

7.5. Классификация мультипроцессорных систем по способу организации основной памяти
Основным классификационным признаком для архитектур мультипроцессорных систем является организация ОП. Это связано с тем, что процессы, параллельно протекающие в мультипроцессорных системах, имеют существенные связи по данным, так как решается общая задача. Это означает, что переменные, значение которых вычисляются в одном процессе, используются в качестве аргументов в других процессах. Существуют два основных типа архитектур: мультипроцессорные системы с общей памятью (рис. 7.2) и мультипроцессорные системы с распределенной памятью (рис. 7.3).

Рис. 7.2. Мультипроцессорная система с общей памятью

Рис. 7.3. Мультипроцессорная система с распределенной памятью
В системах с общей ОП процессоры имеют доступ на уровне команд к одним и тем же общим для них, данным в памяти. При этом процессор не просто решает часть задачи, но и может оперировать с ней целиком. Однако, поскольку процессоры связаны с памятью только через одну шину, возникает проблема быстрого доступа каждого из них к памяти. Частично эту проблему снимает наличие кэшей, но возникает другая, связанная с этим проблема обеспечения «когерентности кэшей», заключающаяся в оперативном отслеживании идентичности данных в кэшах и ОП. Таким образом, общая память способствует ускорению выполнения единой программы параллельно работающими процессорами за счет их быстрого доступа к общим данным в ней, но общая память одновременно является узким местом мультипроцессорной системы, так как с ростом числа процессоров их быстрый доступ к ней становится все более затруднительным.
В мультипроцессорной системы с распределенной памятью каждый процессор обладает своей собственной памятью (на рис. 7.3 П1, П2, Пn) и может иметь свои устройства для ввода и вывода. Процессоры могут быть связаны между собою в систему различными способами. Это зависит от способа реализации коммуникационной сети. В основном для коммуникаций используется сеть связи с фиксированной топологией, когда каждый из процессоров связан только с некоторой ограниченной группой близко расположенных процессоров, а не со всеми. Если требуется сеанс связи процессора с другим, удаленным процессором, с которым у данного процессора нет прямой связи, то передача данных осуществляется через промежуточные процессоры. При этом для передачи формируются сообщения (а не отдельные слова). Поэтому мультипроцессорные системы с распределенной памятью называют мультипроцессорными системами с передачей сообщений. Этот подход к построению архитектуры системы не имеет явных ограничений на число процессоров в системе и обеспечивает возможность их наращивания.
Поскольку системы с общей памятью эффективно реализуют относительно сильно связанные программы, но имеют существенные ограничения по числу процессоров, а системы с передачей сообщений, наоборот, могут иметь большое число процессоров, но программы должны быть слабо связанными, то желательно организовать совместное использование обоих типов архитектур. Примером реализации такого подхода являются кластерные системы. Системы, содержащие группы (кластеры) процессоров с относительно высокой связностью, и имеющие более низкую степень связности между процессорами из разных групп, получили название кластерных. В общем случае они имеют иерархическую архитектуру, когда внутри каждого кластера данного уровня иерархии имеются внутренние кластеры более низкого уровня иерархии.
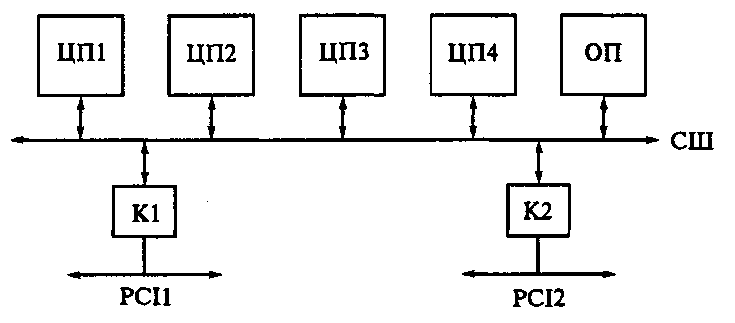
Рис. 7.4. Система SMP:
ЦП 1... ЦП4 - центральные процессоры; ОП - основная память; СШ - системная шина; Kl, К2 – контроллеры
К типу архитектур мультипроцессорных систем с общей памятью относятся системы SMP (Symmetric Multi-Processors). Для этой аббревиатуры используют также расшифровку Shared Memory Processors. В этих системах все процессоры имеют равные права по использованию разделяемых ресурсов (шины, памяти). В системе SMP (рис. 7.4), построенной на процессорах Pentium Pro, процессоры ЦП 1... ЦП4 подключены к общей СШ. Каждый процессор имеет встроенный кэш. К СШ подключена ОП. К ней может обращаться в общем АП любой из четырех процессоров. К СШ подключены два контроллера, обеспечивающие связь с двумя шинами PCI. Контроллер К1 служит мостом между шинами СШ и РС1_1. К шине РС1_1 могут быть подключены периферийные устройства (накопители на дисках, монитор и др.). Второй контроллер К2 служит мостом СШ с шиной РС1_2. Шина РС1_2 может быть использована для объединения нескольких систем SMP. В качестве примера на рис. 7.5 приведена функциональная схема вычислительной системы из 4-х узлов, каждый из которых - система SMP. Распределение задач между процессорами системы SMP осуществляет ОС. Поддержку систем SMP имеют такие ОС, как MS Windows NT, Unix.

Рис. 7.5. ВС из четырех узлов (систем SMP), объединенных через шину PCI
Среди мультипроцессорных систем с распределенной памятью большое внимание уделяется системам с массовым параллелизмом. Их в литературе часто обозначают английской аббревиатурой МРР (Massive Parallel Processing). Существует большое число способов объединения процессорных узлов в систему. Рассмотрим несколько примеров организации систем с распределенной памятью.

Рис. 7.6. МРР-система с топологией «общая шина»:
П1...П4 — память; ЦП1...ЦП4 — центральные процессоры; ИБ — интерфейсный блок.
В системе с топологией «общая шина» (рис. 7.6) в качестве общей шины используют стандартные шины PCI, VME и др. Подключение к шине осуществляется через интерфейсный блок (ИБ). Для адресации к тому или иному процессорному узлу обычно используется АП ввода-вывода. Достоинством такой топологии является относительная простота и низкая стоимость средств коммуникации. Недостатком является то, что общая шина - узкое место в информационном обмене. Это снижает эффект от увеличения числа процессоров.

Рис. 7.7. МРР-система с топологией «полный граф»: П1...П4 - память; ЦП1... ЦП4 - центральные процессоры.
Рассмотрим систему из четырех процессорных узлов с топологией «полный граф» (рис. 7.7). Цифрами 1, 2, 3 обозначены интерфейсные блоки, через которые осуществляется связь типа «точка - точка». При такой топологии каждый процессор непосредственно связан с любым другим. Это обеспечивает максимальные возможности для информационного обмена между узлами. Однако с ростом числа процессоров быстро возрастает сложность коммуникационного оборудования, что ограничивает возможности применения такой топологии.
Рассмотрим систему из четырех процессорных узлов с топологией «двухмерный гиперкуб» (рис. 7.8). При такой топологии каждый процессор непосредственно связан только с ближайшими соседями. Количество требуемых интерфейсных блоков (обозначены цифрами 1 и 2) и каналов связи здесь меньше, чем в предыдущем примере, а интенсивность информационного обмена также меньше, чем в системе с топологией «полный граф», но больше, чем в системе с топологией «общая шина». Топология «гиперкуб» находит широкое применение при построении систем с большим числом процессоров.

Рис. 7.8. МРР-система с топологией «двухмерный куб» П1...П4 - память; ЦП1...ЦП4 - центральные процессоры.
Рассмотрим основные проблемы создания систем для высокопроизводительных вычислений и тенденции в архитектурных решениях. Потребность в высокопроизводительных вычислениях по мере развития науки и техники все время возрастает. Эффективные ВС, способные осуществлять как быстрые вычисления, так и быстрый обмен данными, требуются, например, для точного прогнозирования погоды, для создания новых фармацевтических средств, для проведения научных исследований в различных областях знаний (ядерная физика, аэродинамика, генетика и др.), для задач оборонного значения и многих других. Возможность создания и использования высокопроизводительных ВС относится к факторам стратегического потенциала оборонного, научно-технического и народно-хозяйственного значения. Стоит задача: создать к 2010 г. системы с производительностью порядка 1015 операций/с (1 петафлоп). Это на 6 - 7 порядков выше, чем производительность современного компьютера.
Существуют два направления развития высокопроизводительных вычислений. Первое направление связано с применением дорогих суперкомпьютеров с уникальной архитектурой (специальные векторные процессоры, дорогостоящая сверхбыстрая память, уникальное периферийное оборудование). Известны суперкомпьютеры CRAY, NEC, IBM, Fujitsu, Эльбрус и др. Второе направление представляет собой создание систем с массовым параллелизмом, содержащих большое количество (до 1 тыс. и больше) стандартных процессоров. Это системы МРР. Основной упор при этом делается на увеличение числа процессоров и повышение степени параллелизма программ. Используется массовое производство процессоров, что способствует снижению их стоимости (в сравнении с векторными процессорами). Именно это направление стало основным в решении задач высокопроизводительных вычислений.
Произведем сравнительную характеристику систем SMP и МРР. Основное преимущество систем SMP - относительная простота программирования. В системах, где все процессоры имеют одинаково быстрый доступ к ОП, вопрос о том, какой процессор какие вычисления будет выполнять, не столь принципиален, и значительная часть вычислительных алгоритмов, разработанных для однопроцессорных компьютеров, может ускоренно выполняться в мультипроцессорных системах с использованием распараллеливающих и «векторизирующих» компиляторов. Системы SMP - это наиболее распространенный сейчас тип параллельных ВС, а 2- и 4-процессорные компьютеры на основе процессоров Pentium и Pentium Pro находят массовое применение. Однако, общее число процессоров в системах SMP не превышает 16. Для эффективного использования Процессоров в таких системах требуется решение ряда проблем, таких как когерентность кэшей, арбитраж в конкуренции за шину, обработка аппаратных прерываний. Разработаны способы решения этих проблем. Некоторые из них рассматриваются ниже. Системы МРР позволяют создавать системы с наиболее высокой производительностью. Узлами таких систем часто являются системы SMP.