

14.3. Распределенные взаимоисключения
Напомним, что в главах 5, "Параллельные вычисления: взаимоисключения и многозадачность", и 6, "Взаимоблокировка и голодание", речь шла о вопросах, связанных с выполнением параллельных процессов. Двумя основными проблемами, которые возникают при этом, являются взаимоисключение и взаимоблокировка, В указанных главах основное внимание сосредоточено на решениях указанных проблем в контексте одной системы, обладающей одним или несколькими процессорами, но единой основной памятью. В распределенной операционной системе, управляющей системой с множеством процессоров, которые не используют совместно основную память или часы, возникают новые трудности и требуются новые решения. Алгоритмы взаимоисключения и взаимоблокировки должны зависеть от обмена сообщениями и не могут зависеть от возможности доступа к общей памяти. В этом разделе и далее взаимоисключения и взаимоблокировка изучаются в контексте распределенной операционной системы.
Концепции распределенных взаимоисключений
Если два или большее количество процессов соревнуются за возможность использования системных ресурсов, нужен механизм обеспечения взаимоисключений. Предположим, что двум или большему количеству процессов нужен доступ к единому неразделяемому ресурсу, например к принтеру. Во время своей работы каждый процесс будет отдавать команды этому устройству ввода-вывода, получая информацию о его состоянии, отправляя данные и/или получая их. Такой ресурс мы будем называть критическим, а использующую его часть программы — критическим разделом программы. Важно отметить, что в каждый момент времени может выполняться критический раздел только одной программы. Понимание и воплощение этого ограничения не может основываться лишь на операционной системе, так как точные требования могут быть не очевидными. Например, принтер должен находиться под управлением процесса до тех пор, пока не будет распечатан весь файл. В противном случае в распечатанном документе будут чередоваться строки, направленные разными конкурирующими процессами.
Чтобы успешно применять параллелизм процессов, нужно иметь возможность задавать критические разделы и реализовывать взаимоисключения. Это является основой любой схемы параллельной обработки. Устройство или средство, обеспечивающее взаимоисключения, должно удовлетворять следующим требованиям.
1. Необходимо обеспечить реализацию взаимоисключения: в каждый момент времени лишь один процесс из всех тех, в которых имеются критические разделы одного и того же ресурса или совместно используемого объекта, может находиться в этом критическом разделе.
2. Если выполнение процесса прекращается не в критическом разделе, это не должно влиять на работу других процессов,
3. Нельзя, чтобы процесс, которому нужен доступ к критическому разделу, ожидал до бесконечности: нельзя допускать взаимоблокировок и голодания.
4. Если в критическом разделе нет ни одного процесса, то любой процесс, которому нужно войти в этот критический раздел, должен иметь возможность сделать это без промедления.
5. Не делается никаких предположений об относительной скорости выполнения процессов или об их количестве.
6. Процесс остается в критическом разделе лишь в течение конечного времени.
На рис. 14.7 показана модель, на примере которой можно изучать разные подходы к взаимоисключениям в контексте распределенных систем. Допустим, что некоторое количество систем соединены между собой с помощью какого-то сетевого устройства. Предположим также, что в операционной системе каждой системы имеется некоторая функция или процесс, отвечающий за распределение ресурсов. Каждый такой процесс управляет определенным количеством ресурсов и обслуживает несколько пользовательских процессов. Нужно разработать алгоритм, согласно которому эти процессы могут совместно обеспечивать взаимоисключение.

Механизм взаимоисключения может быть либо централизованным, либо распределенным. В полностью централизованном алгоритме один из узлов настраивается как управляющий; он управляет доступом ко всем совместно используемым объектам. Если какому-то процессу нужен доступ к критическому ресурсу, он генерирует запрос и отправляет его своему локальному процессу, управляющему ресурсами. Локальный управляющий процесс, в свою очередь, передает этот запрос контрольному узлу, который возвращает ответ (разрешение), когда совместно используемый объект становится доступным. Закончив работу с ресурсом, запрашивавший его процесс отправляет управляющему узлу сообщение об освобождении ресурса. Такой централизованный алгоритм обладает двумя определяющими свойствами.
1. Решения о распределении ресурсов принимает только управляющий узел.
2. Вся необходимая информация, включая сведения об идентификаторах и размещении всех ресурсов, а также о статусе распределения каждого ресурса, сосредоточена на управляющем узле.
Централизованный подход является прямолинейным; легко понять, как в нем реализуются взаимоисключения: управляющий узел не удовлетворит запрос на ресурс до тех пор, пока этот ресурс не освободится. Однако такая схема имеет ряд недостатков. При отказе управляющего узла механизм взаимоисключений разлаживается (по крайней мере, на некоторое время). Кроме того, для каждого предоставления или освобождения ресурса нужен обмен сообщениями с управляющим узлом. Таким образом, недостаточная мощность управляющего узла может тормозить работу всей распределенной системы.
Из-за этих, присущих централизованным алгоритмам, проблем, возрос интерес к разработке распределенных алгоритмов. Полностью распределенный алгоритм обладает такими свойствами [МАЕК87].
1. Каждый узел в среднем обладает одинаковым количеством информации.
2. Каждый узел имеет лишь частичные сведения обо всей системе и может принимать решения, основываясь на этих сведениях.
3. За принятие конечного решения все узлы отвечают в равной мере.
4. На осуществление конечного решения все узлы в среднем затрачивают одинаковые усилия.
5. Отказ одного из узлов не приводит к упадку всей системы.
6. В системе нет общих часов, по которым можно координировать события.
Пункты 2 и 6 требуют некоторого уточнения. Что касается пункта 2, то в некоторых распределенных алгоритмах требуется, чтобы все узлы обменивались известной им информацией. Даже в этом случае в каждый фиксированный момент времени некоторая часть информации находится в пути и может еще не дойти до всех остальных узлов. Таким образом, из-за временных задержек, возникающих при передаче сообщений, хранящаяся на каком-то отдельном узле информация не является полностью обновленной, и в этом смысле каждый узел обладает лишь частичной информацией.
Что касается пункта 6, из-за того, что обмен информацией между системами происходит с некоторой задержкой, невозможно поддерживать часы, которые были бы немедленно доступны для всех систем. Кроме того, с технической точки зрения непрактично поддерживать одни централизованные часы, по которым можно было бы точно синхронизовать все локальные часы. Однако через некоторое время в показаниях разных локальных часов возникнет расхождение, в результате чего утратится синхронизация.
Существенное усложнение механизмов взаимоисключения в распределенных системах по сравнению с централизованными вызвано задержками, возникающими при обмене информацией, а также отсутствием общих часов. Перед тем как обратиться к некоторым алгоритмам распределенного взаимоисключения, исследуем общий подход к проблеме преодоления рассогласованности часов.
Упорядочение событий в распределенной системе
Основой работы большинства распределенных алгоритмов взаимоисключений и взаимоблокировок является временное упорядочение событий. Основным ограничением в нашей ситуации является отсутствие общих часов или средств синхронизации локальных часов. Проблему можно сформулировать и так: хотелось бы иметь возможность определить, какое из событий произошло раньше, — событие а в системе i или событие b в системе ). Кроме того, желательно было бы иметь возможность делать такие выводы относительно любой системы, подключенной к сети. К сожалению, эта формулировка не является точной по двум причинам. Во-первых, между самим событием и его наблюдением в других системах может возникать задержка. Во-вторых, из-за отсутствия синхронизации возникают разногласия в показаниях часов, установленных в различных системах.
Чтобы преодолеть эти трудности, Лампорт (Lamport) [LAMP78J предложил метод, получивший название метода временных меток (timestamping), который помогает упорядочивать события в распределенных системах, не используя физические часы. Эта технология оказалась настолько действенной и эффективной, что стала использоваться в подавляющем большинстве алгоритмов взаимоисключений и взаимоблокировок.
Для начала выберем определение понятия событие (event). В конечном счете, мы имеем дело с событиями, происходящими в локальной системе, например вхождением процесса в критический раздел или выходом из него. Однако в распределенной системе процессы взаимодействуют между собой с помощью сообщений. Поэтому имеет смысл ассоциировать события с сообщениями. Связать локальное событие с сообщением очень просто — например, процесс может отправлять сообщение, когда ему нужно войти в критический раздел или выйти из него. Чтобы избежать неоднозначности, события будем связывать только с отправкой сообщений, а не с их получением. Таким образом, каждый раз, когда процесс передает сообщение, задается событие, соответствующее моменту времени, когда сообщение покинуло процесс.
Схема временных меток предназначена для того, чтобы упорядочить события, заключающиеся в передаче сообщений. В каждой подключенной к сети системе i поддерживается локальный счетчик Ci, выполняющий функцию часов. Перед передачей каждого сообщения система увеличивает показания этого счетчика на 1. Сообщение имеет вид
(m,T,i),
где т — содержимое сообщения, T, — временная метка сообщения, равная Ci, i — численный идентификатор узла.
Получив сообщение, система-адресат j устанавливает значение своего счетчика равным увеличенному на единицу максимальному значению из текущего показания счетчика системы и поступившей временной метки:
Сj <- 1 + mах[Сj,Ti]
Упорядочение событий в каждом узле происходит по следующим правилам. Говорят, что сообщение х, поступившее от узла i, предшествует сообщению у, поступившему от узла j, если выполняется одно из следующих условий.
1. Ti < Tj
2. Ti = Tj и i < j.
Временной характеристикой каждого сообщения является его временная метка, а упорядочение времен определяется двумя приведенными выше правилами (т.е. два сообщения, временные метки которых равны, упорядочиваются по номерам их узлов). Благодаря тому, что применение этих правил не зависит от узлов, при таком подходе удается избежать проблем, связанных с расхождением часов процессов, которые обмениваются информацией.
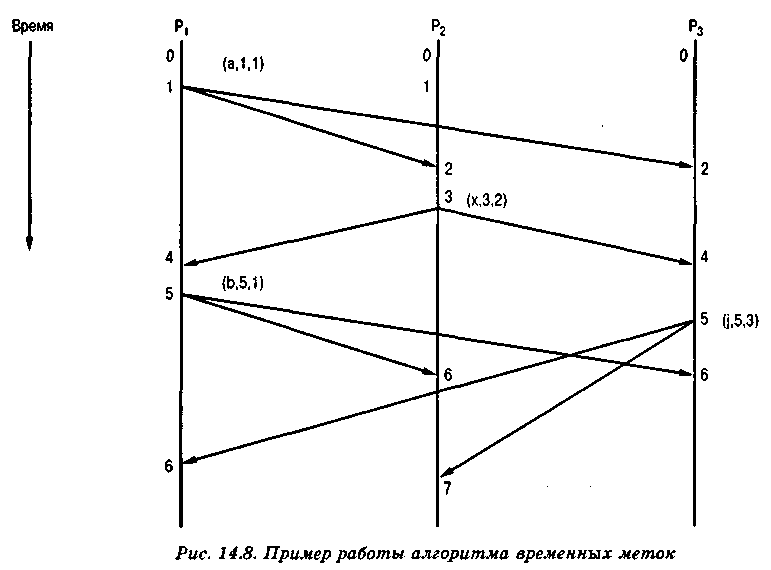
Пример работы этого алгоритма показан на рис. 14.8. В распределенной системе имеется три узла, каждый из которых представлен процессом, выполняющим алгоритм временных меток. Процесс P1 начинается с показанием часов, равным 0. Перед передачей сообщения а он увеличивает показание своих часов на 1 и передает сообщение вида (а, 1,1), в котором первое численное значение соответствует временной метке, а второе — идентификатору узла. Это сообщение принимается процессами на узлах 2 и 3. В обоих случаях показания локальных часов равняются нулю, а после получения сообщения устанавливаются равными 2 = 1+ тах[0,1]. Процесс Р2 генерирует следующее сообщение, увеличивая перед этим показание своих часов на 1 (т.е. до 3). Получив это сообщение, процессы 1 и 3 должны установить на своих часах значение 4. Затем примерно в одно и то же время процесс P1 отправляет сообщение b, a процесс Р3 — сообщение j. Оба сообщения имеют одинаковые временные метки. Благодаря сформулированному выше временному принципу это не приведет к путанице. После всех этих событий упорядочение событий на всех узлах будет одним и тем же, а именно {а, х, b, j}.
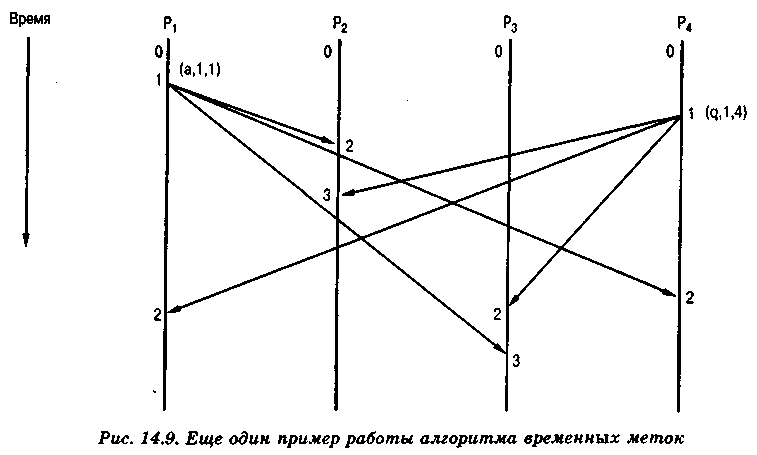
Как показано на рис. 14.9, описанный алгоритм работает, несмотря на различия во времени передачи сообщений в паре систем. Процессы P1 и Р4 отправляют сообщения с одинаковыми временными метками. Сообщение от процесса pi прибывает на узел 2 раньше, чем сообщение от процесса Р4, а на узел 3 сообщения от этих процессов прибывают в обратном порядке. Несмотря на это, после получения всех сообщений их упорядочение на всех узлах остается одинаковым: {a, q}.
Заметим, что упорядочение по такой схеме не всегда соответствует реальной последовательности событий. Так как основой этих алгоритмов является схема временных меток, не важно, какое событие произошло первым на самом деле. Важно только то, что упорядочение всех процессов по этому алгоритму выполняется согласованно.
В двух приведенных примерах процесс адресует каждое сообщение всем остальным процессам. Если какие-то сообщения отправляются по-другому, некоторые узлы не получат всех сообщений, пересланных в системе, и поэтому невозможно будет одинаково упорядочить сообщения на всех узлах. В этом случае получится множество частичных упорядочений. Однако использование временных меток первоначально предназначалось для распределенных алгоритмов взаимоисключений и взаимоблокировок. В таких алгоритмах процесс обычно отправляет сообщение (с временной меткой) всем другим процессам; временные метки используются для того, чтобы определить порядок обработки сообщений.
Распределенная очередь
Первая версия
Один из самых ранних подходов, предложенный для обеспечения распределенных взаимоисключений, связан с концепцией распределенной очереди [LAMP78]. В основе этого алгоритма лежат такие предположения.
1. Распределенная система состоит из N узлов, пронумерованных числами от 1 до N. На каждом узле содержится один процесс, запрашивающий взаимоисключающий доступ к ресурсам от имени других процессов; этот процесс также выступает арбитром, разрешая перекрывающиеся во времени входящие запросы.
2. Получение сообщений, отправленных одним процессом другому, происходит в том же порядке, в котором эти сообщения были отправлены.
3. Каждое сообщение доставляется по указанному адресу в течение конечного времени.
4. Сеть является полносвязной; это означает, что каждый процесс может отправить сообщение любому другому процессу без участия в передаче какого-либо промежуточного процесса.
Условия 2 и 3 можно выполнить, применяя надежный транспортный протокол, такой, как TCP.
Опишем алгоритм, предназначенный для того случая, когда каждый узел управляет только одним ресурсом. Обобщение на случай управления несколькими ресурсами тривиально.
В этом алгоритме предпринята попытка обобщить простой алгоритм, который мог бы работать в централизованной системе. Если ресурсом управляет единый центральный процесс, он может выстраивать поступающие запросы в очередь и предоставлять доступ к ресурсу в порядке поступления запросов. Чтобы реализовать этот же алгоритм в распределенной системе, на всех узлах должна быть копия одной и той же очереди. Чтобы порядок предоставления ресурса по запросам совпадал на всех узлах, можно применять временные метки. При этом возникает одна сложность: из-за того, что сообщение передается в течение какого-то конечного времени, возникает угроза, что на двух различных узлах во главе очереди будут находиться запросы разных процессов. Обратимся к рис. 14.9. Имеется некоторый интервал времени, в течение которого сообщение а уже получено процессом Р2, а сообщение q — процессом Р3, но оба сообщения еще не дошли до других процессов, которым они также были отправлены. Таким образом, в течение этого интервала времени процессы P1 и Р2 считают, что первым в очереди является сообщение а, а процессы Р3 и Р4 считают, что первым является сообщение q. Подобная ситуация может привести к нарушению требования взаимоисключения. Во избежание этого накладывается следующее ограничение: прежде чем процесс, исходя из состояния своей собственной очереди, примет решение о предоставлении ресурса, он должен получить от всех других узлов сообщение, гарантирующее, что в каналах не осталось ни одного сообщения, которое может занять первое место в очереди.
На каждом узле поддерживается структура данных, в которой хранятся записи о последних сообщениях, полученных от каждого узла (а также о тех, которые недавно отправлены с данного узла). Лампорт называет такую структуру очередью; фактически она является массивом, в котором каждому узлу соответствует один элемент. В каждый момент времени в элементе локального массива q[j] содержится сообщение от процесса Рj. Массив инициализируется следующим образом:
q[j] = (Release,0, j) j = 1,□ ,N
В этом алгоритме используются три вида сообщений:
- (Request, Ti, i): запрос ресурса процессом Рi;
- (Reply, Tj, j): предоставление процессом Рj доступа к ресурсу, который находится под его управлением;
- (Release, Tk, k): процесс Pk, освобождает предоставленный ему ресурс.
Алгоритм работает следующим образом.
1. Когда процессу Pi нужен доступ к ресурсу, он отправляет запрос (Request, Ti, i) с временной меткой, значение которой равняется текущему показанию локального счетчика этого процесса. Процесс помещает это сообщение в элемент своего собственного массива q[i] и рассылает его всем остальным процессам.
2. Когда процесс Pj получает запрос (Request, Ti, i), он помещает его в элемент собственного массива q[i]. Если в элементе q[j] не содержится сообщения с запросом, то процесс Рj отправляет процессу Рi ответ. Это именно то действие, с помощью которого реализуется описанное ранее правило. Оно гарантирует, что в момент принятия решения в каналах не осталось ни одного сообщения с запросом.
3. Процесс Рi может получить доступ к ресурсу (войти в критический раздел), если соблюдаются два условия.
а. Запрос q, поступивший от процесса Рi, является первым сообщением в собственной очереди этого процесса; поскольку сообщения на всех узлах упорядочены одинаково, это сообщение предоставляет в каждый момент времени доступ к ресурсу одному и только одному процессу.
б. Все другие сообщения, содержащиеся в локальном массиве, являются более поздними, чем сообщение в элементе q[i]; соблюдение этого правила гарантирует, что процессу Рi известно обо всех запросах, предшествующих его текущему запросу.
4. Процесс Рi освобождает ресурс путем генерации сообщения (Request, Ti, i). которое он помещает в свой собственный массив и рассылает всем другим процессам.
5. Получив сообщение (Request, Ti, j), процесс Рi помещает его в элемент массива q[j], заменяя его текущее содержимое этим сообщением.
6. Получив сообщение (Reply, Tj, j), процесс Рi помещает его в элемент массива q[j], заменяя его текущее содержимое этим сообщением.
Легко показать, что этот алгоритм обеспечивает взаимоисключение, равноправность процессов, отсутствие взаимоблокировок и голодания.
- Взаимоисключение. Запросы на вход в критический раздел обрабатываются в том порядке, который определяется механизмом временных меток. Если процесс Рi принимает решение войти в свой критический раздел, то в системе не может быть никаких других запросов, которые были переданы перед его запросом. Это утверждение является справедливым, так как процесс Рi к этому моменту получил от всех других узлов сообщения, помеченные более поздним временем, чем его запрос. В этом можно быть уверенным благодаря механизму ответных сообщений. Напомним, что при передаче сообщений их порядок не может быть нарушен.
- Равноправность. Доступ по запросам предоставляется строго в соответствии с временными метками. Поэтому все процессы обладают равными возможностями.
- Отсутствие взаимоблокировок. Благодаря тому, что порядок временных меток на всех узлах совпадает, взаимоблокировки невозможны.
- Отсутствие голодания. Как только процесс Рi закончит выполнение своего критического раздела, он передает сообщение об освобождении (Release). Это приводит к удалению на всех узлах запроса, поступившего от процесса Рi, и предоставлению доступа к критическому разделу другому процессу.
Чтобы оценить эффективность работы этого алгоритма, отметим, что для обеспечения исключения необходимо переслать Зх (N - 1) сообщений: (N - 1) сообщений-запросов, (N - 1) ответных сообщений и (N - 1) сообщений об освобождении.
Вторая версия
В [RICA81] предложен улучшенный вариант алгоритма Лампорта. В нем предпринята попытка оптимизировать первоначальную версию этого алгоритма, исключив из него сообщения об освобождении ресурса. Остаются в силе все ранее сделанные предположения, за исключением того, что теперь нам не нужно, чтобы сообщения, отправленные одним процессом другому, приходили в том же порядке, в котором они были отправлены.
Как и ранее, на каждом узле имеется один процесс, управляющий распределением ресурсов. Этот процесс поддерживает массив q и работает по следующим правилам.
1. Если процессу Рi нужен доступ к ресурсу, он генерирует запрос (Request, Ti, i) с временной меткой, значение которой равняется текущему показанию локального счетчика этого процесса. Процесс помещает это сообщение в элемент своего собственного массива q[i] и рассылает его всем остальным процессам.
2. Когда процесс Рj получает запрос (Request, Ti, i), он действует следующим образом.
а. Если процесс Рj в данное время находится в своем критическом разделе, он откладывает отправку ответного сообщения (см. правило 4 ниже).
б. Если процесс Рj не ожидает, пока ему можно будет войти в свой критический раздел (у него нет необработанных запросов), он передает процессу Pi ответ (Reply, Tj, j).
в. Если процесс Рj ожидает, пока ему можно будет войти в свой критический раздел, и если входящее сообщение следует после запроса процесса Рj, то он помещает это сообщение в элемент собственного массива q[i] и откладывает отправку ответного сообщения.
г. Если процесс Рj ожидает, пока ему можно будет войти в свой критический раздел, и если входящее сообщение предшествует запросу процесса Рj, то он помещает это сообщение в элемент собственного массива q[i] и отправляет процессу Pi ответное сообщение (Reply, Tj, j).
3. Процесс Pi может получить доступ к ресурсу (войти в свой критический раздел), если он получил ответные сообщения от всех остальных процессов.
4. После выхода из своего критического ресурса процесс Рi освобождает ресурс, рассылая ответные сообщения на все ожидающие запросы.
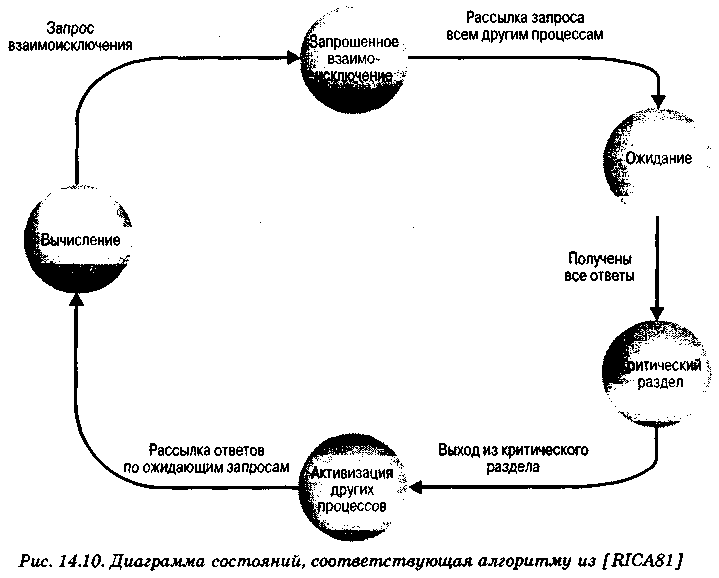
Диаграмма переходов каждого процесса из одного состояния в другое показана на рис. 14.10.
Итак, если процессу нужно войти в свой критический раздел, он рассылает всем другим процессам запрос с временной меткой. Когда он получит ответы от всех них, он сможет войти в свой критический раздел. Если процесс получает запрос от другого процесса, он, в конце концов, должен отправить ему соответствующий ответ. Если процессу не нужно входить в свой критический раздел, он отправляет этот ответ сразу же. Если же ему нужно войти в свой критический раздел, то он сравнивает временные метки своего запроса и запроса, полученного от другого процесса. Если временная метка запроса другого процесса является более поздней, отправка ответа откладывается; в противном случае ответ отправляется тут же.
При соблюдении этого метода требуется 2x(N - 1) сообщений: (N - 1) сообщений-запросов нужны для того, чтобы указать на намерение процесса Pi войти в свой критический раздел, и еще (N - 1) ответных сообщений — чтобы предоставить запрашиваемый доступ.
Использование временных меток в этом алгоритме обеспечивает взаимоисключение; благодаря ему удается также избежать взаимоблокировок. Докажем последнее утверждение методом от противного: предположим, что возможна ситуация, когда в каналах не осталось ни одного сообщения, каждый процесс отправил запрос и не получил необходимого ответа. Такая ситуация невозможна, потому что решение о задержке ответа основывается на порядке поступления запросов. Поэтому найдется хотя бы один запрос с минимальным значением временной метки, который получит все необходимые ответы. Благодаря этому взаимоблокировка невозможна.
Кроме того, поскольку запросы упорядочены, голодания также удается избежать. Так как запросы обслуживаются именно в порядке их расположения, каждый процесс рано или поздно становится самым старым и будет обслужен.
Подход с передачей маркера
Несколько исследователей предложили реализовать взаимоисключения с помощью совершенно иного подхода, в котором используется передача маркера между процессами. Маркер — это объект, который в каждый момент времени может содержаться только в одном процессе. Процесс, в котором находится маркер, может войти в критический раздел без дополнительного разрешения. Покидая свой критический раздел, процесс передает маркер другому процессу.
В этом разделе описана одна из наиболее эффективных схем. Впервые она была предложена в [SUZU82]; логически эквивалентное ей предложение можно найти в [RICA83]. Согласно этому алгоритму нужны две структуры данных. Маркер, который передается от одного процесса другому, на самом деле является массивом, в k-м элементе которого записана временная метка, соответствующая времени, когда маркер побывал в процессе Рk. Кроме того, каждый процесс поддерживает массив запросов, в j-м элементе которого записана временная метка, соответствующая моменту получения запроса от процесса Рj.
Процедура состоит в следующем. Первоначально маркер присваивается одному из процессов, который выбирается произвольным образом. Процесс, которому нужно использовать свой критический раздел, может это сделать, если он владеет маркером; в противном случае процесс рассылает всем другим процессам запрос с временной меткой и ждет, пока один из них не пришлет ему маркер. Покинув свой критический раздел, процесс Рj должен передать маркер какому-то другому процессу. Выбор этого процесса происходит следующим образом. Процесс Рj просматривает массив запросов в следующем порядке: j + 1, j + 2, ..., 1, 2, ..., j — 1, пока не найдет первый элемент [k], в котором временная метка последнего запроса больше, чем k-e значение маркера (запрос[k] > маркер[k]). Это означает, что процесс Pk сделал запрос после последнего пребывания в нем маркера.
В листинге 14.1 приведен алгоритм, состоящий из двух частей. Первая связана с использованием критического раздела и состоит из вступления, критического раздела и заключительной части. Вторая часть касается действий, предпринимаемых после получения запроса. Переменная clock — это локальный счетчик, используемый для временных меток. Выполнение функции wait (access, token) приводит к ожиданию процесса до тех пор, пока не будет получено сообщение типа "доступ", которое затем помещается в массив token.
Для работы алгоритма требуется следующее количество сообщений:
- N сообщений (N - 1 сообщений для рассылки запроса и 1 сообщение для получения маркера), если запрашивающий процесс не содержит маркера;
- ни одного сообщения, если маркер находится в этом процессе.
Листинг 14.1. Алгоритм с передачей маркера (для процесса Рi)
if (!token_present) /* Вступительная часть */
{
clock++;
broadcast (Request, clock, i);
wait (access, token);
token_present = true;
}
token_held = true;
<критический раздел>;
/* Заключительная часть */
token[i] = clock;
token_held = false;
for (int j = i + 1; j < n; j++)
{
if {request(j) > token [j] && token_present)
{
token_present = false;
send (access, token [j]) ;
}
}
for (j = 1; j <= i-l; j++)
{
if (request(j) > token [j] && token_present)
{
token_present = false;
send (access, token [j]);
}
}
а) Первая часть
if (received (Request, k, j))
{
request (j) = max(request(j), k) ;
if (token_present && !token_held)
<код заключительной части>;
}
б) Вторая часть
Примечание
send (j, access, token) отправляет процессом j сообщения
access с маркером
broadcast(request, рассылает сгенерированное
clock, i) процессом i сообщение с запросом
и временной меткой всем другим
процессам
received (request, t, j) принимает от процесса j
сообщение с запросом и временной
меткой t