

3.6. Назначение стека
Стек - это память с линейно упорядоченными ячейками и специальным механизмом доступа, исключающим необходимость указания адреса при записи и чтении. В зависимости от используемого правила доступа, называемого дисциплиной, различают два типа организации стековой памяти: очередь и стек. Дисциплина определяется применительно к входным (записываемым) и выходным (читаемым) последовательностям слов. Очередь реализует дисциплину FIFO (First-In-First-Out - первый поступивший удаляется первым). Стек в отличие от очереди организован в соответствии с дисциплиной LIFO (Last-In-First-Out - последний поступивший извлекается первым), т.е. информация из стека выбирается в обратном по отношению к записи порядке. В МП обычно используют стек. Физически стек представляет собой набор регистров (аппаратурный стек) или ячеек оперативной памяти, снабженный указателем стека SP.
Указатель SP, в качестве которого используют реверсивный счетчик, всегда адресует «вершину стека», под которой понимается ячейка стека, доступная для чтения. По мере записи и считывания данных из стека содержимое указателя SP меняется: при записи или загрузке в стек, например при исполнении команд PUSH, значение указателя SP уменьшается - стек растет в сторону младших адресов, а при чтении или выталкивании данных из стека, в частности при исполнении команд POP, значение указателя SP увеличивается. Указанное правило при обращении к стеку реализуется автоматически, и поэтому при операциях со стеком возможно безадресное задание операнда. Стековая память является безадресной.
Важнейшей характеристикой стека является его размер. МП может содержать относительно небольшой по размеру аппаратный стек (число внутренних регистров стековой памяти, как правило, не превышает 8 - 16) или не содержать такового совсем. Более распространена архитектура МП, использующая практически неограниченный внешний стек, моделируемый в ОП с произвольным доступом.
Стек играет важную роль в микропроцессорных системах как средство сохранения адресов возврата и состояния данных при работе с подпрограммами. Использование стека приводит к существенным упрощениям при организации вложенных подпрограмм, когда одна программа вызывает другую, которая в свою очередь может вызвать третью и т.д. В таких случаях при каждом вызове адрес возврата текущей программы и другая необходимая информация (содержимое РОН) загружаются в стек. При возврате информация в обратном порядке выбирается из стека. Заметим, что при организации стека, моделируемого в памяти с произвольным доступом, время обращения к элементам данных стека равно времени обращения к памяти. Однако стек наряду с отмеченными особенностями его использования эффективнее обычной памяти. Во-первых, используемые при обращении к стеку, команды PUSH и POP короче стандартных команд обращения к памяти, так как в них один из операндов неявно адресуется через регистр SP, и, во-вторых, инкремент или декремент указателя SP с образованием нового адреса производится автоматически.
В современных процессорах стек применяется для разных целей: временного хранения данных, когда для них нет смысла выделять фиксированные места в памяти; организации прерываний, вызовов процедур и возвратов из них; передачи и возврата параметров при вызовах процедур. Кроме того, стековая память является важнейшей компонентой процессоров со стековой архитектурой.
Структуру стекового процессора имеет специализированный арифметический сопроцессор (блок вычислений с плавающей точкой FPU) современных МП Pentium. Чтобы пояснить его назначение, кратко характеризуем предысторию его появления.
В связи с ограничениями на сложность схем ОБ младшие модели МП могли выполнять только операции над числами с фиксированной точкой с ограниченной длиной слова. Обработка чисел повышенной разрядности и чисел в формате с плавающей точкой в таких МП реализовывались программно. Это приводило к значительному снижению производительности.
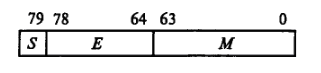
Рис. 3.4. Расширенный формат вещественных чисел:
S – знак числа; E – порядок числа; M – мантисса числа
Для эффективной реализации операций над числами в стандартных форматах в конце 70-х гг. XX в. был предложен принцип специализации. Суть его заключается в разработке специализированных процессорных модулей (сопроцессоров) со своими системами команд, которые ориентированы на конкретные приложения. Арифметический сопроцессор с плавающей точкой является примером такого модуля. Сопроцессоры обычно работают под управлением центрального процессора и совместно используют ОП. Сопроцессор не имеет своей отдельной программы и не может считывать команды из памяти, однако он может обращаться к памяти для записи и считывания данных. Часть кодов команд центрального процессора резервируется для команд сопроцессора. Сопроцессор не может выполнять команды центрального процессора, но свои команды выполняет очень быстро (по сравнению с их программной эмуляцией командами центрального процессора). В процессе работы и процессор, и сопроцессор из общего командного потока выбирают свои команды и выполняют их. Сопроцессор выполняет свои «долгие» арифметические операции параллельно с центральным процессором, при этом последний может продолжать выполнение потока собственных команд.
Такое архитектурное решение фирма Intel применила в семействе программно совместных МП 8086, 80286, 80386, 80486 (i486). Обобщенно архитектуру процессов этого семейства обозначают х86. Для младших членов семейства сопроцессоры были реализованы в виде специализированных СБИС - 8087 (для 8086), 80287 (для 80286), 80387 (для 80386). Благодаря росту уровня интеграции микросхем в МП i486 и всех моделях Pentium арифметический сопроцессор реализован в виде устройства операций с плавающей точкой FPU как составная часть процессора, т.е. является внутренним блоком МП. Размещение устройства FPU на кристалле процессора значительно повышает производительность численных вычислений. Совместно с центральным процессором сопроцессор образует мощный тандем, производительность которого в задачах численной обработки в 10-50 раз выше производительности одного центрального процессора. С точки зрения программиста, система с сопроцессором выглядит как единый процессор с расширенными возможностями ОБ, большим набором команд, форматов чисел и числом регистров. Взаимодействие между центральным процессором и FPU невидимо для пользователя.