

Аналіз даних (АД) – це дисципліна і систематизує поняття, прийоми, математичні методи і моделі, що призначені для організації, збору, стандартного запису, систематизації і обробки ( втому числі і за допомогою ЕОМ) статистичних даних, з метою їх зручного представлення, інтерпретації і отримання наукових і практичних висновків.
Отже, АД – це математична обробка експеремент. даних з використанням статистичних даних.
Етапи аналізу даних.
Основні етапи:
візуальний аналіз (графіки, діаграми, таблиці);
описовий аналіз (прогнозування, запитання і відповіді);
статистична модель (регресійний, диспесійний, кореляційний аналіз і т.д.);
аналіз результатів.
Основні етапи статистичного аналізу даних:
початковий (попередній) аналіз досліджуваної системи;
складання плану для збору вихідної інформації;
збір початкових даних, їх підготовка для введення в ЕОМ;
попередня обробка даних, складання детального плану обчислювального аналізу матеріалу;
реалізація плану обчислювального аналізу початкових даних з допомогою комп'ютера;
проведення підсумків дослідження.
Класифікація типів змінних.
Змінна (англ. термін variable) – це те, що можна вимірювати, контролювати або це те, чим можна маніпулювати в дослідженнях. Іншими словами, це те, що змінюється, а не постійним (від англ. кореня var).
Розрізняють чотири типи змінних: номінальна, порядкова (ординальна), інтеравльна, відносна.
Номінальні змінні використовуються тільки для якісної класифікації. Це означає, що дані змінні можуть бути виміряні тільки в термінах належності можуть бути виміряні тільки в термінах належності до деяких суттєво різних класів, при цьому не можна визначити кількість чи впорядкувати ці класи.
Порядкові змінні дозволяють впорядковувати об'єкти, вказуючи при цьому , які з них в більшій чи меншій мірі володіють якістю, що виражається даною змінною.
Інтервальні змінні дозволяють не тільки впорядковувати об'єкти вимірювання, але і чисельно виражати і порівнювати різницю між ними.
Відносні змінні дуже схожі на інтервальні змінні. Крім всіх властивостей інтервальних змінних вони свою особливість – це наявність визначеної точки абсолютного нуля, таким чином, для цих змінних є обґрунтованим твердження типу: х в два рази більше ніж y.
Залежні змінні і незалежні.
Незалежними змінними називаються змінні, які варіюються дослідником, тоді як залежні змінні – це змінні, які вимірюються чи регіструються.
Якщо ще раз розглянути приклад з кількістю відвідувачів магазину, то інтенсивність реклами-це є незалежна змінна, а потік відвідувачів – залежна.
Метою будь-якого дослідження чи наукового аналізу є знаходження зв'язків (залежностей) між змінними, що вимірюються.
Надійність взаємозалежності менш наглядне поняття, ніж величина залежності, але дуже важливе. Надійність показує наскільки ймовірно те, що залежність, подібна до знайденої, буде знову знайдена (підтвердиться) за даними іншої вибірки.
Величина і надійність представляють собою дві різні характеристики між змінними. Але не можна сказати, що вони зовсім незалежні. В загальному можна стверджувати, що чим більша величина залежності (зв'язку) між змінними у вибірці, тим вона надійніша.
Групування даних.
Описові статистики.
Мінімум і максимум – це мінімальне і максимальне значення змінної.
Середнє
– сума значень змінної, поділене на n
(число значень змінної):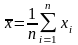
Дисперсія
вибірки
або вибіркова дисперсія
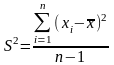 ,
,
Стандартне
відношення
–
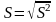 - корінь
квадратний з дисперсії.
- корінь
квадратний з дисперсії.
Медіана вибірки – значення, що розбиває вибірку на дві рівні частини. Половина спостережень лежать вище медіани, половина – нижче.
Обчислюється
таким чином: вибірка впорядковується
за зростанням, отримана послідовно
xk,
k=1,…2m+1,
називається варіаційним рядом або
порядковими статистиками. Якщо число
спостережень непарне (2m+1),
то медіана береться як xm+1,
якщо парне 2т,
то як
 .
.
Квантиль – це число хp, нижче якого знаходиться p-а частина (доля) вибірки.
Мода – значення, яке найбільш часто зустрічається, тобто найбільш „модне” значення змінної.
Асиметрія
– це характеристика форми розподілу
скошеності.
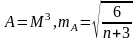 .
.
Ексцес – характеристика форми розподілу, а саме міра гостроти піку
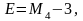
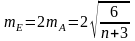 ;
;
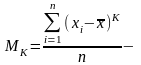 моментами
розподілу
моментами
розподілу