

Информационная технология обработки данных Характеристика и назначение
Информационная технология обработки данных предназначена для решения хорошо структурированных задач, по которым имеются необходимые входные данные и известны алгоритмы и другие стандартные процедуры их обработки. Эта технология применяется на уровне операционной (исполнительской) деятельности персонала невысокой квалификации в целях автоматизации некоторых рутинных постоянно повторяющихся операций управленческого труда. Поэтому внедрение информационных технологий и систем на этом уровне существенно повысит производительность труда персонала, освободит его от рутинных операций, возможно, даже приведет к необходимости сокращения численности работников.
На уровне операционной деятельности решаются следующие задачи:
обработка данных об операциях, производимых фирмой;
создание периодических контрольных отчетов о состоянии дел в фирме;
получение ответов на всевозможные текущие запросы и оформление их в виде бумажных документов или отчетов.
Примеры рутинных операций:
операция проверки на соответствие нормативу уровня запасов указанных товаров на складе. При уменьшении уровня запаса выдастся заказ поставщику с указанием потребного количества товара и сроков поставки;
операция продажи товаров фирмой, в результате которой формируется выходной документ для покупателя в виде чека или квитанции.
Пример контрольного отчета: ежедневный отчет о поступлениях и выдачах наличных средств банком, формируемый в целях контроля баланса наличных средств.
Пример запроса: запрос к базе данных по кадрам, который позволит получить данные о требованиях, предъявляемых к кандидатам на занятие определенной должности.
Существует несколько особенностей, связанных с обработкой данных, отличающих данную технологию от всех прочих:
выполнение необходимых фирме задач по обработке данных. Каждой фирме предписано законом иметь и хранить данные о своей деятельности, которые можно использовать как средство обеспечения и поддержания контроля на фирме. Поэтому в любой фирме обязательно должна быть информационная система обработки данных и разработана соответствующая информационная технология;
решение только хорошо структурированных задач, для которых можно разработать алгоритм;
выполнение стандартных процедур обработки. Существующие стандарты определяют типовые процедуры обработки данных и предписывают их соблюдение организациями всех видов;
выполнение основного объема работ в автоматическом режиме с минимальным участием человека;
использование детализированных данных. Записи о деятельности фирмы имеют детальный (подробный) характер, допускающий проведение ревизий. В процессе ревизии деятельность фирмы проверяется хронологически от начала периода к его концу и от конца к началу;
акцент на хронологию событий;
требование минимальной помощи в решении проблем со стороны специалистов других уровней.
Основные компоненты
Представим основные компоненты информационной технологии обработки данных (рис. 3.12) и приведем их характеристики.
Сбор данных. По мере того как фирма производит продукцию или услуги, каждое ее действие сопровождается соответствующими записями данных. Обычно действия фирмы, затрагивающие внешнее окружение, выделяются особо как операции, производимые фирмой.
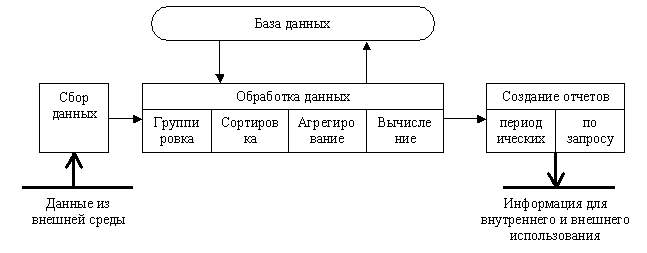
Рис. 3.12. Основные компоненты информационной технологии обработки данных
Обработка данных. Для создания из поступающих данных информации, отражающей деятельность фирмы, используются следующие типовые операции:
классификация или группировка. Первичные данные обычно имеют вид кодов, состоящих из одного или нескольких символов. Эти коды, выражающие определенные признаки объектов, используются для идентификации и группировки записей.
Пример При расчете заработной платы каждая запись включает в себя под (табельный номер) работника, код подразделения, в котором он работает, занимаемую должность и т. п. В соответствии с этими кодами можно произвести разные группировки.
сортировка, с помощью которой упорядочивается последовательность записей;
вычисления, включающие арифметические и логические операции. Эти операции, выполняемые над данными, дают возможность получать новые данные;
укрупнение или агрегирование, служащее для уменьшения количества данных и реализуемое в форме расчетов итоговых или средних значений.
Хранение данных. Многие данные на уровне операционной деятельности необходимо сохранять для последующего использования либо здесь же, либо на другом уровне. Для их хранения создаются базы данных.
Создание отчетов (документов). В информационной технологии обработки данных необходимо создавать документы для руководства и работников фирмы, а также для внешних партнеров. При этом документы или в связи с проведенной фирмой операцией так и периодически в конце каждого месяца, квартала или года.
Системы файлов и системы баз данных
Прототипом современных баз данных были файловые системы (file-based system). Файловые системы были первой попыткой компьютеризировать известные всем ручные картотеки. Подобная картотека (или подшивка документов) в некоторой организации могла содержать всю внешнюю и внутреннюю документацию, связанную с каким-либо проектом, продуктом, задачей, клиентом или сотрудником. Обычно таких папок бывает очень много, они помечаются и хранятся в одном или нескольких шкафах. В целях безопасности шкафы могут закрываться на замок или находиться в охраняемых помещениях. Практически в каждой фирме или офисе есть некое подобие такой картотеки, содержащее подшивки документов, представляющих собой счета, гарантийные талоны, рецепты, страховые и банковские документы и т.п. Если понадобится какая-то информация, требуется просмотреть картотеку от начала до конца, чтобы найти искомые сведения.
В наше время клиентам, менеджерам и другим сотрудникам с каждым днем требуется все больше и больше информации. В некоторых областях деятельности существуют даже правовые нормы на ежемесячные, ежеквартальные и годовые отчеты. Ясно, что ручная картотека совершенно не подходит для выполнения работы подобного типа. Файловые системы были разработаны в ответ на потребность в получении более эффективных способов доступа к данным. Однако, вместо организации централизованного хранилища всех данных предприятия, был использован децентрализованный подход, при котором сотрудники каждого отдела при помощи специалистов по обработке данных (ОД) работают со своими собственными данными и хранят их в своем отделе. При этом всем файловым системам присущи следующие ограничения:
разделение и изоляция данных;
дублирование данных;
зависимость от данных;
несовместимость файлов;
фиксированные запросы/быстрое увеличение количества приложений.
Когда данные изолированы в отдельных файлах, доступ к ним весьма затруднен. Например, для создания списка всех домов, отвечающих требованиям потенциальных арендаторов, предварительно нужно создать временный файл со списком арендаторов, желающих арендовать недвижимость типа "дом". Затем в другом файле следует осуществить поиск объектов недвижимости типа "дом" с арендной платой ниже установленного арендатором максимума. Выполнять подобную обработку данных в файловых системах достаточно сложно. Для извлечения соответствующей поставленным условиям информации программист должен организовать синхронную обработку двух файлов. Трудности существенно возрастают, когда необходимо извлечь данные из более чем двух файлов.
Из-за децентрализованной работы с данными в файловой системе фактически поощряется бесконтрольное дублирование данных, и это, в принципе, неизбежно. Бесконтрольное дублирование данных нежелательно по следующим двум причинам:
1. дублирование данных сопровождается неэкономным расходованием ресурсов, поскольку на ввод избыточных данных требуется затрачивать дополнительные время и деньги. Более того, для их хранения необходимо дополнительное место во внешней памяти, что связано с дополнительными накладными расходами. Во многих случаях дублирования данных можно избежать за счет совместного использования файлов;
2. еще более важен тот факт, что дублирование данных может привести к нарушению их целостности. Иначе говоря, данные в. разных отделах могут стать противоречивыми.
Как уже упоминалось выше, физическая структура и способ хранения записей файлов данных жестко зафиксированы в коде программ приложений. Это значит, что изменить существующую структуру данных достаточно сложно.
Поскольку структура файлов определяется кодом приложений, она также зависит от языка программирования этого приложения.
Фиксированные запросы/быстрое увеличение количества приложений
С точки зрения пользователя возможности файловых систем намного превосходят возможности ручных картотек. Соответственно возрастают и их требования к реализации новых или модифицированных запросов. Однако файловые системы во многом зависят от программиста, потому что все требуемые запросы и отчеты должны быть созданы именно им. В результате события обычно развивались по одному из следующих двух сценариев. 1) Во многих организациях типы создаваемых запросов и отчетов имели фиксированную форму, и не было никаких инструментов создания незапланированных или произвольных (ad hoc) запросов, как к самим данным, так и к сведениям о том, какие типы данных доступны.
В других организациях наблюдалось быстрое увеличение количества файлов и приложений. В конечном счете наступал момент, когда сотрудники отдела обработки данных (ОД) были просто не в состоянии справиться со всей этой работой с помощью имеющихся ресурсов. В этом случае нагрузка на сотрудников отдела ОД настолько возрастала, что неизбежно наступал момент, когда программное обеспечение было неспособно адекватно отвечать запросам пользователей, эффективность его падала, а недостаточность документирования имела следствием дополнительное усложнение сопровождения программ. При этом часто игнорировались вопросы поддержки функциональности системы: не предусматривались меры по обеспечению безопасности или целостности данных; средства восстановления в случае сбоя аппаратного или программного обеспечения были крайне ограниченны или вообще отсутствовали. Доступ к файлам часто ограничивался одним пользователем, т.е. не предусматривалось их совместное использование даже сотрудниками одного и того же отдела.
В любом случае, подобная организация работы (с помощью файловых систем) с течением времени изживает себя, и требуется искать другие решения.
Системы с базами данных
Все перечисленные выше ограничения файловых систем являются следствием двух факторов:
Определение данных содержится внутри приложений, а не хранится отдельно и независимо от них.
Помимо приложений не предусмотрено никаких других инструментов доступа к данным и их обработки.
Для повышения эффективности работы необходимо использовать новый подход, а именно базу данных (database) и систему управления базами данных, или СУБД (Database Management System – DBMS).
База данных представляет собой поименованную, структурированную совокупность данных, относящихся к конкретной предметной области и находящихся под централизованным программным управлением.
База данных совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации.
Любая база данных находится под управлением СУБД.
СУБД – это программное обеспечение, которое взаимодействует с прикладными программами пользователя и базой данных и обладает следующими возможностями:
позволяет определять базу данных, что обычно осуществляется с помощью языка определения данных (DDL — Data Definition Language). Язык DDL предоставляет пользователям средства указания типа данных и их структуры, а также средства задания ограничений для информации, хранимой в базе данных;
позволяет вставлять, обновлять, удалять и извлекать информацию из базы данных, что обычно осуществляется с помощью языка управления данными (DML — Data Manipulation Language). Наличие централизованного хранилища всех данных и их описаний позволяет использовать язык DML как общий инструмент организации запросов, который иногда называют языком запросов (query language). Наличие языка запросов позволяет устранить присущие файловым системам ограничения, при которых пользователям приходится иметь дело только с фиксированным набором запросов или постоянно возрастающим количеством программ, что порождает другие, более сложные проблемы управления программным обеспечением.
Наиболее распространенным типом языка запросов является язык структурированных запросов (Structured Query Language – SQL), который в настоящее время определяется специальным стандартом и фактически является обязательным языком для любых реляционных СУБД. (SQL произносится либо по буквам "S-Q-L", либо как мнемоническое имя "See-Quel".);
• предоставляет контролируемый доступ к базе данных с помощью перечисленных ниже средств:
системы обеспечения безопасности, предотвращающей несанкционированный доступ к базе данных со стороны пользователей;
системы поддержки целостности данных, обеспечивающей непротиворечивое состояние хранимых данных;
системы управления параллельной работой приложений, контролирующей процессы их совместного доступа к базе данных;
системы восстановления, позволяющей восстановить базу данных до предыдущего непротиворечивого состояния, нарушенного в результате сбоя аппаратного или программного обеспечения;
доступного пользователям каталога, содержащего описание хранимой в базе данных информации.
В структуре СУБД можно выделить следующие основные компоненты (см. Рис.32):
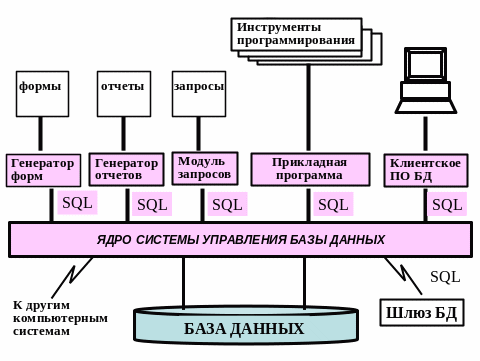
Рисунок 32 – Структура СУБД
Генераторы форм
Генератор форм представляет собой интерактивный инструмент, предназначенный для быстрого создания шаблонов ввода и отображения данных в экранных формах. Генератор форм позволяет пользователю определить внешний вид экранной формы, ее содержимое и место расположения на экране. С его помощью можно задавать цвета элементов экрана, а также другие характеристики, например полужирное, подчеркнутое, мерцающее или реверсивное начертание и т.д. Более совершенные генераторы форм позволяют создавать вычисляемые атрибуты с использованием арифметических операторов или обобщающих функций, а также задавать правила проверки вводимых данных.
Генераторы отчетов
Генератор отчетов является инструментом создания отчетов на основе хранимой в базе данных информации. Он подобен языку запросов в том смысле, что пользователю предоставляются средства создания запросов к базе данных и извлечения из нее информации, используемой для представления в отчете. Однако генераторы отчетов, как правило, предусматривают гораздо большие возможности управления внешним видом отчета. Генератор отчета позволяет либо автоматически определять вид получаемых результатов, либо с помощью специальных команд создавать свой собственный вариант внешнего вида печатаемого документа.
Существует два основных типа генераторов отчетов: языковой и визуальный. В первом случае для определения нужных для отчета данных и внешнего вида документа следует ввести соответствующую команду на некотором подъязыке. Во втором случае для этих целей используется визуальный инструмент, подобный генератору форм.
Генераторы графического представления данных
Этот генератор представляет собой инструмент, предназначенный для извлечения информации из базы данных и отображения ее в виде диаграмм с графическим представлением существующих тенденций и связей. Обычно с помощью подобного генератора создаются гистограммы, круговые, линейчатые, точечные диаграммы и т.д.
Генераторы приложений
Генератор приложений представляет собой инструмент для создания программ, взаимодействующих с базой данных. Применяя генератор приложений, можно сократить время, необходимое для проектирования полного объема требуемого прикладного программного обеспечения. Генераторы приложений обычно состоят из предварительно созданных модулей, содержащих фундаментальные функции, которые требуются для работы большинства программ. Эти модули, обычно создаваемые на языках высокого уровня, образуют "библиотеку" доступных функций. Пользователь указывает, какие задачи программа должна выполнить, а генератор приложений определяет, как их следует выполнить.
СУБД обладают как многообещающими потенциальными преимуществами, так и недостатками.
Преимущества:
Контроль за избыточностью данных.
Непротиворечивость данных.
Больше полезной информации при том же объеме хранимых данных.
Совместное использование данных.
Поддержка целостности данных.
Повышенная безопасность.
Применение стандартов.
Повышение эффективности с ростом масштабов системы.
Возможность нахождения компромисса при противоречивых требованиях.
Повышение доступности данных и их готовности к работе.
Улучшение показателей производительности.
Упрощение сопровождения системы за счет независимости от данных.
Улучшенное управление параллельностью.
Развитые службы резервного копирования и восстановления.
Недостатки
Сложность.
Размер.
Стоимость СУБД.
Дополнительные затраты на аппаратное обеспечение.
Затраты на преобразование.
Производительность.
Более серьезные последствия при выходе системы из строя.
По объему управляемых данных СУБД можно разделить на настольные системы и системы управления корпоративными ресурсами. К числу настольных систем относятся такие СУБД, как MS Access, Paradox, FoxPro. СУБД, использующиеся для работы с большими объемами данных являются Oracle, SQL Server, DBase. В небольших компаниях и офисах наиболее часто используется СУБД MS Access.
Современные технологии баз и банков данных
К современным технологиям обработки данных относится:
распределенная обработка;
системы Клиент-Сервер;
интегрированные (федеративные) системы;
мультибазы данных;
объектно-ориентированные базы данных.
А. Распределенная обработка предполагает, что определенная задача, обрабатывающая данные может быть распределена на нескольких участках сети. Необходимо понимать разницу между распределенной и параллельной обработкой. При параллельной обработке характерно когда машины с физической точки зрения расположены близко друг к другу. А при распределенной обработке это совсем необязательно и зачастую бывает, что машины удалены на значительные расстояния. Связь между машинами осуществляется с помощью сети и специального программного обеспечения управления сетью (см. Рис.33).
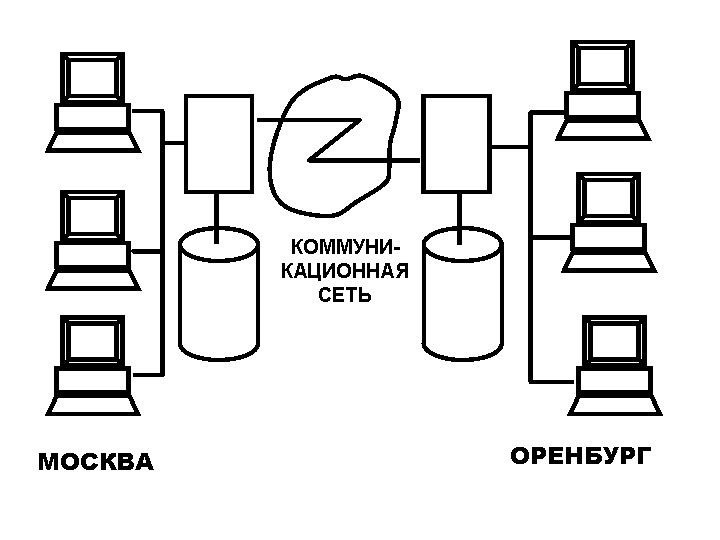
Рисунок 33 – Распределенная система баз данных
Чаще всего бывает, что узлы при распределенной обработке распределены физически, а также географически, хотя в действительности достаточно, чтобы они были распределены логически.
Необходимость распределенной обработки объясняется тем, что крупные предприятия, как правило, имеют распределенную структуру, по крайней мере они распределены логически (по видам деятельности: на бухгалтерию, склад и т.д.) и физически (на отделы, группы, лаборатории и т.д.). Из этого следует, что данные в них также распределены, поскольку на каждом уровне ведется работа с данными, относятся к этому уровню. Таким образом, в распределенной системе можно отобразить структуру предприятия с помощью соответствующей структуры БД, т.е. данные локального значения могут храниться локально, что в наибольшей мере отвечает логической структуре системы, тогда как доступ к удаленным данным осуществляется по мере необходимости.
Системы типа «Клиент-Сервер» могут рассматриваться как особый случай распределенной обработки. Точнее, система К-С сама является распределенной, в которой одни узлы являются клиентами, а другие серверами. Все данные хранятся на серверах, все приложения исполняются клиентами, а места их соединения скрыты от пользователя (см. Рис.34).
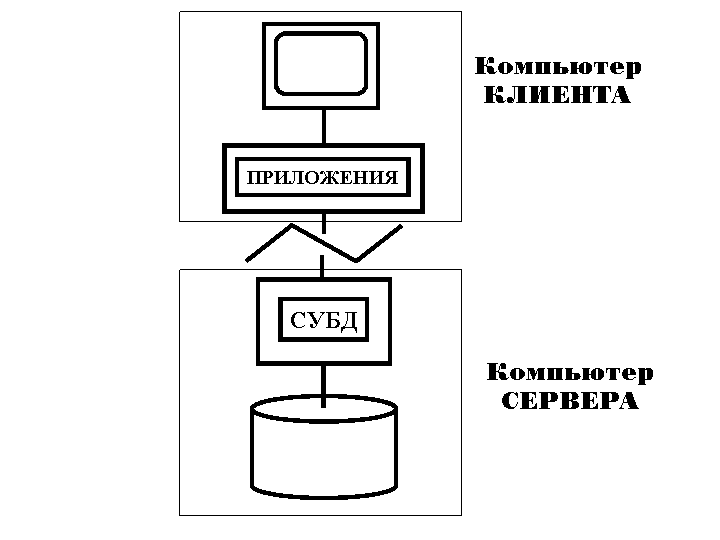
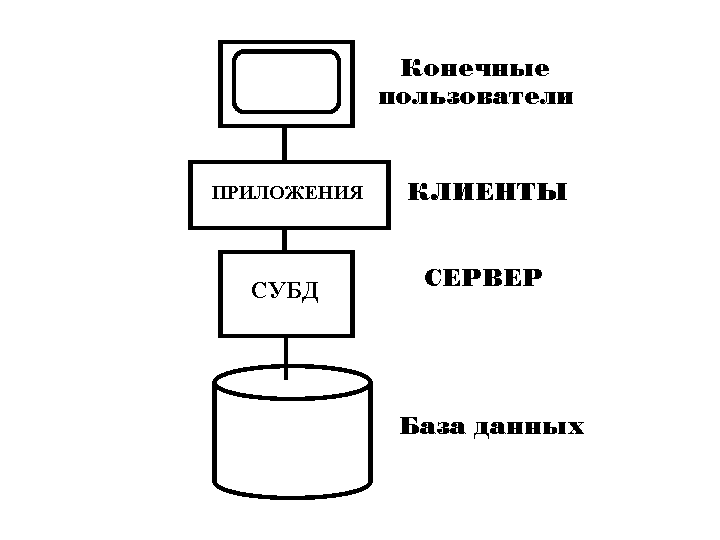
Рисунок 34 – Система Клиент-Сервер
Интегрированные (федеративные) системы и мультибазы данных.
Направление интегрированных или федеративных систем неоднородных БД и мульти-БД появилось в связи с необходимостью комплексирования систем БД, основанных на разных моделях данных и управляемых разными СУБД.
Основной задачей интеграции неоднородных БД является предоставление пользователям интегрированной системы глобальной схемы БД, представленной в некоторой модели данных, и автоматическое преобразование операторов манипулирования БД глобального уровня в операторы, понятные соответствующим локальным СУБД. В теоретическом плане проблемы преобразования решены, имеются реализации.
При строгой интеграции неоднородных БД локальные системы БД утрачивают свою автономность. После включения локальной БД в федеративную систему все дальнейшие действия с ней, включая администрирование, должны вестись на глобальном уровне. Поскольку пользователи часто не соглашаются утрачивать локальную автономность, желая тем не менее иметь возможность работать со всеми локальными СУБД на одном языке и формулировать запросы с одновременным указанием разных локальных БД, развивается направление мульти-БД. В системах мульти-БД не поддерживается глобальная схема интегрированной БД и применяются специальные способы именования для доступа к объектам локальных БД. Как правило, в таких системах на глобальном уровне допускается только выборка данных. Это позволяет сохранить автономность локальных БД.
Как правило, интегрировать приходится неоднородные БД, распределенные в вычислительной сети. Это в значительной степени усложняет реализацию. Дополнительно к собственным проблемам интеграции приходится решать все проблемы, присущие распределенным СУБД: управление глобальными транзакциями, сетевую оптимизацию запросов и т.д. Очень трудно добиться эффективности.
Как правило, для внешнего представления интегрированных и мульти-БД используется (иногда расширенная) реляционная модель данных. В последнее время все чаще предлагается использовать объектно-ориентированные модели, но на практике пока основой является реляционная модель. Поэтому, в частности, включение в интегрированную систему локальной реляционной СУБД существенно проще и эффективнее, чем включение СУБД, основанной на другой модели данных.
Объектно-ориентированные базы данных.
Направление объектно-ориентированных баз данных (ООБД) возникло сравнительно давно (середине 1980-х). Возникновение направления ООБД определяется прежде всего потребностями практики: необходимостью разработки сложных информационных прикладных систем, для которых технология предшествующих систем БД не была вполне удовлетворительной.
В наиболее общей и классической постановке объектно-ориентированный подход базируется на следующих концепциях:
объекта и идентификатора объекта;
атрибутов и методов;
классов;
иерархии и наследования классов.
Любая сущность реального мира в объектно-ориентированных языках и системах моделируется в виде объекта. Любой объект при своем создании получает генерируемый системой уникальный идентификатор, который связан с объектом все время его существования и не меняется при изменении состояния объекта.
Каждый объект имеет состояние и поведение. Состояние объекта - набор значений его атрибутов. Поведение объекта - набор методов (программный код), оперирующих над состоянием объекта. Значение атрибута объекта - это тоже некоторый объект или множество объектов. Состояние и поведение объекта инкапсулированы в объекте; взаимодействие объектов производится на основе передачи сообщений и выполнении соответствующих методов.
Наиболее важным новым качеством ООБД, которого позволяет достичь объектно-ориентированный подход, является поведенческий аспект объектов. В прикладных информационных системах, основанных на БД с традиционной организации (вплоть до тех, которые базировались на семантических моделях данных), существовал принципиальный разрыв между структурной и поведенческой частями. Структурная часть системы поддерживалась всем аппаратом БД, ее можно было моделировать, верифицировать и т.д., а поведенческая часть создавалась изолированно. В частности, отсутствовали формальный аппарат и системная поддержка совместного моделирования и гарантирования согласованности этих структурной (статической) и поведенческой (динамической) частей. В среде ООБД проектирование, разработка и сопровождение прикладной системы становится процессом, в котором интегрируются структурный и поведенческий аспекты. Конечно, для этого нужны специальные языки, позволяющие определять объекты и создавать на их основе прикладную систему.
4. Реляционная модель данных
Терминология реляционная модель данных
Реляционная модель основана на математическом понятии отношения, физическим представлением которого является таблица.
Отношение – это плоская таблица, состоящая из столбцов и строк.
В любой реляционной СУБД предполагается, что пользователь воспринимает базу данных как набор таблиц. Однако следует подчеркнуть, что это восприятие относится только к логической структуре базы данных, т.е. ко внешнему и концептуальному уровням архитектуры. Подобное восприятие не относится к физической структуре базы данных, которая может быть реализована с помощью различных структур хранения.
Атрибут – это поименованный столбец отношения.
В реляционной модели отношения используются для хранения информации об объектах, представленных в базе данных. Отношение обычно имеет вид двумерной таблицы, в которой строки соответствуют отдельным записям, а столбцы – атрибутам. При этом атрибуты могут располагаться в любом порядке – независимо от их переупорядочивания отношение будет оставаться одним и тем же, а потому иметь тот же смысл.
Домены в реляционной модели представляют собой множество значений атрибутов. Каждый атрибут реляционной базы данных определяется на некотором домене. Домены могут отличаться для каждого из атрибутов, но два и более атрибутов могут определяться на одном и том же домене. Понятие домена позволяет централизованно определять смысл и источник значений, которые могут получать атрибуты. В результате при выполнении реляционной операции системе доступно больше информации, что позволяет ей избежать семантически некорректных операций. Например, бессмысленно сравнивать название улицы с номером телефона, даже если для обоих этих атрибутов определениями доменов являются символьные строки. С другой стороны, помесячная арендная плата объекта недвижимости и количество месяцев, в течение которых он сдавался в аренду, принадлежат разным доменам (первый атрибут имеет денежный тип, а второй – целочисленный). Однако умножение значений из этих доменов является допустимой операцией. Как следует из этих двух примеров, обеспечить полную реализацию понятия домена совсем непросто, а потому во многих РСУБД они поддерживаются не полностью, а лишь частично.
Элементами отношения являются кортежи, или строки, таблицы. Кортежи могут располагаться в любом порядке, при этом отношение будет оставаться тем же самым, а значит, и иметь тот же смысл.
Описание структуры отношения вместе со спецификацией доменов и любыми другими ограничениями возможных значений атрибутов иногда называют его заголовком (или содержанием (intension)). Обычно оно является фиксированным, до тех пор, пока смысл отношения не изменяется за счет добавления в него дополнительных атрибутов. Кортежи называются расширением (extension), состоянием (state) или телом отношения, которое постоянно меняется.
Степень отношения определяется количеством атрибутов, которое оно содержит. Отношение с двумя атрибутами называется бинарным (binary), отношение с тремя атрибутами – тернарным (ternary), а для отношений с большим количеством атрибутов используется термин n-арный (n-аrу). Определение степени отношения является частью заголовка отношения.
Кардинальность – это количество кортежей, которое содержит отношение. Эта характеристика меняется при каждом добавлении или удалении кортежей. Кардинальность является свойством тела отношения и определяется текущим состоянием отношения в произвольно взятый момент.
Таким образом, реляционная база данных – это набор нормализованных отношений.
Реляционная база данных состоит из отношений, структура которых определяется с помощью особых методов, называемых нормализацией (normalization).
Отношения в базе данных
Отношение обладает следующими характеристиками:
отношение имеет имя, которое отличается от имен всех других отношений;
каждая ячейка отношения содержит только атомарное (неделимое) значение;
каждый атрибут имеет уникальное имя;
значения атрибута берутся из одного и того же домена;
порядок следования атрибутов не имеет никакого значения;
каждый кортеж является уникальным, т.е. дубликатов кортежей быть не может;
теоретически порядок следования кортежей в отношении не имеет никакого значения (однако, практически этот порядок может существенно повлиять на эффективность доступа к ним).
Отношение не может содержать кортежей-дубликатов, т.е. каждая строка должна быть обязательно уникальной.
Реляционные ключи
Необходимо иметь возможность уникальной идентификации каждого отдельного кортежа отношения по значениям его атрибутов.
Суперключ (superkey) (иначе – первичный (Primary key))– атрибут или множество атрибутов, которое единственным образом идентифицирует кортеж данного отношения.
Если ключ состоит из нескольких атрибутов, то он называется составным ключом.
Поскольку отношение не содержит кортежей-дубликатов, всегда можно уникальным образом идентифицировать каждую его строку. Это значит, что отношение всегда имеет первичный ключ. В худшем случае все множество атрибутов может использоваться как первичный ключ, но обычно, чтобы различить кортежи, достаточно использовать несколько меньшее подмножество атрибутов.
Внешний ключ – это атрибут или множество атрибутов внутри отношения, которое соответствует потенциальному ключу некоторого (может быть, того же самого) отношения.
Если некий атрибут присутствует в нескольких отношениях, то его наличие обычно отражает определенную связь между кортежами этих отношений.
Нормализация данных в БД
Нормализация – это разбиение сущности на две или более, обладающих лучшими свойствами при включении, изменении и удалении данных. Окончательная цель нормализации сводится к получению такого вида базы данных, в котором каждый факт появляется лишь в одном месте, т.е. исключена избыточность информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных.
Всякая нормализованная сущность автоматически считается сущностью в G:\DOCUMENTS\Реляционные базы данных\normalпервой нормальной форме (1НФ). Помимо 1НФ существуют следующие уровни нормализации – вторая нормальная форма (2НФ), третья нормальная форма (3НФ) и т.д. По существу, таблица находится в 2НФ, если она находится в 1НФ и удовлетворяет, кроме того, некоторому дополнительному условию, суть которого будет рассмотрена ниже.
Сущность находится в 3НФ, если она находится в 2НФ и, помимо этого, удовлетворяет еще другому дополнительному условию и т.д. Таким образом, каждая нормальная форма является в некотором смысле более ограниченной, но и более желательной, чем предшествующая.
Теория нормализации основывается на наличии той или иной зависимости между экземплярами сущностей. Определены два вида таких зависимостей: функциональные и многозначные.
Функциональная зависимость. Атрибут В таблицы функционально зависит от атрибута А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений атрибута А обязательно существует только одно из различных значений атрибута В. При этом здесь допускается, что атрибуты А и В могут быть составными.
Полная функциональная зависимость. Атрибут В находится в полной функциональной зависимости от составного атрибута А, если оно функционально зависит от А и не зависит функционально от любого подмножества атрибута А.
Многозначная зависимость. Атрибут А многозначно определяет атрибут В той же сущности, если для каждого значения атрибута А существует хорошо определенное множество соответствующих значений В.
Таблица 5 - Исходное отношение
Сотрудник |
Отдел |
Проект |
||||
Н_СОТР |
ФАМ |
Н_ОТД |
ТЕЛ |
Н_ПРО |
ПРОЕКТ |
Н_ЗАДАН |
1 |
Иванов |
1 |
11-22-33 |
1 |
Космос |
1 |
1 |
Иванов |
1 |
11-22-33 |
2 |
Климат |
1 |
2 |
Петров |
1 |
11-22-33 |
1 |
Космос |
2 |
3 |
Сидоров |
2 |
33-22-11 |
1 |
Космос |
3 |
3 |
Сидоров |
2 |
33-22-11 |
2 |
Климат |
2 |
Сущность находится в первой нормальной форме (1НФ) тогда и только тогда, когда все ее атрибуты просты, т.е. неделимы.
Таблица 6
Н_СОТР |
ФАМ |
Н_ОТД |
ТЕЛ |
Н_ПРО |
ПРОЕКТ |
Н_ЗАДАН |
1 |
Иванов |
1 |
11-22-33 |
1 |
Космос |
1 |
1 |
Иванов |
1 |
11-22-33 |
2 |
Климат |
1 |
2 |
Петров |
1 |
11-22-33 |
1 |
Космос |
2 |
3 |
Сидоров |
2 |
33-22-11 |
1 |
Космос |
3 |
3 |
Сидоров |
2 |
33-22-11 |
2 |
Климат |
2 |
Сущность находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее экземпляры, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом.
Таблица 7
-
Н_СОТР
ФАМ
Н_ОТД
ТЕЛ
1
Иванов
1
11-22-33
2
Петров
1
11-22-33
3
Сидоров
2
33-22-11
Таблица 8
-
Н_ПРО
ПРОЕКТ
1
Космос
2
Климат
Таблица 9
-
Н_СОТР
Н_ПРО
Н_ЗАДАН
1
1
1
1
2
1
2
1
2
3
1
3
3
2
2
Сущность находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и не один из ее неключевых экземпляров не зависит функционально от любого другого неключевого экземпляра. Таблица находится в нормальной форме Бойса-Кодда (НФБК), если и только если любая функциональная зависимость между его полями сводится к полной функциональной зависимости от возможного ключа.
Таблица 10
-
Н_СОТР
ФАМ
Н_ОТД
1
Иванов
1
2
Петров
1
3
Сидоров
2
Таблица 11
-
Н_ОТД
ТЕЛ
1
11-22-33
2
33-22-11
В следующих нормальных формах (4НФ и 5НФ) учитываются не только функциональные, но и многозначные зависимости между экземплярами сущностей. Для их описания используется понятие полной декомпозиции сущности.
Полной декомпозицией сущности называют такую совокупность произвольного числа ее проекций, соединение которых полностью совпадает с содержимым сущности.
Сущность находится в пятой нормальной форме (5НФ) тогда и только тогда, когда в каждой ее полной декомпозиции все проекции содержат возможный ключ. Сущность, не имеющая ни одной полной декомпозиции, также находится в 5НФ.
Четвертая нормальная форма (4НФ) является частным случаем 5НФ, когда полная декомпозиция должна быть соединением ровно двух проекций.
Процедура нормализации основывается на том, что единственными функциональными зависимостями в любой сущности должны быть зависимости вида K→F, где K – первичный ключ, а F – некоторый экземпляр этой сущности. При этом, как следует из определения первичного ключа сущности, в соответствии с которым K→F всегда имеет место для всех экземпляров данной сущности. «Один факт в одном месте» говорит о том, что не имеют силы никакие другие функциональные зависимости.
Цель нормализации состоит именно в том, чтобы избавиться от всех «других» функциональных зависимостей, т.е. таких, которые имеют иной вид, чем K→F.
Реляционная целостность
Поскольку каждый атрибут связан с некоторым доменом, для множества допустимых значений каждого атрибута отношения определяются так называемые ограничения домена. Помимо этого, задаются два важных правила целостности, которые, по сути, являются ограничениями для всех допустимых состояний базы данных. Эти два основных правила реляционной модели называются целостностью сущностей и ссылочной целостностью. Однако, прежде чем приступить к изучению этих правил, следует рассмотреть понятие NULL.
Определитель NULL – указывает, что значение атрибута в настоящий момент неизвестно (т.е. отсутствует, неопределенно) или неприемлемо для этого кортежа.
Определитель NULL следует воспринимать как логическую величину "неизвестно". Другими словами, либо это значение не входит в область определения некоторого кортежа, либо никакое значение еще не задано. Ключевое слово NULL представляет собой способ обработки неполных или необычных данных. Однако определитель NULL не следует понимать как нулевое численное значение или заполненную пробелами текстовую строку. Нули и пробелы представляют собой некоторые значения, тогда как ключевое слово NULL призвано обозначать отсутствие какого-либо значения.
Применение определителя NULL может вызвать проблемы на этапе реализации. Трудности возникают из-за того, что реляционная модель основана на исчислении предикатов первого порядка, которое обладает двузначной, или булевой, логикой, т.е. допустимыми являются только два значения: истина и ложь. Применение определителя NULL означает, что придется вести работу с логикой более высокого порядка, например трехзначной или даже четырехзначной.
Целостность сущностей
Первое ограничение целостности касается первичных ключей базовых отношений. Здесь базовое отношение определяется как отношение, которое соответствует некоторой сущности в концептуальной схеме.
Целостность сущностей означает, что в базовом отношении ни один атрибут первичного ключа не может содержать отсутствующих значений, обозначаемых определителем NULL.
По определению, первичный ключ – это минимальный идентификатор, который используется для уникальной идентификации кортежей. Это значит, что никакое подмножество первичного ключа не может быть достаточным для уникальной идентификации кортежей. Если допустить присутствие определителя NULL в любой части первичного ключа, это равноценно утверждению, что не все его атрибуты необходимы для уникальной идентификации кортежей, что противоречит определению первичного ключа.
Второе ограничение целостности касается внешних ключей.
Ссылочная целостность предполагает, что если в отношении существует внешний ключ, то значение внешнего ключа должно либо соответствовать значению потенциального ключа некоторого кортежа в его базовом отношении, либо задаваться определителем NULL.
5. Логическая модель БД
Проектирование логической модели БД целесообразно проводить с помощью ER-диаграммами (диаграмм Сущность-Связь). В данном вопросе рассматривается нотация ER-диаграмм и основные методы семантического моделирования данных.
Основные понятия ER-диаграмм
Определение 1. Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели.
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе.
Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник", "Накладная".
Каждая сущность в модели изображается в виде прямоугольника с наименованием:

Рисунок 35
Определение 2. Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности "Сотрудник" может быть "Сотрудник Иванов".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Определение 3. Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности:

Рисунок 36
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность:
Определение 4. Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из ключа нарушается его уникальность.
Сущность может иметь несколько различных ключей.
Ключевые атрибуты изображаются на диаграмме подчеркиванием:

Рисунок 37
Определение 5. Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою.
Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Например, связи между сущностями могут выражаться следующими фразами - "СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности:

Рисунок 38
Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Каждая связь может иметь один из следующих типов связи:
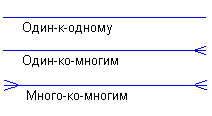
Рисунок 39
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней.
Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности. Мощность связей может подписываться у концов связи (например, 1-к-5).
Каждая связь может иметь одну из двух модальностей связи:
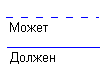
Рисунок 40
Модальность "может" означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность "должен" означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности.
Пример разработки простой ER-модели
При разработке ER-моделей мы должны получить следующую информацию о предметной области:
Список сущностей предметной области.
Список атрибутов сущностей.
Описание взаимосвязей между сущностями.
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным. Разработав первый приближенный вариант диаграмм, мы уточняем их, опрашивая экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Предположим, что перед нами стоит задача разработать информационную систему по заказу некоторой оптовой торговой фирмы. В первую очередь мы должны изучить предметную область и процессы, происходящие в ней. Для этого мы опрашиваем сотрудников фирмы, читаем документацию, изучаем формы заказов, накладных и т.п.
Например, в ходе беседы с менеджером по продажам, выяснилось, что он (менеджер) считает, что проектируемая система должна выполнять следующие действия:
Хранить информацию о покупателях.
Печатать накладные на отпущенные товары.
Следить за наличием товаров на складе.
Выделим все существительные в этих предложениях - это будут потенциальные кандидаты на сущности и атрибуты, и проанализируем их (непонятные термины будем выделять знаком вопроса):
Покупатель - явный кандидат на сущность.
Накладная - явный кандидат на сущность.
Товар - явный кандидат на сущность
(?)Склад - а вообще, сколько складов имеет фирма? Если несколько, то это будет кандидатом на новую сущность.
(?)Наличие товара – это, скорее всего, атрибут, но атрибут какой сущности?
Сразу возникает очевидная связь между сущностями - "покупатели могут покупать много товаров" и "товары могут продаваться многим покупателям". Первый вариант диаграммы выглядит так:
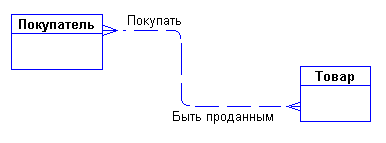
Рисунок 41
Задав дополнительные вопросы менеджеру, мы выяснили, что фирма имеет несколько складов. Причем, каждый товар может храниться на нескольких складах и быть проданным с любого склада.
Куда поместить сущности "Накладная" и "Склад" и с чем их связать? Спросим себя, как связаны эти сущности между собой и с сущностями "Покупатель" и "Товар"? Покупатели покупают товары, получая при этом накладные, в которые внесены данные о количестве и цене купленного товара. Каждый покупатель может получить несколько накладных. Каждая накладная обязана выписываться на одного покупателя. Каждая накладная обязана содержать несколько товаров (не бывает пустых накладных). Каждый товар, в свою очередь, может быть продан нескольким покупателям через несколько накладных. Кроме того, каждая накладная должна быть выписана с определенного склада, и с любого склада может быть выписано много накладных. Таким образом, после уточнения, диаграмма будет выглядеть следующим образом:
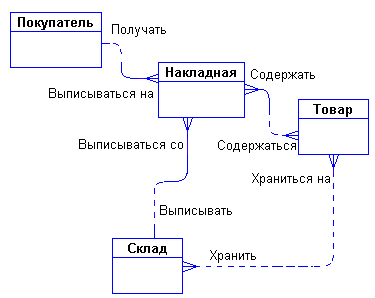
Рисунок 42
Пора подумать об атрибутах сущностей. Беседуя с сотрудниками фирмы, мы выяснили следующее:
Каждый покупатель является юридическим лицом и имеет наименование, адрес, банковские реквизиты.
Каждый товар имеет наименование, цену, а также характеризуется единицами измерения.
Каждая накладная имеет уникальный номер, дату выписки, список товаров с количествами и ценами, а также общую сумму накладной. Накладная выписывается с определенного склада и на определенного покупателя.
Каждый склад имеет свое наименование.
Снова выпишем все существительные, которые будут потенциальными атрибутами, и проанализируем их:
Юридическое лицо - термин риторический, мы не работаем с физическими лицами. Не обращаем внимания.
Наименование покупателя - явная характеристика покупателя.
Адрес - явная характеристика покупателя.
Банковские реквизиты - явная характеристика покупателя.
Наименование товара - явная характеристика товара.
(?)Цена товара - похоже, что это характеристика товара. Отличается ли эта характеристика от цены в накладной?
Единица измерения - явная характеристика товара.
Номер накладной - явная уникальная характеристика накладной.
Дата накладной - явная характеристика накладной.
(?)Список товаров в накладной - список не может быть атрибутом. Вероятно, нужно выделить этот список в отдельную сущность.
(?)Количество товара в накладной - это явная характеристика, но характеристика чего? Это характеристика не просто "товара", а "товара в накладной".
(?)Цена товара в накладной - опять же это должна быть не просто характеристика товара, а характеристика товара в накладной. Но цена товара уже встречалась выше - это одно и то же?
Сумма накладной - явная характеристика накладной. Эта характеристика не является независимой. Сумма накладной равна сумме стоимостей всех товаров, входящих в накладную.
Наименование склада - явная характеристика склада.
В ходе дополнительной беседы с менеджером удалось прояснить различные понятия цен. Оказалось, что каждый товар имеет некоторую текущую цену. Эта цена, по которой товар продается в данный момент. Естественно, что эта цена может меняться со временем. Цена одного и того же товара в разных накладных, выписанных в разное время, может быть различной. Таким образом, имеется две цены - цена товара в накладной и текущая цена товара.
С возникающим понятием "Список товаров в накладной" все довольно ясно. Сущности "Накладная" и "Товар" связаны друг с другом отношением типа много-ко-многим. Такая связь, как мы отмечали ранее, должна быть расщеплена на две связи типа один-ко-многим. Для этого требуется дополнительная сущность. Этой сущностью и будет сущность "Список товаров в накладной". Связь ее с сущностями "Накладная" и "Товар" характеризуется следующими фразами - "каждая накладная обязана иметь несколько записей из списка товаров в накладной", "каждая запись из списка товаров в накладной обязана включаться ровно в одну накладную", "каждый товар может включаться в несколько записей из списка товаров в накладной", " каждая запись из списка товаров в накладной обязана быть связана ровно с одним товаром". Атрибуты "Количество товара в накладной" и "Цена товара в накладной" являются атрибутами сущности " Список товаров в накладной".
Точно также поступим со связью, соединяющей сущности "Склад" и "Товар". Введем дополнительную сущность "Товар на складе". Атрибутом этой сущности будет "Количество товара на складе". Таким образом, товар будет числиться на любом складе и количество его на каждом складе будет свое.
Теперь можно внести все это в диаграмму:
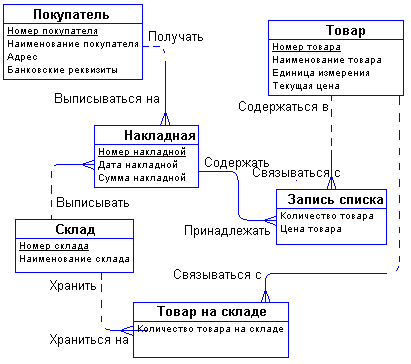
Рисунок 43
Разработанная ER-диаграмма является примером концептуальной диаграммы, т.е. диаграмма не учитывает особенности конкретной СУБД, а отражает лишь логику информационной зависимости данных предметной области. По данной концептуальной диаграмме можно построить физическую диаграмму, которая уже будут учитываться такие особенности СУБД.
6. Реализация логической модели БД в среде СУБД
Реализация логической модели БД основывается на учете особенностей конкретной СУБД. Технологически данная операция выполняется в соответствии со следующими этапами:
Выбор СУБД.
Проектирование таблиц БД.
Разработка схемы связей таблиц БД.
Ввод данных.
Разработка запросов, пользовательских интерфейсов и форм отчетов по работе с БД.
При выборе СУБД для реализации базы данных необходимо руководствоваться следующими требованиями:
простота использования и освоения;
поддержка реляционной модели данных;
возможность реализации и управления правами доступа;
поддержка стандарта SQL;
поддержка объектов данных (индексов, запросов и т.п.);
установленные системные требования к аппаратному обеспечению и операционной среде;
поддержка работы, как в сетевом варианте, так и на локальной машине;
возможность резервного копирования и восстановления БД после аппаратных и программных сбоев.
Далее в качестве предпочтительной СУБД рассматривается MS Access. Данная СУБД имеет следующую пользовательскую структуру.
Microsoft Access позволяет управлять всеми сведениями из одного файла базы данных. В рамках этого файла используются следующие объекты:
таблицы для сохранения данных;
запросы для поиска и извлечения только требуемых данных;
формы для просмотра, добавления и изменения данных в таблицах;
отчеты для анализа и печати данных в определенном формате;
страницы доступа к данным для просмотра, обновления и анализа данных из базы данных через Интернет или интрасеть;
макросы позволяют автоматизировать функции по обработке информации в таблицах БД;
модули предназначены для создания программ обработки данных с использованием VBA.
Рисунок 44
Данные сохраняются один раз в одной таблице, но просматриваются из различных расположений. При изменении данных они автоматически обновляются везде, где появляются.
Таблицы и связи
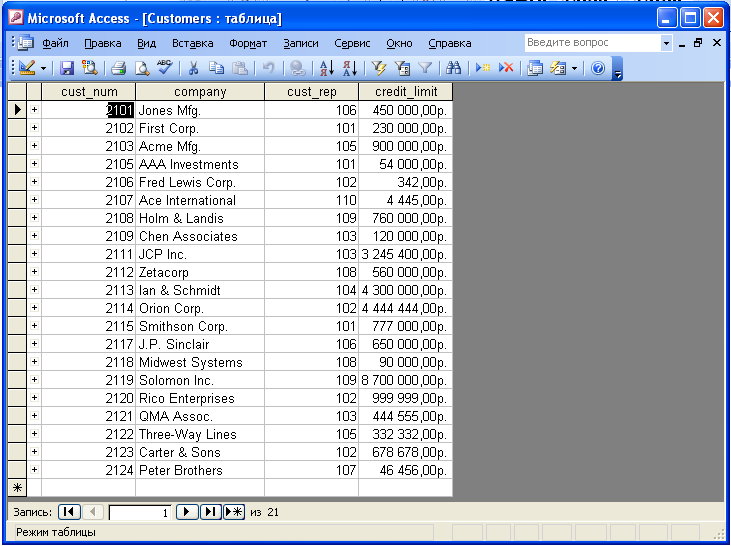
Рисунок 45
Таблица MS Access является обычной двумерной реляционной таблицей. Каждая таблица состоит из полей и записей. Поля образуют столбцы таблицы, а записи – строки. Каждое поле имеет свой тип данных, т.е. характеристику поля, определяющую, какие данные могут сохраняться в поле. Всего в MS Access предусмотрены следующие типы данных:
Текстовый
Текст или комбинация текста и чисел, например, адреса, а также числа, не требующие вычислений, например, номера телефонов, инвентарные номера или почтовые индексы.
Сохраняет до 255 знаков. Свойство Размер поля (FieldSize) определяет максимальное количество знаков, которые можно ввести в поле.
Поле МЕМО
Длинный текст или числа, например, примечания или описания.
Сохраняет до 65536 знаков.
Числовой
Данные, используемые для математических вычислений, за исключением финансовых расчетов (для них следует использовать тип «Денежный»).
Сохраняет 1, 2, 4 или 8 байтов; 16 байтов для кодов репликации (GUID). Конкретный тип числового поля определяется значением свойства Размер поля (FieldSize).
Дата/время
Значения дат и времени.
Сохраняет 8 байтов.
Денежный
Используется для денежных значений и для предотвращения округления во время вычислений.
Сохраняет 8 байтов.
Счетчик
Автоматическая вставка уникальных последовательных (увеличивающихся на 1) или случайных чисел при добавлении записи.
Сохраняет 4 байта; 16 байтов для кодов репликации (GUID).
Логический
Данные, принимающие только одно из двух возможных значений, таких как «Да/Нет», «Истина/Ложь», «Вкл/Выкл». Значения Null не допускаются.
Сохраняет 1 бит.
Поле объекта OLE
Объекты OLE (такие как документы Microsoft Word, электронные таблицы Microsoft Excel, рисунки, звукозапись или другие данные в двоичном формате), созданные в других программах, использующих протокол OLE.
Сохраняет до 1 Гигабайта (ограничивается объемом диска).
Гиперссылка
Гиперссылки. Гиперссылка может иметь вид пути UNC либо адреса URL.
Сохраняет до 64 000 знаков.
Мастер подстановок
Создает поле, позволяющее выбрать значение из другой таблицы или из списка значений, используя поле со списком. При выборе данного параметра в списке типов данных запускается мастер для автоматического определения этого поля.
Для сохранения требуется тот же размер, что и у первичного ключа, соответствующего полю подстановок, — обычно 4 байта.
При создании таблицы задание типа поля обязательно.
Запросы
Для поиска и вывода данных, удовлетворяющих заданным условиям, включая данные из нескольких таблиц. Запрос также может обновлять или удалять несколько записей одновременно и выполнять стандартные или пользовательские вычисления с данными. Для составления запросов в MS Access используется язык SQL. При чем предусмотрена возможность генерации запроса при работе СУБД в режиме «Мастера».
Формы
Для простоты просмотра, ввода и изменения данных непосредственно в таблице создаются формы. При открытии формы Microsoft Access отбирает данные из одной или более таблиц и выводит их на экран с использованием макета, выбранного в мастере форм или созданного пользователем самостоятельно.
Отчеты
Для анализа данных или представления их определенным образом в печатном виде применяются отчеты. Например, можно напечатать один отчет, группирующий данные и вычисляющий итоговые значения, и еще один отчет с другими данными, отформатированными для печати почтовых наклеек.
Страницы доступа к данным
Чтобы сделать данные доступными через Интернет или интрасеть для создания отчетов в интерактивном режиме, ввода данных или их анализа используются страницы доступа к данным. Microsoft Access извлекает данные из одной или нескольких таблиц и отображает их на экране с использованием макета, разработанного пользователем в режиме конструктора или созданного с помощью мастера страниц.
Макросы
Макрос представляет набор макрокоманд, который создается для автоматизации часто выполняемых задач. Группа макросов позволяет выполнить несколько задач одновременно.
Макросом называют набор из одной или более макрокоманд. Макрокоманда – основной компонент макроса; замкнутая инструкция, самостоятельно или в комбинации с другими макрокомандами определяющая выполняемые в макросе действия. Макросы могут быть полезны для автоматизации часто выполняемых задач. Например, при нажатии пользователем кнопки можно запустить макрос, который распечатает отчет.
При создании макроса пользователь вводит макрокоманды, которые требуется выполнить.
Модули
Модули представляют наборы описаний, инструкций и процедур, сохраненных под общим именем для организации программ на языке Microsoft Visual Basic.
После создания в базе данных Microsoft Access управление данными выполняется ядром базы данных Microsoft Jet.
Проектирование таблиц БД.
Создание таблиц БД MS Access может быть выполнено тремя способами:
в режиме конструктора;
в режиме мастера;
путем непосредственного ввода данных в таблицу.
При выборе режима конструктора открывается диалоговое окно (см. Рис. 46.)
В этом окне необходимо определить наименования полей, тип данных каждого поля и свойства поля. Причем содержание окна определения свойств поля изменяется в зависимости от установленного типа поля. По умолчанию в окне свойства поля отображаются только обязательные свойства, но часто бывает необходимо определять и некоторые другие свойства.
Кроме того, для работы таблицы в составе БД MS Access необходимо определить первичный ключ. Для чего нужно вызвать контекстное меню и выбрать команду «Ключевое поле». Справа от названия поля появится значок ключа. Присвоив имя таблице и сохранив ее можно заносить в нее данные.
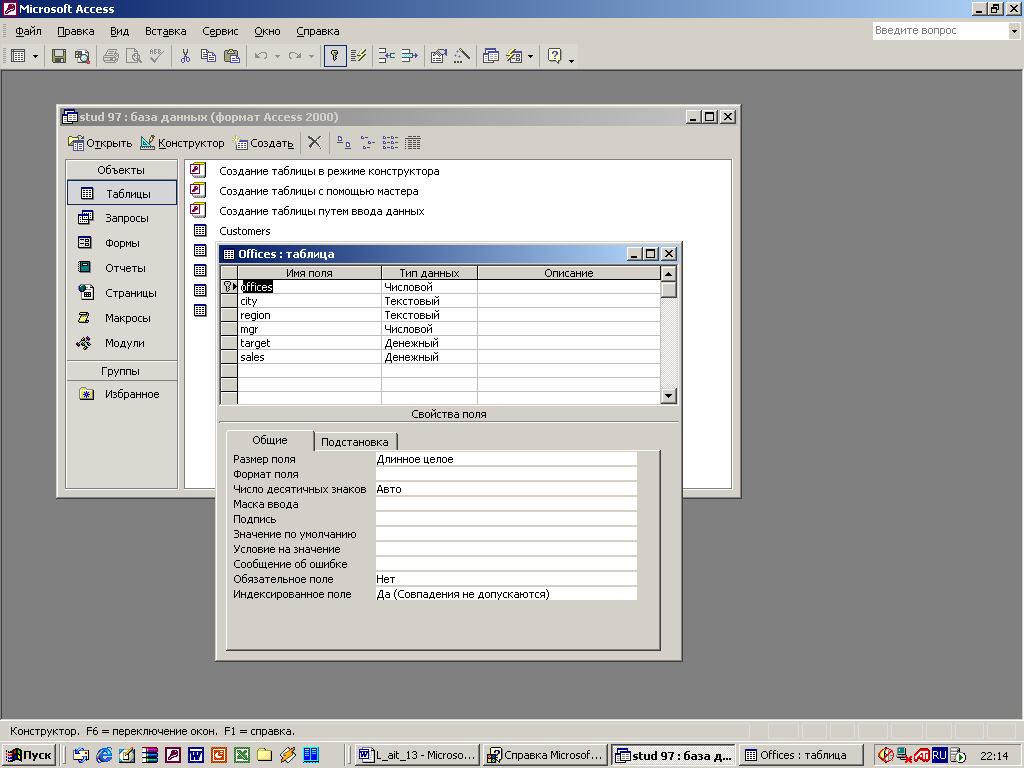
Рисунок 46
Создание таблицы БД в ежимее мастера предусматривает прохождение нескольких последовательных этапов.
1) определение структуры таблицы

Рисунок 47
На данном шаге из списка доступных образцов таблиц требуется выбрать нужный, определить поля в новой таблице (при необходимости имя поля может быть изменено). После чего перейти либо к следующему шагу работы мастера, либо нажатием кнопки «Готово» завершить его работу и получить макет таблицы.
2) определение имени таблицы и ключевого поля
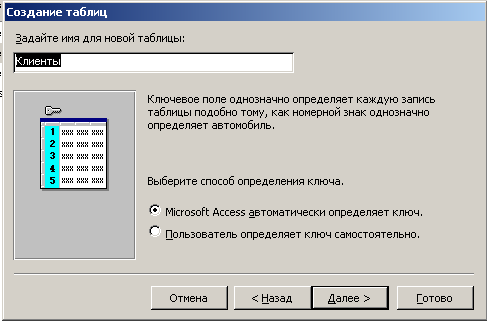
Рисунок 48
3) определение связей между таблицами БД
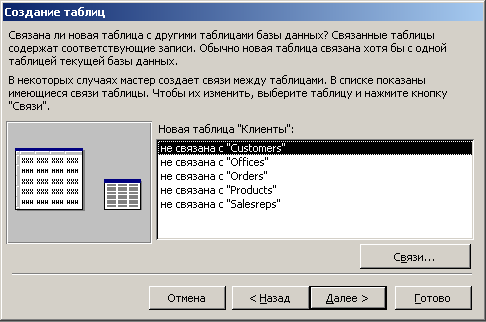
Рисунок 49
4) выбор способа вводе данных в таблицу
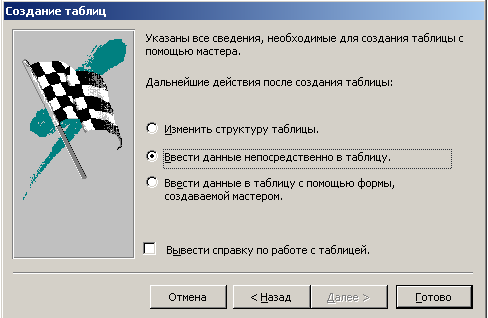
Рисунок 50
При выборе пункта «Создание таблицы путем ввода данных» открывается макет таблицы, в котором необходимо определить имена полей, и перейдя в режим мастера установить типы данных и ключевое поле таблицы.
Рисунок 51
Разработка схемы связей таблиц БД.
Определение связей между таблицами в базе данных Access
После создания в базе данных Microsoft Access отдельных таблиц по каждой теме необходимо выбрать способ, которым Microsoft Access будет вновь объединять сведения таблиц. Первым делом следует определить связи (Отношение. Связь, установленная между двумя общими полями (столбцами) двух таблиц. Существуют связи с отношением «один-к-одному», «один-ко-многим» и «многие-ко-многим».) между таблицами. После этого можно создать запросы, формы и отчеты для одновременного отображения сведений из нескольких таблиц.
Как работают связи между таблицами
Поля в таблицах должны быть скоординированы таким образом, чтобы отображать сведения одного и того же отношения. Эта координация осуществляется путем установления связей между таблицами. Связь между таблицами устанавливает отношения между совпадающими значениями в ключевых полях, обычно между полями, имеющими одинаковые имена в обеих таблицах. В большинстве случаев с ключевым полем одной таблицы, являющимся уникальным идентификатором каждой записи, связывается внешний ключ другой таблицы
Отношение «один-ко-многим»
Отношение «один-ко-многим» является наиболее часто используемым типом связи между таблицами. В отношении «один-ко-многим» каждой записи в таблице A могут соответствовать несколько записей в таблице B, но запись в таблице B не может иметь более одной соответствующей ей записи в таблице A.
Отношение «многие-ко-многим»
При отношении «многие-ко-многим» одной записи в таблице A могут соответствовать несколько записей в таблице B, а одной записи в таблице B несколько записей в таблице A. Этот тип связи возможен только с помощью третьей (связующей) таблицы, первичный ключ которой состоит из двух полей, которые являются внешними ключами таблиц A и B. Отношение «многие-ко-многим» по сути дела представляет собой два отношения «один-ко-многим» с третьей таблицей. Например, отношение «многие-ко-многим» между таблицами «Заказы» и «Товары» определяется путем создания двух отношений «один-ко-многим» с таблицей «Заказано». В одном заказе может быть много товаров, а каждый товар может появляться в нескольких заказах
Первичный ключ из таблицы «Заказы»
Первичный ключ из таблицы «Товары»
Один заказ может содержать несколько товаров, а каждый товар может содержаться в нескольких заказах.
Отношение «один-к-одному»
При отношении «один-к-одному» каждая запись в таблице A может иметь не более одной связанной записи в таблице B и наоборот. Отношения этого типа используются не очень часто, поскольку большая часть сведений, связанных таким образом, может быть помещена в одну таблицу. Отношение «один-к-одному» может использоваться для разделения таблиц, содержащих много полей, для отделения части таблицы по соображениям безопасности, а также для сохранения сведений, относящихся к подмножеству записей в главной таблице. Например, можно создать таблицу для отслеживания участия сотрудников в благотворительных спортивных мероприятиях. Каждому игроку в таблице «Футболисты» должна соответствовать одна запись в таблице «Сотрудники».
Определение связей между таблицами
Тип отношения в создаваемой Microsoft Access связи зависит от способа определения связываемых полей.
Отношение «один-ко-многим» создается в том случае, когда только одно из полей является полем первичного ключа или уникального индекса (Уникальный индекс. Индекс, определенный для поля с заданным для свойства Индексированное поле (Indexed) значением Да (Совпадения не допускаются). При этом ввод в индексированное поле повторяющихся значений становится невозможным. Для ключевых полей уникальный индекс создается автоматически.).
Отношение «один-к-одному» создается в том случае, когда оба связываемых поля являются ключевыми или имеют уникальные индексы.
Отношение «многие-ко-многим» фактически является двумя отношениями «один-ко-многим» с третьей таблицей, первичный ключ которой состоит из полей внешнего ключа двух других таблиц.

Рисунок 52
Имеется возможность связать таблицу саму с собой. Это полезно, когда нужно создать поле подстановок со значениями из этой же таблицы. Например, в таблице «Сотрудники» можно определить связь между полями «КодСотрудника» и «Подчиняется» и отображать в поле «Подчиняется» данные о сотруднике, из связанного поля «КодСотрудника».
Целостность данных
Целостность данных означает систему правил, используемых в Microsoft Access для поддержания связей между записями в связанных таблицах, а также обеспечивающих защиту от случайного удаления или изменения связанных данных. Установить целостность данных можно, если выполнены следующие условия.
Связанное поле главной таблицы (Главная таблица. Таблица на стороне «один» при связи двух таблиц с отношением «один-ко-многим». В главной таблице должен существовать первичный ключ, а все записи в ней должны быть уникальными.) является ключевым полем (Первичный ключ. Одно или несколько полей (столбцов), комбинация значений которых однозначно определяет каждую запись в таблице. Первичный ключ не допускает значений Null и всегда должен иметь уникальный индекс. Первичный ключ используется для связывания таблицы с внешними ключами в других таблицах.) или имеет уникальный индекс.
Связанные поля имеют один тип данных. Здесь существуют два исключения: поле счетчика может быть связано с числовым полем, свойство которого Размер поля (FieldSize) имеет значение Длинное целое, а также поле счетчика, свойство которого Размер поля (FieldSize) имеет значение Код репликации, можно связать с числовым полем, у которого свойство Размер поля (FieldSize) имеет значение Код репликации.
Обе таблицы принадлежат одной базе данных Microsoft Access. Если таблицы являются связанными, то они должны быть таблицами формата Microsoft Access. Для установки целостности данных база данных, в которой находятся таблицы, должна быть открыта. Для связанных таблиц из баз данных других форматов установить целостность данных невозможно.
При использовании условий целостности данных действуют следующие правила.
Невозможно ввести в поле внешнего ключа связанной таблицы значение, не содержащееся в ключевом поле главной таблицы. Однако в поле внешнего ключа возможен ввод значений Null (Null. Значение, которое можно ввести в поле или использовать в выражениях и запросах для указания отсутствующих или неизвестных данных. В Visual Basic ключевое слово Null указывает значение Null. Некоторые поля, такие как поля первичного ключа, не могут содержать значения Null.), показывающих, что записи не являются связанными. Например, нельзя сохранить запись, регистрирующую заказ, сделанный несуществующим клиентом, но можно создать запись для заказа, который пока не отнесен ни к одному из клиентов, если ввести значение Null в поле «КодКлиента».
Не допускается удаление записи из главной таблицы, если существуют связанные с ней записи в подчиненной таблице. Например, невозможно удалить запись из таблицы «Сотрудники», если в таблице «Заказы» имеются заказы, относящиеся к данному сотруднику.
Невозможно изменить значение первичного ключа в главной таблице, если существуют записи, связанные с данной записью. Например, невозможно изменить код сотрудника в таблице «Сотрудники», если в таблице «Заказы» имеются заказы, относящиеся к этому сотруднику.
Каскадное обновление и удаление
Для отношений, в которых проверяется целостность данных, пользователь имеет возможность указать, следует ли автоматически выполнять для связанных записей операции каскадного обновления (Каскадное обновление. Средство поддержания целостности данных в связанных таблицах, обеспечивающее обновление всех связанных записей в подчиненной таблице или таблицах при изменении записи в главной таблице.) и каскадного удаления (Каскадное удаление. Средство поддержания целостности данных в связанных таблицах, обеспечивающее удаление всех связанных записей в подчиненной таблице или таблицах при удалении записи в главной таблице.). Если включить данные параметры, станут возможными операции удаления и обновления, которые в противном случае запрещены условиями целостности данных. Чтобы обеспечить целостность данных при удалении записей или изменении значения первичного ключа в главной таблице, автоматически вносятся необходимые изменения в связанные таблицы.
Если при определении отношения установить флажок Каскадное обновление связанных полей, любое изменение значения первичного ключа главной таблицы приведет к автоматическому обновлению соответствующих значений во всех связанных записях. Например, при изменении кода клиента в таблице «Клиенты» будет автоматически обновлено поле «КодКлиента» во всех записях таблицы «Заказы» для заказов каждого клиента, поэтому целостность данных не будет нарушена. Microsoft Access выполнит каскадное обновление без ввода предупреждающих сообщений.
Если в главной таблице ключевым полем является поле счетчика, то установка флажка Каскадное обновление связанных полей не приведет к каким-либо результатам, так как изменить значение поля счетчика невозможно.
Если при определении отношения установить флажок Каскадное удаление связанных записей, любое удаление записи в главной таблице приведет к автоматическому удалению связанных записей в подчиненной таблице. Например, при удалении из таблицы «Клиенты» записи конкретного клиента будут автоматически удалены все связанные записи в таблице «Заказы» (а также записи в таблице «Заказано», связанные с записями в таблице «Заказы»). Если записи удаляются из формы или таблицы при установленном флажке Каскадное удаление связанных записей, Microsoft Access выводит предупреждение о возможности удаления связанных записей. Если же записи удаляются с помощью запроса на удаление, то Microsoft Access удаляет записи автоматически без вывода предупреждения.
Ввод данных.
Ввод данных производится заполнением таблиц БД информацией о предметной области. Заполнение таблиц следует начинать с таблиц, являющихся «источником» связи, т.к. при ином порядке заполнения будут появляться сообщения об ошибке нарушения целостность БД. Автоматизация ввода данных в БД может быть реализована с помощью пользовательских форм и запросов.
Разработка запросов, пользовательских интерфейсов и форм отчетов по работе с БД
Запросы используются для просмотра, изменения и анализа данных различными способами. Запросы также можно использовать в качестве источников записей для форм, отчетов и страниц доступа к данным. В Microsoft Access предусмотрены следующие типы запросов.
Запросы на выборку
Запрос на выборку является наиболее часто используемым типом запроса. Запросы этого типа возвращают данные из одной или нескольких таблиц и отображают их в виде таблицы, записи в которой можно обновлять (с некоторыми ограничениями). Запросы на выборку можно также использовать для группировки записей и вычисления сумм, средних значений, подсчета записей и нахождения других типов итоговых значений.
Запросы с параметрами
Запрос с параметрами — это запрос, при выполнении отображающий в собственном диалоговом окне приглашение ввести данные, например условие (ограничение, заданное для отбора записей, включаемых в результирующий набор записей запроса или фильтра) для возвращения записей или значение, которое требуется вставить в поле. Можно разработать запрос, выводящий приглашение на ввод нескольких единиц данных, например двух дат. Затем Microsoft Access может вернуть все записи, приходящиеся на интервал времени между этими датами.
Запросы с параметрами также удобно использовать в качестве основы для форм, отчетов и страниц доступа к данным. Например, на основе запроса с параметрами можно создать месячный отчет о доходах. При печати данного отчета Microsoft Access выводит на экран приглашение ввести месяц, доходы за который должны быть приведены в отчете. После ввода месяца Microsoft Access выполняет печать соответствующего отчета.
Перекрестные запросы
Перекрестные запросы используют для расчетов и представления данных в структуре, облегчающей их анализ. Перекрестный запрос подсчитывает сумму, среднее, число значений или выполняет другие статистические расчеты, после чего результаты группируются в виде таблицы по двум наборам данных, один из которых определяет заголовки столбцов, а другой заголовки строк.
Запросы на изменение
Запросом на изменение называют запрос, который за одну операцию изменяет или перемещает несколько записей. Существует четыре типа запросов на изменение:
на удаление записи. Запрос на удаление удаляет группу записей из одной или нескольких таблиц. Например, запрос на удаление позволяет удалить записи о товарах, поставки которых прекращены или на которые нет заказов. С помощью запроса на удаление можно удалять только всю запись, а не отдельные поля внутри нее;
на обновление записи. Запрос на обновление вносит общие изменения в группу записей одной или нескольких таблиц. Например, на 10 процентов поднимаются цены на все молочные продукты или на 5 процентов увеличивается зарплата сотрудников определенной категории. Запрос на обновление записей позволяет изменять данные в существующих таблицах;
на добавление записей. Запрос на добавление добавляет группу записей из одной или нескольких таблиц в конец одной или нескольких таблиц. Например, появилось несколько новых клиентов, а также база данных, содержащая сведения о них. Чтобы не вводить все данные вручную, их можно добавить в таблицу «Клиенты»;
на создание таблицы. Запрос на создание таблицы создает новую таблицу на основе всех или части данных из одной или нескольких таблиц. Запрос на создание таблицы полезен при создании таблицы для экспорта в другие базы данных Microsoft Access или при создания архивной таблицы, содержащей старые записи.
Запросы SQL
Запрос SQL — это запрос, создаваемый при помощи инструкций SQL. Язык SQL (Structured Query Language) используется при создании запросов, а также для обновления и управления реляционными базами данных, такими как базы данных Microsoft Access.
Когда пользователь создает запрос в режиме конструктора запроса, Microsoft Access автоматически создает эквивалентную инструкцию SQL. Фактически, для большинства свойств запроса, доступных в окне свойств в режиме конструктора, имеются эквивалентные предложения или параметры языка SQL, доступные в режиме SQL. При необходимости пользователь имеет возможность просматривать и редактировать инструкции SQL в режиме SQL. После внесения изменений в запрос в режиме SQL его вид в режиме конструктора может измениться.
Некоторые запросы, которые называют запросами SQL, невозможно создать в бланке запроса. Для запросов к серверу, управляющих запросов и запросов на объединение необходимо создавать инструкции SQL непосредственно в окне запроса в режиме SQL. Для подчиненного запроса пользователь должен ввести инструкцию SQL в строку Поле или Условие отбора в бланке запроса.
Формы являются типом объектов базы данных, которые обычно используется для отображения данных в базе данных. Форму можно также использовать как кнопочную форму, открывающую другие формы или отчеты базы данных, а также как пользовательское диалоговое окно для ввода данных и выполнения действий, определяемых введенными данными.
Большинство форм являются присоединенными к одной или нескольким таблицам и запросам из базы данных. Источником записей формы являются поля в присоединенных таблицах и запросах. Однако, форма не должна включать все поля из каждой таблицы или запроса, на основе которых она создается.
Присоединенная форма получает данные из базового источника записей. Другие выводящиеся в форме сведения, такие как заголовок, дата и номера страниц, сохраняются в макете формы.
Связь между формой и ее источником записей создается при помощи графических объектов, которые называют элементами управления. Формы можно также открывать в режиме сводной таблицы или в режиме диаграммы для анализа данных. В этих режимах возможно динамическое изменение макета формы для изменения способа представления данных. Существует возможность упорядочивать заголовки строк и столбцов, а также применять фильтры к полям. При каждом изменении макета сводная форма немедленно выполняет вычисления заново в соответствии с новым расположением данных.
Отчет является средством представления данных в печатном формате. Имея возможность управлять размером и внешним видом всех элементов отчета, пользователь может отобразить сведения желаемым образом: создание почтовых наклеек, отображение итоговых значений на диаграмме, группировка записей по категориям, расчет итоговых значений.
Большинство отчетов являются присоединенными к одной или нескольким таблицам и/или запросам из базы данных. Источником записей отчета являются поля в базовых таблицах и/или запросах. Отчет не должен включать все поля из каждой таблицы или запроса, на основе которых он создается.
Присоединенный отчет получает данные из базового источника записей. Другие данные такие как, заголовок, дата и номера страниц, сохраняются в макете отчета. Данные поступающие из выражений также сохраняются в макете отчета.
Связь между отчетом и его источником данных создается при помощи графических объектов, называемых элементами управления. Элементами управления являются поля, в которых отображаются имена и числа, надписи, в которых отображаются заголовки, а также декоративные линии, графически структурирующие данные и улучшающие внешний вид отчета.
Создать отчет в MS Access можно несколькими способами: с помощью мастера, конструктора и на основе шаблона.