

2 Основні особливості систем, заснованих на інвертованих списках
До числа найбільш відомих і типових представників таких систем відносяться Datacom/DB компанії Applied Data Research, Inc. (ADR), орієнтована на використання на машинах основного класу фірми IBM, і Adabas компанії Software AG. Організація доступу до даних на основі інвертованих списків використовується практично у всіх сучасних реляційних СУБД, але в цих системах користувачі не мають безпосереднього доступу до інвертованих списків (індексам).
База даних, організована за допомогою інвертованих списків, схожа на реляційну БД, але з тією відмінністю, що збережені таблиці й шляхи доступу до них видимі користувачам. При цьому:
Рядки таблиць упорядковані системою в деякій фізичній послідовності.
Фізична упорядкованість рядків усіх таблиць може визначатися і для всієї БД (так робиться, наприклад, у Datacom/DB).
Для кожної таблиці можна визначити довільне число ключів пошуку, для яких будуються індекси. Ці індекси автоматично підтримуються системою, але явно видимі користувачам.
Підтримуються два класи операторів - оператори, що встановлюють адресу запису, серед яких:
прямі пошукові оператори (наприклад, знайти перший запис таблиці по деякому шляху доступу);
оператори, що знаходять запис у термінах відносної позиції від попередньої запису по деякому шляху доступу.
Загальні правила визначення цілісності БД відсутні. У деяких системах підтримуються обмеження унікальності значень деяких полів, але в основному усіх покладається на прикладну програму.
3 Ієрархічні системи
Типовим представником (найбільш відомим і розповсюдженої) є Information Management System (IMS) фірми IBM. Перша версія з'явилася в 1968 р. Дотепер підтримується багато баз даних, що створює істотні проблеми з переходом як на нову технологію БД, так і на нову техніку.
Однією з найбільш важливих сфер застосування перших СУБД було планування виробництва для компаній, що займаються випуском продукції.
Список складових частин виробу по своїй природі є ієрархічною структурою. Для збереження даних, що мають таку структуру, була розроблена ієрархічна модель даних, що ілюструє мал. 2.2. У цій моделі кожен запис бази даних представляв конкретну деталь. Між записами існували відносини предок/нащадок, що зв'язують кожну частину з деталями, що входять до неї.
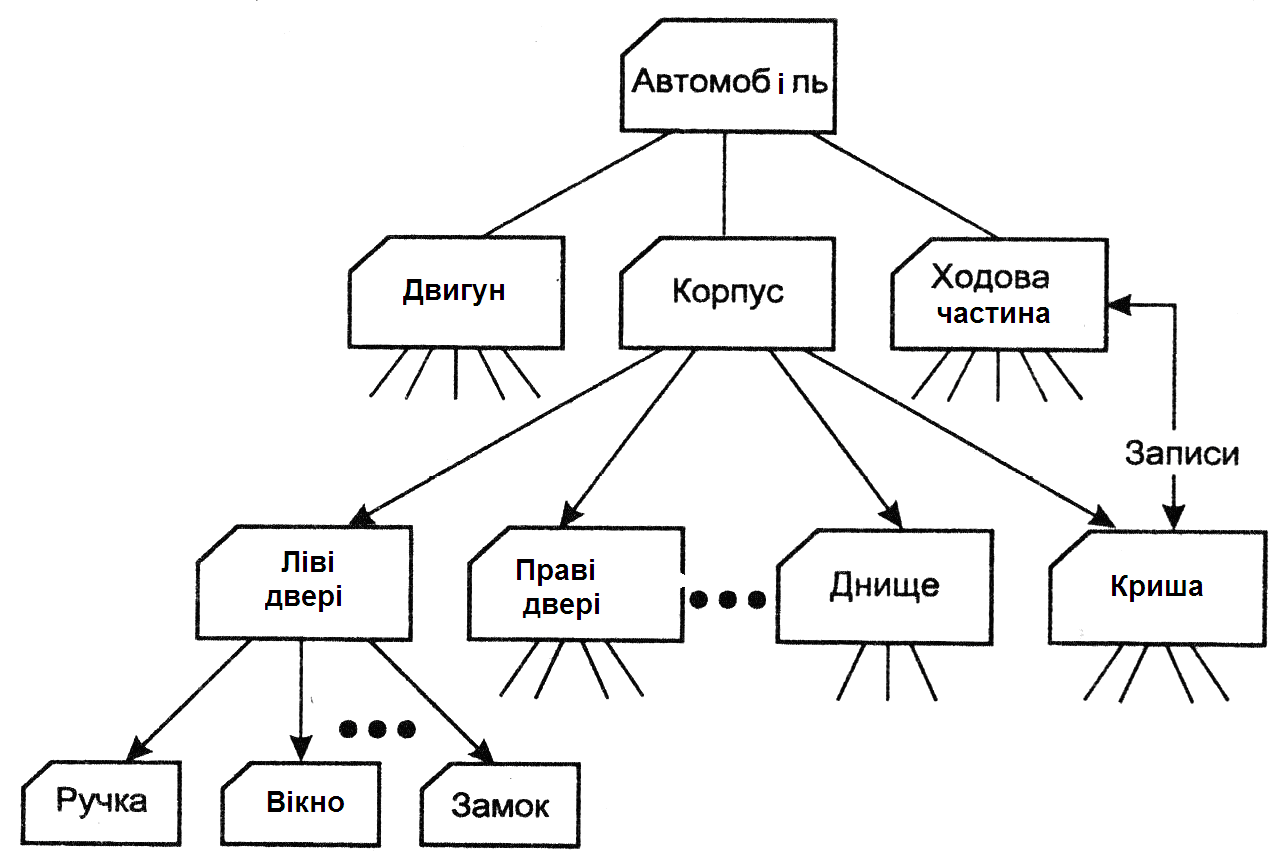
Рис. 2.2. Ієрархічна база даних, що одержить інформацію про складові частини.
Щоб одержати доступ до даних, що міститься в базі даних, програма могла:
• знайти конкретну деталь (ліві двері) по її номеру;
• перейти "униз" до першого нащадка (ручка дверей);
• перейти "нагору" до предка (корпус);
• перейти "убік" до іншого нащадку (праві двері).
Таким чином, ієрархічна БД складається з упорядкованого набору дерев; більш точно, з упорядкованого набору декількох екземплярів одного типу дерева.
Тип дерева складається з одного "кореневого" типу запису та упорядкованого набору інших типів піддерев (кожне з який є деяким типом дерева). Тип дерева в цілому являє собою ієрархічно організований набір типів запису. Між типами запису підтримуються зв'язки.
База даних з такою схемою могла б виглядати в такий спосіб (показаний один екземпляр дерева) рис. 2.3:
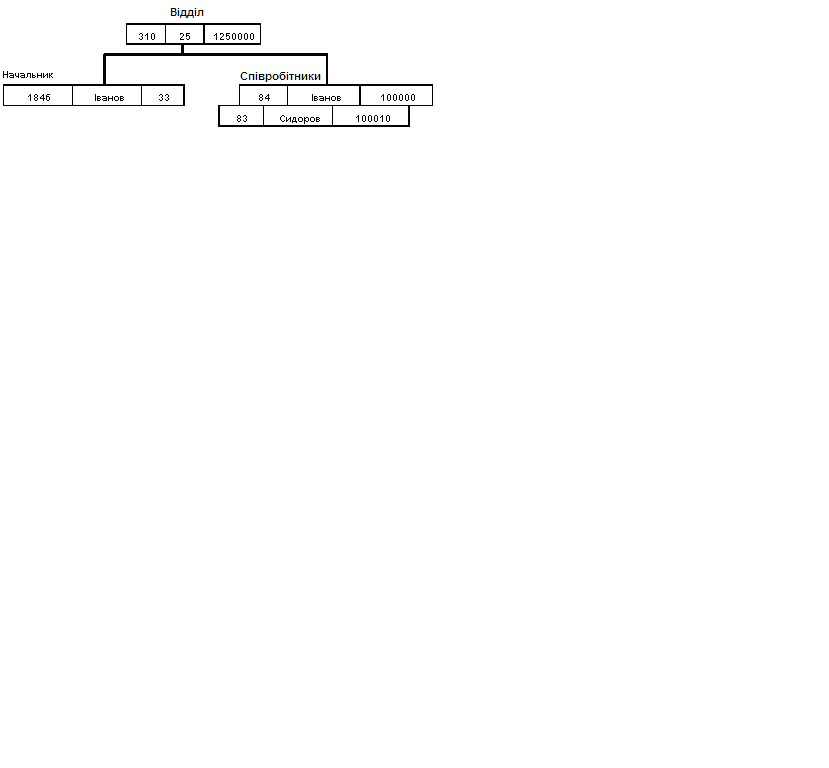
Рис. 2.3. Приклад організації ієрархічної бази даних.
Всі екземпляри даного типу нащадка з загальним екземпляром типу предка називаються близнюками. Для БД визначений повний порядок обходу - униз, праворуч. Таким чином, для читання даних з ієрархічної бази даних Було потрібно переміщатися по записах, за один раз переходячи на один запис верх, чи вниз убік.
У IMS використовувалася оригінальна і нестандартна термінологія: "сегмент" замість "запис", а під "записом БД" розумілося все дерево сегментів.
Прикладами типових операторів маніпулювання ієрархічно організованими даними можуть бути наступні:
знайти зазначене дерево БД (наприклад, відділ 310);
перейти від одного дерева до іншого;
перейти від одного запису до інший усередині дерева (наприклад, від відділу - до першого співробітника);
перейти від одного запису до іншої в порядку обходу ієрархії;
вставити новий запис у зазначену позицію;
видалити поточний запис.
Автоматично підтримується цілісність посилань між предками й нащадками. Основне правило: ніякий нащадок не може існувати без свого батька. Помітимо, що аналогічна підтримка цілісності по посиланнях між записами, що не входять в одну ієрархію, не підтримується (прикладом такої "зовнішньої" посилання може бути вміст, полючи Каф_Номер в екземплярі типу запису Куратор).
Простота моделі. Принцип побудови IMS був легкий для розуміння. Ієрархія бази даних нагадувала структуру компанії чи генеалогічне дерево.
Використання відносин предок/нащадок. СУБД IMS дозволяла легко представляти відносини предок/нащадок, наприклад,: "А є частиною У" або "А володіє В".
Швидкодія. У СУБД IMS відносини предок/нащадок були реалізовані у вигляді фізичних покажчиків з одного запису на іншу, унаслідок чого переміщення по базі даних відбувалося швидко. Оскільки структура даних у цієї СУБД відрізнялася простій, IMS могла розміщати запису предків і нащадків на диску поруч один з одним, що дозволяло звести до мінімуму кількість операцій запису-читання. СУБД IMS усе ще є однієї з найбільш розповсюджених СУБД для великих ЕОМ компанії IBM.
4 Мережеві системи
Якщо структура даних виявлялася складніше, ніж звичайна ієрархія, простота структури ієрархічної бази даних ставала її наприклад, у базі даних для збереження замовлень одне замовлення могло брати участь у трьох різних відносинах предок/нащадок, що зв'язують замовлення з клієнтом, що розмістив його, із що служить, що прийняли його, і із замовленим товаром, що ілюструє рис. 2.4. Такі структури даних не відповідали строгій ієрархії IMS.
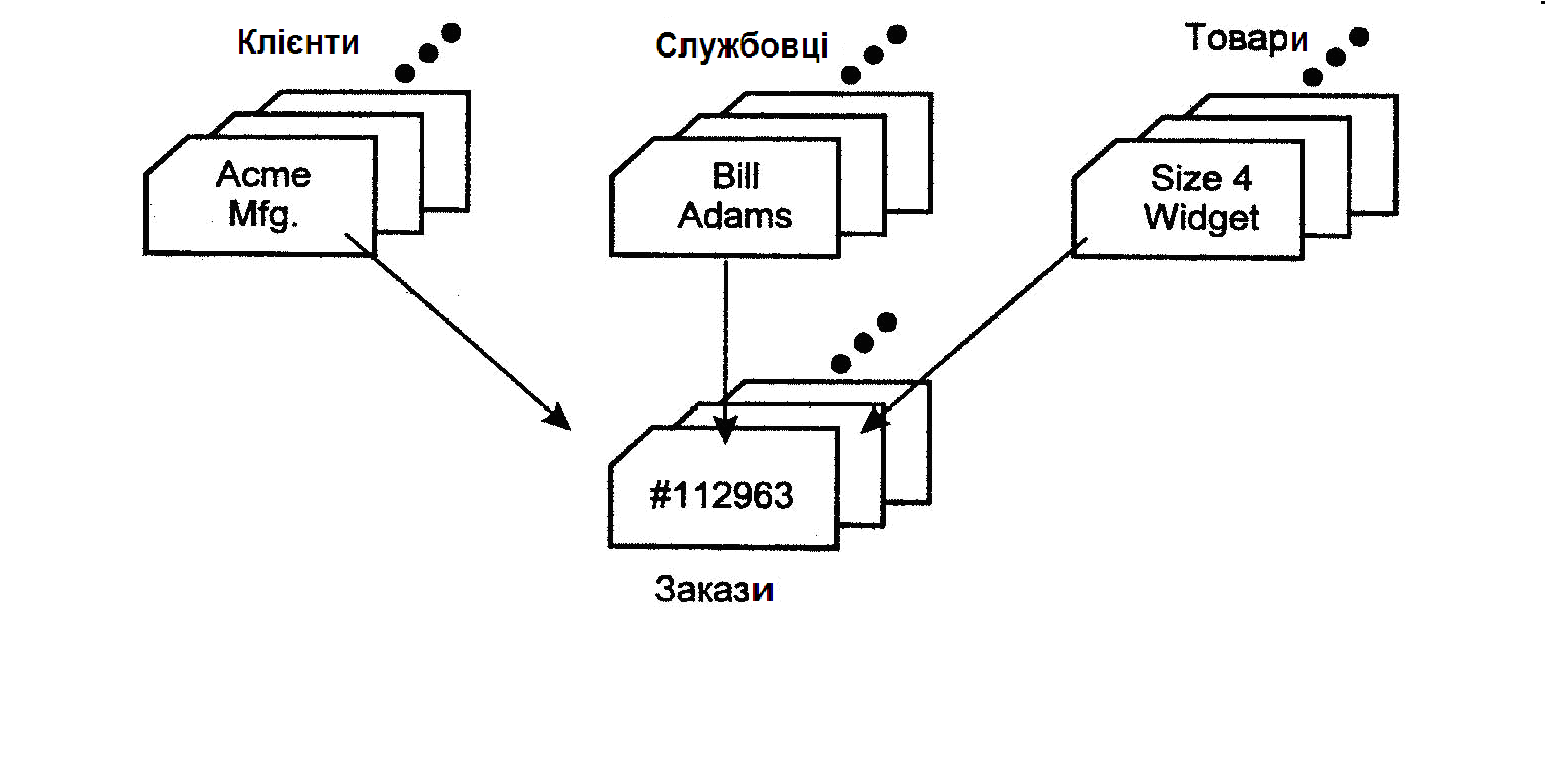
Рис. 2.4. Приклад множинних відносин предок/нащадок.
У зв'язку з цим для таких додатків, як обробка замовлень, була розроблена нова мережева модель даних. Вона була поліпшеною ієрархічною моделлю, у якій один запис міг брати участь у кількох відносинах предок/нащадок, як показано на рис. 2.5.
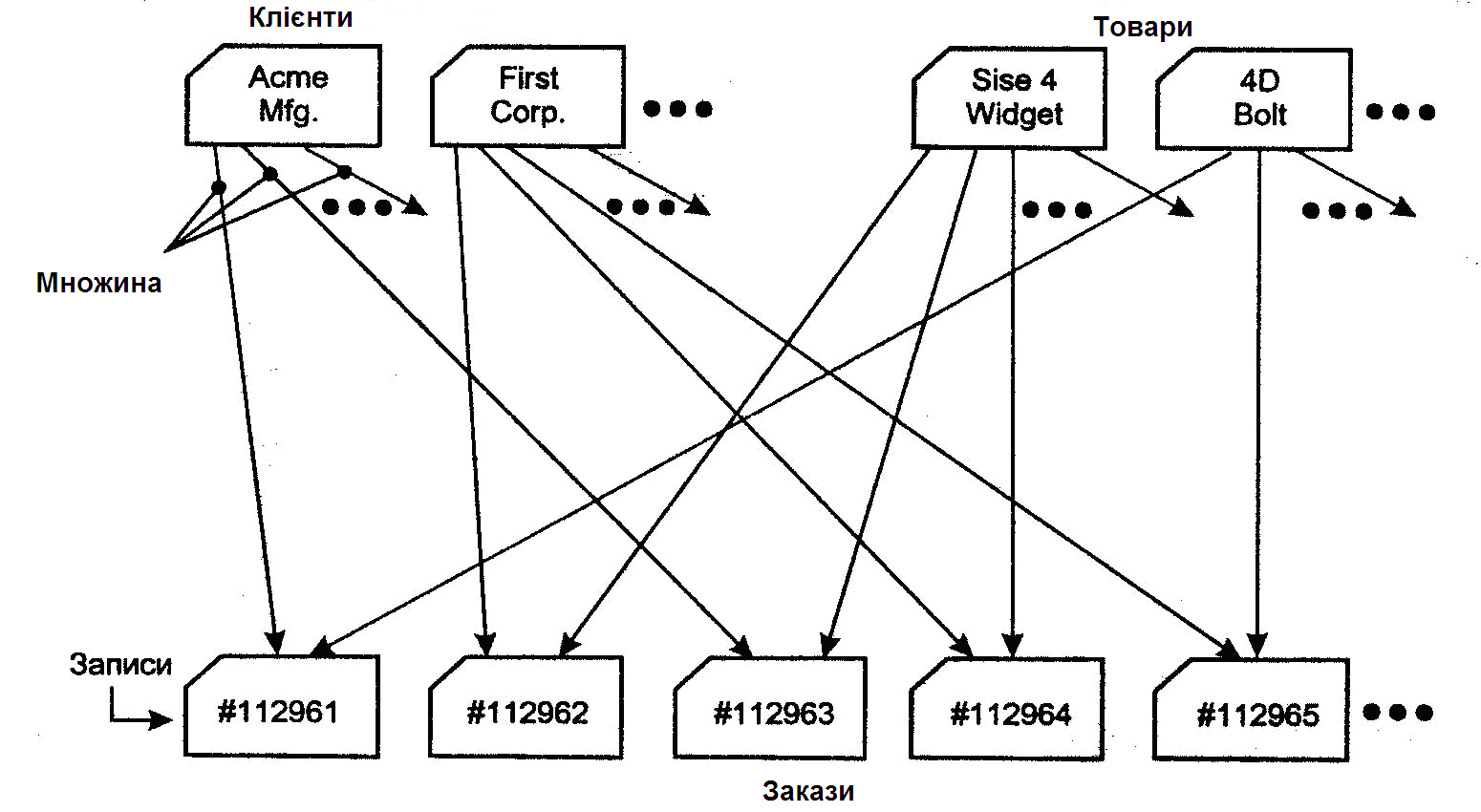
Рис. 2.5. Мережева база даних, що містить інформацію про замовлення.
У мережевій моделі такі відносини називалися множинами. У 1971 році на конференції по мовах систем даних був опублікований офіційний стандарт мережевих баз даних, що відома як модель CODASYL. Компанія IBM не стала розробляти власну мережну СУБД і замість цього продовжувала нарощувати можливості IMS. Але в 70-х роках незалежні виробники програмного забезпечення реалізували мережну модель у таких продуктах, як IDMS (Integrated Database Management System) компанії Cullinet, Total компанії Cincom і СУБД Adabas, що набули більшу популярність. З погляду програміста, доступ до мережної бази даних був дуже схожий на доступ до ієрархічної бази даних. Прикладна програма могла:
знайти конкретний запис предка по ключу (наприклад, номер клієнта);
перейти до першого нащадка в конкретній множині (перше замовлення, розміщена клієнтом);
перейти убік від одного нащадка до іншого в конкретній множині (наступне замовлення, зроблена цим же клієнтом);
перейти нагору від нащадка до його предка в іншій множині (службовець, що прийняв замовлення).
Мережевий підхід до організації даних є розширенням ієрархічного. В ієрархічних структурах запис-нащадок повинна мати в точності одного предка; у мережевій структурі даних нащадок може мати будь-яке число предків. Мережева БД складається з набору записів і набору зв'язків між цими записами, а якщо говорити більш точно, з набору екземплярів кожного типу з заданого в схемі БД набору типів запису і набору екземплярів кожного типу з заданого набору типів зв'язку. Тип зв'язку визначається для двох типів запису: предка й нащадка. Екземпляр типу зв'язку складається з одного екземпляра типу запису предка й упорядкованого набору екземплярів типу запису нащадка. Для даного типу зв'язку L із типом запису предка P і типом запису нащадка C повинні виконуватися наступні дві умови:
кожен екземпляр типу P є предком тільки в одному екземплярі L;
кожен екземпляр C є нащадком не більш ніж в одному екземплярі L.
На формування типів зв'язки не накладаються особливі обмеження; можливі, наприклад, що випливають ситуації:
тип запису нащадка в одному типі зв'язку L1 може бути типом запису предка в іншому типі зв'язку L2 (як в ієрархії).
даний тип запису P може бути типом запису предка в будь-якому числі типів зв'язку.
даний тип запису P може бути типом запису нащадка в будь-якому числі типів зв'язку.
може існувати будь-яке число типів зв'язку з тим самим типом запису предка і тим самим типом запису нащадка; і якщо L1 і L2 - два типи зв'язку з тим самим типом запису предка P і тим самим типом запису нащадка C, те правила, по яких утвориться споріднення, у різних зв'язках можуть різнитися.
типи запису X і Y можуть бути предком і нащадком в одному зв'язку й нащадком і предком - в іншій.
предок і нащадок можуть бути одного типу запису.
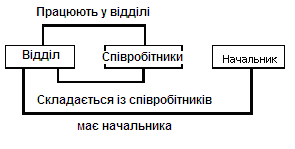
Рис. 2.6. Простий приклад мережної схеми БД.
Зразковий набір операцій може бути наступним:
знайти конкретний запис у наборі однотипних записів (інженера Сидорова);
перейти від предка до першого нащадка по деякому зв'язку (до першого співробітника відділу 310);
перейти до наступного нащадка в деякому зв'язку (від Сидорова до Іванова);
перейти від нащадка до предка по деякому зв'язку (знайти відділ Сидорова);
створити новий запис;
знищити запис;
модифікувати запис;
включити в зв'язок;
виключити зі зв'язку;
переставити в інший зв'язок тощо.
У принципі їхня підтримка не потрібно, але іноді вимагають цілісності по посиланнях (як в ієрархічній моделі).
Мережеві бази даних мають переваги:
Гнучкість. Множинні відносини - предок/нащадок дозволяли мережевій базі даних зберігати дані, структура яких була складніше простої ієрархії.
Стандартизація. Поява стандарту CODASYL збільшило популярність мережної моделі, а такі постачальники міні-комп'ютерів, як Digital Equipment Corporation і Data General почали реалізацію мережевих СУБД.
Швидкодія. Усупереч своїй великій складності, мережеві бази даних досягали швидкодії, порівнянного зі швидкодією ієрархічних баз даних. Множини були представлені покажчиками на фізичні записи даних, і в деяких системах адміністратор міг задати кластеризацію даних на основі множині відносин.
Звичайно, у мережевих баз даних були недоліки. Як і ієрархічні бази даних, мережеві бази даних були дуже твердими. Набори відносин і структуру записів доводилося задавати наперед. Зміна структури бази даних звичайно означало перебудову всієї бази даних.
Таблиця 1. Переваги й недоліки ранніх моделей даних.
Сильні сторони |
Недоліки: |
Розвинені засоби управління даними в зовнішній пам'яті на низькому рівні |
Їхня логіка переобтяжена деталями організації доступу до БД |
Можливість побудови вручну ефективних прикладних систем |
Фактично необхідні знання про фізичну організацію |
Можливість економії пам'яті за рахунок поділу підоб’єктів (у мережевих системах) |
Прикладні системи залежать від цієї організації |
|
Занадто складно користатися |