

4.1. Латентні структури знань і психосемантика
Більшість систем, що видобувають знання, полегшують складний і трудомісткий процес формування баз знань і реалізують прямий діалог з експертом. Однак виявлені в такий спосіб структури знань часто відбивають лише поверхневу складову знань експерта, не зачіпаючи їхньої глибинної структури. Такий самий недолік має більшість методів безпосереднього видобування знань.
Щоб видобути глибинні шари експертного знання, можна скористатися методами психосемантики — науки, що виникла на стику когнітивної психології, психолінгвістики, психології сприйняття і досліджень індивідуальної свідомості. Психосемантика досліджує структури свідомості через моделювання індивідуальної системи знань і виявлення тих категоріальних структур свідомості, які можуть не усвідомлюватися (латентні, імпліцитні або приховані).
4.1.1. Семантичні простори і психологічне градуювання
Основним методом експериментальної психосемантики є метод реконструкції суб'єктивних семантичних просторів. Тут психосемантика тісно пов'язана із психолінгвістикою й лінгвістичною семантикою — з методологією виявлення значень слів, лексикографією, «відмінковою граматикою» і структурними дослідженнями. Однак лінгвістичні методи, в основному, спрямовані на аналіз текстів, відчужених від суб'єкта, від його мотивів і задумів.
Психолінгвістичні методи звертаються безпосередньо до випробуваного. Більшість із них пов'язані з різними формами суб'єктивного градуювання. Перед випробуваним ставиться завдання оцінити «подібність знань» за допомогою деякої градуйованої шкали, наприклад, від 0 до 5 або від 0 до 9. У цьому випадку дослідник отримує чисельно подані стандартизовані дані, що легко піддаються статистичному опрацюванню.
Психосемантика — як один з нових напрямів сучасної психології — відразу була оцінена фахівцями в галузі штучного інтелекту як перспективний інструмент, що дозволяє реконструювати семантичний простір пам'яті як психологічну модель глибинної структури знань експерта. Уже перші досягнення психосемантики в середині 80-х XX ст. років дозволили одержати досить наочні результати. У психології семантичні простори виступають як модель категоріальної структури індивідуальної свідомості. При концептуальному аналізі знань структуру семантичного простору експерта можна вважати основою для формування поля знань. При цьому окремі параметри семантичного простору відповідають різним компонентам поля (розмірність простору співвідноситься зі складністю поля, виділені понятійні структури — з метапоняттями, змістовні зв'язки між поняттями-стимулами — це суть відношення тощо).
Найлегше ознайомитися з експериментальною психосемантикою на прикладі, пов'язаному з виявленням структури і розмірності семантичного простору знань із деякої предметної області. В основі побудови семантичних просторів, як правило, лежить статистична процедура (наприклад, факторний аналіз, багатомірне градуювання або кластерний аналіз), що дозволяє групувати ряд окремих ознак опису в місткіші категорії-фактори. Говорячи мовою поля знань, це — побудова концептів вищого рівня абстракції. При геометричній інтерпретації семантичного простору значення окремої ознаки відображається як точка або вектор із заданими координатами усередині n-мірного простору, координатами якого виступають виділені фактори. Побудова семантичного простору, таким чином, включає перехід до опису предметної області на вищому рівні абстракції, тобто перехід від мови, що містить великий алфавіт ознак описування, до місткішої мови концептуалізації, що містить менше число концептів і виступає своєрідною метамовою стосовно першої. Залежно від досвіду та професійної компетентності тих, кого випробовують, розмірність простору і розташування в ній первинних понять може істотно варіюватися. Ця особливість семантичних просторів може бути використана на стадії контролю в процесі навчання, при тестуванні експериментів і користувачів.
Так, для перевірки знань і розуміння англійської мови в роботі [118] було взято десять найпоширеніших прийменників, які досить важко перекладати. На екрані дисплея випробовуваному пропонували кілька прийменників і запитували, чи часто в нього викликає труднощі вибір одного із цих прийменників. Ступінь утруднення оцінювалася в балах від 1 до 9. На цих даних методами багатомірного градуювання було побудовано структуру складності вживання англійських прийменників з погляду носія російської мови. Ця модель істотно залежить від рівня знань. Так, модель новачка не є організованою структурою. У людей, що мають певні навички, виявилася деяка структурованість семантичного простору, у ньому чітко позначилися пари й трійки подібних прийменників.
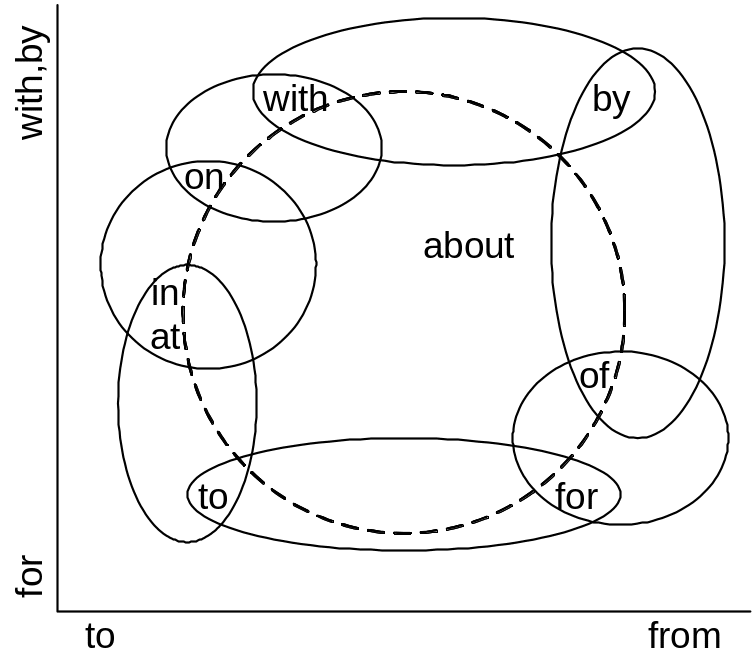
Рис. 4.1. Семантичний простір близькості англійських прийменників.
Найбільш чітка й зв'язна структура наведена на рис. 4.1. За її допомогою можна пояснити особливості диференціації прийменників в англійській мові. Основа структури подається у вигляді кола, близькі крапки на якому відповідають прийменникам, які важко диференціювати. Структура спирається на дві ортогональні осі. Вісь абсцис відповідає прийменникам напрямку руху, а вісь ординат — прийменникам мети, або засобу.
На підставі одержаних методами психосемантики моделей можна здійснювати контроль знань. При аналізі індивідуальних семантичних просторів виявляються питання, які не засвоєні й не уклалися в систему. Контроль структури знань здійснюється на основі зіставлення семантичних просторів хороших фахівців і новачків (студентів, слухачів, молодих фахівців). Ступінь погодженості семантичних просторів (їхньої розмірності, ознаки й конфігурації понять) буде визначати рівень знань новачка.
Однак тут необхідно врахувати, що семантичні простори двох кваліфікованих фахівців можуть бути різними, тому що містять індивідуальні розходження сприйняття, що віддзеркалюють досвід і характер діяльності людини. Тому не завжди можна формально порівняти семантичні простори експерта й новачка, варто попередньо вивчити семантичні простори декількох фахівців, а потім уже робити порівняння.
У роботі [56] описаний подібний експеримент. Були отримані когнітивні структури знань досвідченого льотчика-винищувача й пілота-новачка з використанням двох методів: багатовимірного градуювання (алгоритм MDS — Alscal) і мережного градуювання із врахованими зв'язками (алгоритм Pathfinder). Обидва алгоритми засновані на використанні оцінок психологічної близькості. Досвідчений пілот і новачок оцінювали всі можливі парні сполучення 30-ти пов'язаних з польотом понять, приписуючи числа від 0 до 9 кожній парі, де 0 позначав найслабший ступінь зв'язку між поняттями, а 9 — найсильніший. Ці оцінки потім опрацьовувалися із застосуванням обох алгоритмів градуювання.
Відповідно до алгоритмів MDS кожний концепт, що виражає деяке поняття, вміщують в k-вимірний простір таким чином, що відстань між точками відбиває психологічну близькість відповідних концептів. Алгоритм Pathfinder будує семантичну мережу. Дуги можуть бути або орієнтованими (несиметричне відношення), або неорієнтованими (симетричне відношення). Обидва методи забезпечують стискання великих обсягів даних (у формі попарних оцінок) до меншого набору параметрів; але націлені вони на виявлення різних властивостей досліджуваних структур. Якщо в алгоритмі Pathfinder центром уваги є локальні відношення між концептами, то алгоритм MDS забезпечує ширше розуміння властивостей простору концептів, що підлягає метризації.
Результуючі когнітивні структури виявилися близькими для пілотів-винищувачів з однаковим рівнем досвіду, але були різними для різних груп випробуваних. Автори експериментів виявили, що за когнітивною структурою, характерною для пілота-винищувача, можна встановити, новачок він чи досвідчений пілот. Нарешті, здійснений ними ж аналіз когнітивних структур виявив наявність концептів і відношень, спільних для подань досвідченого фахівця й новачка, і, крім того, ряд концептів і відносин, які з'явилися тільки в одному з подань. Прямим розвитком розглянутої роботи стала експертна система керування повітряним боєм ACES.
Аналогічне дослідження механізмів нагромадження досвіду було здійснене в області програмування на ЕОМ. За допомогою методів градуювання було показано, що один з аспектів досвіду програміста — організація знань відповідно до задуму програми, або семантики, а не відповідно до синтаксису.
Мережне подання абстрактних понять програмування на основі оцінок зв'язності концептів у програмістів показане на рис. 4.2. Експеримент показав, що всіх програмістів на основі аналізу структури семантичного простору можна розбити на три групи: новачки, недосвідчені фахівці середнього рівня, досвідчені фахівці. Цей висновок збігається з результатами, отриманими в роботі [29]. Крім того, досліджувалася еволюція когнітивної структури програміста в міру його просування від новачка до досвідченого фахівця.
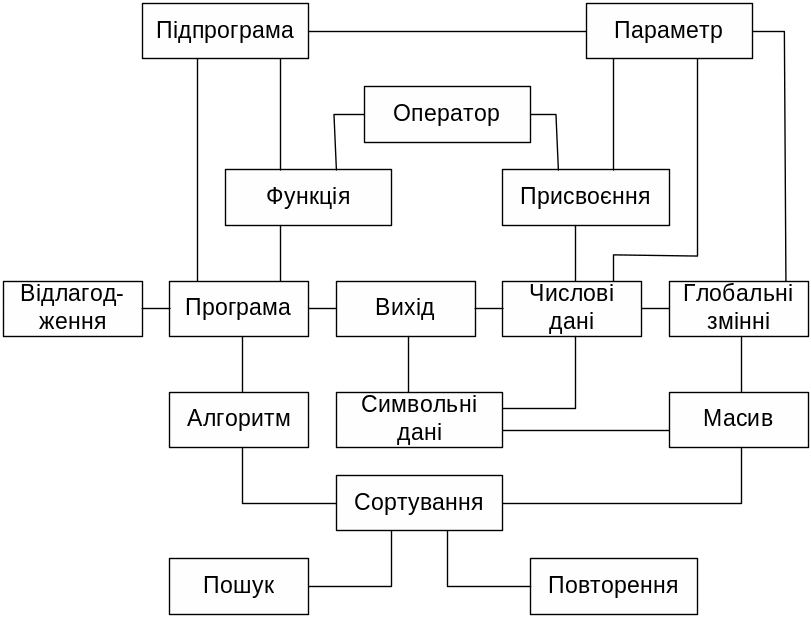
Рис. 4.2. Асоціативна мережа структури знань експерта-програміста.
Інтерпретація виявлених відношень (зв'язків) між поняттями вимагає додаткових зусиль від колективу розроблювачів інтелектуальних систем. Так, наприклад, для означення дуг на рис. 4.2 необхідним став додатковий експеримент, учасникам якого була запропонована пара понять і поставлено завдання дати словесний опис зв'язку між поняттями пари. Результати наведено в табл. 4.1. Отже, асоціативна мережа на рис. 4.2 може бути перетворена в семантичну.
Таблиця 4.1. Опис зв'язку між поняттями
Пов'язані пари понять |
Відношення між пов'язаною парою понять |
Підпрограма — програма |
Є частина |
Символьні дані — вихід |
Є тип |
Параметр — програма |
Використовується |
Програма — вихід |
Робить |
Сортування — пошук |
Містить у собі |
Чисельні дані — параметр |
Може бути |
Функція — оператор |
Є |
Функція — програма |
Є частина |
Налагодження — програма |
Піддається |
Вихід — чисельні дані |
Складається з... |
Масив — символьні дані |
Може складатися з... |
Функція — підпрограма |
Є |
Присвоєння значень — параметр |
Використовується для |
Масив — глобальна зміна |
Може бути |
Масив — чисельні дані |
Може складатися з... |
Повторення — сортування |
Є частина |
Програма — алгоритм |
Є виконання |
Сортування — алгоритм |
Є |
Сортування — чисельні дані |
Робиться на |
Присвоєння — оператор |
Є |
Всі вищезгадані методи (включаючи кластерний аналіз) можна віднести до методів психологічного градуювання. Їхню основу становлять алгоритми перетворення складних структур даних у зрозумілішу форму, що передбачається психологічно змістовною. Результуюче подання залежить від методу:
кластерний аналіз породжує деревоподібну структуру;
багатомірне градуювання й факторний аналіз — просторову;
алгоритм МDS — мережну;
репертуарні решітки породжують конструкти або мета-виміри.
Формальна методологія психосемантичного градуювання дозволяє частково автоматизувати процес структурування знань і одержувати «когнітивний розріз» його подань про предметну область. Методологія градуювання дозволяє виявляти структури знання непрямим шляхом при одержанні відповідей від експертів на досить прості запитання (наприклад, «наскільки близькі поняття Х1 і Х2» замість «скажіть, який зв'язок між Х1 і Х2, як вони впливають один на одного»).
Майже всі експерименти дозволили виявити одну закономірність. Розмірність семантичного простору з підвищенням рівня професіоналізму зменшується. Цей висновок збігається з відомими твердженнями когнітивної психології про те, що процес пізнання супроводжується узагальненням.
Побудова семантичного простору зазвичай включає три послідовних кроки.
1. Вибір і застосування відповідного методу оцінки семантичної подібності. Цей крок містить у собі експеримент із випробовуваними особами, яким пропонується оцінити спільність поданих стимульних ознак на деякій шкалі.
2. Побудова структури семантичного простору на основі математичного аналізу отриманої матриці подібності. При цьому відбувається зменшення числа досліджуваних понять за рахунок узагальнення й одержання генералізованих осей.
3. Ідентифікація, інтерпретація виділених факторних структур, кластерів або груп об'єктів, осей тощо. На цьому кроці необхідно знайти значеннєві еквіваленти, мовні «ярлики» для виділених структур. Тут великого значення набуває лінгвістичне чуття й професіоналізм фахівця, що здійснює дослідження, і випробуваних експертів. Часто до інтерпретації залучають групу експертів.