

Кому выгодны облачные вычисления?
http://cloud.cnews.ru/
пониманию облачных вычислений, которое предложено исследовательской группой Университета Калифорнии в Беркли. В соответствии с этим пониманием, облачные вычисления представляют собой сочетание подходов Software as a Service (SaaS) и общедоступных вычислений (utility computing). При этом исследователи из Беркли сознательно не говорят о так называемых "приватных облаках", которые в их модели к облачным вычислениям не относятся.
Владельцы крупных дата-центров именно в силу масштаба своих площадок (насчитывающих десятки тысяч серверов) в состоянии добиться специфических преимуществ, которые недоступны держателям серверных площадок малого (до 100 серверов) и среднего (порядка 1000 серверов) размера.
Экономия за счет масштаба: сопоставление крупных и средних цод
Статья затрат |
Стоимость для среднего ЦОД |
Стоимость для крупного ЦОД |
Коэффициент экономии |
|
Сетевая инфраструктура |
$95 за Мбит/с в месяц |
$13 за Мбит/с в месяц |
7,1 |
|
Хранение |
$2,20 за ГБ/с в месяц |
$0,40 за ГБ/с в месяц |
5,7 |
|
Администрирование |
140 серверов на администратора |
> 1000 серверов на администратора |
7.1 |
|
Источник: UC Berkeley, 2009
Вторая причина, по которой крупные площадки оказываются экономически более эффективными, связана с тем, что они в гораздо меньшей степени страдают от неравномерной нагрузки, вызванной суточным, годовым и отраслевым дисбалансом.
учитывая высокий входной порог вхождения (построение крупного ЦОД в США на 50 000 серверов требует около $200 млн), совершенной конкуренции на этом рынке ожидать не приходится
облачные вычисления позволяют компаниям полностью избавиться от расходов и рисков, связанных с эксплуатацией собственных серверов. В случае, если компания решит свернуть ИТ-проект или же нагрузка на серверы снизится благодаря оптимизации ПО, "лишнее" оборудование не повиснет на компании мертвым грузом – высвободившиеся ресурсы просто вернутся арендатору. Разумеется, такая возможность наиболее удобна в пилотных внедрениях и при разработке, где нагрузка на ресурсы наименее предсказуема, а долгосрочная судьба проектов – наиболее туманна. Однако убедительность аргумента о CAPEX/OPEX существенно снижается для промышленных систем, которые существенно более предсказуемы и которые, как правило, составляют основную долю в ИТ-затратах компаний.
Можно сделать вывод, что облачные вычисления наиболее выгодны пользователям в случае рискованных ИТ-проектов, создаваемых с нуля: в этом случае компания не несет расходов, связанных с миграцией уже существующих ИТ-решений и существенно снижает риски, связанные с непредсказуемостью судьбы проектов. Кроме того, использование облаков позволяет избавиться от рисков, связанных с невозможностью заранее определить степень популярности вновь создаваемых ИТ-проектов: даже если сервис произведет фурор и обеспечит приток из сотен тысяч пользователей в день (который через несколько суток может упасть до десятка тысяч), то облачный провайдер вполне сможет справиться с такой нагрузкой. Для расчета выгодности использования облачных вычислений исследователи из Беркли предложили простую формулу:
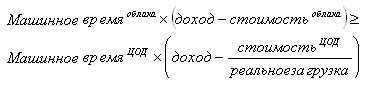
Согласно этой формуле, определяющим фактором при принятии решения о выгодности использования облаков является загрузка корпоративного ЦОД: если она приближается к единице, то использование облаков становится невыгодным. И напротив, если реальная нагрузка существенно меньше единицы (что часто происходит в случае сервисов с непредсказуемой нагрузкой), то предпочтительным становится использование облачных вычислений.
Рост "облаков" требует пересмотра законов
Юридические вопросы, возникающие при использовании сервисов SaaS/PaaS/IaaS, очень "неудобны" с точки зрения существующего законодательства: каковы обязательства поставщика SaaS по отношению к пользовательским данным? Отличаются ли они от обязательств поставщика IaaS, который не осуществляет обработку данных, а просто предоставляют вычислительную площадку? Каковы могут быть юридические последствия в том случае, если поставщики SaaS/PaaS/IaaS-услуг находятся в других юрисдикциях? Какие права правохранительные органы имеют в отношении данных, принадлежащих пользователям из других стран? И напротив – насколько пользователи свободны выносить свои данные за пределы своего государства?
стало решение Верховного суда Великобритании (2010, ноябрь) о том, что лицо, опубликовавшее информацию в интернете, несет ответственность за соблюдение авторско-правового законодательства в отношении этой информации только в той стране, где физически расположены серверы.
Удаленный вызов процедур. Организация связи между клиентом и удаленной процедурой.
С точки зрения разработчика программного обеспечения, перспективным является подход, когда используется прикладной программный интерфейс высокого уровня, изолирующий программу от специфики сетевого взаимодействия. В данном разделе мы рассмотрим один из таких подходов - удаленный вызов процедур (Remote Procedure Call, RFC). На его базе, в частности, разработана файловая система NFS и технология Microsoft - СОМ.
Удаленный вызов процедуры включает следующие шаги.
1. Программа-клиент производит локальный вызов процедуры, называемой заглушкой (stub). При этом клиенту "кажется", что, вызывая заглушку, он производит собственно вызов процедуры-сервера: клиент передает заглушке необходимые параметры, а она возвращает результат. Однако задача заглушки — принять аргументы, предназначаемые удаленной процедуре, возможно, преобразовать их в некий стандартный формат и сформировать сетевой запрос. Упаковка аргументов и создание сетевого запроса называется сборкой (marshalling).
2. Сетевой запрос пересылается по сети на удаленную систему. Для этого в заглушке используются соответствующие вызовы. При этом могут быть использованы различные транспортные протоколы, причем не только семейства TCP/IP.
3, На удаленном хосте все происходит в обратном порядке. Заглушка сервера ожидает запрос и при получении извлекает аргументы вызова процедуры. Извлечение может включать необходимые преобразования (например, изменения порядка расположения байтов).
4. Заглушка выполняет вызов настоящей процедуры-сервера, которой адресован запрос клиента, передавая ей полученные по сети аргументы.
5. После выполнения процедуры управление возвращается в заглушку сервера. Как и заглушка клиента, заглушка сервера преобразует возвращенные процедурой значения, формируя сообщение-отклик, который передается по сети системе, от которой пришел запрос.
6. Операционная система передает полученное сообщение заглушке клиента, которая, после необходимого преобразования, передает значения (являющиеся значениями, возвращенными удаленной процедурой) клиенту, воспринимающему это как нормальный возврат из процедуры.
Клиент вызывает удаленную процедуру так же, как он вызывал бы локальную. То же самое можно сказать и о сервере: заглушка сервера стандартным образом вызывает локальную процедуру и получает от нее возвращаемые значения. Клиент воспринимает заглушку как вызываемую процедуру-сервер, а сервер принимает собственную заглушку за клиента.
Заглушки составляют ядро системы RPC, отвечая за все аспекты формирования и передачи сообщений между клиентом и удаленным сервером. Преимущества такого подхода: и клиент и сервер не зависят от сетевой реализации, оба они работают в рамках некой распределенной виртуальной машины, и вызовы процедур имеют стандартный интерфейс.
Благодаря такому подходу, достигается независимость основных компонентов распределенного приложения (клиента и сервера) не только от сетевой реализации, но и от типа операционных систем, и от языка программирования.
Удаленный вызов процедур. Особенности вызова удаленной процедуры клиентом. Общая схема программы, работающей по протоколу RPC.
Передача параметров
Заглушка клиента размещает значение параметра в сетевом запросе, возможно, выполняя преобразования к стандартному виду (например, изменяя порядок следования байтов). Клиенты RPC могут передавать параметры только по значению, хотя это, безусловно, накладывает серьезные ограничения. Более сложные среды распределенного программирования (например, CORBA) лишены подобных ограничений и обладают рядом дополнительных возможностей.
Связывание (binding)
Прежде чем клиент сможет вызвать удаленную процедуру, необходимо связать его с удаленной системой, располагающей требуемым сервером. Таким образом, задача связывания распадается на две:
нахождение удаленного хоста с требуемым сервером;
нахождение требуемого серверного процесса на данном хосте.
Для нахождения хоста могут использоваться различные подходы. Возможный вариант — создание централизованного справочника, в котором хосты анонсируют свои серверы, и где клиент при желании может выбрать подходящие для него хост и адрес процедуры.
Обычно несколько функционально сходных процедур реализуются в одном программном модуле, который при запуске становится сервером этих процедур, и который идентифицируется номером программы. Каждая процедура RPC однозначно определяется номером программы и номером процедуры. Каждой программе также присваивается номер версии, так что при внесении в программу незначительных изменений (например, при добавлении процедуры) отсутствует необходимость менять ее номер. Таким образом, когда клиент хочет вызвать удаленную процедуру, ему необходимо знать номера программы, версии и процедуры, предоставляющей требуемый сервис.
Для передачи запроса клиенту также необходимо знать сетевой адрес хоста и номер порта, связанный с программой-сервером, обеспечивающей требуемые процедуры. Для этого используется демон portmap (в некоторых системах он называется rpcbind). Демон запускается на хосте, который предоставляет сервис удаленных процедур, и использует общеизвестный номер порта. При инициализации процесса-сервера он регистрирует в portmap свои процедуры и номера портов. Теперь, когда клиенту требуется знать номер порта для вызова конкретной процедуры, он посылает запрос на сервер portmap.
Вызов
При вызове удаленной процедуры невозможно установить, когда конкретно будет выполняться процедура, будет ли она выполнена вообще, а если будет, то какое число раз. Например, если запрос будет получен удаленной системой после аварийного завершения программы сервера, процедура не будет выполнена вообще. Если клиент при неполучении отклика после определенного промежутка времени (тайм-аута) повторно посылает запрос, то может создаться ситуация, когда отклик уже передается по сети, а повторный запрос вновь принимается на обработку удаленной процедурой. В этом случае процедура будет выполнена несколько раз.
Таким образом, количество выполнений удаленной процедуры может быть следующим.
Один и только один раз. Данного поведения (в некоторых случаях наиболее желательного) трудно требовать ввиду возможных аварий сервера.
Максимум раз. Это означает, что процедура либо вообще не была выполнена, либо была выполнена только один раз. Подобное утверждение можно сделать при получении ошибки вместо нормального отклика.
Хотя бы раз. Процедура наверняка была выполнена один раз, но возможно и больше. Для нормальной работы в такой ситуации удаленная процедура должна быть такой, чтобы ее многократное выполнение не вызывало накапливающихся изменений. Например, чтение файла в этой ситуации проходит, а добавление текста в файл — нет.
Представление данных
В большинстве реализаций RPC используются стандартные виды представления данных, к которым должны быть преобразованы все значения, передаваемые в запросах и откликах.
Например, формат представления данных в RPC фирмы Sun Microsystems следующий:
Порядок следования байтов Старший — последний
Представление значений с плавающей точкой IEEE
Представление символа ASCII
Протоколы
RPC занимает промежуточное место между уровнем приложения и транспортным уровнем. Этому положению соответствуют уровни представления и сеанса. Таким образом, RPC теоретически независим от сетевых протоколов транспортного уровня.
Сообщения передаются, как правило, с использованием протоколов TCP или UDP. Выбор того или иного протокола зависит от требований приложения. Выбор протокола UDP оправдан для приложений, обладающих следующими характеристиками.
Вызываемые процедуры не накапливают изменения.
Размер передаваемых аргументов и возвращаемого результата меньше размера пакета UDP — 8 Кбайт.
Сервер обеспечивает работу с несколькими сотнями клиентов. Поскольку при работе с протоколами TCP сервер вынужден поддерживать соединение с каждым из активных клиентов, это занимает значительную часть его ресурсов. Протокол UDP в этом отношении является менее ресурсоемким.
TCP обеспечивает эффективную работу приложений со следующими характеристиками.
Приложению требуется надежный протокол передачи.
Вызываемые процедуры накапливают изменения.
Размер аргументов или возвращаемого результата превышает 8 Кбайт.
Выбор протокола обычно остается за клиентом, и система по-разному организует формирование и передачу сообщений. Так, при использовании протокола TCP, для которого передаваемые данные представляют собой поток байтов, необходимо отделять сообщения друг от друга. Для этого, например, применяется протокол маркировки записей, описанный в RFC1057 "RPC: Remote Procedure Call Protocol specification version 2", при котором в начале каждого сообщения помещается 32-разрядное целое число, определяющее размер сообщения в байтах.
По-разному обстоит дело и с особенностями вызова. Например, если RPC выполняется с использованием ненадежного транспортного протокола (UDP), система выполняет повторную передачу сообщения через короткие промежутки времени (тайм-ауты). Если приложение-клиент не получает отклик, то с уверенностью можно сказать, что процедура была выполнена ноль или большее число раз. Если отклик был получен, приложение может сделать вывод, что процедура была выполнена хотя бы однажды. При использовании надежного транспортного протокола (TCP) в случае получения отклика можно сказать, что процедура была выполнена один раз. Если же отклик не получен, определенно сказать, что процедура не была выполнена, нельзя. Даже при использовании надежных транспортных протоколов в случае аварийного завершения работы сервера требуются повторное установление связи и повторная передача.
При разработке распределенных приложений не придется вникать в подробности протокола RPC или программировать обработку сообщений. Среда разработки значительно облегчает создание прикладного программного обеспечения. Разработка распределенного приложения начинается с определения интерфейса объекта — формального описания функций сервера, сделанного на специальном языке. На основании этого интерфейса затем автоматически создаются заглушки клиента и сервера. После этого необходимо написать фактический код процедуры.
Например, RPC фирмы Sun Microsystems состоит из трех основных частей:
rpcgen — RPC-компилятор, который на основании описания интерфейса удаленной процедуры генерирует заглушки клиента и сервера в виде программ на языке С.
Библиотека XDR (external Data Representation), которая содержит функции преобразования данных в стандартный вид для обмена между разнородными системами.
Библиотека модулей, обеспечивающих работу системы в целом.
Сетевые службы и сетевые сервисы. Виды сетевых служб.
Под «службой» будем понимать сетевой компонент, который реализует некоторый набор услуг, а под «сервисом» - описание набора услуг, который предоставляется данной службой. То есть «сервис» - это интерфейс между потребителем услуг и поставщиком услуг (службой).
Сетевая служба состоит из клиентской и серверной частей. Принципиальной разницей между ними является то, что инициатором выполнения работы сетевой службой всегда выступает клиент, а сервер всегда находится в пассивном ожидании запросов.
Сетевые службы могут быть следующих видов:
файловая служба (доступ через сеть к файловой системе другого компьютера);
служба печати (доступ через сеть к общим принтерам сети, сервис печати);
почтовая служба (доступ к информационному ресурсу сети – электронным письмам);
служба удаленного доступа (доступ к ресурсам сети через коммутируемые каналы);
служба каталогов (ведение базы данных о пользователях, а также о программных и аппаратных компонентах сети);
служба мониторинга сети (анализ сетевого трафика);
служба резервного копирования и архивирования;
служба безопасности (идентификация пользователей и разграничение доступа к ресурсам сети).
Наиболее важными для пользователей являются файловая служба и служба печати. Конкретная ОС может содержать и другие наборы услуг.
Встроенные сетевые службы и сетевые оболочки
На практике сложилось несколько подходов к построению сетевых операционных систем, различающихся глубиной внедрения сетевых служб в операционную систему:
сетевые службы глубоко встроены в ОС;
сетевые службы объединены в виде некоторого набора — оболочки;
сетевые службы производятся и поставляются в виде отдельного продукта.
Например, встроенная файловая служба Windows NT реализует протокол SMB, используемый во всех ОС компании Microsoft, а дополнительная файловая служба, входящая в состав оболочки File and Print Services for NetWare для той же Windows NT, работает по протоколу NCP, «родному» для сетей NetWare.
Первые сетевые ОС представляли собой совокупность уже существующей локальной ОС и надстроенной над ней сетевой оболочки.
В дальнейшем разработчики сетевых ОС посчитали более эффективным подход, при котором сетевая ОС с самого начала работы над ней задумывается и проектируется специально для работы в сети. Сетевые функции у этих ОС глубоко встраиваются в основные модули системы, что обеспечивает ее логическую стройность, простоту эксплуатации и модификации, а также высокую производительность. Важно, что при таком подходе отсутствует избыточность.
Другой вариант реализации сетевых служб — объединение их в виде некоторого набора (оболочки), при этом все службы такого набора должны быть между собой согласованы, то есть в своей работе они могут обращаться друг к другу, могут иметь в своем составе общие компоненты. Для работы оболочки необходимо наличие некоторой локальной операционной системы, которая выполняла бы обычные функции, необходимые для управления аппаратурой компьютера, и в среде которой выполнялись бы сетевые службы, составляющие эту оболочку.
Одна и та же оболочка может предназначаться для работы над совершенно разными операционными системами. Сетевые оболочки часто подразделяются на клиентские и серверные. Оболочка, которая преимущественно содержит клиентские части сетевых служб, называется клиентской. Например, типичным набором программного обеспечения рабочей станции в сети NetWare является система MS-DOS с установленной над ней клиентской оболочкой NetWare, состоящей из клиентских частей файловой службы и службы печати, а также компонента, поддерживающего пользовательский интерфейс.
Сеть, оправдывающая свое назначение и обеспечивающая взаимодействие компьютеров, может быть построена по одной из трех следующих схем:
сеть на основе одноранговых узлов — одноранговая сеть;
сеть на основе клиентов и серверов — сеть с выделенными серверами;
сеть, включающая узлы всех типов, — гибридная сеть.
Каждая из этих схем обладает своими достоинствами и недостатками, определяющими их области применения.
В одноранговых сетях на всех компьютерах устанавливается такая операционная система, которая предоставляет всем компьютерам в сети потенциально равные возможности, поэтому одноранговые ОС должны включать как серверные, так и клиентские компоненты сетевых служб. Одноранговые сети проще в организации и эксплуатации, по этой схеме организуется работа в небольших сетях, в которых количество компьютеров не превышает 10-20.
В сетях с выделенными серверами используются специальные варианты сетевых ОС, которые оптимизированы для работы в роли серверов и называются серверными ОС. Пользовательские компьютеры в этих сетях работают под управлением клиентских ОС.
Для оптимизации серверных операций разработчики ОС ущемляют другие ее функции, иногда вплоть до полного их отбрасывания. Примером такого подхода является серверная ОС NetWare. В ней оптимизированы файловый сервис и сервис печати и отсутствуют многие элементы, важные для универсальной ОС: графический интерфейс пользователя, поддержка универсальных приложений, виртуальная память, защита приложений мультипрограммного режима. Это позволило добиться уникальной скорости файлового доступа и вывело эту операционную систему в лидеры серверных ОС на долгое время.
К основным отличиям серверных ОС от клиентских можно отнести:
поддержку мощных аппаратных платформ, в том числе мультипроцессорных;
поддержку большого числа одновременно выполняемых процессов и сетевых соединений;
включение в состав ОС компонентов централизованного администрирования сети (например, справочной службы или службы аутентификации и авторизации пользователей сети);
более широкий набор сетевых служб.
Многие компании, разрабатывающие сетевые ОС, выпускают два варианта одной и той же операционной системы: серверный и клиентский. Эти варианты чаще всего основаны на одном и том же базовом коде, но отличаются набором служб и утилит, а также параметрами конфигурации, некоторые из которых устанавливаются по умолчанию и не изменяются.
Например, операционная система Windows NT выпускается в варианте для рабочей станции — Windows NT Workstation — и в варианте для выделенного сервера — Windows NT Server. ОС Windows NT Workstation, кроме выполнения функций сетевого клиента, может предоставлять сетевым пользователям файловый сервис, сервис печати, сервис удаленного доступа и другие сервисы, а следовательно, может служить основой для одноранговой сети.
ОС Windows NT Server позволяет локально запускать прикладные программы, которым могут потребоваться клиентские функции ОС при появлении запросов к ресурсам других компьютеров. Windows NT Server имеет такой же развитый графический интерфейс, как и Windows NT Workstation, что позволяет использовать ее для интерактивной работы пользователя или администратора. Однако вариант Windows NT Server имеет больше возможностей для предоставления своих ресурсов другим пользователям сети, так как поддерживает более широкий набор функций, большее количество одновременных соединений с клиентами, централизованное управление сетью, более развитые средства защиты.
Концепции распределенной обработки в сетевых ОС. Схемы распределения приложений в сети.
Целесообразно выделить три основных группы способов организации работы приложений в сети:
разделение приложения на части, выполняющиеся на разных компьютерах сети;
выделение специализированных серверов в сети, на которых выполняются некоторые общие для всех приложений функции;
взаимодействие между частями приложений, работающих на разных компьютерах.
Приложение можно разделить, например, на шесть функциональных частей:
средства представления данных на экране, например средства графического пользовательского интерфейса;
логика представления данных на экране (правила и возможные сценарии взаимодействия пользователя с приложением: выбор из системы меню, выбор элемента из списка и т. п.);
прикладная логика — набор правил для принятия решений, вычислительные процедуры и операции;
логика данных — операции с данными для реализации прикладной логики;
внутренние операции базы данных — действия СУБД, вызываемые в ответ на выполнение запросов логики данных, такие как поиск записи по определенным признакам;
файловые операции — стандартные операции над файлами и файловой системой, которые обычно являются функциями операционной системы.
Можно построить несколько схем распределения частей приложения между компьютерами сети.
Двухзвенные схемы
Распределение приложения между компьютерами сети существенно усложняет организацию самого приложения. Поэтому на практике приложение обычно разделяют на две или три части и достаточно редко — на большее число частей.
Наиболее распространенной является двухзвенная схема распределения приложения между двумя компьютерами. Перечисленные выше типовые функциональные части приложения можно разделить между двумя компьютерами различными способами.
В централизованной схеме (рис. 2.1) компьютер пользователя работает как терминал, выполняющий лишь функции представления данных, а все остальные функции передаются центральному компьютеру. Фактически эта схема повторяет организацию многотерминальной системы на базе мэйнфрейма с тем лишь отличием, что вместо терминалов используются компьютеры, подключенные не через локальный интерфейс, а через сеть. Главным недостатком этой схемы является ее недостаточная масштабируемость и отсутствие отказоустойчивости.
Этот подход достаточно распространен и называется терминальным доступом. Его преимущества: высокая безопасность (на рабочей станции устанавливается только операционная система и клиентская часть приложения и не устанавливаются средства доступа к СУБД), невысокие требования к аппаратному обеспечению рабочих станций, низкие затраты на сопровождение рабочих станций.
Компьютер 1 Компьютер 2
Эмуляция терминала сервера
Логика приложения и обращения к базе данных |
Операции базы данных |
Файловые операции |

Клиент Сервер
Рис. 2.1. Централизованная схема распределения приложения
В схеме «файловый сервер» (рис. 2.2) на клиентской машине выполняются все части приложения, кроме файловых операций. В сети имеется достаточно мощный компьютер, имеющий дисковую подсистему большого объема, который хранит файлы, доступ к которым необходим большому числу пользователей. Распределенное приложение в этой схеме мало отличается от полностью локального приложения. Единственным отличием является обращение к удаленным файлам вместо локальных.
Чтобы в этой схеме использовать локальные приложения, в операционную систему ввели компонент сетевой файловой службы - редиректор, который перехватывает обращения к удаленным файлам и направляет запросы в сеть, освобождая приложение от необходимости явно задействовать сетевые системные вызовы.
Такая схема обладает хорошей масштабируемостью, так как дополнительные пользователи и приложения добавляют лишь незначительную нагрузку на центральный узел — файловый сервер. Однако эта архитектура имеет и свои недостатки:
во многих случаях резко возрастает сетевая нагрузка (например, многочисленные запросы к базе данных могут приводить к загрузке всей базы данных в клиентскую машину), что приводит к увеличению времени реакции приложения;
компьютер клиента должен обладать высокой вычислительной мощностью, чтобы справляться с представлением данных, логикой приложения, логикой данных и поддержкой операций базы данных.
Компьютер 1 Компьютер 2
Файловые операции

Интерфейс пользователя |
Логика приложения и обращения к базе данных |
Операции базы данных |
Рис. 2.2. Схема «файловый сервер»
Другие варианты двухзвенной модели более равномерно распределяют функции между клиентской и серверной частями системы. Наиболее часто используется схема, в которой на сервер возлагаются функции проведения внутренних операций базы данных и файловых операций (рис. 2.3).
Клиентский компьютер при этом выполняет все функции, специфические для данного приложения, а сервер — функции, реализация которых не зависит от специфики приложения, из-за чего эти функции могут быть оформлены в виде сетевых служб. Поскольку функции управления базами данных нужны далеко не всем приложениям, то в отличие от файловой системы они чаще всего не реализуются в виде службы сетевой ОС, а являются независимой распределенной прикладной системой. Система управления базами данных (СУБД) является одним из наиболее часто применяемых в сетях распределенных приложений.
Компьютер 1 Компьютер 2

Клиент Сервер
Рис. 2.3. Двухзвенная модель с равномерным распределением функций между клиентской и серверной частями
Трехзвенные схемы
Трехзвенная архитектура позволяет еще лучше сбалансировать нагрузку на различные компьютеры в сети, а также способствует дальнейшей специализации серверов и средств разработки распределенных приложений. Примером трехзвенной архитектуры может служить такая организация приложения, при которой на клиентской машине выполняются средства представления и логика представления, а также поддерживается программный интерфейс для вызова частей приложения второго звена — промежуточного сервера (рис. 2.4).
Промежуточный сервер называют в этом варианте сервером приложений, так как на нем выполняются прикладная логика и логика обработки данных, представляющих собой наиболее специфические и важные части большинства приложений. Слой логики обработки данных вызывает внутренние операции базы данных, которые реализуются третьим звеном схемы — сервером баз данных.
Компьютер 1 Компьютер 2 Компьютер 3
Логика приложения и обращения к базе данных
Операции Файловые
базы
данных операции
Интерфейс
пользователя


Клиент Сервер приложений Сервер баз данных
Рис. 2.4. Трехзвенная схема
Сервер баз данных, как и в двухзвенной модели, выполняет функции двух последних слоев — операции внутри базы данных и файловые операции.
Итак, централизованная реализация логики приложения решает проблему недостаточной вычислительной мощности клиентских компьютеров для сложных приложений, упрощает администрирование и сопровождение, а также снижает риск несанкционированного доступа к корпоративным данным. В том случае, когда сервер приложений сам становится узким местом, в сети можно применить несколько серверов приложений, распределив запросы пользователей между ними
Трехзвенные схемы часто применяются для централизованной реализации в сети некоторых общих для распределенных приложений функций, отличных от файлового сервиса и управления базами данных.
Сервер приложений должен базироваться на мощной аппаратной платформе (мультипроцессорные системы, специализированные кластерные архитектуры). ОС сервера приложений должна обеспечивать высокую производительность вычислений, а значит, поддерживать многопоточную обработку, вытесняющую многозадачность, мультипроцессирование, виртуальную память и наиболее популярные прикладные среды.
Таким образом, к основным функциональным компонентам сетевой ОС относятся средства управления локальными ресурсами и сетевые средства. Последние, в свою очередь, можно разделить на три компонента: средства предоставления локальных ресурсов и услуг в общее пользование — серверная часть ОС, средства запроса доступа к удаленным ресурсам и услугам — клиентская часть ОС (редиректор) и транспортные средства ОС, которые совместно с коммуникационной системой обеспечивают передачу сообщений между компьютерами сети.
В число требований, предъявляемых к сетевым ОС, входят: функциональная полнота и эффективность управления ресурсами, модульность и расширяемость, переносимость (многоплатформенность), совместимость на уровне приложений и пользовательских интерфейсов, способность к интеграции с другими ОС, надежность и отказоустойчивость, безопасность и производительность.
Сетевые файловые системы. Варианты организации взаимодействия клиента и сервера.
Ключевым компонентом любой распределенной системы является файловая система, которая также является в этом случае распределенной. Если файловую систему рассматривать как набор услуг, то ее можем считать файловой службой. Функцией файловой службы в распределенной системе, как и в централизованных системах, является хранение программ и данных и предоставление доступа к ним.
Файловая служба имеет две функционально различные части: собственно файловую службу и службу каталогов файловой системы (ФС). Первая имеет дело с операциями над отдельными файлами, такими как чтение, запись или добавление, а вторая — с созданием каталогов и управлением ими, добавлением и удалением файлов из каталогов и т. п.
Клиент сетевой ФС передает по сети запросы серверу сетевой ФС. Сервер, получив запрос, может выполнить его либо самостоятельно, либо передать запрос локальной файловой системе для отработки. После получения ответа от локальной файловой системы сервер передает его по сети клиенту, а тот, в свою очередь, — приложению, обратившемуся с запросом.
Клиент и сервер взаимодействуют по определенному протоколу (например, RPC). В ОС Windows основой сетевой файловой службы является протокол SMB (Server Message Block), который был совместно разработан компаниями Microsoft, Intel и IBM (его последние версии получили название Common Internet File System, CIFS). Он построен на базе FAT и относится к классу протоколов, ориентированных на соединение. Как и все протоколы файловых служб, этот протокол работает на прикладном уровне модели OSI. Протокол SMB базируется на различных транспортных протоколах (NetBIOS и его более поздняя реализация NetBEUI, а также TCP/UDP и IPX).
Протокол сетевой файловой системы кроме просто ретрансляции системных файловых вызовов от клиента серверу может выполнять и более сложные функции, влияющие на эффективность удаленного доступа к файлам. Рассмотрим несколько возможных ситуаций.
Отказ компьютера, на котором выполняется сервер сетевой файловой системы, во время сеанса связи с клиентом. Локальная файловая система запоминает состояние операций во внутренней системной таблице открытых файлов (системные вызовы open, read, write изменяют состояние этой таблицы). Если таблица открытых файлов хранится на серверном компьютере, то после его перезагрузки, вызванной крахом системы, содержимое этой таблицы теряется, и клиент не может продолжить нормальную работу с открытыми до краха файлами. Одно из решений этой проблемы - передача функции ведения и хранения таблицы открытых файлов от сервера клиенту. Тогда после перезагрузки сервера работа с файлами может быть продолжена. Файловый сервер в этом варианте получил название «stateless», то есть «не запоминающий состояния».
Большие задержки обслуживания из-за заторов в сети и перегрузки файлового сервера при подключении большого числа клиентов. Для решения этой проблемы можно организовывать кэширование файлов целиком или частично на стороне клиента. Тогда в сети может образоваться большое количество копий файла, которые изменяются разными пользователями. То есть протокол должен обеспечивать согласованность копий файлов, имеющихся на разных компьютерах.
Потери данных и разрушение целостности файловой системы при сбоях и отказах серверных компьютеров. Для повышения отказоустойчивости файловой системы можно хранить копии файлов (или копии локальной файловой системы), причем каждую копию — на отдельном компьютере. Такие копии файлов называются репликами. Протокол сетевого доступа к файлам обращается в случае отказа одного файлового сервера к другому серверу. Репликация файлов повышает отказоустойчивость и повышает производительность системы, так как запросы к файлам распределяются между несколькими серверами. Репликация похожа на кэширование — в том и другом случаях в сети создается несколько копий одного и того же файла, при этом повышается скорость доступа к данным. Основным отличием репликации от кэширования является то, что реплики хранят файловые серверы, а кэшированные файлы - клиенты.
Аутентификация выполняется на одном компьютере, например на клиентском, а авторизация, то есть проверка прав доступа к каталогам и файлам, — на другом, выполняющем роль файлового сервера. Эта проблема должна учитываться протоколом взаимодействия клиентов и серверов, поддерживающих тот или иной набор дополнительных функций.
Доступ к локальной файловой системе могут обеспечивать различные протоколы сетевой файловой системы. Так, к файловой системе NTFS можно получить доступ с помощью различных протоколов (рис. 2.5), например, SMB, NCP (NetWare Control Protocol — компании Novell) и NFS (Network File System — компании Sun Microsystems, популярный в различных вариантах ОС UNIX).
За достаточно долгий срок развития сетей в них утвердилось несколько сетевых файловых систем. В локальных сетях на протяжении многих лет доминировала сетевая операционная система NetWare, которая использовала на файловых серверах оригинальную локальную файловую систему NetWare и протокол NCP. Клиенты этой сетевой файловой системы обеспечивали приложениям расширенный интерфейс файловой системы FAT — расширения включали в основном поддержку разграничения прав доступа к файлам и каталогам.
В среде операционной системы UNIX наибольшее распространение получили две сетевые файловые системы — FTP (File Transfer Protocol) и NFS (Network File System). Они первоначально разрабатывались для доступа к локальной файловой системе s5/ufs, являющейся основной для большинства ОС семейства UNIX.
Рис. 2.5. Доступ к одной локальной файловой системе с помощью нескольких протоколов клиент-сервер
Интерфейс сетевой файловой службы. Варианты (семантики) совместного использования файлов.
Структура файла
Для любой файловой службы важен вопрос, каким является файл? Во многих системах, таких как UNIX и Windows, файл — это не интерпретируемая последовательность байтов. Значение и структура информации в файле является заботой прикладных программ, операционную систему это не интересует. В ОС мэйнфреймов поддерживаются разные типы логической организации файлов, каждый с различными свойствами. Файл может быть организован как последовательность записей, и у операционной системы имеются вызовы, которые позволяют работать на уровне этих записей.
Большинство сетевых файловых систем, как и локальные файловые системы, рассматривают файлы как последовательности байтов, а не последовательности записей.
Модифицируемость файлов
Важным аспектом файловой модели является возможность модификации файла после его создания. В большинстве сетевых файловых систем файлы могут модифицироваться, но в некоторых распределенных системах единственными операциями с файлами являются create (создать) и read (прочитать). Такие файлы называются неизменяемыми. Для неизменяемых файлов намного легче осуществить кэширование файла и его репликацию, так как исключаются все проблемы, связанные с обновлением всех копий файла при его изменении. Однако проблемы поддержки многих версий неизменяемого файла, возникающих при его модификации, перекладываются на пользователей, которые должны давать им имена с учетом того, что все эти файлы имеют близкое содержание, и в то же время необходимо различать версии файлов.
Семантика разделения (совместного использования) файлов
Когда два или более пользователей используют один и тот же файл, необходимо точно определить семантику чтения и записи, чтобы избежать ошибок в использовании данных файла.
Семантика UNIX. В централизованных многопользовательских операционных системах, таких как локальная версия UNIX, обычно определяется, что когда операция чтения следует за операцией записи, то читается только что обновленный файл. Аналогично, когда операция чтения следует за двумя операциями записи, то читается файл, измененный последней операцией записи. Тем самым система придерживается абсолютного временного упорядочивания всех операций и всегда возвращает самое последнее значение данных. Если запись осуществляется в открытый многими пользователями файл, то пользователи немедленно видят результат изменения данных файла. Такая модель называется семантикой UNIX.
Семантика UNIX может быть обеспечена и в распределенных системах, но только если в ней имеется лишь один файловый сервер и клиенты не кэшируют файлы. Для этого все операции чтения и записи направляются на сервер, который обрабатывает их строго последовательно. Чтобы поднять производительность, иногда клиентам разрешают обрабатывать локальные копии часто используемых файлов в своих личных кэшах. Если клиент изменит копию файла в своем локальном кэше, а после этого другой клиент прочитает этот файл с сервера, то он получит неверную копию файла. Для устранения этого недостатка немедленно переносят все изменения в кэшированном файле на сервер. Такой подход не эффективен, поэтому обычно используется более свободная семантика разделения файлов.
Сеансовая семантика. В соответствии с этой моделью изменения в открытом файле сначала видны только процессу, который модифицирует файл, и только после закрытия файла эти изменения могут видеть другие процессы. При использовании сеансовой семантики возникает проблема одновременного использования одного и того же файла двумя или более клиентами. Одним из решений этой проблемы является принятие правила, в соответствии с которым окончательным является тот вариант, который был закрыт последним. Однако из-за задержек в сети часто оказывается трудно определить, какая из копий файла была закрыта последней. Менее эффективным, но гораздо более простым в реализации является вариант, при котором окончательным результирующим файлом на сервере считается любой из этих файлов, то есть результат операций над файлом не является детерминированным.
Семантика неизменяемых файлов. Если сделать файл неизменяемым, то файл нельзя открывать для записи, а можно выполнять только операции create (создать) и read (читать). Тогда изменение файла будет состоять в создании полностью нового файла и занесении его в каталог под новым именем. Следовательно, хотя файл и нельзя модифицировать, его можно заменить новым файлом. В этом случае проблема обеспечения одновременного использования файла исчезает для файловой системы, но не для пользователей, которые будут вынуждены вести учет имен своих копий модифицированного файла.
Транзакционная семантика — это использование механизма неделимых транзакций, то есть неделимых работ, которые не могут быть выполнены частично.
Управление доступом
С каждым разделяемым файлом обычно связан список управления доступом (Access Control List, ACL). Если локальная файловая система поддерживает механизм ACL для файлов и каталогов, то его использует и сетевая файловая система. Если же механизм защиты в локальной файловой системе отсутствует, то сетевой файловой системе приходится поддерживать его самостоятельно, иногда — упрощенным способом, защищая разделяемый каталог и входящие в него файлы и подкаталоги как единое целое. В том случае, когда работают оба уровня защиты, у пользователей и администраторов могут иногда возникать некоторые логические сложности, связанные с определением реальных прав доступа как комбинации нескольких правил.
Единица доступа
Файловый интерфейс может быть отнесен к одному из следующих двух типов (моделей).
1. Модель загрузки-выгрузки, где пользователю предлагаются средства чтения или записи файла целиком. Схема обработки файла следующая: чтение файла с сервера на машину клиента, обработка файла на машине клиента и запись обновленного файла на сервер. Типичным представителем этого вида файлового интерфейса является служба FTP, пользователь которой должен применить команду get для перемещения файла с сервера на клиентский компьютер и команду put для возвращения файла на сервер.
Преимуществом этой модели является ее простота и, возможно, эффективность в отношении объема создаваемого трафика. Недостатки этой модели: высокие требования к объему диска клиента, который должен вместить любой файл, хранящийся на сервере; необходимость перемещения всего файла, если нужна его небольшая часть.
2. Модель удаленного доступа, которая поддерживает большое количество операций над файлами: открытие и закрытие файлов, чтение и запись частей файла, изменение атрибутов файла и т. д. В модели загрузки-выгрузки файловый сервер обеспечивал только хранение и перемещение файлов. В данном случае все файловые операции выполняются на серверах, а клиенты только генерируют запросы на их отработку. Преимуществом такого подхода являются низкие требования к дисковому пространству на клиентских машинах, а также исключение необходимости передачи целого файла, когда нужна только его часть. Модели удаленного доступа могут использовать различные единицы перемещения части файла: байт, блок или запись. Запись используется только, когда локальная файловая система поддерживает структурированные файлы.
Вопросы реализации сетевой файловой системы. Схемы реализации файлового сервера.
Размещение клиентов и серверов по компьютерам и в операционной системе
В некоторых файловых системах на всех компьютерах сети работает одно и то же базовое программное обеспечение, включающее как клиентскую, так и серверную части. Для предоставления услуг файловой службы администратор объявляет имена выбранных каталогов разделяемыми (экспортируемыми в терминах NFS). Тогда другие машины могут иметь к ним доступ. В некоторых системах файловый сервер — это специализированный компонент серверной ОС, отсутствующий в клиентских компьютерах (пример - ОС NetWare).
Файловые серверы типа stateful и stateless
Файловый сервер может быть реализован по одной из двух схем: с запоминанием данных о последовательности файловых операций клиента, то есть по схеме stateful, и без запоминания таких данных, то есть по схеме stateless.
1. Серверы stateful работают по схеме, обычной для любой локальной файловой службы. Такой сервер поддерживает тот же набор вызовов, что и локальная система, то есть вызовы open, read, write и т. п. Таблица, отображающая дескрипторы файлов на сами файлы, является хранилищем информации о состоянии клиентов.
2. Для сервера stateless каждый запрос должен содержать всю информацию (полное имя файла, смещение от начала файла и количество читаемых или записываемых байт), необходимую серверу для выполнения требуемой операции. В этой схеме увеличивается длина сообщения и время, которое тратит сервер на открытие файла каждый раз, когда производится очередная операция. Набор команд, предоставляемый клиенту сервером stateless, может состоять только из двух команд: read и write. Для того чтобы обеспечить приложениям, работающим на клиентских машинах, привычный файловый интерфейс, включающий вызовы открытия и закрытия файлов, клиент файловой службы должен самостоятельно поддерживать таблицы открытых его приложениями файлов.
Преимущества каждого из подходов можно обобщить следующим образом.
Серверы stateless:
отказоустойчивы;
не нужны вызовы open/close;
меньше памяти сервера расходуется на таблицы;
нет ограничений на число открытых файлов;
отказ клиента не создает проблем для сервера.
Серверы stateful:
более короткие сообщения при запросах;
лучше производительность;
возможно опережающее чтение;
возможна блокировка файлов.
Вопросы реализации сетевой файловой системы. Кэширование. Способы распространения модификаций. Проверка достоверности кэша.
Схемы кэширования в сетевых файловых системах отличаются по трем вопросам:
месту расположения кэша;
способу распространения модификаций;
проверке достоверности кэша.
На схему кэширования влияет, какая выбрана в файловой системе модель переноса файлов между сервером и клиентами: модель загрузки-выгрузки или модель удаленного доступа. В первом случае файл кэшируется целиком, а во втором - кэшируются только те части файла, к которым выполняется обращение.
Место расположения кэша
В клиент-серверных системах имеются три места для хранения кэшируемых файлов и их частей: память сервера, диск клиента и память клиента.
Память сервера практически всегда используется для кэширования файлов. При этом файловый сервер может использовать для кэширования своих файлов существующий механизм локального кэша операционной системы. Однако кэширование только в памяти сервера не решает всех проблем — скорость доступа по-прежнему снижают задержки, вносимые сетью, и загруженность процессора сервера.
Кэширование на стороне клиента. Использование диска как места временного хранения данных на стороне клиента позволяет кэшировать большие файлы, что особенно важно при применении модели загрузки-выгрузки, переносящей файлы целиком. Диск также является более надежным устройством хранения информации по сравнению с оперативной памятью. Однако такой способ кэширования вносит дополнительные задержки доступа, связанные с чтением данных с клиентского диска, а также неприменим на бездисковых компьютерах.
Кэширование в оперативной памяти клиента позволяет ускорить доступ к данным, но ограничивает размер данных объемом кэша, что может стать существенным ограничением при применении модели загрузки-выгрузки.
Способы распространения модификаций
Существование в одно и то же время в сети нескольких копий файла, хранящихся в кэшах клиентов, порождает проблему согласования копий.
Для решения этой проблемы необходимо, чтобы модификации данных, выполненные над одной из копий, были своевременно распространены на все остальные копии. Существует несколько вариантов распространения модификаций. От выбранного варианта в значительной степени зависит семантика разделения файлов.
Одним из путей решения проблемы согласования является использование алгоритма сквозной записи. Когда кэшируемый элемент (файл или блок) модифицируется, новое значение записывается в кэш и одновременно посылается на сервер для обновления главной копии файла (семантика в стиле UNIX).
Один из недостатков алгоритма сквозной записи состоит в том, что он уменьшает интенсивность сетевого обмена только при чтении, при записи интенсивность сетевого обмена та же самая, что и без кэширования. Поэтому часто применяют алгоритм отложенной записи: вместо того чтобы выполнять запись на сервер, клиент просто помечает, что файл изменен. Примерно каждые 30 секунд все изменения в файлах собираются вместе и отсылаются на сервер за один прием. Одно большое сообщение для сетевого обмена обычно более эффективно, чем множество коротких.
Применяется также сеансовая семантика, в соответствии с которой запись файла на сервер производится только после закрытия файла. Этот алгоритм называется «запись по закрытию» и приводит к тому, что если две копии одного файла кэшируются на разных машинах и последовательно записываются на сервер, то второй записывается поверх первого.
Для всех схем, связанных с задержкой записи, характерна низкая надежность, так как модификации, не отправленные на сервер на момент краха системы, теряются. Кроме того, задержка делает семантику совместного использования файлов не очень ясной, поскольку считываемые данные зависят от соотношения момента чтения с моментом очередной записи модификаций.
Проверка достоверности кэша
Распространение модификаций решает только проблему согласования главной копии файла, хранящейся на сервере, с клиентскими копиями. В то же время этот прием не дает никакой информации о том, когда должны обновляться данные, находящиеся в кэшах клиентов. Очевидно, что данные в кэше одного клиента становятся недостоверными, когда данные, модифицированные другим клиентом, переносятся в главную копию файла. Следовательно, необходимо каким-то образом проверять, являются ли данные в кэше клиента достоверными. В противном случае данные кэша должны быть повторно считаны с сервера. Существуют два подхода к решению этой проблемы — инициирование проверки клиентом и инициирование проверки сервером.
1. Клиент связывается с сервером и проверяет, соответствуют ли данные в его кэше данным главной копии файла на сервере. Клиент может выполнять такую проверку одним из трех способов.
Перед каждым доступом к файлу. Этот способ дискредитирует саму идею кэширования, так как каждое обращение к файлу вызывает обмен по сети с сервером. Но зато это обеспечивает семантику разделения файлов UNIX.
Периодические проверки. Улучшают производительность, но делают семантику разделения неясной, зависящей от временных соотношений.
Проверка при открытии файла. Этот способ подходит для сеансовой семантики. Сеансовая семантика требует одновременного применения модели доступа загрузки-выгрузки, метода распространения модификаций «запись по закрытию» и проверки достоверности кэша при открытии файла.
2. Инициирование проверки сервером можно назвать методом централизованного управления. Когда файл открывается, то клиент посылает соответствующее сообщение файловому серверу. Файловый сервер сохраняет информацию о том, кто и какой файл открыл, а также о том, открыт файл для чтения, для записи или для того и другого. Если файл открыт для чтения, то другие процессы могут открыть его для чтения, но открытие его для записи должно быть запрещено. Если файл открыт для записи, то все другие виды доступа должны быть запрещены. При закрытии файла оповещается сервер для того, чтобы он обновил свои таблицы, содержащие данные об открытых файлах. В такой момент модифицированный файл может быть выгружен на сервер.
Когда новый клиент делает запрос на открытие уже открытого файла и сервер обнаруживает, что режим нового открытия входит в противоречие с режимом текущего открытия, то сервер может ответить на такой запрос следующими способами:
отвергнуть запрос;
поместить запрос в очередь;
запретить кэширование для данного конкретного файла, потребовав от всех клиентов, открывших этот файл, удалить его из кэша.
Подход, основанный на централизованном управлении, весьма эффективен, обеспечивает семантику разделения UNIX, но обладает следующими недостатками.
Он отклоняется от традиционной модели взаимодействия клиента и сервера, при которой сервер только отвечает на запросы, инициированные клиентами. Это делает код сервера нестандартным и достаточно сложным.
Сервер должен хранить информацию о состоянии сеансов клиентов (тип stateful).
Клиенты должны инициировать проверки достоверности кэша при открытии файлов.
Вопросы реализации сетевой файловой системы. Репликация. Прозрачность репликации. Способы согласования реплик.
Репликация подразумевает существование нескольких копий одного и того же файла, каждая из которых хранится на отдельном файловом сервере, при этом обеспечивается автоматическое согласование данных в копиях файла.
Главные причины применения репликации: увеличение надежности за счет наличия независимых копий каждого файла и распределение нагрузки между несколькими серверами.
Если кэширование предназначено для обеспечения локального доступа к файлу одному клиенту и повышения за счет этого скорости работы этого клиента, то репликация нужна для повышения надежности хранения файлов и снижения нагрузки на файловые серверы. Реплики файла доступны всем клиентам, так как хранятся на файловых серверах, а не на клиентских компьютерах, и о существовании реплик известно всем компьютерам сети. Файловая система обеспечивает достоверность данных реплики и защиту ее данных.
Прозрачность репликации
Прозрачность здесь связана со следующими вопросами. До какой степени пользователи должны быть в курсе того, что некоторые файлы реплицируются? Должны они играть какую-либо роль в процессе репликации или репликация должна выполняться полностью автоматически.
Прозрачность репликации зависит от двух факторов: используемой схемы именования реплик и степени вовлеченности пользователя в управление репликацией.
Именование реплик. Прозрачность доступа к файлу, существующему в виде нескольких реплик, может поддерживаться системой именования, которая отображает имя файла на его сетевой идентификатор, однозначно определяющий место хранения файла. При обращении к файлу приложение использует имя, а справочная система возвращает ему один из идентификаторов, указывающий на сервер, хранящий реплику.
Наиболее просто такую схему реализовать для неизменяемых файлов, все реплики которых всегда (или почти всегда, если файлы редко, но все же изменяются) идентичны. В случае когда реплицируются изменяемые файлы, полностью прозрачный доступ требует ведения некоторой базы, хранящей сведения о том, какие из реплик содержат последнюю версию данных, а какие еще не обновлены.
Управление репликацией. Этот процесс подразумевает определение количества реплик и выбор серверов для их хранения. В прозрачной системе репликации такие решения принимаются автоматически при создании файла на основе правил стратегии репликации, определенных заранее администратором системы. В непрозрачной системе репликации решения о количестве реплик и их размещении принимаются с участием пользователя, или разработчика приложения, если файлы создаются в автоматическом режиме. Существуют два режима управления репликацией:
При явной репликации пользователь создает файл с явным указанием сервера, на котором он размещается (первая реплика), а затем создается несколько реплик, причем для каждой реплики сервер также указывается явно. Пользователь при желании может впоследствии удалить одну или несколько реплик.
При неявной репликации (implicit replication) выбор количества и места размещения реплик производится без участия пользователя. Файловая система самостоятельно выбирает сервер, на который помещает первую реплику файла. Затем в фоновом режиме система создает несколько реплик этого файла, выбирая их количество и серверы для их размещения. Если надобность в некоторых репликах исчезает (это также определяется автоматически), то система их удаляет.
Согласование реплик
Существует несколько способов обеспечения согласованности реплик.
Чтение любой — запись во все. При записи в файл все реплики блокируются, затем выполняется запись в каждую копию, после чего блокировка снимается и файл становится доступным для чтения. Чтение может выполняться из любой копии (семантика в стиле UNIX). Недостатком является то, что запись не всегда можно осуществить, так как некоторые серверы, хранящие реплики файла, могут в момент записи быть неработоспособными.
Запись в доступные. Запись выполняется только в те копии, серверы которых доступны на момент записи. Чтение осуществляется из любой реплики файла, как и в предыдущем методе. Любой сервер, хранящий реплику файла, после перезагрузки должен соединиться с другим сервером и получить от него обновленную копию файла и только потом начать обслуживать запросы на чтение из файла. Для обнаружения отказавших серверов в системе должен работать процесс, постоянно опрашивающий серверы. Недостатком метода является возможность появления несогласованных копий файла из-за проблем в сети, когда невозможно выявить отказавший сервер.
Первичная реплика. В этом методе запись разрешается только в одну реплику файла, называемую первичной. Все остальные реплики файла являются вторичными, и из них можно только читать данные. После модификации первичной реплики все серверы, хранящие вторичные реплики, должны связаться с сервером, поддерживающим первичную реплику, и получить от него обновления. Недостатком метода является его низкая надежность — при отказе первичного сервера модификации файла невозможны.
Кворум. Этот метод обобщает подходы, реализованные в предыдущих методах.
Сетевые файловые службы. Протокол передачи файлов FTP. Файловая система NFS.