = “допуск”, то синтаксичний аналіз завершено.
4 Якщо action[sm, ai] = “помилка”, аналізатор знайшов помилку і виконуються дії з діагностицки і відновлення.
Нижче наведено алгоритм LR-аналізу. Усі LR-аналізатори ведуть себе однаково. Різниця між ними полягає у різному змісті таблиць дій і переходів.
Алгоритм 4.5 Алгоритм LR-аналізу.
Установити покажчик ip на перший символ w$
repeat forever
begin
Нехай s – стан на вершині стека, а a – символ,
на який вказує ip;
if action [s, a] = “перенесення s' ” then begin
Помістити у стек a і потім s'
на вершину стека;
перемістити ip до наступного
вхідного символа.
end
else if
action [s, a] = “згортання A →β ” then begin
видалити зі стека 2*| β | символів;
нехай s' - стан на вершині стека;
помістити у стек A, а потім
стан goto [s', A];
вивести продукцію A →β.
end
else if action [s, a] = “допуск ” then
return
else error
end
Спочатку в стеку поміщено початковий стан s0, а у вхідному буфері – w$. Потім аналізатор виконує наведену нижче програму доти, поки не буде досягнуте успішне завершення або знайдена помилка.
Візьмемо граматику арифметичних виразів з бінарними операціями “+” і “*”:
(1) E → E + T , 4) T → F ,
(2) E → T , 5) E → ( E ) , (4.3)
(3) T → T * F, (6) E → id .
Функції синтаксичного аналізу action і goto показані у табл. 4.5.
У таблиці використані такі коди дій:
1) si означає перенесення в i–й стан на вершині стека;
2) rj означає згортання у відповідності з продукцією номер j;
3) acc означає допуск вхідного рядка;
4) порожній елемент означає помилку.
Значення goto[s, a] для термінала a шукається у полі action, зв'язаному з перенесенням для вхідного символа a в стані s. Поле goto дає значення goto[s, A] для нетерміналів A.
Таблиця 4.5
Стан |
action |
goto |
id + * ( ) $ |
E T F |
|
0 1 2 3 4 5 6 7 8 9 10 11 |
s5 s4 s6 acc r2 s7 r2 r2 r4 r4 r4 r4 s5 s4 r6 r6 r6 r6 s5 s4 s5 s4 s6 s11 r1 s7 r1 r1 r3 r3 r3 r3 r5 r5 r5 r5 |
1 2 3
8 2 3
9 3 10 |
Для вхідного рядка id+id*id послідовність станів стека і вхідного буфера наведена у табл. 4.6.
Наприклад, у першому рядку LR-аналізатор перебуває у стані 0 і читає перший вхідний символ id. Дія s5 у нульовому рядку і стовпці id таблиці action означає перенесення і занесення на вершину стека стану 5. У другому рядку виконується занесення в стек першого символа id і символа стану s5 та видалення id з вхідного потоку.
Після цього поточним вхідним символом стає “*”. Дія для стану s5 і вхідного символа “*” – r6, тобто згортання у відповідності з продукцією F→ id. З вершини стека при цьому знімаються два символи (один символ стану й один символ граматики), і на вершині стека з’являється стан 0. Тепер аналізується нульовий стан. Оскільки goto[0,F] дорівнює s3, у стек заносяться F і 3. Тепер маємо конфігурацію, яка відповідає третьому рядкові. Інші кроки визначаються аналогічно.
Таблиця 4.6
Стек |
Вхідний потік |
Дія |
|
id*id+id $ *id+id $ *id+id $ *id+id $ id+id $ +id $ +id $ +id $ +id $ id $ $ $ $ $ |
Перенесення Згортання за F→ id Згортання за T→ F Перенесення Перенесення Згортання за F→ id Згортання за T→ T*F Згортання за E→ T Перенесення Перенесення Згортання за F→ id Згортання за T→ F Згортання за E→ E+T Допуск |
4.9 LR-граматики
Граматики, для яких можна побудувати таблицю LR-розбору, називаються LR-граматиками. Існують контекстовільні граматики, що не є LR-граматиками, однак практично для опису мов типових конструкцій мов їх можна уникнути.
Щоб граматика була LR-граматикою, аналізатор, що працює зліва направо по типу перенесення-згортання, повинен уміти розпізнавати основи на вершині стека. LR-аналізатор не повинен сканувати весь стек, щоб розпізнати появу основи на вершині стека. Більше того, символ стану на вершині стека містить всю необхідну інформацію. Але якщо можна розпізнати основу, знаючи тільки символи граматики в стеку, то існує скінченний автомат, що може, читаючи символи граматики в стеку зверху вниз, визначити цю основу. Функцією переходів цього скінченного автомата є таблиця переходів LR-аналізатора. Щоб не переглядати стек на кожному кроці аналізу, на вершині стека завжди зберігається той стан, у якому повинен виявитися цей скінченний автомат після того, як він прочитав символи граматики в стеку від дна до вершини.
Для вибору рішення про перенесення або згортання аналізатор переглядає чергові k вхідних символів. Практичний інтерес становлять випадки k=0 і k=1. Наприклад, у колонках action табл. 4.5 використовується тільки один символ. Граматика, для розбору якої LR- аналізатору потрібен перегляд до k вхідних символів на кожному кроці, називається LR(k)-граматикою.
Основна різниця між LL- і LR-граматиками полягає у наступному. Щоб граматика була LR(k), необхідно вміти розпізнавати появу правої частини продукції, бачачи усе, що породжено з цієї правої частини, а також k вхідних символів. Ця вимога істотно менш строга, ніж вимога для LL(k)-граматики, коли необхідно визначити застосовну продукцію, бачачи тільки перші k символів, виведених з її правої частини.