

оценка проектов создания различных организаций массового обслуживания, например центров обработки заказов, заведений быстрого питания, больниц, отделений связи; анализ финансовых и экономических систем и т. д.
Имитационное моделирование - один из наиболее распространенных методов исследования операций и теории управления (а возможно, и самый распространенный метод). Более широкому использованию ИМ препятствовали несколько факторов.
Во-первых, модели, применяемые для исследования больших систем, все более усложняются, что, в свою очередь, затрудняет написание компьютерных программ. В последние годы эту задачу удалось существенно облегчить путем разработки мощных программных продуктов, включающих элементы, необходимые для создания имитационной модели.
Во-вторых, для моделирования сложных систем часто требуется много компьютерного времени. Однако по мере увеличения быстродействия и уменьшения стоимости компьютеров эта проблема постепенно становится решаемой. ИМ является экспериментальной и прикладной методологией, имеющей целью описать поведение системы, построить теории и выдвинуть гипотезы, а также использовать эти теории для предсказания будущего поведения системы. Модель, включающую все аспекты такой классификации, будем называть полной или совершенной имитационной моделью. В соответствии с классификационным признаком полноты моделирование делится на полное, неполное и приближенное. При полном моделировании модели идентичны объекту во времени и пространстве. Для неполного моделирования эта идентичность не сохраняется. В основе приближенного моделирования лежит подобие, при котором некоторые стороны реального объекта не моделируются совсем.
Вопрос 14
Основные преимущества и недостатки имитационного моделирования
Применение имитационных моделей дает множество преимуществ по сравнению с выполнением экспериментов над реальной системой и использованием других методов.
Стоимость. Допустим, компания уволила часть сотрудников, что в дальнейшем привело к снижению качества обслуживания и потери части клиентов. Принять обоснованное решение помогла бы имитационная модель, затраты на применение которой состоят лишь из цены программного обеспечения и стоимости консалтинговых услуг.
Время. В реальности оценить эффективность, например, новой сети распространения продукции или измененной структуры склада можно лишь через месяцы или даже годы. Имитационная модель позволяет определить оптимальность таких изменений за считанные минуты, необходимые для проведения эксперимента. Повторяемость. Современная жизнь требует от организаций быстрой реакции на изменение ситуации на рынке. Например, прогноз объемов спроса продукции должен быть составлен в срок, и его изменения критичны. С помощью имитационной модели можно провести неограниченное количество экспериментов с разными параметрами, чтобы определить наилучший вариант.
Точность. Традиционные расчетные математические методы требуют применения высокой степени абстракции и не учитывают важные детали. Имитационное моделирование позволяет описать структуру системы и её процессы в естественном виде, не прибегая к использованию формул и строгих математических зависимостей.
Наглядность. Имитационная модель обладает возможностями визуализации процесса работы системы во времени, схематичного задания её структуры и выдачи результатов в графическом виде. Это позволяет наглядно представить полученное решение и донести заложенные в него идеи до клиента и коллег.
Универсальность. Имитационное моделирование позволяет решать задачи из любых областей: производства, логистики, финансов, здравоохранения и многих других. В каждом случае модель имитирует, воспроизводит, реальную жизнь и позволяет проводить широкий набор экспериментов без влияния на реальные объекты.
Однако имитационное моделирование наряду с достоинствами имеет и недостатки:
- разработка хорошей имитационной модели часто обходится дороже создания аналитической модели и требует больших временных затрат;
- может оказаться, что имитационная модель неточна (что бывает часто), и мы не в состоянии измерить степень этой неточности;
- зачастую исследователи обращаются к имитационному моделированию, не представляя тех трудностей , с которыми они встретятся и совершают при этом ряд ошибок методологического характера.
И, тем не менее, имитационное моделирование является одним из наиболее широко используемых методов при решении задач синтеза и анализа сложных процессов и систем.
Вопрос 15
Дискретно-событийное моделирование.
Дискретно-событийное моделирование используют для построения модели, отражающей изменение состояния системы, когда переменные изменяются мгновенно в конкретные моменты времени. При этом происходят мгновенные события, которые могут изменить состояние системы.)Несмотря на то что теоретически ДСМ можно осуществлять вручную, большое количество данных, которые должны сохраняться и обрабатываться при моделировании реальных систем, обусловливает необходимость применения ЭВМ.
В качестве примера рассмотрим очередь покупателей к прилавку небольшого магазина подарков (так называемая однолинейная система массового обслуживания с одним устройством).
Покупатель |
Время после прибытия предыдущего покупателя, мин |
Время обслуживания, мин |
Время нахождения покупателя у прилавка, мин |
Время простоя продавца в ожидании покупателя, мин |
1 |
- |
1 |
1 |
0 |
2 |
3 |
4 |
4 |
2 |
3 |
7 |
4 |
4 |
3 |
4 |
3 |
2 |
3 |
0 |
5 |
9 |
1 |
1 |
6 |
6 |
10 |
5 |
5 |
9 |
7 |
6 |
4 |
4 |
1 |
8 |
8 |
6 |
6 |
4 |
Предположим, что промежутки времени между последовательными появлениями покупателей распределены равномерно в интервале от 1 до 10 мин, а время, необходимое для обслуживания каждого покупателя, распределяется равномерно в интервале от 1 до 6 мин. Хозяйку магазина интересует среднее время пребывания покупателя в магазине, а также время (в %), в течение которого продавец, стоящий на контроле, не загружен работой.
Для моделирования системы необходимо найти способ имитации последовательности прибытия покупателей и времени, требуемого для обслуживания каждого из них. Один из предполагаемых способов состоит в том, чтобы взять десять фишек с цифрами от 1 до 10 и один игральный кубик. Положим фишки в шляпу и тщательно ее встряхнем. При вытягивании фишки из шляпы и считывании .выпавшего числа моделируются промежутки времени между приходами предыдущего и последующих покупателей, а при бросании кубика и считывании с его верхней грани выпавшего числа очков определяется время обслуживания каждого покупателя. Повторяя эти операции в указанной последовательности (возвращая каждый раз фишки обратно и встряхивая шляпу перед каждым вытягиванием), можно получить временные ряды, представляющие собой промежутки времени между последовательными прибытиями покупателей и соответствующие им времена обслуживания. Результаты, полученные в случае посещения 20 покупателей, приведены в табл. 1.1.
Таблица 1.1
Окончание табл. 1.1
Покупатель |
Время после прибытия предыдущего покупателя, мин |
Время обслуживания, мин |
Время пребывания покупателя у прилавка, мин |
Время простоя продавца в ожидании покуг^теля, мин |
9 |
8 |
1 |
1 |
2 |
10 |
8 |
3 |
3 |
7 - |
11 |
7 |
5 |
5 |
4 |
12 |
3 |
5 |
7 |
0 |
13 |
8 |
3 |
3 |
1 |
14 |
4 |
6 |
6 |
1 |
15 |
4 |
1 |
3 |
0 |
16 |
7 |
1 |
1 |
4 |
17 |
1 |
6 |
6 |
0 |
18 |
6 |
1 |
1 |
0 |
19 |
7 |
2 |
2 |
6 |
20 |
6 |
2 |
2 |
5 |
Всего |
- |
63 |
68 |
55 |
В результате обработки данных получаем время пребывания покупателя в магазине *маг = 68/20 = 3,4 мин и время простоя продавца tn = [55/(55 + 63)] • 100 % - 47 %.
Очевидно, что для получения статистической значимости результатов необходимо иметь достаточно большую выборку, учесть ряд таких привходящих нюансов, как начальные условия работы магазина и др., однако приведенный пример носит чисто методический характер.
Вопрос 16
Непрерывное моделирование — это моделирование системы по времени с помощью представления, в котором переменные состояния меняются непрерывно по отношению ко времени. Как правило, в непрерывных имитационных моделях используются дифференциальные уравнения, которые устанавливают отношения для скоростей изменения переменных состояния во времени. Если дифференциальные уравнения очень просты, их можно решать аналитически, чтобы представить значения переменных состояния для всех значений времени как функцию значений переменных состояния в момент времени 0. При больших непрерывных моделях аналитическое решение невозможно, но для численного интегрирования дифференциальных уравнений в случае с заданными специальными значениями для переменных состояния в момент времени 0 используются технологии численного анализа, например интегрирование Рунге-Кутта.
Пример
Рассмотрим непрерывную модель соперничества между двумя популяциями. Биологические модели такого типа, именуемые моделями хищник-добыча, рассматривались многими авторами, в том числе Брауном и Гордоном. Среда представлена двумя популяциями -хищников и добычи, взаимодействующими друг с другом. Добыча пассивна, но хищники зависят от ее популяции, поскольку она является для них источником пищи. (Например, хищниками могут быть акулы, а добычей — рыба, которой они питаются) Пусть x(t) и y(t) обозначают численность особей в популяциях соответственно добычи и хищников в момент времени t. Допустим, популяция добычи имеет обильные запасы пищи; при отсутствии хищников темп ее прироста составит rх(t) для некоторого положительного значения r (r — естественный уровень рождаемости минус естественный уровень смертности). Существование взаимодействия между хищниками и добычей дает основание предположить, что уровень смертности добычи в связи с этим взаимодействием пропорционален произведению численностей обоих популяций х(t)у(t). Поэтому общий темп изменения популяции добычи dx/dt: может быть представлен как
 (1)
(1)
где а — положительный коэффициент пропорциональности. Поскольку существование самих хищников зависит от популяции добычи, темп изменения популяции хищников в отсутствии добычи составляет -sу(t) для некоторого положительного s. Более того, взаимодействие между двумя популяциями приводит к росту популяции хищников, темп которого также пропорционален х(t)у(t). Следовательно, общий темп изменения популяции хищников dy/dt составляет
 (2)
(2)
где b — положительный коэффициент пропорциональности. При начальных условиях х(0) > 0 и y(0) >0 решение модели, определенной уравнениями ( 1) и ( 2), имеет интересное свойство: х(t) > 0 и у(t) > 0 для любого t0. Следовательно, популяция добычи никогда не будет полностью уничтожена хищниками. Решение {х(t), у(t)} также является периодической функцией времени. Иными словами, существует такое значение Т>0, при котором х(t + пТ)=x(t) и у(t + пТ) = у(t) для любого положительного целого числа п. Такой результат не является неожиданным. По мере увеличения популяции хищников популяция добычи уменьшается. Это приводит к снижению темпа роста популяции хищников и, соответственно, вызывает уменьшение их числа, что, в свою очередь, ведет к увеличению популяции добычи и т. д.
Р ассмотрим
отдельные значения г = 0,001, а = 2 * 10 –6;
s
= 0,01; b=10
-6,
исходные размеры
популяций составляют х(0)
= 12 000 и y(0)
= 600. На рис. представлено численное
решение уравнений (1) и (2), полученное
при использовании вычислительного
пакета, разработанного для численного
решения систем дифференциальных
уравнений (а
не языка непрерывного моделирования).
ассмотрим
отдельные значения г = 0,001, а = 2 * 10 –6;
s
= 0,01; b=10
-6,
исходные размеры
популяций составляют х(0)
= 12 000 и y(0)
= 600. На рис. представлено численное
решение уравнений (1) и (2), полученное
при использовании вычислительного
пакета, разработанного для численного
решения систем дифференциальных
уравнений (а
не языка непрерывного моделирования).
Обратите внимание на то, что приведенный выше пример полностью детерминистический, то есть в нем нет случайных компонентов. Однако имитационная модель может содержать и неизвестные величины; например, в уравнения (1) и (2) могут быть добавлены случайные величины, которые каким-то образом зависят от времени, или постоянные множители могут быть смоделированы как величины, случайно изменяющие свои значения в определенные моменты времени.
Вопрос 17
Комбинированное непрерывно-дискретное моделирование
Поскольку некоторые из систем невозможно отнести ни к полностью дискретным, ни к полностью непрерывным, может возникнуть необходимость в создании модели, которая объединяет в себе аспекты как дискретно-событийного, так и непрерывного моделирования, в результате чего получается комбинированное непрерывно- дискретное моделирование. Между дискретным и непрерывным изменениями переменных состояния могут происходить три основных типа взаимодействия:
- дискретное событие может вызвать дискретное изменение в значении непрерывной переменной состояния;
- в определенный момент времени дискретное событие может вызвать изменение отношения, управляющего непрерывной переменной состояния;
- непрерывная переменная состояния, достигшая порогового значения, может вызвать возникновение или планирование дискретного события.
В следующем примере комбинированного непрерывно-дискретного моделирования дано краткое описание модели, подробно рассмотренной Прицкером, который в своей работе приводит и другие примеры этого типа моделирования.
Пример
Танкеры, перевозящие нефть, прибывают в один разгрузочный док, пополняя резервуар-хранилище, из которого нефть по трубопроводу попадает на нефтеперегонный завод. Из разгружающегося танкера нефть подается в резервуар-хранилище с постоянной скоростью (Танкеры, прибывающие к занятому доку, образуют очередь.) На нефтеперегонный завод нефть подается из резервуара с различными заданными скоростями. Док открыт с 6.00 до 24.00. По соображениям безопасности разгрузка танкеров прекращается по закрытии дока.
Дискретными событиями в этой (упрощенной) модели являются прибытие танкера на разгрузку, закрытие дока в полночь и открытие в 6.00. Уровни нефти в разгружающемся танкере и резервуаре-хранилище задаются переменными непрерывного состояния, скорости изменения которых описаны с помощью дифференциальных уравнений. Разгрузка танкера считается завершенной, когда уровень нефти в танкере составляет менее 5 % его емкости, но разгрузка должна быть временно прекращена, если уровень нефти в резервуаре-хранилище станет равным его емкости. Разгрузка может быть возобновлена, когда уровень нефти в резервуаре станет меньше 80 % его емкости. В случае если уровень нефти в резервуаре станет меньше 5000 баррелей, нефтеперегонный завод должен быть временно закрыт. Для того чтобы избежать частого закрытия и возобновления работы завода, подача нефти из резервуара на завод не будет возобновляться до тех пор, пока в нем не наберется 50 000 баррелей нефти. Каждое из пяти событий, связанных с уровнем нефти (например, падение уровня нефти ниже 5 % емкости танкера), по определению Прицкера, является событием состояния. В отличие от дискретных событий, события состояния не планируются, они происходят, когда переменные непрерывного состояния переходят пороговое значение.
18. Этапы разработки имитационных моделей
Практика разработки имитационных моделей реальных систем позволила выделить следующие этапы этого процесса.
Определение системы - установление границ, ограничений и критериев эффективности изучаемой системы.
Формулирование модели - переход от реальной системы к некоторой логической схеме.
Подготовка данных - отбор данных, необходимых для построения модели и представления их в соответствующей форме.
Разработка программного обеспечения — описание модели на языке, приемлемом для используемого компьютера.
Оценка адекватности - оценка соответствия результатов функционирования реальной системы и результатов, получаемых на основе имитационной модели.
Стратегическое планирование - планирование эксперимента для получения необходимой информации с наименьшими затратами средств.
Тактическое планирование - определение способа проведения каждой серии испытаний, предусмотренных планом эксперимента.
Экспериментирование - имитация процесса на компьютере для получения необходимой информации об исследуемой системе и анализа чувствительности модели.
Интерпретация - формулировка выводов и рекомендаций по результатам проведенных исследований.
Реализация - практическое использование модели и результатов моделирования.
Документирование - регистрация хода осуществления проекта и использования его результатов.
В связи с тем что перечисленные этапы ИМ определены, возможно, не самым эффективным способом, задача создания" методологии ИМ до настоящего времени окончательно не решена.
19. Системный подход к формированию имитационных моделей
При исследовании и особенно при формировании сложных систем в любой сфере человеческой деятельности в последнее время большое распространение получил методологический подход, называемый системным. Рассмотрение объекта исследования в многообразии его связей с другими объектами и его построение в целях повышения эффективности большой системы можно назвать системным подходом. Под большой системой понимают систему, частью которой является изучаемый объект. Системный подход предполагает комплексный учет взаимодействия всех элементов системы.
В современных представлениях понятие системы имеет важное значение. В настоящее время системный подход для решения сложных задач получил достаточно широкое распространение. Использование этого подхода обусловлено тем, что если даже каждый элемент или подсистема имеет оптимальные конструктивные или функциональные характеристики, то результирующее поведение системы в целом вследствие взаимодействия между ее отдельными частями может оказаться субоптимальным.
А. Эйнштейн как-то сказал, что «правильная постановка задачи более важна, чем ее решение». Чтобы найти приемлемое или оптимальное решение задачи, вначале необходимо знать, в чем она состоит.
Во многих случаях заказчик имитационной модели не может точно сформулировать свою проблему. Поэтому анализ системы обычно начинается с ее изучения, причем опыт показывает, что постановка задачи является, непрерывным процессом в течение всего хода исследования. Это связано с непрерывным получением новой информации, касающейся ограничений, задач я возможных альтернативных вариантов. В целях уточнения формулировки и постановки задачи такую информацию необходимо периодически использовать.
Важной частью постановки задачи является нахождение характеристик изучаемой системы. Поскольку все системы представляю собой подсистемы более крупных систем, первый шаг при решении этой задачи состоит в проведении анализа той срёды,
в которой находится система. Этот анализ начинается с определения целей и граничных условий (т. е. того, что является и не является частью системы). При этом необходим учет существенных связей, имеющихся между изучаемой системой и окружающей средой, в которой она функционирует.
Определив задачи исследования и границы системы, следует составить ее логическую структурную схему, или так называемую статическую модель. Требуется построить такую модель системы, которая, с одной стороны, не будет настолько упрощенной, что станет тривиальной, а с другой - не будет настолько детализиро- ванной, что станет громоздкой в обращении и чрезмерно дорогой. При этом ситуация осложняется тем, что усовершенствование модели характеризуется увеличением количества параметров, которые иногда ничего не вносят в понимание рассматриваемой задачи.
Системные аналитики слишком часто стремились отразить все сложности реальных систем в модели, надеясь, что с помощью компьютера они решат все проблемы. Такой подход нецелесообразен не только потому, что при его использовании осложняется программирование и возрастает стоимость прогонов, но и потому, что действительно важные аспекты и взаимосвязи между ними могут оказаться неучтенными. Во избежание этого следует строить модель, ориентированную на решение конкретных задач, а не имитировать подробно реальную систему. Закон Парето гласит, что в каждой группе или совокупности существует жизненно важное меньшинство м тривиальное большинство. В связи с этим модель должна отображать только те аспекты системы, которые могут оказать существенное влияние на достижение желаемых результатов.
20. Основные свойства систем, являющиеся причиной возникновения ошибок при попытки улучшить поведение системы.
Сложные системы отличаются свойствами, являющимися причиной возникновения многих ошибок при попытке улучшить поведение системы. Отметим среди них следующие.
Изменчивость. Характеристики системы изменяются, поскольку в процессе эволюционного развития те или иные элементы вводятся в состав системы или выводятся из него.
Наличие окружающей среды. Каждая система существует в окружающей ее среде и является подсистемой более крупной системы. Окружающая систему среда представляет собой комплекс элементов с определенными свойствами, которые хотя и являются
частью системы, однако при их модификации могут вызвать изменения состояния системы. Поэтому окружающая систему среда должна быть описана всеми внешними переменными, которые могут оказать влияние на систему.
Противоинтуитивное поведение. Поверхностное ознакомление со сложными системами может привести к выводу о необходимости того или иного корректирующего воздействия, однако оно бывает неэффективным или даже приводит к обратным результатам. Причины и следствия часто не имеют тесной связи во времени и пространстве, признаки следствия могут проявиться намного позже начала действия вызвавших их причин. Очевидные решения в действительности могут привести к осложнению проблемы, а не к ее решению.
Тенденция к ухудшению характеристик. Характеристики сложных систем, как правило, с течением времени ухудшаются. Например, части, из которых состоит система, изнашиваются, это становится одной из причин снижения эффективности ее функ- ционировакия, что может привести к негативным последствиям в ходе принятия проектных решений.
Взаимозависимость. Каждое событие в сложной системе зависит от предшествующих событий и оказывает влияние на последующие. Кроме того, различные процессы в реальных условиях протекают параллельно и в конечном счете оказывают влияние друг на друга.
Организация. Сложные системы состоят из элементов, характеризующихся высокой степенью организации. Части объединяются в иерархии подсистем, которые взаимодействуют между собой для выполнения целевого назначения системы. Следует отметить, что выбор элементов, вводимых в систему или выводимых из нее, и их конфигурация определяются исследователем. В связи с этим при определении понятия изучаемой системы и границ между нею и окружающей ее средой следует проявлять большую осторожность.
21. Основные три задачи, решаемы при имитационном моделировании
Прежде
чем, переходить к разработке имитационной
модели, необходимо понять, что собой
представляют элементы, из которых она
строится. Несмотря на то, что математическая
или физическая структура модели может
быть очень сложной, основы ее построения
весьма просты. В общем случае изучаемую
систему можно охарактеризовать векторами
входных, внутренних
и
выходных параметров
 ,
,
 ,
,
 ,
соответственно, причем
,
соответственно, причем
 -i-мерное
эвклидово арифметическое пространство.
Выходные параметры, как правило,
называют характеристиками. Одни и те
же физические, экономические или
информационные характеристики в моделях
различного уровня и содержания могут
выполнить функцию как внешних или
внутренних, так и выходных параметров.
Тогда структуру имитационной модели
можно представить в виде
у
= f(x,
z),
где f-
векторная функция векторного
аргумента.
Использование такой модели позволяет
легко определять выходные параметрs
по задаваемым значениям входных и
внутренних параметров, т. е. решать
так называемую
прямую задачу.
В инженерной практике решение такой
задачи часто именуют поверочным расчетом.
-i-мерное
эвклидово арифметическое пространство.
Выходные параметры, как правило,
называют характеристиками. Одни и те
же физические, экономические или
информационные характеристики в моделях
различного уровня и содержания могут
выполнить функцию как внешних или
внутренних, так и выходных параметров.
Тогда структуру имитационной модели
можно представить в виде
у
= f(x,
z),
где f-
векторная функция векторного
аргумента.
Использование такой модели позволяет
легко определять выходные параметрs
по задаваемым значениям входных и
внутренних параметров, т. е. решать
так называемую
прямую задачу.
В инженерной практике решение такой
задачи часто именуют поверочным расчетом.
При разработке системы возникает необходимость решать более сложную обратную задачу, или задачу управления: по заданному математическому описанию системы и известным выходным параметрам найти входные параметры. Решение обратной задачи осуществляют с помощью проектировочного расчета, цель которого часто состоит в определении входных параметров по некоторому критерию оптимизации W = W(x,y,z). Для такого расчета необходимо ввести ограничения на области существования компонент вектора х, а также функциональные ограничения, связывающие компоненты векторов хиг.
Гораздо более сложная обратная задача возникает, когда заданы совокупности входных и выходных параметров и необходимо составить математическое описание самой системы. Эта задача известна как задача идентификации, или структурного синтеза, системы. Трудность в этом случае состоит в том, что одно и то же соотношение между входными и выходными параметрами может описываться различными математическими выражениями.
Задача идентификации может быть решена на основе принципа «черного ящика» путем математической обработки информации, полученной с помощью соотношений между входными и выходными параметрами, установленных в ходе проведения эксперимента. Один из способов решения такой задачи состоит в применении регрессионного анализа.
Прямая задача - когда определяются выходные параметры по заданным входным и внутренним параметрам.
Обратная задача (задача управления) – когда по заданному математическому описанию системы и известным выходным параметрам находят выходные параметры.
Задача идентификации (задача типа «черный ящик») -наиболее сложная из 3-х перечисленных, заданы совокупности входных и выходных параметров нужно произвести математическое описание самой системы.
22. Методы, используемые при построении и проверке имитационных моделей
В целом имитационная модель предназначена отражать структуру и внутренние связи моделируемой системы. Правильность построения модели может быть проверена только на практике. Так как при создании любой модели используют упрощения и абстракции реальной системы, модель не может быть абсолютно точной в отношении однозначного ее соответствия реальной системе. Имитационное моделирование проводят не с целью поиска абсолютной истины, с его помощью можно лишь получить множество последовательных приближений к абсолютно точным данным. Проблема обоснования применимости имитационной модели ничем не отличается от аналогичной проблемы, касающейся теории или гипотезы в любой отрасли науки.
Поскольку построение модели и ее проверка являются неотъемлемыми элементами любой теории научных исследований, рассмотрим вкратце некоторые методы таких исследований.
Субъективные и объективные методы. При построении и обосновании имитационных моделей часто возникает противоречие между стремлением к объективности и необходимостью использовать субъективные представления. Под этими представлениями понимают взгляды, интуицию, мнения, ощущения, предположения и впечатления, которые имеются относительно того, как работает изучаемая система. Под объективными понимают представления, основанные только на экспериментальных данных. Это противоречие можно разрешить, если процесс построения модели рассматривать как непрерывные дополняющие друг друга переходы от субъективных соображений к объективным фактам и наоборот.
Рационализм и эмпиризм. Представители этих направлений единодушны во мнении о том, что наука начинается с наблюдений над некоторым объектом или процессом, но на этом их взаимопонимание заканчивается.
Рационалисты делают свои выводы на основе математики и логики. Их деятельность обычно направлена на разработку математически выражаемых гипотез относительно взаимодействий системы, причем таких, которые отвечают данным имеющихся наблюдений, а затем - на применение методов формальной логики для получения тех или иных результатов. Однако, как правило, вскоре выявляется неточность принимаемых допущений и предпосылок, на которых основаны конкретные модели.
Так, известна модель развития городов, базирующаяся на предпосылках, которые содержат обоснование в собственной формулировке. Однако главное предположение о том. что, если на душу населения тратится больше собранных в виде налогов средств, качество обслуживания населения улучшается, не очевидно, а в условиях современных городов не выдерживает никакой критики.
Эмпиризм отражает противоположное направление. Эмпирик отказывается принимать любые предпосылки или допущения, которые не могут быть проверены с помощью эксперимента или на основе анализа эмпирических данных. Иными словами, эмпиризм основывается на доказанных фактах и отказе от непроверенных предположений.
Абсолютный прагматизм. Если имитационную модель рассматривать как «черный ящик», преобразующий входные переменные в выходные, рационалист и эмпирик занимаются определением структуры этого «ящика». Прагматика совершенно не интересует его структура, он занят лишь исследованиями соотношений между входом и выходом. При таком подходе упомянутая выше модель, основанная на связи экономических циклов с пятнами на Солнце, должна быть принята, если она дает лучшие результаты, чем другие модели.
Утилитарный подход. Рационалисты, эмпирики и прагматики, придерживающиеся только одного направления, встречаются очень редко. Большинство экспериментаторов обычно в той или иной степени используют все эти методы, и такой подход можно назвать утилитарным. На первой стадии решение задач моделирования сводится к построению внутренней структуры модели на основе априорной информации предыдущих исследований и существующих теорий. Любая сложная имитационная модель состоит из множества простых моделей. Имитируемые этими моделями процессы обычно очевидны и понятны. Однако при их объединении в сложную систему большое количество вариантов возможных взаимодействий делает понимание поведения всей этой системы затруднительным.
23. Стадии построения модели
Рассмотрим стадии построения модели.
Первая стадия состоит в рассмотрении и моделировании простых составляющих сложной системы. При таком подходе нет необходимости в эмпирической проверке каждой гипотезы, но требуется, чтобы каждая используемая гипотеза была основана на полных знаниях об изучаемой системе. Таким образом, на первой стадии применяется рационалистический подход, при котором не принимаются синтетические априорные допущения Канта, а необходимо лишь, чтобы допущения имели физический смысл.
Вторая стадия также связана с построением внутренней структуры модели и состоит в эмпирической проверке (когда это возможно) используемой гипотезы. Основой для такой оценки и проверки гипотез может быть теория математической статистики.
Третья стадия состоит во всесторонней проверке пригодности модели для предсказания поведения реальной системы, заключающейся в проверке соотношений входных и выходных параметров. При этом лучшей считается модель, которая наиболее точно предсказывает поведение системы.
Рассмотренные три стадии при создании модели осуществляются итеративно, в процессе их проведения учитываются точки зрения рационалиста, эмпирика и прагматика. При построении и применений модели необходимо помнить о возможности возникновения на всех стадиях различного рода ошибок и делать все возможное, чтобы их избежать.
Итак, процесс построения и проверки модели состоит из трех стадий:
- использование ряда гипотез о способах взаимодействия элементов сложной системы, основанных на имеющейся информации, которая включает наблюдения, результаты предыдущих исследований, теории и интуитивные представления;
- проверка (когда это возможно) принятых допущений и гипотез с помощью статистических тестов;
- сравнение соотношений входных и выходных параметров модели и реальной системы.
24. Задачи и цели имитационного моделирования
В процессе создания имитационной модели, по крайней мере, необходимо определить следующее:
назначение модели;
какие элементы должны входить в модель;
параметры включенных элементов;
функциональные соотношения между элементами и описывающими их параметрами.
Эксперименты по моделированию проводят с различными целями, из которых наиболее распространенными являются:
оценка - определение, в какой степени предлагаемая структура системы будет отвечать некоторым конкретным критериям;
сравнение - сопоставление систем, предназначенных для выполнения определенной функции, или сопоставление нескольких предлагаемых принципов или методов;
прогноз - предсказание поведения системы при некотором предполагаемом соотношении рабочих параметров с учетом условий эксплуатации;
анализ чувствительности - выявление из большого числа факторов и параметров тех. которые в наибольшей степени влияют на поведение системы в целом;
оптимизация - точное нахождение такого соотношения параметров, при котором обеспечивается наилучший отклик (критерий оптимизации) всей системы в целом;
выявление функциональных соотношений - определение зависимости между двумя или несколькими параметрами и откликом системы.
Четкая формулировка цели построения модели имеет существенное значение при ее создании и экспериментальной проверке. Например, если модель предназначена для того, чтобы определить характеристики проектируемой или существующей системы, то это отражается на ее точности; при этом требуется высокая степень изоморфизма модели. В то же время, если назначением модели является лишь сравнительная оценка двух или нескольких систем или рабочих параметров, модель может быть пригодна даже в том случае, если абсолютное значение ее отклика на внешние воздействия существенно отличается от соответствующего значения в реальной системе.
25. Проверка модели. Основные способы проверки.
Рассмотрим вопросы, связанные с проверкой модели, в ходе которой достигается приемлемый уровень уверенности пользователя в том, что любой вывод о поведении системы, сделанный на основе моделирования, будет верным.
Проверка модели - это чрезвычайно важный процесс, который должен выполняться непрерывно. Тем не менее необходимо выделить два наиболее важных этапа при проведении проверки. Первый этап связан с созданием имитационной модели и состоит в проверке математической модели со всеми ее допущениями, называемой концептуальной. На втором этапе осуществляется проверка имитационной модели в целом.
Рассмотрим такие важные термины, использующиеся при моделировании, как «верификация», «валидация» и «доверие к модели».
При верификации - проверке достоверности модели, определяется, правильно ли по концептуальной модели составлена компьютерная программа, т. е. выполняется отладка моделирующей программы.
Приведем несколько методов верификации компьютерных программ, представляющих интерес при отладке работы имитационной модели. Одни из этих методов применимы к любым компьютерным программам, другие же предназначены исключительно для ИМ.
При разработке имитационной модели компьютерную программу лучше писать и отлаживать по модулям или подпрограммам. В процессе разработки сложных имитационных моделей желательно, чтобы компьютерную программу проверяли несколько человек, так как разработчик может слишком привыкнуть к своей программе и не заметить ошибок. В некоторых организациях этот подход осуществляют на практике, он называется структурным разбором. Иногда, чтобы убедиться, что получены удовлетворительные результаты, достаточно выполнить прогон имитационной модели с различными входными параметрами. В некоторых случаях можно точно вычислить простые рабочие параметры и использовать их для сравнения. Одним из наиболее распространенных методов, применяемых для отладки дискретно-событийных имитационных программ, является трассировка. При ее проведении данные о состоянии моделируемой системы, т. е. список событий, переменные состояния и др., выводятся на экран после возникновения каждого события и сравниваются с результатами вычислений. При трассировке желательно оценить все возможные ветви программ, а также возможность обрабатывать предельные условия функционирования системы.
Валидация - это процесс, использование которого дает возможность установить, является ли имитационная модель (не компьютерная программа) точным представлением системы для конкретных целей исследования. Валидацию можно противопоставить интерпретации или анализу выходных данных (см гл. 6), который представляет собой статистическую задачу, связанную с оценкой достоверности результатов, полученных с помощью имитационной модели. При анализе выходных данных необходимо знать продолжительность прогона и переходного периода, а также число независимых прогонов имитационной модели.
26. Имитационная модель реальной системы, факторы и предпосылки для её создания
Математическая модель, которую требуется изучить путем моделирования называют имитационная модель.
Оценивая целесообразность применения метода ИМ для исследования конкретной системы, необходимо учитывать его очевидные достоинства и недостатки. Имитационное моделирование, как правило, используют в случаях, когда:
не существует адекватной математической постановки либо не разработаны аналитические методы решения сформулированной математической модели (например, модели массового обслуживания, модели для решения военно-технических задач и др.);
аналитические методы имеются, но математические операции настолько сложны и трудоемки, что ИМ позволяет решить задачу с меньшими затратами ресурсов;
-из-за слабой подготовки технического персонала использовать имеющиеся аналитические решения невозможно;
представляет интерес наблюдение за ходом процесса во времени, а не только оценка выходных характеристик;
-ИМ оказывается единственной возможностью исследований из-за трудностей, возникающих при постановке экспериментов и наблюдениях за проведением процесса в реальных условиях (космос, стратегические оборонные инициативы и др.);
имеется возможность сжатия временной шкалы исследуемого процесса (анализ старения городов).
Дополнительным преимуществом ИМ можно считать широкие возможности его применения в сфере образования и профессиональной подготовки. Разработка и использование имитационной модели позволяют экспериментатору исследовать на модели реальные процессы и ситуации. Это, в свою очередь, в значительной мере способствует более глубокому пониманию проблемы, что стимулирует процесс поиска нововведений.
В силу своей простоты идея ИМ интуитивно привлекательна как для руководителей, так и для исследователей систем. Поэтому метод ИМ стремятся применять для решения каждой задачи, с которой приходится сталкиваться. И хотя специалистам с высоким уровнем математической подготовки ИМ представляется последним средством, к которому следует прибегать, этот метод является самым распространенным при решении проблем управления; доля использования ИМ из всех методов исследования операций - свыше 30 %.
Однако, как и другие методы, (ИМ имеет недостатки, ограничивающие сферу его применения:
-разработка имитационной модели часто обходится дорого, поскольку для этого требуется много времени, а также наличие высококвалифицированных специалистов;
-из-за трудностей получения исходной статистической информации Имитационная модель не всегда отражает действительность;
-трудность оценки точности результатов, однако эта проблема свойственна всем типам моделей;
с помощью модели, как правило, можно получить только результаты в численном виде.
Анализ достоинств и недостатков показывает, что, 'хотя ИМ является чрезвычайно ценным и полезным методом решения сложных задач, этот метод, конечно, не панацея для преодоления всех трудностей в процессе исследования. Разработками применение ИМ в большей степени является искусством, чем наукой. Неудача определяется не столько методом, сколько тем, как он используется.
Для успешного применения разрабатываемой имитационной модели и она должна отвечать следующим требованиям:
целенаправленность;
адекватность описываемым процессам;
точность, обеспечивающая приемлемое совпадение реальных выходных данных и данных, полученных с помощью модели;
-полнота в отношении учета всех интересующих особенностей функционирования системы;
-простота, наглядность и доступность для понимания пользователем;
удобство в управлении и обращении;
адаптивность к изменению исходных данных;
робастность, характеризующая устойчивость модели по отношению к погрешности исходных данных.
В процессе создания имитационной модели, по крайней мере, необходимо определить следующее:
назначение модели;
какие элементы должны входить в модель;
параметры включенных элементов;
функциональные соотношения между элементами и описывающими их параметрами.
Эксперименты по моделированию проводят с различными целями, из которых наиболее распространенными являются:
» оценка - определение, в какой степени предлагаемая структура системы будет отвечать некоторым конкретным критериям;
сравнение - сопоставление систем, предназначенных для выполнения определенной функции, или сопоставление нескольких предлагаемых принципов или методов;
прогноз - предсказание поведения системы при некотором предполагаемом соотношении рабочих параметров с учетом условий эксплуатации;
анализ чувствительности - выявление из большого числа факторов и параметров тех. которые в наибольшей степени влияют на поведение системы в целом;
»оптимизация - точное нахождение такого соотношения параметров, при котором обеспечивается наилучший отклик (критерий оптимизации) всей системы в целом;
выявление функциональных соотношений - определение зависимости между двумя или несколькими параметрами и откликом системы.
27. Схемы образования случайных величин. Три типа физической природы возникновения случайных величин.
При создании имитационных моделей приходится сталкиваться с различными случайными величинами, процессами и событиями. Случайными являются результаты отдельных выстрелов, моменты, в которые они были произведены, взаимное расположение снаряда и цели во время выстрела и т. д. В связи с производственными допусками, кроме того, случайными будут скорость и дальность полета снарядов, а также эффективность действия боевой части. Случайным будет и сочетание географических, климатических и метеорологических условий боя, Это перечисление можно продолжить для моделей массового обслуживания, экономического и социального развития и т. п.
Законы распределения случайных величин являются отражением физической природы возникновения этих величин, и поэтому выбор математического выражения для описаний статистических свойств тех или иных явлений не может быть произвольным. Можно выделить три типа явлений, встречающихся на практике.
К первому типу следует отнести явления очень сложной физической природы, для которых не представляется возможным прогнозировать характер статистических закономерностей. В таких случаях проводится накопление статистических данных, а затем осуществляется формальный подбор математического выражения, при использовании которого вероятностные свойства эмпирического распределения описываются удовлетворительно. Например, существует система кривых распределения Пирсона и разработан специальный математический аппарат для выбора типа кривой, обеспечивающей совпадение первых четырех моментов теоретического и эмпирического распределений.
Следует отметить, что, хотя такой формальный подход в целом позволяет достичь удовлетворительного описания экспериментальных данных, иногда его применение приводит к нарушению физического смысла в некотором интервале значений случайной величины. Нередки случаи, когда распределение случайной величины, заведомо являющейся положительной, аппроксимируется нормальным законом, что приводит к абсурдному результату: cp(.x) > 0 при v <0 В основном такие несоответствия носят чисто формальный характер и не отражаются на практической стороне дела, поскольку вероятность появления абсурдных значений случайной величины мала. Тем не менее необходимо стремиться к получению такого описания экспериментальных данных, при котором для всего диапазона изменения случайной величины сохранялся бы физический смысл
Ко второму типу можно отнести явления, которые допускают хотя бы схематическое описание механизма получения случайной величины, что дает возможность логического (может быть, не строгого математически) выбора закона распределения для описания их статистических свойств. Такого рода физически обоснованные законы распределения имеют большую практическую ценность, в отличие от вариантов, базирующихся на чисто формальном подборе математических соотношений, им должно отдаваться предпочтение.
К третьему типу следует отнести хорошо изученные явления, для которых можно провести строгое обоснование вида закона распределения случайной величины.
Изложенное объясняет то, что для описания событий исследователи используют различные законы распределения, нередко оказывающиеся удовлетворительными только для частных случаев
Далее приведены основные схемы случайных явлений, для которых возможно использование наиболее распространенных законов распределения Рассмотрим в первую очередь наиболее часто встречающиеся на практике распределения дискретных случайных величин.
Бывают следующие виды распределения:
Биномиальное распределение Имеется п независимых случайных величин Хи Л';, .., Х„, которые могут принимать значение 1 с вероятностью р и значение 0 с вероятностью q ~ (1 -р).
Распределение Пуассона. Основная схема, которая приводит к этому распределению, состоит в следующем. Предположим, что на некоторой оси распределены точки, при этом ось можно использовать для отсчета времени, площади, расстояния и т. д. Точки же означают случаи того, что интересующее нас событие произошло. Задача состоит в том, чтобы определить закон распределения числа точек на участке оси длиной /, Это может быть число целей, расположенных в заданном интервале боевого порядка, число выстрелов, произведенных за время t, число осколков, попавших в уязвимую площадь цели, и г. д.
Геометрическое распределение. Это распределение является дискретным аналогом экспоненциального распределения, рассматриваемого в дальнейшем, в том отношении, что это единственное дискретное распределение с отсутствием последействия.
Равномерное распределение. Случайная величина имеет равномерное распределение на отрезке [а, Ь], если ее плотность распределения имеет вид
![]()
Нормальное распределение. Нормальный закон распределения в качестве предельного можно получить из биномиального закона и закона Пуассона. Однако наиболее общая схема, приводящая к этому закону и показывающая причины его широкого распространения, следует из центральной предельной теоремы теории вероятностей. Эта теорема утверждает, что в общем случае сумма независимых случайных величин с произвольными законами распределения асимптотически нормальна. Когда среди случайных величин нет доминирующей (все слагаемые вносят в сумму примерно одинаковый вклад), суммарный закон распределения становится приблизительно нормальным уже при числе слагаемых, равном 3-5.
Экспоненциальное {показательное) распределение. При рассмотрении схемы, приводящей к закону Пуассона, можно установить закон распределения, которому подчиняются длины «пустых» (не содержащих точек) интервалов оси. Обозначим случайный промежуток времени между событиями Т. Тогда интегральный закон распределения можно представить следующим образом: F(t) = P(T<t) = 1-Р(Т>1) = 1-е-λt где P(T>t) = Р0(t) = е-λt - вероятность того, что на промежутке времени t не произойдет ни одного события, причем 0 ≤ t ≤ ∞.
Следовательно, функция плотности распределения длины «пустых» интервалов будет иметь вид
f(t) =λ е-λt
Вопрос 28
Дискретной называют случайную величину, которая принимает отдельные, изолированные возможные значения с определёнными вероятностями. Число возможных значений дискретной случайной величины может быть конечным или бесконечным.
Математическим
ожиданием дискретной случайной величины
называют сумму произведений всех её
возможных значений на их вероятность.
![]() ,
,
где
Х – случайная величина,
![]() - значения, вероятности которых
соответственно равны
- значения, вероятности которых
соответственно равны
![]() .
.
Математическое ожидание приближённо равно (тем точнее, чем больше число испытаний) среднему арифметическому наблюдаемых значений случайной величины.
Дисперсией
(рассеянием) случайной величины называют
математическое ожидание квадрата
отклонения случайной величины от её
математического ожидания:
![]() .
.
Средним
квадратичным отклонением случайной
величины Х называют квадратный корень
из дисперсии:
![]() .
.
Дискретное распределение (общий случай). Предположим, что известны частоты аi выбора из N объектов на определенном интервале времени, i=1,....,N. Пример таких частот для N =7 представлен в табл. 1. Первая строка таблицы - это номер объекта, а вторая -частота его выбора. Требуется разработать программную функцию, которая должна возвращать значение номера объекта в соответствии с этими частотами.
Значения обратных функций для получения дискретного распределения
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
i |
130 |
5 |
11 |
44 |
32 |
2 |
67 |
i |
0.447 |
0.017 |
0.038 |
0.151 |
0.110 |
0.007 |
0.230 |
i |
0.447 |
0.464 |
0.502 |
0.653 |
0.763 |
0.770 |
1.000 |
В оспользуемся
методом обратных функций. Сначала найдем
сумму всех частот:
оспользуемся
методом обратных функций. Сначала найдем
сумму всех частот:
В нашем случае получаем =291.
После этого построим таблицу нормированных
значений i=i/(третья
строка табл. 1.3). Далее рассчитаем значения
дискретной функции i;
по формуле
нашем случае получаем =291.
После этого построим таблицу нормированных
значений i=i/(третья
строка табл. 1.3). Далее рассчитаем значения
дискретной функции i;
по формуле
Значения i находятся в четвертой строке табл. 1.3. Построим график дискретной функции у, Далее воспользуемся рассмотренной выше программой получения случайных величин, распределенных равномерно на отрезке (0,1), и каждый раз будем получать случайную величину р,. Условимся, что То = 0 . После этого выбор объекта с номером i осуществляется при выполнении соотношения
Также для дискретных случайных величин существуют:
Биномиальное распределение, Геометрическое распределение, Гипергеометрическое распределение, Пуассоновское распределение
Вопрос 29 Непрерывные случайные величины.
Случайная величина, значения которой заполняют некоторый промежуток, называется непрерывной.
В частных случаях это может быть не один промежуток, а объединение нескольких промежутков. Промежутки могут быть конечными, полубесконечными или бесконечными, например: (a; b], (– ; a), [b;), (–; ).
Вообще непрерывная случайная величина – это абстракция. Снаряд, выпущенный из пушки, может пролететь любое расстояние, скажем, от 5 до 5,3 километров, но никому не придёт в голову измерять эту величину с точностью до 0,0000001 километра (то есть до миллиметра), не говоря уже об абсолютной точности. В практике такое расстояние будет дискретной случайной величиной, у которой одно значение от другого отличается по крайней мере на 1 метр.
При описании непрерывной случайной величины принципиально невозможно выписать и занумеровать все её значения, принадлежащие даже достаточно узкому интервалу. Эти значения образуют несчётное множество, называемое «континуум».
Если – непрерывная случайная величина, то равенство = х представляет собой, как и в случае дискретной случайной величины, некоторое случайное событие, но для непрерывной случайной величины это событие можно связать лишь с вероятностью, равной нулю, что однако не влечёт за собой невозможности события. Так, например, можно говорить, что только с вероятностью «нуль» снаряд пролетит 5245,7183 метра, или что отклонение действительного размера детали от номинального составит 0,001059 миллиметра. В этих случаях практически невозможно установить, произошло событие или нет, так как измерения величин проводятся с ограниченной точностью, и в качестве результата измерения можно фактически указать лишь границы более или менее узкого интервала, внутри которого находится измеренное значение.
Равномерное распределение на интервале (0,1).
Один из наиболее простых и эффективных вычислительных методов получения последовательности равномерно распределенных случайных чисел ri, с помощью, например, калькулятора или любого другого устройства, работающего в десятичной системе счисления, включает только одну операцию умножения.
Описанная процедура в основном применяется для получения более сложных распределений, как дискретных, так и непрерывных. Эти распределения получаются с помощью двух основных приемов:
• обратных функций;
• комбинирования величин, распределенных по другим законам, например по равномерному на интервале (0,1).
Равномерное распределение на произвольном интервале. Рассмотрим важное и очень простое равномерное распределение на интервале (m-s, m+s). Плотность вероятностей этого распределения описывается следующей формулой:

где: m - математическое ожидание;
s - максимальное отклонение от математического ожидания
Такое распределение используется, если об интервалах времени известно только то, что они имеют максимальный разброс, и ничего не известно о распределениях вероятностей этих интервалов.
Нормальное распределение. Нормальное, или гауссово распределение, - это, несомненно, одно из наиболее важных и часто используемых видов непрерывных распределений. Оно симметрично относительно математического ожидания. Сначала остановимся на практическом смысле этого распределения применительно к экономическим задачам и сформулируем центральную предельную теорему теории вероятностей в следующей практической интерпретации.
Н епрерывная
случайная величина t
имеет нормальное распределение
вероятностей с параметрами т
и
> 0, если ее плотность вроятностей имеет
вид:
епрерывная
случайная величина t
имеет нормальное распределение
вероятностей с параметрами т
и
> 0, если ее плотность вроятностей имеет
вид:
где т - математическое ожидание M[t],
- среднеквадратичное отклонение.
Причем если D[t} - это дисперсия, то = D[t] .
Практический смысл этой теоремы очень прост. Любые сложные работы на объектах экономики (ввод информации из документа в компьютер, проведение переговоров, ремонт оборудования и др.) состоят из многих коротких последовательных элементарных составляющих работ. Причем количество этих составляющих работ иногда настолько велико, что требования в приведенной выше теореме о независимости и одинаковом распределении становятся излишними. Поэтому при оценках трудозатрат всегда справедливо предположение о том, что их продолжительность - это случайная величина, которая распределена по нормальному закону.
Экспоненциальное распределение. Оно также занимает очень важное место при проведении системного анализа экономической деятельности. Этому закону распределения подчиняются многие явления, например:
• время поступления заказа на предприятие;
• посещение покупателями магазина-супермаркета;
• телефонные разговоры;
• срок службы деталей и узлов в компьютере, установленном, например, в бухгалтерии.
Рассмотрим это распределение подробнее. Если вероятность наступления события на малом интервале времени Д< очень мала и не зависит от наступления других событий, то интервалы времени между последовательностями событий распределяются по экспоненциальному закону с плотностью вероятностей

Особенностью этого распределения являются его параметры:
• математическое ожидание M[t] =1/.;
• дисперсия D[t]=2=(1/)2.;
Математическое ожидание равно среднеквадратичному отклонению, что является одним из основных свойств экспоненциального распределения
Обобщенное распределение Эрланга.
Обычно распределение Эрланга используется в случаях, когда длительность какого-либо процесса можно представить как сумму k элементарных последовательных составляющих, распределенных по экспоненциальному закону. Если обозначить математическое ожидание длительности всего процесса как M[t]= 1/, среднюю длительность элементарной составляющей как 1/, то плотность вероятностей распределения Эрланга представляется следующей формулой:

Дисперсия такого распределения D[t]=1/(2k)
Очевидно, что при k=1 - это экспоненциальное распределение. Разновидности этого распределения для разных k > 0 представлены на рис. 1.5.
Обобщенное распределение Эрланга применяется при создании как чисто математических, так и имитационных моделей в двух случаях.
1) Его удобно применять вместо нормального распределения, если модель можно свести к чисто математической задаче, применяя аппарат марковских или полумарковских процессов либо используя метод Кендалла. Однако такие модели далеко не всегда адекватны реальным процессам.
2) В реальной жизни существует объективная вероятность возникновения групп заявок в качестве реакции на какие-то действия, поэтому возникают групповые потоки. Применение чисто математических методов для исследования в моделях эффектов oi таких групповых потоков либо невозможно из-за отсутствия способа получения аналитического выражения, либо затруднено, так как аналитические выражения содержат большую систематическую погрешность из-за многочисленных допущений, благодаря которым исследователь смог получить эти выражения. Для описания одной из разновидностей 1пуппового потока можно применить обобщенное распределение Эрланга, которое рассмотрим ниже. Внешне похожее на гамма-распределение, оно имеет свои математические особенности.
Появление групповых потоков в сложных экономических системах приводит к резкому увеличению средних длительностей различных задержек (заказов в очередях, задержек платежей и др.), а также к увеличению вероятностей рисковых событий или страховых случаев.
Треугольное распределение. Применимость такого распределения связанно с динамическими характеристиками системы управления базами данных (СУБД) в экономической информационной системой.
30. Выборочный метод Монте-Карло
В случаях, когда аналитические методы неприемлемы, используют универсальный метод статистического моделирования, или, как его часто называют, метод Монте-Карло. Разыгрывание выборок по методу Монте-Карло является основным принципом моделирования систем, включающих стохастические или вероятностные факторы. Его зарождение связано с работой Дж. фон Неймана и С. Улама в конце 1940-х годов, когда они ввели термин «Монте-Карло» и применили этот метод к решению некоторых задач экранирования ядерных излучений. Этот термин был известен уже много лет, но свое второе рождение он получил, когда нашел применение в Лос-Аламосе в закрытых работах по ядерной технике, которые велись под кодовым названием «Монте-Карло». Использование метода оказалось настолько успешным, что он получил распространение и в других областях науки и техники; сегодня многим специалистам термин «метод Монте-Карло» представляется синонимом термина «имитационное моделирование». Несмотря на то что метод Монте-Карло целесообразно использовать при моделировании вероятностных ситуаций, он также применим и для решения некоторых полностью детерминистских задач, не имеющих аналитического решения.
Метод Монте-Карло - это численный метод решения математических задач с использованием моделирования случайных чисел.
Суть метода проста и состоит в следующем: вместо того чтобы описывать случайное явление с помощью аналитических зависимостей, проводят «розыгрыш» - моделирование этого явления с получением случайных результатов. При этом используют таблицы случайных чисел, колесо рулетки, компьютерные подпрограммы и др. Проведя такой «розыгрыш» очень большое число раз, получают статистический материал - множество реализаций случайного явления, - который затем обрабатывают методами математической статистики.
Метод Монте-Карло используют:
при моделировании сложных процессов, на проведение которых оказывает влияние множество различных случайных факторов;
при оценке точности аналитических методов, основанных на определенных допущениях (например, пуассоновский характер потоков событий, независимость случайных величин, отсутствие накопления ущерба и т. д.);
в целях выработки поправок к эмпирическим формулам.
31. Задачи, решаемые проведением розыгрыша
В сущности, методом Монте-Карло можно решить любую вероятностную задачу, но его использование становится целесообразным только тогда, когда проведение розыгрыша оказывается проще, а не сложнее получения аналитического решения.
Пример 1. По цели производят четыре независимых выстрела, каждый из которых попадает в нее с вероятностью р =0,5. Для поражения цели требуется не менее ю-2 попаданий. Необходимо определить вероятность поражения цели.
Аналитическое решение. Вероятность поражения Ж можно вычислить через вероятность противоположного события - непоражения цели, которое имеет место, если:
не было ни одного попадания Р04 = 0,54;
было только одно попадание

Окончательно получаем:

Метод Монте-Карло. Пусть четыре выстрела - это четыре монеты; «орел» - попадание, «решка» - промах. Опыт, или розыгрыш, - это бросание четырех монет. Цель поражена, если при четырех бросаниях будет не менее двух «орлов»; опыт повторяется много раз. Тогда согласно теореме Бернулли частота поражения будет мало отличаться от вероятности этого события W. Пусть было N опытов, из них т раз цель была поражена. Следовательно, W=m/N= 0,688.
При решении этой задачи использование метода Монте-Карло сложнее получения аналитического решения.
Пример 2. По самолету снарядами производится стрельба так, что для поражения самолета необходимо, чтобы точки попадания располагались достаточно близко друг к другу. Требуется найти закон поражения, т. е. вероятность G{m) того, что самолет будет поражен, если в него попало m снарядов. Эту задачу проще решать розыгрышем, чем расчетом.
Пусть m=5. Найдем вероятность поражения самолета, если в него попали все снаряды. Разделим проекцию самолета на k элементарных ячеек одинаковой площади, каждую из которых пронумеруем. Изготовим k жетонов (тоже пронумеруем) и заложим их во вращающийся барабан.
Проведем опыт: будем вынимать из барабана пять жетонов по одному, каждый раз возвращая жетон в барабан и перемешивая жетоны.
Пусть всего проведено N опытов, в течение которых в п случаях было зарегистрировано поражение цели, т. е. жетоны оказались расположенными близко друг к другу.
Частота поражения цели:


Путем проведения розыгрыша можно определить не только вероятность интересующих нас случайных величин, но и математические ожидания и дисперсии. Основным элементом, из совокупности которых создается статистическая модель, представляется одна случайная реализация моделируемого явления, например «один обстрел цели», «один день работы транспорта» и т. д.
Отдельную реализацию разыгрывают с помощью специально разработанного алгоритма, в котором важное значение имеет бросание жребия. Каждый раз, когда на ход явления оказывает влияние случай, это учитывается не расчетом, а жребием. Для реализации этого алгоритма необходимо использовать некоторый случайный механизм (например, бросить игральную кость или несколько монет или выбрать число из таблицы случайных чисел и т. д.) и условиться о том, какой результат означает, что произошло некоторое событие А, а какой - не означает. Такие механизмы могут быть различными, однако любой из них может быть заменен стандартным механизмом, позволяющим решить одну-единственную задачу: получить случайную величину, распределенную с постоянной плотностью от 0 до 1, которую называют «случайное число от 0 до 1» и обозначают R или U.
Условимся называть единичным жребием любой опыт со случайным исходом, проведение которого позволяет ответить на один из следующих вопросов.
Произошло событие А или нет? Пусть Р(А) = Р. С помощью стандартного механизма получим R (Приложение 2). Считаем, если R<P - событие произошло, а если R>P - событие не произошло.
Какое из событий А,, А2, ..., Ак произошло? Имеется полная группа несовместных событий Ah А2, ..., А„ с вероятностями Pt, Рг, Рп, при этом Pi + Р> + ... + Р„ = \. Если R, полученное с помощью стандартного механизма, выпало на участок Ри считаем, что событие А, произошло.
Какое значение приняла случайная величина Х. Пусть случайная величина непрерывна и имеет заданную непрерывную функцию распределения F(x). Из рис. 2.24 следует, что при Х<х величина R< F(х), т. е. P(X<x)^P(R< F{x)). Если взять на оси ординат случайное число R (от О до 1) и найти значение X, при котором F(X) = R, то полученная случайная величина X будет иметь функцию распределения F(x).
Следовательно, розыгрыш значения случайной величины X с заданной функцией распределения F (х) сводится к следующему:
получить случайное число R (от 0 до 1),
в качестве значения X использовать Х- F~l{R), где F~l - функция, обратная функции F.
При разработке имитационной модели, включающей стохастические или вероятностные элементы, всегда возникает вопрос: следует ли при использовании метода Монте-Карло применять эмпирические данные или же надо воспользоваться одним из теоретических распределений? Ответ на этот вопрос достаточно
прост: если есть возможность использовать теоретические распределения, модель, как правило, получается лучше с учетом общности результатов и удобства ее применения.
В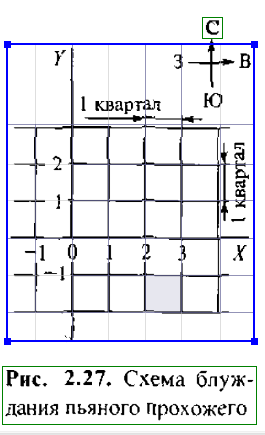 целях иллюстрации этого метода рассмотрим
классическую задачу о пьяном прохожем,
которую также называют задачей о
случайном блуждании. Предположим,
что пьяный, стоя на углу улицы, решил
прогуляться, чтобы развеять хмель. Пусть
известны вероятности того, что, идя до
очередного перекрестка, он пройдет на
север, юг, восток или запад. Необходимо
найти вероятность того, что, пройдя 10
кварталов, пьяный окажется не далее
двух кварталов от места, от которого он
начал прогулку. Схема блуждания пьяного
прохожего приведена на рис. 2.27.
целях иллюстрации этого метода рассмотрим
классическую задачу о пьяном прохожем,
которую также называют задачей о
случайном блуждании. Предположим,
что пьяный, стоя на углу улицы, решил
прогуляться, чтобы развеять хмель. Пусть
известны вероятности того, что, идя до
очередного перекрестка, он пройдет на
север, юг, восток или запад. Необходимо
найти вероятность того, что, пройдя 10
кварталов, пьяный окажется не далее
двух кварталов от места, от которого он
начал прогулку. Схема блуждания пьяного
прохожего приведена на рис. 2.27.
Начнем с того, что обозначим местоположение пьяного на каждом перекрестке двухмерным вектором (A'. Y), где X - направление с запада на восток, a Y - направление с юга на север. Каждое перемещение на один квартал к востоку соответствует увеличению А7 на 1, а каждое перемещение на один квартал к западу - уменьшению А' на 1 - Подобным же образом при передвижении пьяного на один квартал к северу Г увеличивается на 1, а на один квартал к югу - уменьшается на 1. Если обозначить начальное положение (0, 0), то на каждом этапе прогулки можно точно знать, где находится пьяный относительно этого положения. В случае, если в конце прогулки протяженностью в 10 кварталов окажется, что сумма абсолютных значений X и Y больше 2, то, следовательно, пьяный ушел от начальной точки дальше, чем на два квартала. Разыгрывая случайные числа по схеме «какое событие произошло?» на каждом перекрестке, можно определить, где окажется пьяный через 10 кварталов. Эти розыгрыши следует повторять необходимое число раз, чтобы с достаточной степенью уверенности (с некоторой вероятностью) ответить на поставленный вопрос. В зависимости от различных привходящих обстоятельств можно изменять как вероятности выбора направления движения, так и цель пьяного блуждания.
Вопрос 32
Основные понятия математическая статистика
Математические законы теории вероятностей не являются беспредметными абстракциями, не имеющими физического смысла; они представляют собой математическое выражение закономерностей, реально существующих в случайных массовых явлениях природы. Разработка методов регистрации, описания и анализа статистических экспериментальных данных, получаемых в результате наблюдений этих явлений, составляет предмет специальной науки - математической статистики.
Рассмотрим вкратце некоторые типичные задачи математической статистики, часто встречаемые на практике.
В реальных условиях всегда приходится оперировать с ограниченным количеством экспериментальных данных, в связи с чем результаты наблюдений и их обработка всегда в той или иной степени носят случайный характер. Возникает вопрос: какие черты являются постоянными, а какие - случайными, встречающимися в конкретной серии наблюдений только из-за ограниченного объема экспериментальных данных? В связи с этим встает задача выравнивания статистических данных (регрессионный анализ).
Статистический материал может с большей или меньшей степенью достоверности подтверждать справедливость той или иной гипотезы. Например, может возникнуть такой вопрос: согласуются ли результаты эксперимента с гипотезой о том, что данная случайная величина подчинена закону распределения f(x) (проверка гипотез)? Кроме того, может появиться другой вопрос; указывает ли наблюдаемая в опыте тенденция к зависимости между двумя случайными величинами на наличие действительной объективной зависимости между ними или же она объясняется случайными причинами, связанными с недостаточным объемом наблюдений (корреляционный анализу).
Зачастую приходится решать задачу определения некоторых параметров случайной величины на основе экспериментального материала. Это так называемая задача оценок искомых параметров, т. е. нахождение таких их приближенных значений, использование которых при массовом применении приводило бы в среднем к меньшим ошибкам (доверительный интервал и доверительная вероятность). Это далеко не полный перечень основных задач математической статистики.
Математическая (или теоретическая) статистика опирается на методы и понятия теории вероятностей, но решает в каком-то смысле обратные задачи.
В теории вероятностей рассматриваются случайные величины с заданным распределением или случайные эксперименты, свойства которых целиком известны. Предмет теории вероятностей — свойства и взаимосвязи этих величин (распределений).
Но часто эксперимент представляет собой черный ящик, выдающий лишь некие результаты, по которым требуется сделать вывод о свойствах самого эксперимента. Наблюдатель имеет набор числовых (или их можно сделать числовыми) результатов, полученных повторением одного и того же случайного эксперимента в одинаковых условиях.
1. В математике сформировалась новая область — математическая статистика, изучающая общие закономерности статистических данных или явлений и взаимосвязи между ними.
Сфера применения математической статистики распространилась во многие, особенно экспериментальные, науки. Так появились экономическая статистика, медицинская статистика, биологическая статистика, статистическая физика и т.д. С появлением быстродействующих ЭВМ возможность применения математической статистики в различных сферах деятельности человека постоянно возрастает. Расширяется ее приложение и к области физической культуры и спорта. В связи с этим основные понятия, положения и некоторые методы математической статистики рассматриваются в курсе “Спортивная метрология”. Остановимся на некоторых основных понятиях математической статистики.
2. Статистические данные
В настоящее время под термином "статистические данные" понимают все собранные сведения, которые в дальнейшем подвергаются статистической обработке. В различной литературе их еще называют: переменные, варианты, величины, даты и т.д. Все статистические данные можно разделить на: качественные, труднодоступные для измерения (имеется, не имеется; больше, меньше; сильно, слабо; красный, черный; мужской, женский и т.д.), и количественные , которые можно измерить и представить в виде числа общих мер (2 кг, 3 м, 10 раз, 15 с и т.д.); точные , величина или качество которых не вызывают сомнений (в группе 6 человек, 5 столов, деревянный, металлический, мужской, женский и т.д.), и приближенные , величина или качество которых вызывает сомнение (все измерения: рост 170 см, вес 56 кг, результат бега на 100 м - 10,3 с и т.д.; близкие понятия — синий, голубой, мокрый, влажный и т.д.); определенные (детерминированные), причины появления, не появления или изменения которых известны (2 + 3 = 5, подброшенный вверх камень обязательно будет иметь вертикальную скорость, равную 0 и т.д.), и случайные , которые могут появляться и не появляться или не все причины изменения которых известны (пойдет дождь или нет, родится девочка или мальчик, команда выиграет или нет, в беге на 100 м — 12,2 с, принятая нагрузка вредна или нет). В большинстве случаев в физической культуре и спорте мы имеем дело с приближенными случайными данными.
3. Статистические признаки, совокупности
Общее свойство, присущее нескольким статистическим данным, называют их статистическим признаком . Например, рост игроков команды, результат бега на 100 м, принадлежность к виду спорта, частота сердечных сокращений и т.д.
Статистической совокупностью называют несколько статистических данных, объединенных в группу хотя бы одним статистическим признаком. Например, 7.50, 7.30, 7.21, 7.77 — результаты прыжка в длину в метрах у одного спортсмена; 10, 12, 15, 11, 11 — результаты подтягивания на перекладине пяти студентов и т.д. Число данных в статистической совокупности называют ее объемом и обозначают n . Различают следующие совокупности:
бесконечные — n (масса планет Вселенной, число молекул и т.д.); конечные — n - конечное число; большие — n > 30; малые — n 30;
генеральные — содержащие все данные, обусловленные постановкой задачи;
выборочные — части генеральных совокупностей.
Например, пусть рост студентов 17-22 лет в РФ — генеральная совокупность, тогда рост студентов КГАФК, всех студентов города Краснодара или студентов II курса — выборки.
4. Кривая нормального распределения
При анализе распределения результатов измерений всегда делают предположение о том распределении, которое имела бы выборка, если бы число измерений было очень большим. Такое распределение (очень большой выборки) называют распределением генеральной совокупности или теоретическим , а распределение экспериментального ряда измерений — эмпирическим.
Теоретическое распределение большинства результатов измерений описывается формулой нормального распределения, которая впервые была найдена английским математиком Муавром в 1733 г.:

5. Виды представления статистических данных
После того, как определена выборка и стали известны ее статистические данные (варианты, даты, элементы и т.д.), возникает необходимость представить эти данные в удобном для решения задачи виде. На практике используют много различных видов представления статистических данных. Наиболее часто употребляют следующие:
а) текстовый вид;
б) табличный вид;
в) вариационный ряд;
г) графический вид.
33. Программное обеспечение имитационного моделирования
При ИМ используют вычислительные системы трех типов - универсальные ЭВМ, электронные аналоговые машины и гибридные ЭВМ. Преимущества каждой из них определяются спецификой основных свойств аналоговых и цифровых ЭВМ. Аналоговая вычислительная машина (АВМ) представляет переменные параметры в виде легкогенерируемых и управляемых физических величин, например электрического напряжения. С ее помощью получают решение, выполняя операции параллельно, в то время как цифровая ЭВМ производит операции последовательно (сериями). Это дает АВМ существенное преимущество в скорости вычислений, особенно при решении систем дифференциальных уравнений.
В то же время цифровая ЭВМ может обеспечивать большую точность и расширенный функциональный диапазон в результате возможности считать, подчиняться логическим правилам, работать с плавающей точкой и использовать длинные слова. Таким образом, одно из основных различий между АВМ и цифровыми ЭВМ заключается в способе обработки зависимых переменных. В АВМ для записи таких переменных (к независимым переменным это может и не относиться) используется непрерывная форма. В цифровых же ЭВМ все переменные (зависимые и независимые) представляются только в дискретном виде. Точность чисел (т. е. количество значимых цифр) в АВМ ограничена качеством компонентов ее электрических цепей, в то время как точность цифровых ЭВМ зависит от количества разрядов и ограничена лишь размером или объемом регистров памяти.
В целом с любой задачей, которую решает АВМ, может справиться и мощная цифровая ЭВМ. Но на АВМ решать многие задачи можно быстрее, легче и дешевле.
При создании гибридных вычислительных систем сделана попытка объединить преимущества, присущие аналоговым и цифровым машинам, и устранить их недостатки. Некоторые типы задач обусловливают необходимость усовершенствовать цифровую ЭВМ добавлением аналоговой части для увеличения скорости расчетов. В то же время в аналоговых системах желательно обеспечить высокую точность вычислений, гибкость, а также возможность как хранения данных, так и использования логических функций, характерных для цифровых ЭВМ.
Применение гибридных вычислительных систем в настоящее время, как правило, целесообразно, поскольку они позволяют устранить недостатки, присущие как аналоговым, так и цифровым машинам. Однако по мере устранения этих недостатков преимущества гибридных ЭВМ при имитационном моделировании будут не столь очевидны. Например, уже в настоящее время большее быстродействие, меньшая стоимость, оперативный режим разделения времени в больших цифровых вычислительных системах значительно сузили диапазон применения гибридных систем.
При рассмотрении преимуществ и недостатков аналоговых, цифровых и гибридных вычислительных машин было установлено, что для машинного ИМ можно использовать не только цифровую технику. При определенных обстоятельствах более предпочтительными могут оказаться аналоговые и гибридные машины. Желательно, чтобы исследователь имел возможность выбирать наиболее подходящую вычислительную машину. К сожалению, не каждый имеет доступ ко всем трем типам вычислительных машин, и на практике, вероятнее всего, используется та машина, которая имеется в распоряжении.
34. Особенности выбора программного обеспечения имитационного моделирования
При разработке имитационных моделей предъявляют определенные требования к функциональным возможностям, необходимым для программирования большинства дискретно-событийных моделей. К таким возможностям относятся:
генерирование случайных величин с заданным распределением вероятностей (например, с экспоненциальным распределением);
продвижение часов модельного времени;
- определение каждого следующего события по списку событий;
добавление или удаление записей из списка;
-сбор и обработка выходных статистических данных и составление отчета с полученными результатами;
определение сбойных ситуаций.
В сущности, именно эти и некоторые другие общие функциональные возможности в моделирующих программах позволили разработать специальные программные пакеты ИМ. Более того, дальнейшее усовершенствование таких пакетов и простота их применения способствовали росту популярности ИМ в последние годы.
Одно из наиболее важных решений, которые приходится принимать разработчикам моделей или аналитикам, касается выбора программного обеспечения (ПО). Если ПО недостаточно гибко или с ним сложно работать, то ИМ может дать неверные результаты или оказаться вообще невыполнимым.
Использование пакета DM по сравнению с применением универсального языка программирования имеет несколько преимуществ.
Пакеты ИМ автоматически предоставляют большинство функциональных возможностей, требующихся для создания имитационной модели, что позволяет существенно сократить время, необходимое для программирования, и общую стоимость проекта.
Пакеты ИМ обеспечивают естественную среду для создания имитационных моделей. Их основные моделирующие конструкции больше подходят для имитационного моделирования, чем соответствующие конструкции в универсальных языках программирования.
Имитационные модели, которые созданы с помощью пакетов моделирования, как правило, проще модифицировать и использовать.
Пакеты ИМ обеспечивают более совершенные механизмы обнаружения ошибок, поскольку они выполняют автоматический поиск ошибок многих типов. И так как для использования модели не требуется большого числа структурных компонентов, вероятность совершить какую-либо ошибку снижается.
Тем не менее некоторые имитационные модели (особенно относящиеся к задачам оборонной сферы) по-прежнему создают с помощью универсальных языков программирования, которые также обладают некоторыми преимуществами.
.Языки программирования знает большинство разработчиков, чего нельзя сказать о пакетах ИМ.
Скорость выполнения прогона имитационных моделей, написанных на языках программирования, обычно больше, чем моделей, созданных с помощью пакетов имитационного моделирования. Это связано с тем, что такие пакеты часто разрабатывают для различных систем посредством одного набора моделирующих конструкций, тогда как программа на языке программирования может быть более удачно написана для конкретной системы. Однако с распространением недорогих быстродействующих персональных компьютеров это преимущество несколько утратило свою актуальность.
3.При программировании универсальные языки обеспечивают большую гибкость, чем пакеты ИМ.
4.Стоимость универсального ПО обычно ниже стоимости пакета ИМ, хотя не всегда ниже общей стоимости проекта.
Таким образом, поскольку применение обоих методов имеет определенные преимущества, разработчику моделей следует очень серьезно подходить к выбору каждого из них. Если же выбор сделан в пользу пакетов ИМ, по критериям и характеристикам, которые используются при создании модели, можно решить, какой конкретно пакет лучше выбрать.
35. Классификация программных средств имитационного моделирования
Пакеты ИМ разделены на два основных типа: языки ИМ и предметно-ориентированные программы моделирования. Языки ИМ являются универсальными. Их использование расширяет возможности в процессе моделирования, яо зачастую их применение затруднительно. Программы моделирования ориентированы на решение определенной задачи, в них модель разрабатывается с использованием графики, диалоговых окон и раскрывающихся меню. Такие программы проще изучать и реализовывать, но они не всегда могут обеспечить достаточную гибкость при ИМ.
В последние годы создатели языков ИМ попытались сделать ПО более простым в употреблении. Для этого они использовали графический подход с применением пиктограмм для построения Модели. Вначале разработчик выбирает пиктограммы с помощью мыши и помещает их в рабочую область. Затем он соединяет пиктограммы, чтобы обозначить именованные потоки в исследуемой системе. Двойным щелчком мышью на пиктограмме можно вывести диалоговое окно, где уточняются параметры для добавляемых пиктограмм. Предположим, пиктограмма представляет устройство обслуживания в какой-либо системе, в этом случае диалоговое окно позволяет уточнить информацию о числе параллельных устройств обслуживания, распределении времени обслуживания для каждого из них, о том, может ли устройство прийти в неисправность (если может, то каким образом). В то же время разработчики предметно-ориентированных программ моделирования сделали программные средства более гибкими, обеспечив возможность программировать с использованием псевдоязыка. По крайней мере, в одной программе моделирования сейчас можно изменять существующие конструкции и создавать новые. Это привело к тому, что отличия между языками ИМ и программами моделирования стали менее заметными.
Таким образом, существуют два типа пакетов ИМ. Универсальные пакеты предназначены для различных целей, но они могут иметь специальные функции для решения одного конкретного вида задач (например, моделирования производственных систем, систем связи или модернизации технологий производства). К таким пакетам можно отнести следующие: АРЕНА, EXTEND и GPSS (США).
Предметно-ориентированные пакеты ИМ используют для решения таких специальных задач, как моделирование работы производственных систем, медицинских учреждений, центров выполнения заказов.
Для создания имитационных моделей существуют различные подходы, но, прежде чем переходить к их рассмотрению, отметим некоторые особенности процесса продвижения часов модельного времени. В имитационной модели переменная, обеспечивающая текущее значение времени, называется часами модельного времени. При использовании дискретно-событийных имитационных моделей требуется следить за текущим значением модельного времени. При этом также необходим механизм для продвижения модельного времени от одного значения к другому. В случае применения универсальных языков единица времени для часов модельного времени явно никогда не устанавливается. К тому же модельное время и время, необходимое для прогона имитационной модели на компьютере, как правило, соотнести невозможно.
Существуют два основных подхода к продвижению часов модельного времени: продвижение времени от события к событию и продвижение времени посредством постоянного шага. Первый подход используется во всех основных имитационных программах большинством разработчиков, создающих модели на универсальных языках. С учетом этого, а также того, что второй подход является разновидностью первого, в дискретно-событийных моделях, рассматриваемых в этой книге, применяется такой подход, как продвижение времени от события к событию. При использовании этого подхода часы модельного времени в исходном состоянии устанавливаются в положение 0 и определяется время возникновения будущих событий. После этого часы модельного времени переходят на время возникновения ближайшего события; при этом состояние системы с учетом происшедшего события, а также сведения о времени появления будущих событий обновляются. Затем часы модельного времени продвигаются ко времени возникновения следующего (нового) ближайшего события, состояние системы обновляется, определяется время будущих событий и т. д. Процесс продвижения часов модельного времени от времени возникновения одного события ко времени возникновения другого продолжается до тех пор, пока не будет выполнено какое-либо условие останова, указанное заранее. Поскольку в дискретно-событийной имитационной модели все изменения происходят только во время возникновения событий, периоды бездействия системы просто пропускаются, и часы переводятся со времени возникновения одного события на время возникновения другого. (При продвижении часов модельного времени с постоянным шагом такие периоды бездействия не пропускаются, что приводит к большим затратам компьютерного времени.) Следует отметить, что длительность интервала продвижения часов модельного времени от одного события к другому может быть различной.
36. Возможности при использовании программ имитационного моделирования
При выборе программных средств ИМ следует учитывать все имеющиеся в случае их использования возможности:
быстродействие, объем памяти и др.;
совместимость оборудования и ПО;
анимацию;
средства получения и обработки статистических данных;
услуги, предоставляемые заказчикам, и документацию;
отчеты с выходными данными и графиками.
Самым важным свойством, которым должен обладать программный продукт ИМ, является гибкость, т. е. возможность моделировать системы с различным уровнем сложности технологических процессов. Поскольку двух полностью идентичных систем не существует, пакет ИМ, в котором применяется фиксированное число моделирующих конструкций и нет возможности программирования, для некоторых систем, несомненно, окажется непригодным. В идеале должна быть возможность моделирования любой системы с использованием только имеющегося программного пакета без применения программ, написанных на каком-либо другом языке. Некоторые возможности ПО, придающие гибкость программному продукту ИМ, перечислены ниже:
определять и изменять атрибуты объектов и основных переменных, а также применять их в логике решений (например, конструкции if.. .then., .else);
использовать математические выражения и функции (логарифмирование, возведение в степень и т. п.);
создавать новые моделирующие конструкции и изменять уже существующие, а также применять их в модифицированном виде.
Следующим важным свойством средств ИМ является простота в применении; многие современные пакеты моделирования снабжены графическим интерфейсом пользователя. В таких пакетах должны быть моделирующие конструктивные элементы (например, пиктограммы или блоки), не слишком примитивные, но и не слишком сложные. В первом случае понадобится очень много конструктивных элементов для моделирования даже достаточно простой ситуации; во втором же случае диалоговое окно каждого такого элемента будет содержать слишком большое число параметров, необходимых для обеспечения соответствующей гибкости программы. Управлять такими параметрами можно с помощью вкладок в диалоговых окнах.
При исследовании сложных систем может оказаться целесообразным иерархическое моделирование. Использование иерархии позволяет сгруппировать несколько основных конструктивных элементов в новые структурные элементы более высокого уровня. В дальнейшем эти элементы можно объединить в структурные элементы еще более высокого уровня и т. д. Последние структурные элементы помещают в библиотеку доступных структурных элементов для их повторного использования. Повторное применение частей модели с расширением логических возможностей позволяет повысить эффективность моделирования. Иерархия является важной концепцией многих пакетов моделирования. Ее использование также дает возможность избежать неясностей на экране в графически ориентированных моделях, состоящих из множества пиктограмм и блоков.
Программное обеспечение должно быть снабжено такими средствами отладки, как интерактивный отладчик. Использование мощного отладчика позволяет:
отслеживать отдельные объекты по всей модели, чтобы убедиться в правильности их обработки;
проверить состояние модели при каждом возникновении некоторого события (например, при поломке станка);
устанавливать значения определенных переменных для продвижения событий до конца по логическому пути, встречающемуся с малой вероятностью.
При моделировании некоторых систем очень важное значение имеет высокая скорость работы модели. В первую очередь это касается моделей военных систем и моделей, тогда требуется обрабатывать большое количество событий (например, модель быстродействующей сети связи). Для использования имитационной модели кем-либо, кроме разработчика, желательно, чтобы имелась возможность создания такого интерфейса, с помощью которого неспециалист смог бы легко ввести параметры ИМ.