

3.3. Текстологічні методи
Група текстологічних методів об'єднує методи видобування знань, засновані на вивченні спеціальних текстів з підручників, монографій, статей, методик та інших носіїв професійних знань.
У буквальному розумінні текстологічні методи не відносять до текстології — науки, яка народилася в руслі філології з метою критичного читання літературних текстів, вивчення та інтерпретації джерел з вузькоприкладної задачі — підготування текстів до видання.
Зараз текстологія розширила свої межі включенням аспектів суміжних наук — герменевтики (науки правильного тлумачення древніх текстів — біблії, античних рукописів та ін.), семіотики, психолінгвістики тощо.
Текстологічні методи видобування знань, безумовно, використовуючи основні положення текстології, відрізняються принципово від її методології, по-перше, характером і природою своїх джерел (професійна спеціальна література, а не художня, що живе за своїми власними законами), а по-друге, жорсткою граматичною спрямованістю видобування конкретних професійних знань.
Серед методів видобування знань ця група є найменш розробленою, з неї майже немає бібліографії, тому подальший виклад є наче введенням в методи вивчення текстів в тому вигляді, як це уявляють автори.
Задачу видобування знань з текстів можна сформулювати як задачу розуміння і виокремлення суті тексту. Сам текст на звичайній мові є лише провідником суті, а задум і знання автора лежать у вторинній структурі (змістовній структурі чи макроструктурі тексту), надбудованій над звичайним текстом, або, як сформульовано в роботі [123], «текст не містить і не передає суті змісту, а є тільки інструментом для автора тексту».
При цьому можна виділити дві такі змістові структури:
М1 — зміст, який намагався вкласти автор, це його модель світу, і M2 — зміст, який розуміє читач, у нашому випадку інженер зі знань (рис. 3.5), в процесі інтерпретації I. При цьому T — це словесна оболонка M, тобто результат вербалізації V.
Складність процесу полягає в принциповій неможливості співпадіння знань, що утворюють М1 і М2 через те, що М1 утворюється за рахунок всієї сукупності уявлень, потреб, інтересів та досвіду автора, лише невелика частина яких знаходить відображення у тексті Т. Відповідно, і M2 утворюється в процесі інтерпретації тексту Т за рахунок залучення всієї сукупності наукового та людського багажу читача. Отже, два інженери зі знань видобудуть з одного Т дві різні моделі М1 і М2 .
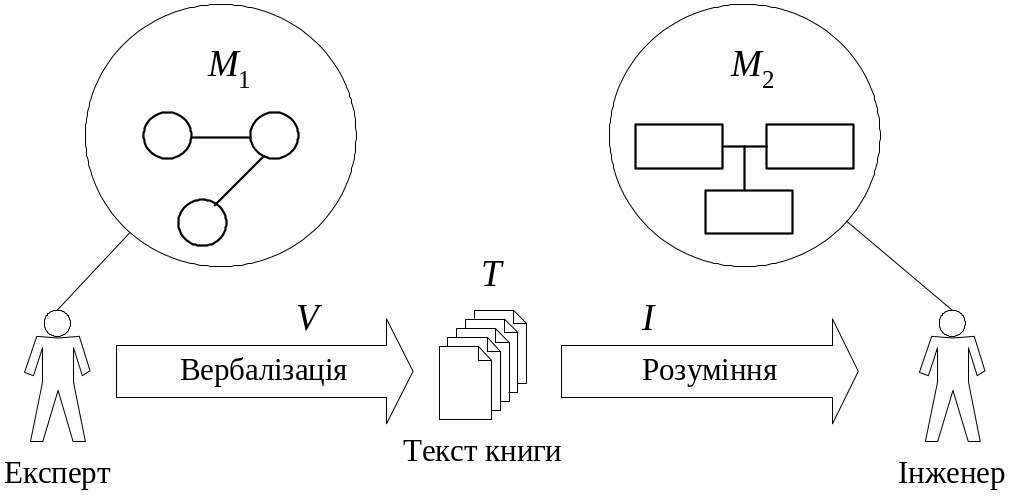
Рис. 3.5. Схема видобування знань зі спеціальних текстів.
Постає завдання: з’ясувати, за рахунок чого можна досягти максимальної адекватності М1 і М2, пам’ятаючи при цьому, що розуміння завжди відносне, оскільки це синтез двох змістів „своє — чуже”.
Розглянемо детальніше, які джерела живлять модель М1 і створюють текст Т. У роботі [34] вказані два компоненти будь-якого наукового тексту. Це перший матеріал спостережень та система наукових понять β в момент створення тексту. На додаток до цього, на наш погляд, крім об’єктивних даних експериментів та спостережень, в тексті обов’язково є суб’єктивні погляди автора , як результат його особистого досвіду, а також деякі „загальні місця” або „вода” . Крім цього, будь-який науковий текст містить запозичення з інших джерел (статей, монографій) і т.ін., при цьому всі компоненти занурені в мовне середовище L. Можна записати:
Т = (,,,,)L.
Отже, компоненти наукового тексту можна подати у вигляді наступної схеми (рис. 3.6). При цьому компоненти , частина входять і в модель М1.

Рис. 3.6. Компоненти наукового тексту.
При видобуванні знань аналітику, який інтерпретує текст, доводиться розв'язувати задачу декомпозиції цього тексту на перераховані вище компоненти для виділення справді важливих для реалізації баз знань фрагментів. Складність інтерпретації наукових і спеціальних текстів полягає і в тому, що будь-який текст набирає значення тільки в контексті, де під контекстом розуміється оточення, в яке «занурений» текст.
Розрізняють мікро- та макроконтекст. Мікроконтекст — це найближче оточення тексту. Так, речення отримує зміст в контексті абзацу, абзац в контексті розділу і т. д. Макроконтекст — це вся система знань, пов'язана з предметною областю (тобто знання про особливості та властивості, явно не вказані в тексті). Іншими словами, будь-яке знання набуває сенсу в контексті деякого метазнання.
Тепер детальніше про центральну ланку процедури вилучення знання — про розуміння тексту. Класичним в текстології є визначення німецького філософа і мовознавця В. фон Гумбольдта:
«...Люди розуміють один одного не тому, що передають співбесіднику ознаки предметів, і навіть не тому, що взаємно налаштовують один одного на точне і повне відтворення ідентичного поняття, а тому, що взаємно зачіпають один в одному одну й ту саму ланку чуттєвих уявлень і початків внутрішніх понять, доторкаються до одних і тих самих клавіш інструмента свого духа, завдяки чому у кожного спалахують у свідомості відповідні, а не тотожні розуміння».
Спілкуючись мовою сучасного мовознавства, розуміння — це формування «другого тексту», тобто семантичної структури (поняттєвої структури). У нашій термінології — це спроба відтворення семантичної структури М1 в процесі формування моделі М2, тобто це перший крок структурування знань.
Як відбувається процес розуміння І? Одна з можливих схем викладена в роботі [117]. Ми внесли деякі зміни в цю схему у зв'язку з тим, що в ній трактується розуміння тексту на іноземній мові, а нас цікавить розуміння тексту в новій для людини, що пізнає, предметні області. Крім цього, доповнимо її деякими положеннями герменевтики. У цілому одержана схема узгоджується зі стратегією вивчення всього нового.
Основними моментами розуміння тексту є:
висування попередньої гіпотези про суть всього тексту (передбачення);
визначення значень незрозумілих слів (тобто спеціальної термінології);
виникнення загальної гіпотези про зміст тексту (про знання);
уточнення значення термінів та інтерпретація окремих фрагментів тексту під впливом загальної гіпотези (від цілого до частин);
формування деякої змістової структури за рахунок встановлення внутрішніх зв'язків між окремими важливими (ключовими) словами, фрагментами, а також за рахунок виникнення абстрактних понять, що узагальнюють окремі фрагменти знань;
корекція загальної гіпотези відносно фрагментів знань, що містяться в тексті (від частин до цілого);
прийняття основної гіпотези, тобто формування М2.
Варто зауважити наявність як дедуктивної (від цілого до
частин), так і індуктивної (від частин до цілого) складових процесу розуміння. Такий двоєдиний підхід дозволяє охоплювати текст як змістову єдність особливого роду, з її основними ознаками, такими як зв'язність, цілісність, завершеність та ін..
Центральними поняттями процесу І є кроки 5 та 7, тобто формування змістової структури чи виділення «опірних», ключових слів чи «змістових віх», а також заключне зв'язування «змістових віх» в єдину семантичну структуру.
При аналізі тексту важливе виявлення внутрішніх зв'язків між окремими елементами тексту та поняттями. Традиційно виділяють два види зв'язків у тексті — експліцитні (явні зв'язки), які виражаються у зовнішньому подрібненні тексту, та імпліцитні (приховані зв'язки). Експліцитні зв'язки ділять текст на параграфи за допомогою перелічення компонентів, вставних слів (або конекторів) типу «по-перше...», «по-друге...», «проте» тощо. Імпліцитні (внутрішні) зв'язки між окремими «змістовими віхами» викликають основні складнощі при розумінні.
Отже, семантична структура тексту виникає у свідомості суб'єкта, який пізнає за допомогою знань про мову, знань про світ, а також загальних (фонових) знань у тій предметній області, якій присвячений текст: «тексти пишуть для посвячених». Іншими словами, якщо текст не є науково-популярним, то для його адекватного читання потрібна деяка підготовка.
Отже, шлях до знань збільшується ще на одну ланку. Якщо раніше ми говорили, що самі текстологічні методи рідко вживаються як самостійний метод видобування, а зазвичай використовується як деяка підготовка до комунікативної взаємодії, то тепер стверджуємо, що і для читання текстів потрібна підготовка. Яка ж?
Підготовкою для читання спеціальних текстів є вибір разом з експертами деякого «базового» списку літератури, який поступово введе аналітика в предметну область. У цьому списку можуть бути підручники для початківців, розділи і фрагменти з монографій, популярні видання. Лише після ознайомлення з «базовим» списком доцільно переходити до читання спеціальних текстів.
Отже, на процес розуміння (чи інтерпретації) І та модель М2 впливають наступні компоненти (рис. 3.7):
екстракт компонентів (,,,)', почерпнутий з тексту Т;
попередні знання аналітика про предметну область ПО;
загальнонаукова ерудиція аналітика ;
його особистий досвід D.
М2=[(,,,)', ПО, , D].
Процес I — це складний процес, що не піддається формалізації, на який суттєвим чином впливають такі чисто індивідуальні компоненти, як когнітивний стиль пізнання, інтелектуальні характеристики та ін.

Рис. 3.7. Компоненти формування змісту тексту.
Але процедури розбиття тексту на частини («змістові групи»), а потім згущення, стиснення вмісту кожного змістового шматка у «змістову віху» є, очевидно, основою для будь-якого індивідуального процесу розуміння. Така компресія (стиснення) тексту у вигляді набору ключових слів, що передають основний зміст тексту, може слугувати зручною методологічною основою для здійснення текстологічних процедур видобування знань.
Як ключове слово може слугувати будь-яка частина мовлення (іменник, прикметник, дієслово і т. ін.) або їх поєднання. Набір ключових слів (НКС) — це набір опірних точок, за якими розгортається текст при кодуванні в пам'ять і усвідомлюється при декодуванні; це семантичне ядро цілості.
Приклад
Як приклад подано результати експерименту з формування НКС. Знання видобувались з наступного тексту.
«Теорія фреймів належить до психологічних понять, які стосуються розуміння того, що ми бачимо та чуємо. Ці способи сприйняття трактуються з послідовної точки зору, на їх основі здійснюється концептуальне моделювання, доцільність одержаних моделей досліджується разом з різними проблемами, що виникають в цих двох областях».
Для усвідомлення того факту, що задана інформація в цих областях має єдиний зміст, людська пам'ять передусім повинна бути здатною вказувати цю інформацію зі спеціальними концептуальними об'єктами. В іншому випадку не вдається систематизувати інформацію, яка виглядає різною. В основі теорії фреймів лежить сприйняття фактів через співставлення одержаної ззовні інформації з конкретними елементами та значеннями.