

Ядро и подсистемы памяти Pentium
 Системная шина
Системная шина
Рис.4.10.
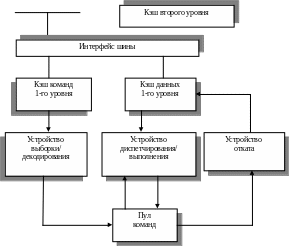
Процессор Pentium II построен на основе семи базовых модулей (рис. 4.10) — Fetch/Decode Unit (модуль загрузки/декодирования инструкций), Dispatch/Execute Unit (модуль диспетчеризации/исполнения инструкций), Retire Unit (модуль завершения и удаления инструкций). Instruction Pool (пул инструкций, его также называют Reorder Buffer — буфер переупорядочивания инструкций). Bus Interface Unit (модуль внешнего интерфейса), LI ICache (L1-кэш для инструкций) и LI DCache (L1-кэш для данных).
Fetch/Decode Unit предназначен для приема входного потока инструкций исполняемой программы, поступающего из L1-кэша инструкций, и их последующего декодирования в поток микроопераций (рис. 4.11).
Этот модуль работает следующим образом. Прежде всего, блок Next_IP вычисляет индекс (порядковый номер) инструкции, содержащейся в L1-кэше инструкций, которая должна быть обработана следующей — то есть извлечена из L1-кэша инструкций и передана для последующего декодирования.
Индекс этой инструкции вычисляется блоком Next_IP на основе поступающей в него информации о прерываниях, которые были переданы в процессор для обработки, возможных предсказанных переходах (предсказание выполняется блоком Branch Target Buffer), и сообщениях о неправильно предсказанных переходах (branch-misprediction), которые поступают от целочисленных вычислительных ресурсов, расположенных в модуле Dispatch/Execute Unit. После вычисления индекса следующей обрабатываемой инструкции Li-кэш инструкций извлекает две строки кэшированных данных (cache line) — ту, которая соответствует вычисленному индексу, и следующую за ней, — а затем передает для декодирования извлеченные 16 байт, которые содержат IA-инструкции (Intel Architecture). Начало и конец IA-инструкций маркируются.
Далее маркированный поток байт обрабатывается сразу тремя параллельно работающими декодерами, которые отыскивают в нем IA-инструкции. Каждый декодер преобразует найденную IA-инструкцию в набор триадных микроопераций (uops) — триадных в том смысле, что микрооперация проводится над двумя исходными логическими операндами, а в результате ее выполнения получается только один логический результат. Микрооперация — это примитивная инструкция, которая может быть выполнена одним из вычислительных ресурсов, расположенных в модуле Dispatch/Execute Unit.
Из трех декодеров два — простые, которые могут преобразовывать только IA-инструкций, требующие выполнения одной микрооперации, а третий декодер — более совершенный; он может преобразовывать IA-инструкции, требующие выполнения от одной до четырех микроопераций. Таким образом, за один такт работы процессора все три декодера могут в сумме сгенерировать максимум шесть микроопераций. Для преобразования еще более сложных IA-инструкций используется микрокод, который содержится в блоке Microcode Instruction Sequencer и представляет собой набор предварительно запрограммированных последовательностей обычных микроопераций.