

0. Общее описание
Важным элементом модуля синтеза речевого сигнала является алгоритм PSOLA (Pitch Synchronous OverLap Add – алгоритм синхронного накладывающегося окна с равномерным шагом), реализующий модификацию речевого сигнала во времени, при использовании готовой дифонной базы данных. Для выражения интонации в реальности люди динамически меняют период частоты основного тона: грубо говоря – скорость речи. Например, если пользователь хочет увеличить продолжительность синтезируемого текста, специфические периоды (отмеченные) дублируются в новом списке. С другой стороны, если он хочет сократить продолжительность синтезируемого текста, специфические периоды в новом списке пропускаются.
Дифо́н – (лингв.) сегмент речи между серединами соседних фонем
Синтез,
основанный на TD-PSOLA алгоритме, реализуется
склейкой фонем, выделенных из человеческого
речевого сигнала, разделенного на
сегменты, названные дифонами. Мы в
состоянии достигнуть синтезируемой
речи, связывая эти сегменты. Кроме того,
алгоритм позволяет, изменить скорость
и продолжительность речи. Для периодических
сигналов мы в состоянии изменить частоту,
изменяя расстояние между периодами, и
продолжительность, добавляя или опуская
некоторых из них. Для непериодических
сигналов мы только в состоянии изменить
продолжительность специфических частей
сигнала. Если бесконечный периодический
сигнал, мы в состоянии сдвинуть на период
от оригинального T0 до необходимого
 ,
суммируя оконные данные
,
суммируя оконные данные
 ,
порожденный из
,
порожденный из
 сигнала.
сигнала.


Образцы
отличаются от ноля только на интервале,
зависящем от F – фактора восстановления,
определенного как отношение размера
окна
 анализа к шагу периода
анализа к шагу периода
 .
.

Практически,
мы выбираем
 ,
когда спектр сигнала
приближается к спектру
,
когда спектр сигнала
приближается к спектру
 .
Тогда процесс связи изменяет шаг, не
затрагивая частоты формант. Использование
различного фактора восстановления
вызывает сильную деградацию синтезируемой
речи, например бульканье или эффект
металлического голоса.
.
Тогда процесс связи изменяет шаг, не
затрагивая частоты формант. Использование
различного фактора восстановления
вызывает сильную деградацию синтезируемой
речи, например бульканье или эффект
металлического голоса.
Входные
параметры алгоритмов - отметки времени
для синтезируемого дифона, тип окна
анализа, и коэффициент для относительного
изменения шага. В течение каждого периода
для дифона
 ищется максимальная ценность амплитуды,
после чего отмечается соответствующее
время
ищется максимальная ценность амплитуды,
после чего отмечается соответствующее
время
 сегмент в интервале времени
.
Длина устанавливается равной
сегмент в интервале времени
.
Длина устанавливается равной
 ,
где
,
где
 – коэффициент перекрытия окон в
промежутке от 0 до 1. Далее из полученых
сегментов сигнала создаются Hann-окна,
причем неналожившаяся часть сегмента
отправляется в output,
а наложившаяся часть сегмента входит
в новый цикл, где она суммируется с
соответствующей частью следующего
сегмента и так же помещается в output.
– коэффициент перекрытия окон в
промежутке от 0 до 1. Далее из полученых
сегментов сигнала создаются Hann-окна,
причем неналожившаяся часть сегмента
отправляется в output,
а наложившаяся часть сегмента входит
в новый цикл, где она суммируется с
соответствующей частью следующего
сегмента и так же помещается в output.

Hann-окна слева, соответствующие сегментам сигнала (справа)
Поскольку
длина извлеченных сегментов
 ,
то необходимо, использовать k-кратное
наложение, чтобы достигнуть оригинальной
продолжительности речи. Использование
большего наложения обеспечивает
увеличение шага. С другой стороны,
меньшее наложение вызывает уменьшение
шага.
,
то необходимо, использовать k-кратное
наложение, чтобы достигнуть оригинальной
продолжительности речи. Использование
большего наложения обеспечивает
увеличение шага. С другой стороны,
меньшее наложение вызывает уменьшение
шага.
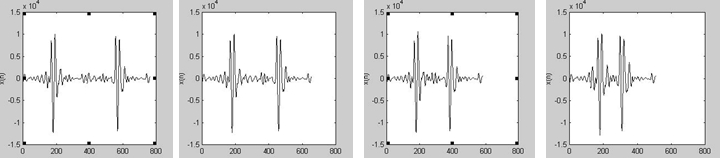
Исходный сигнал
(слева) и, соответственно (2-4, слева на
право), сжатые с наложение
 ,
,
 и
и
