

Семантический анализ. Таблица типов.
В компиляторе должен существовать способ уникального представления каждого типа конкретной программы. Если исходный язык содержит только конечное число типов, для представления разрешенных типов можно использовать различные целые числа. Некоторые ранние языки, такие как FORTRAN, подобное позволяли, однако, более поздние языки в общем случае уже нельзя рассматривать так просто. При рассмотрении подходящего представления типов в программе необходимо принять во внимание следующие факторы.
Высокая структурированность и рекурсивная природа многих типов.
Общие операции, которые компилятор должен будет производить над, типами.
Общими операциями над типами в С являются следующие.
Нахождение типа поля элементов struct или union.
Нахождение типа элемента массива.
Нахождение типа результата функции.
Основные типы, такие как int, float и char, могут представляться в С посредством целых чисел, а составные типы, например, array и union, могут представляться как структуры.
Например, тип typedef
typedef struct {
int day;
int mth;
int year;
} dob;
можно представить с помощью следующей структуры

А тип typedef
typedef long int[9][19] matrix;
можно представить с помощью следующей структуры
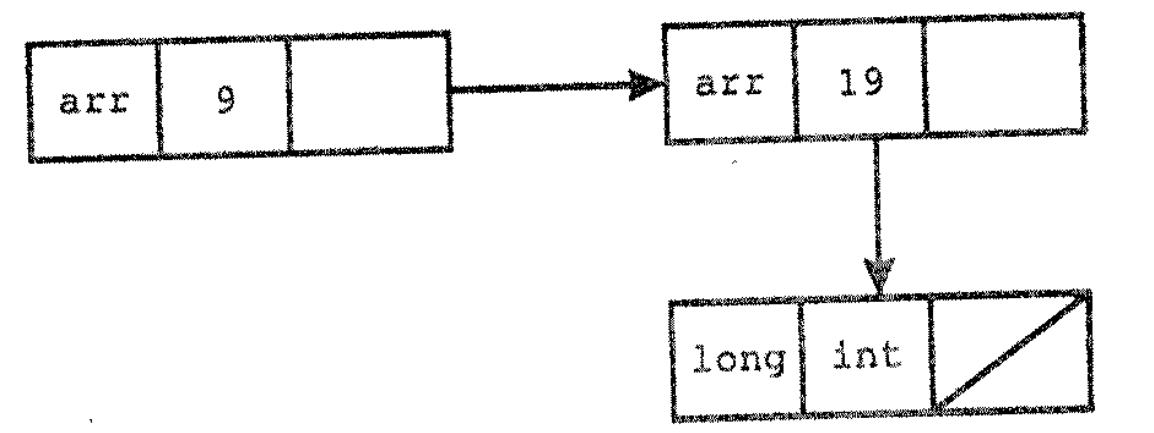
Этот способ представления позволяет сравнительно легко выполнять обычные операции над типами. Остается всего лишь определить массив (таблицу типов), который отображает имена типов в указатели на структуры типов. Поскольку используемые в программе имена типов, как и другие имена, имеют области видимости, в таблице также должна существовать возможность отображения областей видимости подобно тому, как это сделано в таблице символов. В простых случаях достаточной является стековая структура таблицы.
31.Семантический анализ. Таблицы функций. Таблицы меток
Число других таблиц, необходимых в процессе компиляции, определенным образом зависит от компилируемого языка. Обычно используются следующие таблицы.
Таблица функций.
Таблица меток.
Некоторым образом функция подобна типу, с ней соотнесены подтипы, т.е. типы параметров и результатов функции. В процессе генерации кода ей также выделяется адрес, а вся информация об этом хранится в таблице времени компиляции, обзор которой производится согласно соответствующим правилам языка.
Управляющие структуры в языках высокого уровня должны быть представлены в целевом коде посредством переходов (условных или иных) и меток. Таким образом, целевые версии исходных программ будут содержать как метки, определенные пользователем, так и метки, определенные компилятором. Структура многих языков позволяет использовать таблицу стекового типа для связывания определяющего вхождения метки и применимого вхождения метки. Из этого следует, что, по-видимому, в процессе компиляции (и во время выполнения) придется использовать несколько стеков. Управление стеками, в смысле выделения каждому из них достаточной памяти, становится сложным, если число стеков больше двух, так что значительные преимущества дает возможность объединения множества стеков в единую стековую структуру. К счастью, правила обзора многих языков такие возможности предоставляют.