

5.4. Висновки
Ідентифікація класів і об'єктів — найважливіше завдання об’єктно-орієнтованого проектування; процес ідентифікації складається з відкриття й винаходу.
Класифікація є проблемою групування (кластеризації) об'єктів.
Класифікація — процес послідовних наближень; проблеми класифікації обумовлені, в основному, тим, що є багато рівноправних рішень.
Є три підходи до класифікації: класичний розподіл за категоріями (класифікація за властивостями), концептуальна кластеризація (класифікація за поняттями) і теорія прототипів (класифікація за подібністю із прототипом).
Метод сценаріїв — це потужний засіб об’єктно-орієнтованого аналізу, його можна використати для інших методів: класичного аналізу, аналізу поведінки й аналізу предметної області.
Ключові абстракції відображають словник предметної області; їх шукають в самій області або придумують у процесі проектування.
Механізми позначають стратегічні проектні рішення щодо спільної діяльності об'єктів багатьох різних типів.
Запитання для повторення та контролю знань
1. Важливість правильної класифікації.
2. Складнощі класифікації.
3. Ідентифікація класів і об'єктів.
4. CRC-картки.
5. Ключові абстракції.
6. Ідентифікація механізмів.
РОЗДІЛ 6. ОНТОЛОГІЇ Й ОНТОЛОГІЧНІ СИСТЕМИ
Основні визначення
Моделі онтологій. Онтологічні системи
Системи і засоби подання онтологічних знань
У цьому розділі дається поняття онтології, розглядаються онтологічні системи. Описано моделі онтологій і їх використання під час розроблення інтелектуальних систем. У кінці розділу описано системи та засоби подання онтологічних знань.
6.1. Поняття онтології
Онтологія (від грец. онтос — суще, логос — навчання, поняття) — термін, що визначає вчення про буття, про сутність, на відміну від гносеології — вчення про пізнання. Вже у X.Вольфа (1679-1754), автора терміну «онтологія», вчення про буття було відокремлене від вчення про пізнання. Tермін введений у філософську літературу німецьким філософом Р.Гокленіусом (1547-1628). До цього онтологія була частиною метафізики, наукою самостійною, незалежною і не пов’язаною з логікою, з «практичною філософією», з науками про природу. Її предмет складає вивчення абстрактних і загальних філософських категорій, таких як буття, субстанція, причина, дія, явище тощо, а сама онтологія як наука домагалася повного пояснення причин усіх явищ.
Зрозуміло, що таке визначення трохи недоречне для практичного використання, але дає поштовх для подальшої конкретизації й обговорення, виходячи з цілей цього видання. У цьому значенні цікавіше визначення онтології, запропоноване в межах розроблення системи стандартів на мультиаґентні системи міжнародним співтовариством FIPA (Foundation for Intelligent Physical Agents). У філософському розумінні можна посилатися на онтологію як на певну систему категорій, що є наслідком певного погляду на світ.
При цьому сама система категорій не залежить від конкретної мови: онтологія Арістотеля завжди одна і та сама, незалежно від мови, використаної для її опису.
З іншої точки зору, ближчої до понять, пов’язаних зі штучним інтелектом, онтологія — це знання, формально відображені на базі концептуалізації. Концептуалізація, як вже обговорювалося вище, припускає опис безлічі об’єктів і понять, знань про них і зв’язків між ними. Отже, онтологією називається експліцитна специфікація концептуалізації. Формально онтологія складається з термінів, організованих в таксономію, їх визначень і атрибутів, а також пов’язаних з ними аксіом і правил виведення.
Часто набір припущень, що становлять онтологію, має форму логічної теорії першого порядку, де терміни словника є іменами унарних і бінарних предикатів, званих відповідно концептами і відношеннями. У простому випадку онтологія описує тільки ієрархію концептів, зв’язаних відношеннями категоризації. У складніших випадках в неї додаються відповідні аксіоми для вираження інших відношень між концептами і для того, щоб обмежити їх передбачувану інтерпретацію. Враховуючи вищесказане, онтологія є базою знань, що описує факти, які передбачаються завжди істинними в рамках певної спільноти на основі загальноприйнятого значення використовуваного словника.
Ще конкретнішим поняття онтології є у відомому проекті Оntolingua, який активно розробляється у Стенфордському університеті. Тут передбачається, що онтологія — це експліцитна специфікація певної теми.
Такий підхід припускає формальне і декларативне подання деякої теми, яке включає словник (або список констант) для посилання до термінів предметної області, обмеження цілісності на терміни, логічні твердження, які обмежують інтерпретацію термінів і те, як вони поєднуються один з одним.
Резюмуючи вищесказане, можна констатувати, що на сьогодні розуміння терміну «онтологія» різне, залежно від контексту і цілей його використання. У роботі [44] дане достатньо змістовне і цікаве обговорення цих питань, яке зводиться до того, що тут виділяються такі аспекти інтерпретації цього терміну:
онтологія як філософська дисципліна;
онтологія як неформальна концептуальна система;
онтологія як формальний погляд на семантику;
онтологія як специфікація «концептуалізації»;
онтологія як уявлення концептуальної системи через логічну теорію, що характеризується:
спеціальними формальними властивостями,
її призначенням;
онтологія як словник, використовуваний логічною теорією;
онтологія як метарівнева специфікація логічної теорії.
Зазначимо, що перша інтерпретація радикально відрізняється від інших і пов’язана, як пропонують автори вищезгаданої роботи, з тим, що тут ми говоримо про Онтологію (з великої літери) і маємо на увазі філософську дисципліну, що вивчає, за Арістотелем, природу й організацію сущого. У цьому значенні Онтологія намагається відповісти на запитання: «Що є суще?» або, в іншому формулюванні, на запитання: «Які властивості є загальними для всього сущого?». Коли ж ми говоримо про онтологію (з маленької літери), то посилаємося на об’єкт, природа якого може бути різною, залежно від вибору між інтерпретаціями 2-7. За другою інтерпретацією онтологія є концептуальною системою, яку ми можемо припускати як базис визначеної БЗ. Згідно з інтерпретацією 3 онтологія, на основі якої побудована БЗ, виражається в термінах відповідних формальних структур на семантичному рівні. Отже, ці дві інтерпретації розглядають онтологію як концептуальну «семантичну» сутність, неважливо — формальну чи неформальну, тоді як інтерпретації 5-7 трактують онтологію як спеціальний «синтаксичний» об’єкт. Інтерпретація, що залишилася, четверта, яка була запропонована Грубером як визначення онтології для використання в рамках ШІ-спільноти, — одна з найпроблематичніших, оскільки точне значення її залежить від розуміння термінів «специфікація» і «концептуалізація». І разом з тим, саме це визначення найчастіше і використовується сьогодні в роботах з проектування і дослідження онтології.
Для визначеності подальшого викладу ми вважатимемо, що онтології — це бази знань (БЗ) спеціального типу, які можуть «читатися» і розумітися, відчужуватися від розробника чи фізично розділятися їх користувачами.
При цьому онтологічний інжиніринґ — гілка інженерії знань, яка використовує Онтологію (з великої букви) для побудови онтології (з маленької букви). Зрозуміло, що будь-яка онтологія має під собою концептуалізацію, але одна концептуалізація може бути основою різних онтологій, і дві різні БЗ можуть відображати одну онтологію.
Історично, онтології виникли з гілки філософії, відомої як метафізика, яка працює з природою реальності та буття. Ця фундаментальна гілка аналізує різноманітні типи моделей буття, часто з особливою увагою до зв’язків між частковим і загальним, внутрішнім і зовнішнім, існуванням і буттям.
У середині 70-х років ХХ ст. дослідники в галузі штучного інтелекту зрозуміли, що збирання знань — це ключ до побудови великих і потужних систем штучного інтелекту. Дослідники обговорювали можливість створення онтологій як інструменту чисельного моделювання, що дає змогу виконувати логічне виведення знань. У 80-х роках ХХ ст. дослідники прийшли до висновку, що термін «онтологія» може використовуватися у двох значеннях. По-перше, онтологія — це компонент систем, що базуються на знаннях, по-друге, — це змодельована за допомогою формальних засобів частина реального світу.
На початку 90-х минулого століття років робота Тома Грубера «Майбутні принципи проектування онтологій для поширення та колективного використання знань» містила визначення онтології як технічного терміну в комп’ютерних науках. Грубер описував термін «онтологія» як специфікацію концептуалізації деякої області. Це означало, що онтологія — це опис концептів і зв’язків між ними, які існують для деякої множини аґентів. Це визначення узгоджується з використанням онтологій як множини визначень концептів, але є більш загальним, і, звичайно, має інший сенс, ніж у філософії. Онтології часто порівнюють з таксономічними ієрархіями класів і з визначеннями класів з категоризацією зв’язків, але онтології не обмежуються лише цими формами. Онтології не обмежуються консервативними визначеннями, на зразок систем теорем та аксіом.
Формування семантичного Webу почалось з розроблення мови RDF консорціумом W3C. Але історія роботи з метаданими у W3C почалася 1995 року з появою PICS (Platform for Internet Content Selection). PICS — це механізм для передавання комунікаційних ярликів Web-сторінок від сервера до клієнта. Ці ярлики містили інформацію про вміст Web-сторінок, для прикладу, про рецензовані наукові статті, розміщені на сторінці, чи про авторизацію ресурсу акредитованим дослідником. Також ярлики часто містили публічні дані авторів сторінок, посилання на іншомовні версії сторінки тощо. Замість того, щоб визначити фіксований набір критеріїв, PICS забезпечувала загальний механізм створення ярликових систем. Різні організації визначали власний вміст сайту, залежно від їхніх цілей, необхідності і користувачів. Розроблення PICS мотивувалося тим, що назрівають зміни у Webі, причому ці зміни мали стосуватися, в основному, різного роду обмежень у США та інших країнах.
Після серії обговорень, були ідентифіковані обмеження в PICS, і змінилися функціональні вимоги. Вимоги почали охоплювати загальніші проблеми, ніж асоціація дескриптивної інформації з Інтернет-ресурсами, базованими на PICS архітектурі. Як результат, W3C створив нову робочу групу PICS-NG (Next Generation), яка почала досліджувати загальніші проблеми опису ресурсів.
Через деякий час нова команда розробила попередню специфікацію документу PICSMOD, який визначав новий формат. Цей формат відразу був застосований у кількох, різних за своєю структурою, аплікаціях і при цьому він залишився незмінним. Побачивши результат, W3C сконсолідував групу для роботи над RDF. Нова група була названа «W3C Resource Description Framework working group».
Мова RDF стала результатом роботи численних об’єднань спеціалістів, що займалися дослідженням метаданих. У RDF є кілька попередників. Технічно найближчим до RDF був проект MCF, ініційований Раманатаном Гуа в компанії «Apple Computer» і продовжений після купівлі цього проекту компанією Netscape. Ідеї «Dublin Core» та PICS також мали ключове значення при створенні RDF.
Специфікація RDF-моделі та її XML-синтаксис був опублікований 1999 року у вигляді W3C-рекомендації. Потім почалася робота над створенням нових пов’язаних специфікацій, які були опубліковані 2004 року.
Історія онтологічних розроблень у комп’ютерних науках досить давня. Починаючи з 90-х минулого століття років частина дослідників намагалася поширити ідеї про використання знань у Webі. Ці дослідження включали створення різноманітних мов, базованих на HTML (наприклад, SHOE), на XML(XOL, пізніше OIL) та на фреймах.
OWL, в основному, базований на дослідженнях DARPA (Defense Advanced Research Projects Agency), які створили мову DAML+OIL. Вона своєю чергою, базувалася на мовах DAML та OIL.
World Wide Web Consortium створив робочу групу "Web Ontology Working Group", яка почала роботу 1 листопада 2001 року очолювалася Джеймсом Хендлером та Гусом Скрейбером. Перший робочий документ був опублікований в липні 2002 року. Документ став офіційною рекомендацією W3C 10 лютого 2004 року. Група була розформована 31 травня 2004 року.
Одним із найскладніших і найдовших етапів у формуванні семантичного Webу є створення SPARQL (Simple Protocol and RDF Query Language) — мови запитів до RDF, яка розроблена групою DAWG (RDF Data Access Working Group).
Спочатку, в квітні 2006 року, SPARQL була подана як кандидат W3C рекомендації, але потім її повернули на доопрацювання у статусі робочого стандарту. У червні 2007 року SPARQL знову висувається в кандидати до рекомендації. 12 листопада 2007 року SPARQL став запропонована до рекомендації і 15 січня 2008 року стала офіційною рекомендацією W3C.
Мова SPARQL дозволяє робити запити за допомогою триплетів «суб’єкт-предикат-об’єкт», кон’юнкцій, диз’юнкцій та необов’язкових шаблонів. Існує кілька реалізацій SPARQL для програмних мов, зокрема для Java.
Загалом RDF, SPARQL та OWL створюють цілісну картину засобів семантичного Webу, необхідних для побудови онтологічних моделей.
У книзі «Семантичний Web: введення в майбутнє XML, Web сервісів та управління знаннями» М. Даконта та інші автори описали, що таке RDF, чому вона не користувалася популярністю і чому виникли онтології. Автору дають таке пояснення, що таке RDF. На найпростішому рівні RDF є XML базованою мовою для опису ресурсів. Якщо XML має метадані лише в частині документу, то RDF описує всі метадані, які необхідні для опису знань в документі. Дуже хорошим прикладом використання RDF є опис ресурсів, які є невидимими для користувача, наприклад, аудіофайли.
Модель RDF складається із тверджень (триплетів), кожен з яких складається з суб’єкта, предиката та об’єкту. На рис. 6.1 наведено RDF-твердження.

Рис. 6.1. RDF твердження.
Суб’єкт. Граматично суб’єкт — це іменник, який в реченні виконує певну дію. Наприклад, у реченні «Компанія купує продукт» суб’єктом є «компанія». У RDF суб’єкт — це ресурс, інформація про який описується в предикаті та об’єкті. Тому для ідентифікації суб’єкту використовується URI (Unified Resource Identifier), наприклад, «http://www.business.org/ontology/#company».
Предикат. Граматично предикат є дієсловом чи дієслівним зворотом, наприклад, у тому самому реченні «Компанія купує продукт» предикат — «купує». Іншими словами предикат каже нам щось про суб’єкт. У RDF предикат є зв’язком між суб’єктом та об’єктом. Тому, предикат у RDF подається як URI на зразок: «http://www.business.org/ontology/#buy» .
Об’єкт. Граматично об’єкт є іменником, якого стосується дія задана в дієслові (предикаті). У попередньому прикладі об’єктом є «продукт». У RDF об’єкт — це ресурс або літерал, пов’язаний предикатом. У прикладі об’єкт має такий URI: «http://www.business.org/ontology/#product», але в загальному випадку об’єктом може бути літеральне значення, наприклад, «Змінна рівна 5», де 5 — літеральне значення об’єкту.
Твердження. У RDF сукупність суб’єкту, предиката та об’єкту прийнято називати твердженням. Наприклад, у N3 (Notation3) твердження називають триплетами.
М.Даконта та інші автори у своїй книзі також пояснили причини, чому RDF активно не використовується. По-перше, мова RDF не достатньо добре інтеґрується в XML-файли. Це пояснюється тим, що RDF завжди має простір імен, тоді як XML чи XHTML-документи можуть описувати лише дані без необхідних інфраструктурних елементів метаданих (таких як простори імен). Хоча RDF-об’єкти серіалізуються так само, як і XML об’єкти, все ж існувала проблема інтеґрації RDF у XHTML та XML. Виправивши синтаксис, робоча група W3C із RDF вирішила цю проблему інтеґрації. Для прикладу, існують спеціальні утиліти на зразок SMORE, які вміють читати вкладені RDF документи в HTML та XHTML.
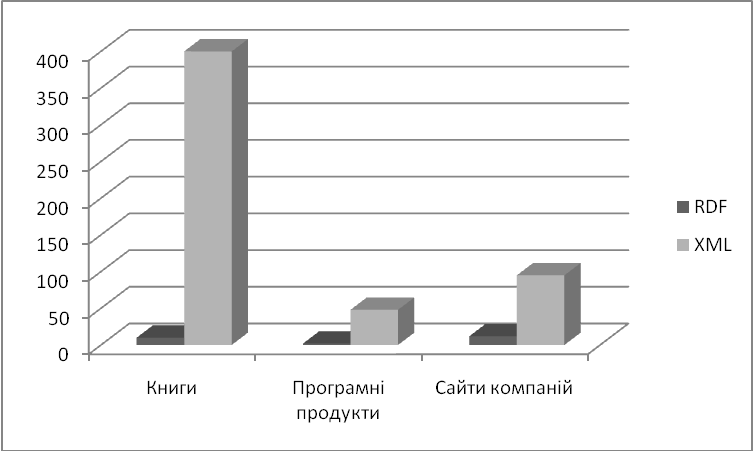
Рис. 6.2. Порівняння використання технологій RDF та XML.
По-друге, мова RDF складніша, ніж XML, яка своєю чергою не є достатньо читабельною для розробників і через це складною. Складність RDF полягає в тому, що насправді в RDF-документах існують і дані, і метадані, які також мають складний синтаксис. Тобто при роботі з RDF треба знати не лише ієрархічну структуру даних, але й ієрархічну структуру метаданих, які тісно між собою переплітаються.
Автори книги навели статистику (рис. 6.2) щодо кількості книжок, програмних продуктів та сайтів компаній, присвячених використанню RDF та XML відповідно. Статистика яскраво показує, що використання XML суттєво перевищує RDF, і що більше реальні програмні продукти з використанням RDF фактично не створюються.
Отже, виникла гостра необхідність створити нову мову, яка б описувала знання на вищому рівні абстракції, ніж звичайні Web-ресурси, як це робить RDF. Тому виникла мова OWL. Вона була покликана змінити типову архітектуру систем з метою перетворити дані у знання, а системи зробити ближчими до реального світу. На рис. 6.3 наведено типовий процес роботи зі знаннями.
На першому рівні відбувається ввід інформації з певного джерела (від людей, з джерел даних таких як бази даних, Інтернет тощо).
На другому рівні відбувається продукування, на якому дані записуються в базу даних, цифрові файли чи пошукову машину. Основною проблемою є те, що група чи проект вводять одну і ту саму інформацію по-різному. Як результат отримують багато жорстко-зв’язаних систем.
Третім рівнем процесу може бути (а може й не бути) інтеґрація, яка залежить від складності інформаційної структури комплексу. Оскільки всі інформаційні системи є жорстко-зв’язаними, то зазвичай інтеґрація цих систем для отримання цілісної картини є не дуже хорошим рішенням. Відповідно, процес інтеґрації систем не буде містити повторюваних частин, тобто кожен раз інтеґрацію треба буде починати спочатку. Якщо навіть існує інтеґраційне рішення, то корпорації платять великі гроші інтеґраторам за дуже дорогу інформаційну систему, що буде інтеґрувати інші системи.
Четвертий рівень процесу — пошук знань серед внутрішніх ресурсів корпорації (необов’язково включаючи інтеґраційну систему). Це довготривалий та, за суттю, майже випадковий процес. Понад усе, часто інформація, яка шукається, може бути недостатньо релевантною через свою загальність.
Наступний рівень — це утворена програма з результатів пошуку. Із цієї системи можна отримати, зазвичай, презентацію чи звіт. Після того, як новий продукт створений, результати звітів можуть зберігатися, але зазвичай вони ще складніше класифікуються, ніж жорстко-зв’язані системи. Ще одною проблемою в системах такого роду є версифікація документів, адже перебирати кожен раз документи у всіх системах нереально, а явну версифікацію запроваджувати для всіх файлів теж дуже складно. Ну і нарешті, останньою постає проблема повторного використання даних.
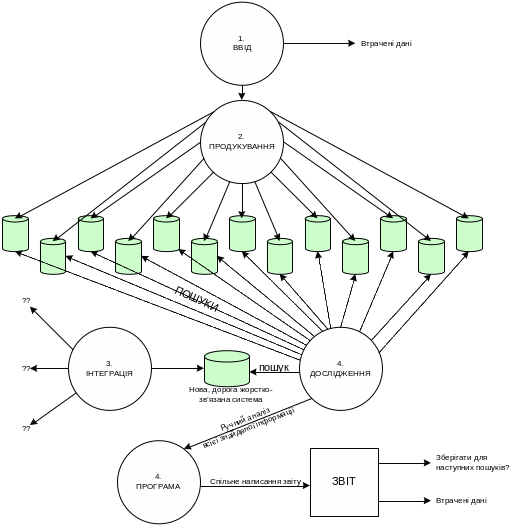
Рис. 6.3. Процес роботи зі знаннями в типових системах.
Як результат така система знань має дуже складну архітектуру, і тому її важко інтеґрувати з іншими системами. При інтеґрації треба дотримуватися такого правила: системи не можуть розпізнавати одна одну, якщо вони не працюють через однаковий контракт. Інформаційний контракт декларує способи взаємодії систем таким чином, що одна система підтримує контракт, а інша, знаючи про його існування, використовує цей контракт як вхідний інтерфейс системи. У загальному випадку такий контракт треба спеціально описувати. У випадку з онтологіями сама онтологія є контрактом між двома системами, які інтеґруються.
Тепер онтології все частіше використовуються в реальних проектах. Переваги онтологій:
використання єдиних термінів у біохімічних знаннях пришвидшує розроблення, а також дає можливість передавати знання;
онтології забезпечують додаткові можливості з формування і тестування наукових тез, з опрацювання даних на природній мові, з інтеґрації даних.
Одним із прикладів проектів, які використовують онтологій для роботи з біохімічними знаннями, є GONG. Він був спрямований на ґенерацію генетичної онтології GO (Gene Ontology).
Іншими прикладами розроблених онтологій в галузі біохімії є онтологія DOLCE та онтологія Ontology Works. Вони містять формальні визначення базових елементів в біохімії (процесів, подій, випадків, типів тощо).
Висновки, які випливають наступні. Проекти GONG, DOLCE та інші описують частину загальних характеристик біологічних даних. Основною метою роботи була оцінка складності використання загальноприйнятих технік моделювання за допомогою онтологій. Автори переконують, що використання онтологій допоможе описувати різноманітні аспекти біохімії та молекулярної біології розподілено та дистанційно. Біохімічні онтології використовуються як основа побудови баз даних для зберігання інформації. Як результат роботи створений спеціальний стандарт XML — SBML (Systems Biology Markup Language), який використовується для обміну інформацією між імітаційними моделями біохімічних реакцій.
У [144] описане використання онтологій у блогах з відкритим кодом. Проект VIStology’s IBlogs покликаний розробити розподілену інтелектуальну систему для автоматичного моніторинґу блогів. У проекті розроблені онтологія Blog та онтологія News Event. Вони дають можливість отримувати знання з блогів і передавати їх у вигляді стрічок новин RSS.
Автори підводять підсумки своєї роботи: проект IBlogs робить перші кроки в побудові технології, яка повинна вирішити проблему аналізу, інтерпретації та аґреґації вмісту блогів. Проект демонструє, що використання онтологій є корисним для перегляду інформації про блоги та взаємозв’язки між його складовими — публікаціями, у вигляді невеликих заміток про нові події, методи, технології тощо.
Стаття про моделювання знань в системі EON [6] описує як використовувати систему для побудови інформаційних моделей знань про пацієнтів, медичні спеціальності та про медичні рішення і дії у відповідних випадках. Система EON має складну серверну архітектуру, складається з багатьох компонентів, обмін між якими здійснюється за допомогою онтологій.
За визначенням авторів, система EON створена для структурування інформації про пацієнтів, медичні концепції та загальні знання. У цій системі клінічні рекомендації можуть бути інтерпретовані для читання пацієнтами чи для формування таксономічних ієрархій медичних термінів.
У статті [42] описується, як за допомогою онтологій та правил можна порівнювати різні ступені та оцінки у різноманітних системах оцінювання. Наводиться приклад порівняння оцінок у північно американських (оцінки від “F” до “A+”), східноєвропейських (оцінки від “2” до “5”) та інших вузах.
На основі GO (Gene Ontology), яка згадувалася раніше, розроблені засоби для анотації біомедичних даних. Ці засоби є базованими на онтологіях і дають можливість не лише індексувати біомедичні ресурси, але й давати доступ до інформації про них на Web-сторінках. Архітектура системи побудована так, щоб вона інтеґрувалася з Web-порталом з одного боку, і щоб видобувала знання з різнотипних ресурсів з іншого.
У підсумку роботи над GO (Gene Ontology) описана реалізація прототипу системи анотування, базованої на онтологіях. Завданням системи було описати велику кількість біомедичних ресурсів для створення каталогу анотованих елементів. Ресурси NCBO (National Center for Biomedical Ontology) складені в найбільшу бібліотеку біомедичних ресурсів, і система анотування дозволяє користувачеві знаходити різноманітну біомедичну інформацію, використовуючи одну точку входу, тобто єдиний репозиторій знань і, отже, не витрачати час на пошук біомедичних ресурсів у Webі. Система здатна опрацьовувати метадані з множинами генетичних виразів, радіологічних рисунків, клінічних звітів тощо, перетворюючи їх у відповідні онтології.
У середовищах eHealth використовуються онтології для поширення клінічних знань та даних про онкологічні дослідження. В eHealth описано процес створення онтологій, які повинні максимально відповідати реаліям в сучасних дослідженнях та відображеннях знань. Причини вибору онтологій як засобу відображеннях знань:
логічна структура, яку можна алгоритмічно опрацьовувати;
пряма відповідність термінів та знань;
інтероперабельність (можливість взаємодії мереж).
Висновки, зроблені авторами, є наступними. Середовища eHealth надають зручні та корисні утиліти для роботи з біомедичними онтологіями. Досягнуто консенсусу між розробниками у великій кількості аспектів, пов’язаних з описом знань, алгоритмами роботи тощо.
Абсолютно очевидним є той факт, що онтології набули найбільшого використання в біомедичній галузі. Основною причиною є те, що знання в медицині є неточними та часто слабо формалізованими. До початку використання онтологій в медицині існувала велика кількість аплікацій, які по різному трактували одні і ті самі поняття. На сьогодні ситуація суттєво покращилась за рахунок можливості загального доступу до знань. Системи стали менш залежними одна від одної. Цього намагалися досягти розробники онтологій. Також онтології починають активно застосовувати для добре досліджених предметних областей, наприклад, блогів, об’єднань людей, форумів тощо.