

4.2.Иерархические подходы в службах локализации.
В такой иерархической схеме сеть делится на домены. Домен верхнего уровня охватывает всю сеть целиком. В свою очередь каждый домен делится на поддомены – иерархия. Домен самого нижнего уровня называется листовым поддоменом(доменом). Обычно этот листовой домен соответствует локальной сети.
Каждый домен имеет ассоциированный с ним направляющий узел – dir(D). Вот направляющий узел отслеживает сущности доменов. А поскольку домены – некая иерархия, то имеем в такой схеме дерево направляющих узлов. Направляющий узел самого верхнего уровня называют корневым направляющим узлом. И этот корневой направляющий узел содержит сведения обо всех сущностях.
Рассмотрим эту идею.
Структура домена.
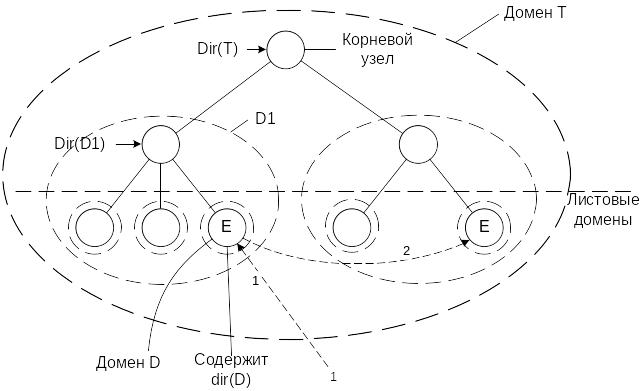
Рис. 4.24.
1: Листовой домен содержит локализующую запись для сущности E. Фактически он содержит текущий адрес сущности.
Рассмотрим домен более высокого уровня: D1. Имеем направляющий узел – dir(D1). Этот узел содержит только указатель на нижележащий направляющий узел, в котором содержится E. Он содержит не адрес сущности, а только указатель на направляющий узел.
Теперь ищем объекты.
Клиент начинает искать сущность в своем направляющем узле, то есть в своей локальной сети. Если она там есть, то все в порядке. Если нет, то подымаемся на более высокий уровень иерархии – обращаемся к направляющему узлу родителя. У него есть информация обо всех сущностях, входящих в его домен. Если там есть она, то известно куда надо спуститься. Если инфо об этом объекте нет, тогда нужно перемещаться на более высокий уровень и так, пока не доберемся до корневого узла. Он знает все и он направит.
Как осуществляется перемещение сущности: выполняется пересылка сообщений вышележащем узлам, что объект переместился. Как только до корневого узла все узлы это обработали, то фиксируется E в новом узле, а из старого удаляется.
4.2.1Кэширование указателей
Будут говорится для нас очевидные вещи. Если мобильность объектов отсутствует или мала, то если клиент обратился к сущности, прошел по иерархической цепочке, получил инфо, то может ее кэшировать. При повторных обращениях кэш ускоряет поиск сущности.
Есть различные варианты перемещения сущности:
только в пределах листового узла, тогда в вышестоящих узлах инфо стабильна.
если в пределах листовых узлов, то через уровень инфо стабильна.
4.2.2Масштабирование
Когда сеть разрастается до больших размеров, то корневой узел – узкое место: к нему постоянно идут запросы и от него идут запросы.
Загрузка сети пакетами, транзакциями.
Тогда надо корневой узле надо разбить на несколько компьютеров, и распределяем нагрузку по ним. Если на более низких уровнях начинаются перегрузки, то там выполняется эта же процедура.
4.3.Объектный трейдинг.
Бывают ситуации, когда клиент напрямую не может идентифицировать сервер. Тогда выход этого сервера по просьбе клиент осуществляет трейдер: он выбирает поставщика сервиса или сервера, опираясь на некоторые требуемые характеристики требуемого сервиса. Тогда просматривается следующая схема.
Идентификация через поставщика.
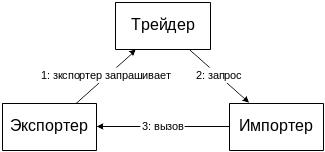
Рис. 4.25.
Трейдер – служба. Експортер сообщает трейдеру, какие он может оказывать услуги.
Имортер обращается к трейдеру с просьбой найти услуги нужного качества.
Трейдер знает об оказываемых услугах и куда нужно обратиться для ее получения.
Тогда импортер непосредственно обращается к экспортеру за этими услугами.
Покупка и продажа акций. Покупателю надо выяснить условия сделки. Есть некий интерфейсный компонент, с помощью которого он будет выяснять условия сделки. С помощью этого компонента клиент будет связываться с фондовыми биржами, выяснять условия сделки и принимать решение, с какими из фондовых бирж он будет взаимодействовать.
В такой постановке задачи на этапе компиляции ничего сделать нельзя. Задача динамична. И на этот компонент должны возложить достаточно большие задачи. Сервисные компоненты являются экспортерами. А трейдер осуществляет поиск для интерфейсного компонента клиента – для импортера. Импортер просто будет обращаться к трейдеру. А экспортеру выгодно, чтобы к нему обращались. Зарегистрируется у терейдера и даст ему инфо и сообщит о своих характеристиках.
Импортер обращается к трейдеру, выставляя условия на характеристики и трейдер выдает список экспортеров, удовлетворяющих условиям. После чего импортер непосредственно обращается к экспортеру.
4.3.1Просматривается инфо обмена.
Типы сервиса определяют функциональный состав и качество сервиса.
Функциональный состав определяется операциями, которые этот сервис экспортирует. В рассмотренном примере это покупка и продажа акций.
Качество сервиса
Свойство представляют пару: (<name>, <value>). Эта пара описывает характеристику сервиса. В примере – это процентная ставка от сделки. Важно чтобы импортер и экспортер понимали свойство одинаково.
4.4.Синхронизация
Рассмотрим однопроцессорную систему. Таймер и центральный процессор.
В распределенных системах гораздо сложнее. У каждого компьютера свой уникальный кварц. Проблема синхронизации часов.(Windows Time service – и ее нет).
Если будем привязываться к физическим часам, то у нас в идеальном случае:
![]() (4.1)
(4.1)
где Cp(t) – показываемое время
t – реальное время
Тогда для синхронизации надо наложить ограничения на производные. Например, так:
![]() (4.2).
(4.2).
Тогда эта величина будет характеризоваться величиной 2ρ.