

Лекция 9
Отказоустойчивость файловых и дисковых систем
Одна из причин отказов дисков и файловых систем - нарушение магнитных свойств отдельных областей поверхности. Повысить устойчивость вычислительной системы к отказам дисков можно за счет использования избыточных дисков и специальных алгоритмов управления массивами таких дисков.
Другой причиной недоступности данных после сбоя системы может служить нарушение целостности служебной информации файловой системы, произошедшее из-за незавершенности операций по изменению этой информации при крахе системы. Примером такого нарушения может служить несоответствие между адресной информацией файла, хранящейся в каталоге, и фактическим размещением кластеров файла. Для борьбы с этим явлением применяются так называемые восстанавливаемые файловые системы, которые обладают определенной степенью устойчивости к сбоям и отказам компьютера (при сохранении работоспособности диска, на котором расположена данная файловая система).
Комплексное применение отказоустойчивых дисковых массивов и восстанавливаемых файловых систем повышают такой важный показатель вычислительной системы, как общая надежность.
Восстанавливаемость файловых систем
Причины нарушения целостности файловых систем
Восстанавливаемость файловой системы — это свойство, которое гарантирует, что все начатые файловые операции будут либо успешно завершены, либо отменены безо всяких отрицательных последствий для работоспособности файловой системы.
Последствия сбоя питания или краха ОС зависят от того, какая операция ввода-вывода выполнялась в этот момент, в каком порядке выполнялись подоперации и до какой подоперации продвинулось выполнение операции к этому моменту.
Некорректность файловой системы может возникать не только в результате насильственного прерывания операций ввода-вывода, выполняемых непосредственно с диском, но и в результате нарушения работы дискового кэша. Кэширование данных с диска предполагает, что в течение некоторого времени результаты операций ввода-вывода никак не сказываются на содержимом диска - все изменения происходят с копиями блоков диска, временно хранящихся в буферах оперативной памяти. В этих буферах размещаются данные из пользовательских файлов и служебная информация файловой системы, такая как каталоги, индексные дескрипторы, списки свободных, занятых и поврежденных блоков и т. п.
Для согласования содержимого кэша и диска время от времени выполняется запись всех модифицированных блоков, находящихся в кэше, на диск. Выталкивание блоков на диск может выполняться либо по инициативе менеджера дискового кэша, либо по инициативе приложения. Менеджер дискового кэша вытесняет блоки из кэша в следующих случаях:
- если необходимо освободить место в кэше для новых данных;
- если к менеджеру поступил запрос от приложения или модуля ОС на запись указанных в запросе блоков на диск;
- при выполнении регулярного, периодического сброса всех модифицированных блоков кэша на диск (как это происходит, например, в результате работы системного вызова sync в ОС UNIX).
Также в распоряжение приложений обычно предоставляются средства, с помощью которых они могут запросить у подсистемы ввода-вывода операцию сквозной записи; при ее выполнении данные немедленно и практически одновременно записываются и на диск, и в кэш.
Несмотря на то, что период полного сброса кэша на диск обычно выбирается весьма коротким (порядка 10-30 секунд), все равно остается высокая вероятность того, что при возникновении сбоя содержимое диска не в полной мере будет соответствовать действительному состоянию файловой системы — копии некоторых блоков с обновленным содержимым система может не успеть переписать на диск. Для восстановления некорректных файловых систем, использующих кэширование диска, в операционных системах предусматриваются специальные утилиты, такие как fsck для файловых систем ext3 или chkdsk для файловой системы NTFS. Однако объем несоответствий может быть настолько большим, что восстановление файловой системы после сбоя с помощью стандартных системных средств становится невозможным.
Протоколирование транзакций
Проблемы, связанные с восстановлением файловой системы, могут быть решены при помощи техники протоколирования транзакций. В системе должны быть определены транзакции (transactions) — неделимые работы, которые не могут быть выполнены частично. Они либо выполняются полностью, либо вообще не выполняются.
В файловых системах такими транзакциями являются операции ввода-вывода, изменяющие содержимое файлов, каталогов или других системных структур файловой системы. Если все подоперации были благополучно завершены, то транзакция считается выполненной. Это действие называется фиксацией (committing) транзакции. Если же одна или более подопераций не успели выполниться, тогда для обеспечения целостности файловой системы все измененные в рамках транзакции данные файловой системы должны быть возвращены в состояние, в котором они находились до начала выполнения транзакции.
Транзакцией может быть представлена операция удаления файла. Также в файловой системе существуют операции, которые нет необходимости рассматривать как транзакции (чтение файла, просмотр атрибутов файла).
Чтобы файловая система реализовывала свойство транзакций «все или ничего» необходимо протоколировать (запоминать) все изменения, происходящие в рамках транзакции, чтобы на основе этой информации в случае прерывания транзакции можно было отменить все уже выполненные подоперации, то есть сделать так называемый откат транзакции.
Для восстановления файловой системы используется упреждающее протоколирование транзакций. Оно заключается в том, что перед изменением какого-либо блока данных на диске или в дисковом кэше производится запись в специальный системный файл — журнал транзакций (log file), где отмечается, какая транзакция делает изменения, какой файл и блок изменяются и каковы старое и новое значения изменяемого блока. Только после успешной регистрации всех подопераций в журнале делаются изменения в исходных блоках. Если транзакция прерывается, то информация журнала регистрации используется для приведения файловой системы в исходное состояние, то есть производится откат. Если транзакция фиксируется, то и об этом делается запись в журнал регистрации, но новые значения измененных данных сохраняются в журнале еще некоторое время, чтобы сделать возможным повторение транзакции, если это потребуется.
Избыточные дисковые подсистемы RAID
Идея технологии RAID (Redundant Array of Independent/Inexpensive Disks, дословно - «избыточный массив независимых/недорогих дисков») состоит в том, что для хранения данных используется несколько дисков, даже в тех случаях, когда для таких данных хватило бы места на одном диске. Организация совместной работы нескольких централизованно управляемых дисков позволяет придать их совокупности новые свойства, отсутствовавшие у каждого диска в отдельности.
RAID-массив может быть создан на базе нескольких обычных дисковых устройств, управляемых обычными контроллерами, в этом случае для организации управления всей совокупностью дисков в операционной системе должен быть установлен специальный драйвер. Существуют также модели дисковых систем, в которых технология RAID реализуется полностью аппаратными средствами, в этом случае массив дисков управляется общим специальным контроллером.
Дисковый массив RAID представляется для пользователей и прикладных программ единым логическим диском. Такое логическое устройство может обладать различными качествами в зависимости от стратегии, заложенной в алгоритмы работы средств централизованного управления и размещения информации на всей совокупности дисков.
Различают несколько вариантов RAID-массивов, называемых также уровнями: RAID-0, RAID-1, RAID-2, RAID-3, RAID-4, RAID-5 и некоторые другие.
При оценке эффективности RAID-массивов чаще всего используются следующие критерии:
- степень избыточности хранимой информации (или тесно связанная с этим критерием стоимость хранения единицы информации);
- производительность операций чтения и записи;
- степень отказоустойчивости.
В логическом устройстве RAID-0 (рисунок 9.1) общий для дискового массива контроллер при выполнении операции записи расщепляет данные на блоки и передает их параллельно на все диски, при этом первый блок данных записывается на первый диск, второй — на второй и т. д. Различные варианты реализации технологии RAID-0 могут отличаться размерами блоков данных, например в наборах с чередованием, представляющих собой программную реализацию RAID-0 в Windows NT, на диски поочередно записываются полосы данных (strips) по 64 Кбайт. При чтении контроллер мультиплексирует блоки данных, поступающие со всех дисков, и передает их источнику запроса.
По сравнению с одиночным диском, в котором данные записываются и считываются с диска последовательно, производительность дисковой конфигурации RAID-0 значительно выше за счет одновременности операций записи/чтения по всем дискам массива.
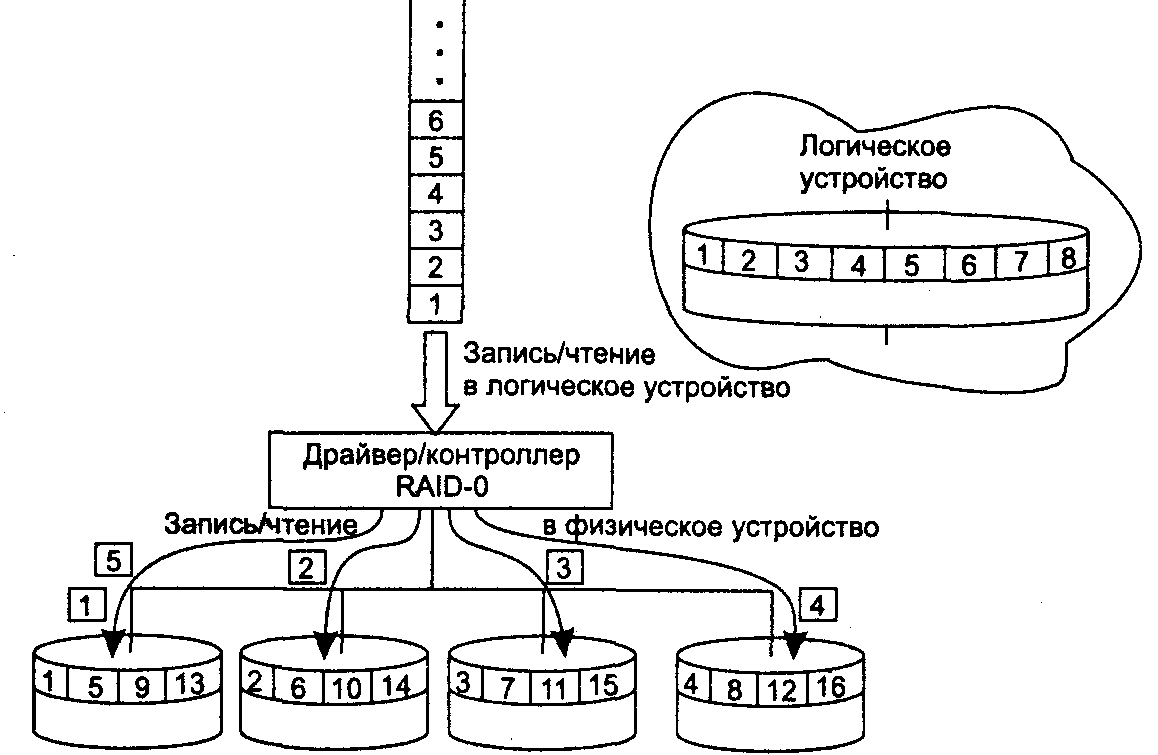
Рисунок 9.1 - Организация массива RAID-0
Уровень RAID-0 не обладает избыточностью данных, а значит, не имеет возможности повысить отказоустойчивость. Отказоустойчивость снижается, поскольку если один из дисков выйдет из строя, то восстанавливать придется все диски массива. Имеется еще один недостаток — если при работе с RAID-0 объем памяти логического устройства потребуется изменить, то сделать это путем простого добавления еще одного диска к уже имеющимся в RAID-массиве дискам невозможно без полного перераспределения информации по всему изменившемуся набору дисков.
Уровень RAID-1 (рисунок 9.2) реализует подход, называемый зеркальным копированием (mirroring). Логическое устройство в этом случае образуется на основе одной или нескольких пар дисков, в которых один диск является основным, а другой диск (зеркальный) дублирует информацию, находящуюся на основном диске. Если основной диск выходит из строя, зеркальный продолжает сохранять данные, тем самым обеспечивается повышенная отказоустойчивость логического устройства. Избыточность — все данные хранятся на логическом устройстве RAID-1 в двух экземплярах, в результате дисковое пространство используется лишь на 50%.

Рисунок 9.2 - Организация массива RAID-1
При внесении изменений в данные, расположенные на логическом устройстве RAID-1, контроллер (или драйвер) массива дисков одинаковым образом модифицирует и основной, и зеркальный диски, при этом дублирование операций абсолютно прозрачно для пользователя и приложений. Удвоение количества операций записи снижает, хотя и не очень значительно, производительность дисковой подсистемы, поэтому во многих случаях наряду с дублированием дисков дублируются и их контроллеры. Такое дублирование (duplexing) помимо повышения скорости операций записи обеспечивает большую надежность системы — данные на зеркальном диске останутся доступными не только при сбое диска, но и в случае сбоя дискового контроллера.
Некоторые современные контроллеры (например, SCSI-контроллеры) обладают способностью ускорять выполнение операций чтения с дисков, связанных в зеркальный набор. При высокой интенсивности ввода-вывода контроллер распределяет нагрузку между двумя дисками так, что две операции чтения могут быть выполнены одновременно. В результате распараллеливания работы по считыванию данных между двумя дисками время выполнения операции чтения может быть снижено в два раза. Таким образом, некоторое снижение производительности, возникающее при выполнении операций записи, с лихвой компенсируется повышением скорости выполнения операций чтения.
Уровень RAID-2 расщепляет данные побитно: первый бит записывается на первый диск, второй бит — на второй диск и т. д. Отказоустойчивость реализуется в RAID-2 путем использования для кодирования данных корректирующего кода Хэмминга, который обеспечивает исправление однократных ошибок и обнаружение двукратных ошибок. Избыточность обеспечивается за счет нескольких дополнительных дисков, куда записывается код коррекции ошибок. Так, массив с числом основных дисков от 16 до 32 должен иметь три дополнительных диска для хранения кода коррекции. RAID-2 обеспечивает высокую производительность и надежность, но он применяется в основном в мэйнфреймах и суперкомпьютерах. В сетевых файловых серверах этот метод в настоящее время практически не используется из-за высокой стоимости его реализации.
В массивах RAID-3 используется расщепление (stripping) данных на массиве дисков с выделением одного диска на весь набор для контроля четности. То есть если имеется массив из N дисков, то запись на N-1 из них производится параллельно с побайтным расщеплением, а N-й диск используется для записи контрольной информации о четности (контрольную сумму по модулю 2 XOR). Диск четности является резервным. Если какой-либо диск выходит из строя, то данные остальных дисков плюс данные о четности резервного диска позволяют не только определить, какой из дисководов массива вышел из строя, но и восстановить утраченную информацию. Это восстановление может выполняться динамически, по мере поступления запросов, или в результате выполнения специальной процедуры восстановления, когда содержимое отказавшего диска заново генерируется и записывается на резервный диск.
Необходимо минимум 3 диска для создания конфигурации RAID-3. В этом случае избыточность достигает максимального значения - 33%. При увеличении числа дисков степень избыточности снижается.
Уровень RAID-3 позволяет выполнять одновременное чтение или запись данных на несколько дисков для файлов с длинными записями, однако в каждый момент выполняется только один запрос на ввод-вывод, то есть RAID-3 позволяет распараллеливать ввод-вывод в рамках только одного процесса (рисунок 9.3). Таким образом, уровень RAID-3 повышает как надежность, так и скорость обмена информацией. Массив этого типа хорош только для однозадачной работы с большими файлами, так как наблюдаются проблемы со скоростью при частых запросах данных небольшого объёма. Большая нагрузка на контрольный диск, что приводит к тому, что его надёжность сильно падает по сравнению с дисками с данными.
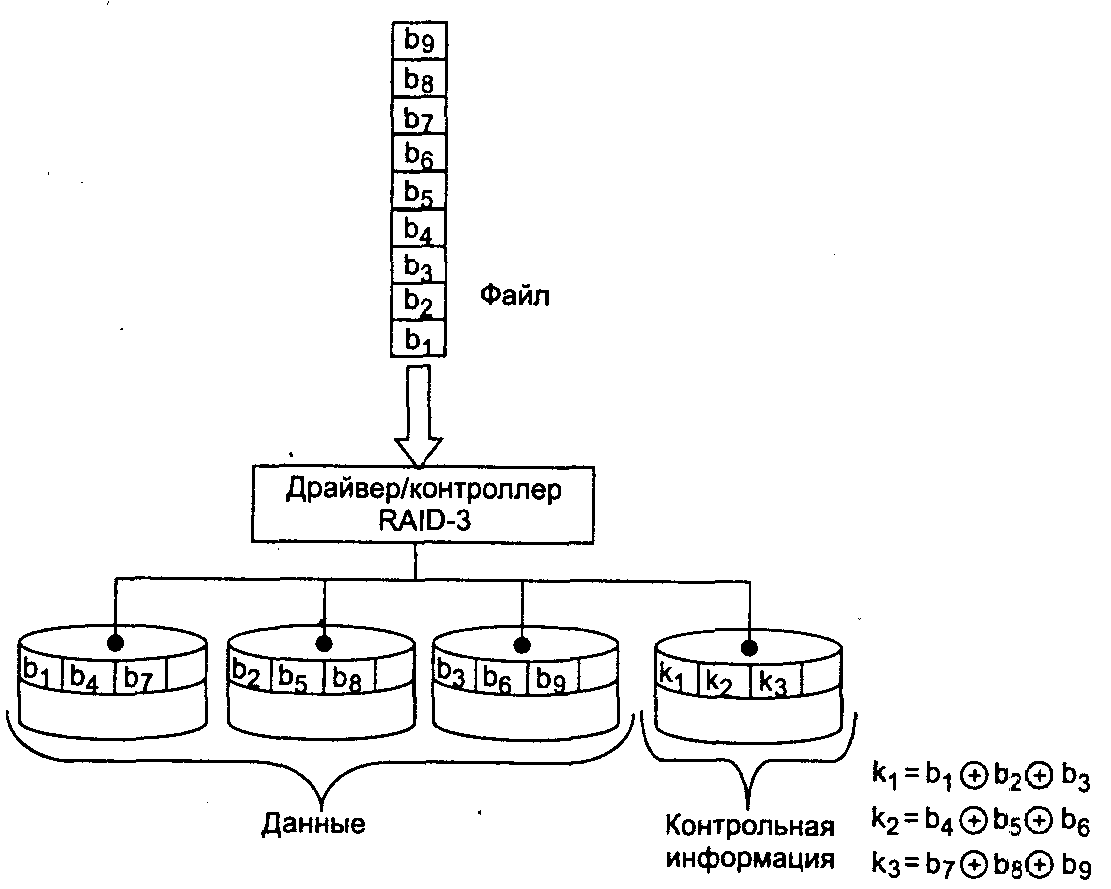

Рисунок 9.3 - Организация массива RAID-3
Организация RAID-4 (рисунок 9.4) аналогична RAID-3, за тем исключением, что данные распределяются на дисках не побайтно, а блоками. Таким образом, удалось «победить» проблему низкой скорости передачи данных небольшого объема. За счет блочной передачи может происходить независимый обмен с каждым диском. Для хранения контрольной информации также используется один дополнительный диск. Эта реализация удобна для файлов с очень короткими записями и большей частотой операций чтения по сравнению с операциями записи, поскольку в этом случае при подходящем размере блоков диска возможно одновременное выполнение нескольких операций чтения.
Однако по-прежнему допустима только одна операция записи в каждый момент времени, так как все операции записи используют один и тот же дополнительный диск для вычисления контрольной суммы. Запись производится медленно, поскольку четность для блока генерируется при записи и записывается на единственный диск. Используются массивы такого типа очень редко.

Рисунок 9.4 - Организация массива RAID-4
В уровне RAID-5 (рисунок 9.5) используется метод, аналогичный RAID-4, но данные о контроле четности распределяются по всем дискам массива. Каждая команда записи инициирует ту же последовательность «считывание—модификация—запись» в нескольких дисках, как и в методе RAID-4. Наибольший выигрыш в производительности достигается при операциях чтения.
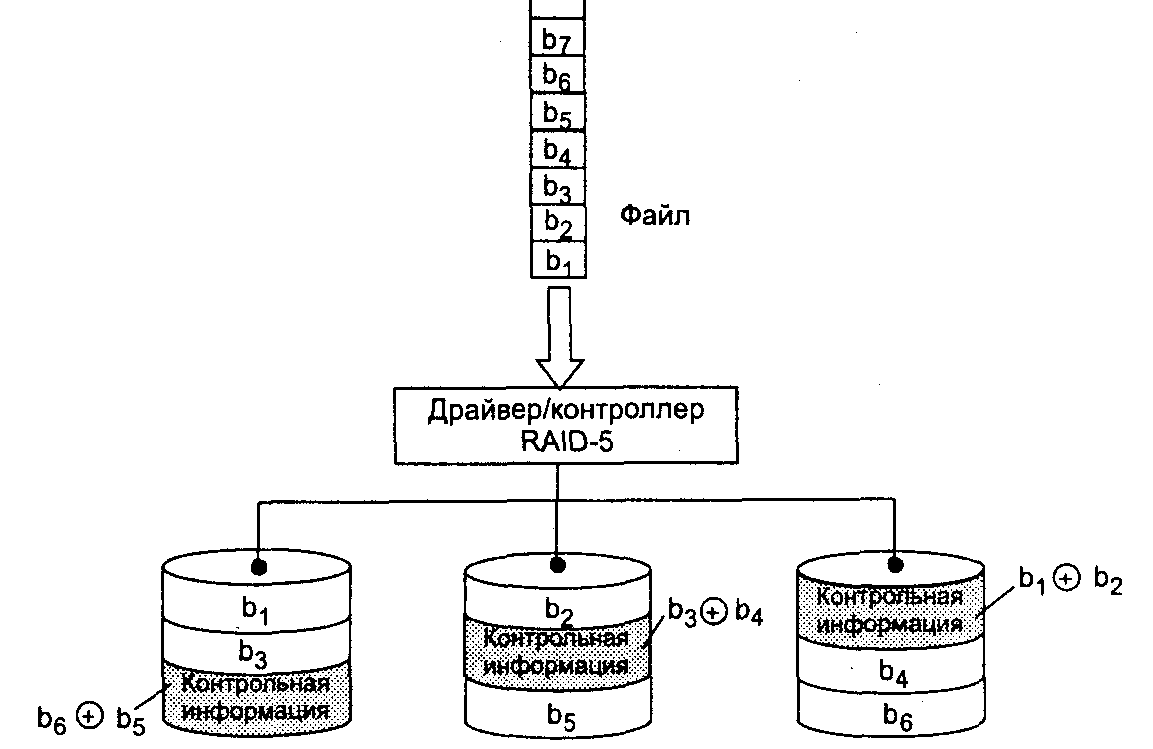
Рисунок 9.5 - Организация массива RAID-5
Основным недостатком уровней RAID от 2-го до 4-го является невозможность производить параллельные операции записи, так как для хранения информации о четности используется отдельный контрольный диск. RAID 5 не имеет этого недостатка. Блоки данных и контрольные суммы циклически записываются на все диски массива, нет асимметричности конфигурации дисков.
Поскольку информация о четности может быть считана и записана на несколько дисков одновременно, скорость записи по сравнению с уровнем RAID-4 увеличивается, однако она все еще гораздо ниже скорости отдельного диска метода RAID-1 и RAID-3.
RAID-5 получил широкое распространение, в первую очередь, благодаря своей экономичности. Объем дискового массива RAID5 рассчитывается по формуле (n-1)*hddsize, где n - число дисков в массиве, а hddsize - размер одного диска. Например для массива из 4-х дисков по 100 гигабайт общий объем будет (4 -1)*100=300 гигабайт. На запись информации на том RAID-5 тратятся дополнительные ресурсы, так как требуются дополнительные вычисления, зато при чтении (по сравнению с отдельным жестким диском) имеется выигрыш, потому что потоки данных с нескольких накопителей массива обрабатываются параллельно.
Недостатки RAID-5 проявляются при выходе из строя одного из дисков — весь том переходит в критический режим (degrade), все операции записи и чтения сопровождаются дополнительными манипуляциями, резко падает производительность. При этом уровень надежности снижается до надежности одиночного диска. Если до полного восстановления массива выйдет из строя хотя бы еще один диск, то массив разрушается, и данные на нем восстановлению обычными методами не подлежат. Минимальное количество используемых дисков равно трём.
С томом RAID-5 можно использовать диск Hot Spare. Основное время дополнительный диск простаивает, но при выходе из строя одного из дисков массива, его восстановление начинается немедленно с использованием spare-диска. При использовании одного тома RAID-5 данная конфигурация дисков является расточительной, эффективнее использовать RAID-6. Целесообразность использования spare-диска проявляется в системе из нескольких томов RAID-5, в которой spare-диск проинициализирован для каждого из томов RAID-5, и может быть использован в случае необходимости для немедленного восстановления одного из томов.
RAID-6 (Advanced Data Guarding) (рисунок 9.6) - похож на RAID-5, но имеет более высокую степень надежности — под контрольные суммы выделяется емкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. Требует более мощный RAID-контроллер. Обеспечивает работоспособность после одновременного выхода из строя двух дисков - защита от кратного отказа. Для организации массива требуется минимум 4 диска.
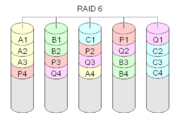
Рисунок 9.6 - Организация массива RAID-6
RAID-7 - зарегистрированная марка компании Storage Computer Corporation. Структура массива: на N-1 дисках хранятся данные, один диск используется для складирования блоков четности. Но добавилось несколько важных деталей, призванных ликвидировать главный недостаток массивов такого типа: кэш данных и быстрый контроллер, заведующий обработкой запросов. Это позволило снизить количество обращений к дискам для вычисления контрольной суммы данных. В результате удалось значительно повысить скорость обработки данных (кое-где в пять и более раз).
Прибавились и новые недостатки: очень высокая стоимость реализации такого массива, сложность его обслуживания, необходимость в источнике бесперебойного питания для предотвращения потери данных в кэш-памяти при перебоях питания.