

Лексический анализ с помощью конечных автоматов
Вместо регулярных выражений можно использовать соответствующий конечный автомат. Конечный автомат состоит из конечного множества состояний и переходов между ними, которые определяются считываемыми знаками из входной строки. При этом одно состояние определяется как начальное, а одно или более состояний — как конечные. Считается, что конечный автомат принял входную строку, если, начав работу с начального состояния и выполнив соответствующие переходы при считывании каждого знака исходной строки, автомат переходит в конечное состояние, когда
строка полностью считана. Или другими словами Конечный автомат используется при написании программы с помощью регулярных выражений. Конечный автомат состоит из конечного множества состояний и переходов между ними, которые определяются считываемыми знаками между ними, которые определяются считываемыми знаками из входной строки.
Конченый автомат определяется как следующая пятерка элементов.


П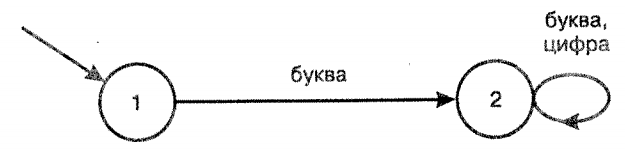 ереходы
δ
можно определить как таблицу (или
графически), и они для каждого состояния
будут указывать следующее
состояние
и все возможные входные знаки.
ереходы
δ
можно определить как таблицу (или
графически), и они для каждого состояния
будут указывать следующее
состояние
и все возможные входные знаки.
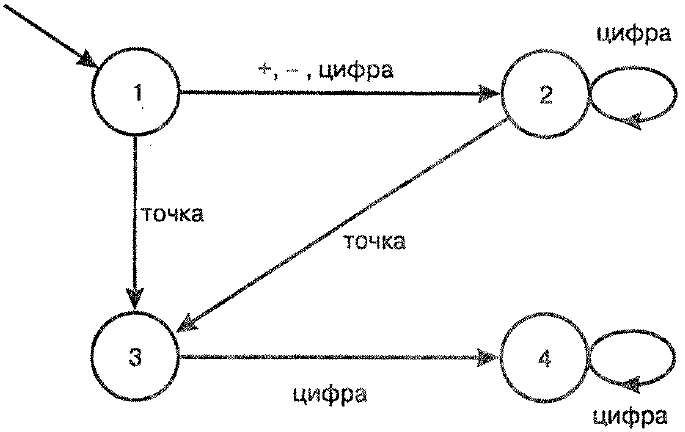
Действительное число можно представить с помощью приведенного ниже конечного автомата ==========================>
14. Лексический анализ с помощью Lex
Конструирование устройств распознавания символов из регулярных выражений или конечных автоматов, принимающих эти выражения может быть легко автоматизировано с помощью инструментальных средств, таких как Lex. Форма записи Lex допускает более эффективное представление (с точки зрения числа знаков, используемых в представлении) некоторых типов символов. Форма записи Lex расширяет выразительную силу обозначений регулярных выражений. Letter и digit являются определениями в Lex. Если какое-то действие должно выполняться всякий раз, когда встречается идентификатор, то оно выражается в виде правила {identifier} {printf («идентификатор опознан\n») ;} полным входом для создания анализатора, распознающего идентификаторы имеет следующий код
letter [a-z]
digit [0-9]
identifier {letter} ( {letter}| {digit} )*
%%
{identifier} {printf («идентификатор опознан\n») ;}
%%
Если этот код содержится в файле firstlex.l, тогда анализатор создается с помощью следующей команды lex firstlex.l Результатом данной команды будет написанный на С анализатор, помещаемый в файл lex.yy.c далее его можно откомпилировать cc –o firstlex lex.yy.c –ll и поместить целевой код в файл firstlex. Общий вид входа, ожидаемого Lex:
определения
%%
правила
%%
пользовательские функции
перед знаками ввода, которые являются частью системы обозначений («-» и «.») необходимо употреблять знак «\». Знак «+» используется для указания, что предшествующий знак один или более раз. Основные свойства обозначений, используемых на входе Lex: а- представляет отдельный знак; \а- представляет а, если а-знак, используемый в системе обозначений; «а»- также представляет а, если а-знак,используемый в системе обозначений; а|b – предстваляет а или b; а?- представляет нуль или одно вхождение а; а*- представляет а или более вхождений а; а+ - представляет одно или более вхождений а; а (m,n)- представляет от m до n вхождений а; [а-z]- представляет набор знаков (алфавит); [a-zA-Z]- представляет набор знаков; [^a-z]- представляет дополнение первого набора знаков; {name}- представляет регулярное выражение, определенное идентификатором name; ^a- представляет а в начале строки; a$- представляет а в конце строки; ab\xy – представляет ab, следующее перед xy. Типы анализа, связанные с лексической структурой программы: идентификация слов языка, идентификация и вычисление констант, определение всех отдельных идентификаторов программ, определение числа строк комментариев в программе, определение числа и средней длины литералов в программе.