

Семантический анализ. Таблица символов.
Основная задача таблицы символов – установить соответствие между переменной и ее типом. С таблицей символов связаны следующие две основные операции.
• Соответствующая определяющему вхождению переменной, например, int х. Имя переменной и ее тип помещаются в таблицу символов.
• Соответствующая применимому вхождению переменной, например, х = 5; Исследуется таблица символов для нахождения типа переменной.
Сложность таблицы символов и процедур работы с таблицей зависят от:
языка реализации;
важности эффективной компиляции.
Необходимо отметить, что неверным будет предположение о том, что только одна переменная в программе может быть представлена идентификатором х, поскольку, в общем случае, в программе может находиться произвольное количество переменных с именем х. Таким образом, для каждого применимого вхождения переменной х определяется позиция таблицы символов, соответствующая подходящему определяющему вхождению переменной х.
Форма таблицы символов, требуемой для анализа одной функции языка С, является простой. Рассмотрим схему функции С.
void scopes()
{int a, b, c /*уровень 0*/
…
{ int a, b /*уровень 1a*/
…
}
{ float c, d /*уровень 1b*/
{ int m /*уровень 2*/
…
}
}
}
Таблицу символов можно представить с помощью растущих вверх стеков, если поиск в ней определяющего вхождения идентификатора осуществляется сверху вниз, и позиции удаляются из стека после выхода переменной из области видимости.
Используя в качестве иллюстрации приведенную выше схему функции, покажем состояния стека на различных этапах анализа.
Изначально таблица символов пуста:
![]()
После обработки первых трех объявлений таблица имеет следующий вид.
![]()
После обработки объявлений уровня 1а таблица имеет такой вид.
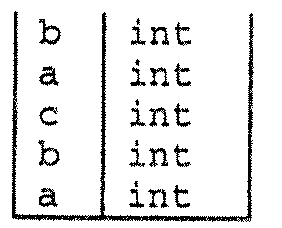
Поскольку поиск в таблице символов осуществляется сверху вниз, будут идентифицированы позиции, соответствующие наиболее недавним (или наиболее глубоким) определяющим вхождениям a или b. После прохождения области видимости, соответствующей объявлениям 1а, позиции, соответствующие этим объявлениям, должны удаляться из таблицы символов, таким образом, таблица вернется к прежнему виду.
В это же время значение указателя стека уменьшается до значения, имевшегося перед обработкой объявлений уровня 1a. Чтобы сделать это, требуется поддерживать массив указателей стека. После обработки объявлений уровня 1b стек принимает следующий вид.
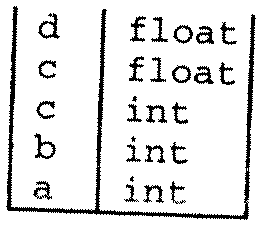
После обработки объявлений уровня 2 таблица имеет такой вид.

После прохождения области видимости объявлений уровня 2 стек возвращается к прежнему значению.

После прохождения области видимости объявлений уровня 1b он вновь имеет следующий вид.
После выхода из функции таблица символов снова становится пустой
Существует несколько моментов, на которые стоит обратить внимание. Во-первых, для глобально объявленных переменных необходим нижний (или внешний) уровень стека, существующий во время всего процесса компиляции. Отметим также, что при рассмотрении операций таблицы символов внешняя переменная (для которой память выделяется в другом исходном файле) трактуется так же, как и глобальная.
С точки зрения таблицы символов статическая переменная трактуется так же, как и автопеременная (подобная рассмотренным в примере), хотя при распределении памяти работа с этими переменными достаточно отличается.
На практике таблица символов может иметь более двух полей. Например, дополнительное поле может использоваться для указания того, относится ли идентификатор к переменным или к константам. Еще одно роле можно использовать для хранения констант или адресов переменных времени компиляции, хотя значение этого поля будет неизвестным до момента распределения памяти.
Если линейный поиск оказывается неэффективным для нахождения определяющего вхождения идентификатора, более эффективные алгоритмы поиска могут дать более сложные структуры данных, такие как бинарные деревья для различных уровней стека. Методы, рассмотренные в связи с лексическим и синтаксическим анализом, требуют времени, пропорционального длине программы, К сожалению, того же нельзя сказать для не-контекстно-свободного анализа, который часто называют статическим семантическим анализом. Чем больше программа, тем больше некоторые ее таблицы и тем больше времени будет занимать поиск в них. Это означает, что полное время компиляции может быть нелинейной функцией размера программы и для длинных программ может оказаться несоразмерно большим.
Стековое представление таблицы символов, подходящее для языка С, будет неадекватным для языков с более сложными правилами обзора, например, для языка Ada.
Из правил языка Ada следует:
оператор use может сделать идентификатор непосредственно видимым, только если тот не является непосредственно видимым при отсутствии этого оператора;
идентификатор, ставший непосредственно видимым при использовании оператора use, должен объявляться в одном и только одном пакете, указанном в операторе use.
Учитывая эти правила, необходимо вставить корректную реализацию оператора use в видимую часть сегмента таблицы символов, указанную в операторе use “вверху” таблицы символов. После того, как завершится область видимости оператора use, данную часть таблицы символов можно будет удалить.
Типы соотносятся не только с переменными и константами; каждый элемент выражения имеет соответствующий ему тип, в том числе это относится:
к литералам, таким как 3, 23.4, true;
к выражениям, таким как 3 + 4.
Типы литералов обычно определяются при лексическом анализе. Например (предполагается использование языка С), 3, очевидно, имеет тип int, а 23.4 – float. Типы выражений определяются по типам их компонентов. Поскольку 23.4 и 34.2 имеют тип float, то выражение
23.4 + 34.2
также будет иметь тип float. Подобным образом выражение
23.4 + 5
будет иметь тип float.
Это можно объяснить двумя способами, в зависимости от рассматриваемого языка.
Переменная типа float плюс переменная типа int дает переменную типа float.
Сложение определено только для переменных одного типа, поэтому перед сложением целое 5 должно преобразовываться в тип float.
В большинстве языков программирования имеет место неявное изменение типов. Реже встречаются языки, подобные Ada, в которых большинство изменений типов должно быть явным.
В языке С явно заданные изменения называются приведением типов, примером подобного может служить следующее выражение.
x = float(m)
Здесь значение m (предполагаемое целым) преобразовывается в тип float перед присвоением его значения переменной х.
В языках со статическими типами, например С, все типы известны во время компиляции, и это относится к типам выражений, идентификаторам и литералам. При этом не важно, насколько сложным является выражение: его тип может определяться во время компиляции за определенное количество шагов, исходя из типов его составляющих. Фактически, это позволяет производить контроль типов во время компиляции и находить заранее (в процессе компиляции, а не во время выполнения программы) многие программные ошибки.