

12.2 Эмулирование моделей данных
Давно известно, что в реальных информационных системах трудно обойтись единственной моделью данных. В однослойной конструкции одна из моделей выбирается в качестве базисной. Именно она определяет структуры хранения данных. Остальные модели эмулируются, то есть реализуются через базисную модель. Мы уже представляли в реляционной модели древесные и полуструктурированные данные.
Понятно, что эмулированная структура может обладать многими недостатками. Однако известная идея о том, что все необходимые модели должны быть нативными, то есть реализованными независимо в рамках одной СУБД, вряд ли когда-нибудь будет поддержана вендорами. Именно поэтому мы посмотрим, что может дать эмуляция моделей в базисной табличной и иерархической моделях.
Мы попробуем бороться с почти очевидными недостатками, такими как неоптимальность хранения, сложность манипулирования данными и невысокое быстродействие. Но будут отмечены возможные области применения и особенности эмулированных систем, которых нет в базисной модели данных. Это преимущества работы с постоянно изменяемыми структурами данных, возможность реализации полуструктурированных, табличных, объектных, объектно-реляционных моделей, различных сетей и деревьев, возможность работы с базами, содержащими очень большое число мало заполненных таблиц.
Модели, эмулированные в табличной модели данных
Структуры данных во время работы базы изменяются довольно редко. Однако существует два типа систем, в которых схема базы перестраивается постоянно:
Информационные системы (ИС) с данными, структуры которых невозможно предусмотреть заранее. Типичный пример – медицинские данные.
Средства разработки ИС. Особый интерес представляют инструментальные средства, в которых структуры данных или же весь прототип ИС собирается “на ходу” в процессе сбора сведений о предметной области и решаемой задаче, причём иногда необходимы откаты создаваемых архитектур.
Подобные системы можно реализовать с помощью виртуальных баз данных со следующими свойствами:
Виртуальные структуры данных, включая словарь и сами данные, хранятся в фиксированном наборе таблиц вмещающей базы и могут изменяться в процессе работы. Допускаются откаты команд языка определения данных (DDL), чего нет в обычных базах данных.
Словарь вмещающей базы не содержит данных словаря виртуальной базы.
Возможен экспорт и импорт из виртуальной базы во вмещающую базу или базу с другой моделью данных.
Впервые базы данных с такими свойствами были предложены в восьмидесятых годах для работы с медицинскими данными. Из-за разнообразия медицинских данных в реляционной базе их необходимо размещать в разных таблицах, причем при появлении новых видов анализов на ходу должны появляться новые таблицы. В подобных базах ускоряются только запросы, ориентированные на получение полной информации по пациенту.
Из-за недостаточной известности подобных работ и очевидности идеи построения виртуальной базы это направление несколько раз открывалась повторно. При этом в большинстве таких работ базы данных с описанными свойствами предлагались как альтернатива обычной базе со словарем, а не как средство реализации изменяющихся частей базы. На наш взгляд, это малоперспективный подход, поскольку, решая основную задачу получения инвариантной структуры, в которой хранятся данные с меняющейся структурой, мы резко увеличиваем сложность запросов, значительно (в разы) уменьшаем скорость их исполнения и порождаем целый ряд проблем, связанных с представлением ограничений целостности, индексов и других хранимых объектов.
Базы с описанными свойствами принято называть универсальными (УБД), говорят и об универсальной модели данных (УМД).
Реализация УМД может быть выполнена в трёх основных вариантах:
с использованием инвариантных структур в обычной базе, например, реляционного типа;
на основе XML-баз или XML-опций баз данных;
на основе иерархических моделей.
Выбор предпочтительного варианта зависит от того, насколько удается использовать возможность включающей СУБД. Современные реляционные базы данных редко имеют мощные средства для работы с XML. Для реализации УМД на основе XML необходимо, чтобы данные хранились в уже разобранном виде, а не цельным текстом. Кроме того, необходима поддержка языков для работы с XML: XPath, XQuery и т.п. Желательно, чтобы СУБД предоставляла средства для вставки и изменения в середине документа. Не все современные СУБД располагают перечисленными возможностями.
УМД на основе иерархических моделей будут бегло рассмотрены в следующем разделе.
УМД на основе табличной модели состоит из фиксированного набора таблиц. Она может хранить в себе и данные, и метаданные нескольких виртуальных схем базы. В простейшем варианте УМД представляет собой набор из четырех таблиц изображённый на рис.12.6.

Рис. 12.6. Ненормализованный вариант УМД
Этот набор таблиц остаётся неизменным при любых изменениях виртуальной схемы данных и самих данных. Для добавления имени таблицы в виртуальную схему необходимо добавить одну строку в таблицу “Таблица”, а для добавления столбца – добавить одну строку в таблицу “Столбец”. Количество строк в таблице “Данные”, определяющих одну строку таблицы, равно числу столбцов у этой таблицы. Тип столбца может быть описан в колонке “Описание” таблицы “Столбец”, но может быть добавлен в дополнительном столбце. Заметим, что может быть создана не только пустая виртуальная схема, но и таблица без столбцов, не существующая в реляционной модели.
Приведенная схема УМД сделана ненормализованной для того, чтобы при запросах к виртуальным таблицам обращаться к единственной таблице “Данные” и тем самым сократить количество соединений таблиц. Число соединений таблицы данных с собой на единицу меньше числа столбцов в соответствующей виртуальной таблице.
Одной команде DML для виртуальной таблицы соответствует транзакция в виде набора из однотипных команд записи, обновления или удаления данных для реальной таблицы данных из УМД. Их число также на единицу меньше числа столбцов в соответствующей виртуальной таблице.
Как уже упоминалось, УМД обладают следующими недостатками:
очень сложные запросы;
низкое быстродействие;
отсутствие во многих реализациях ограничений целостности (ОЦ) (декларативных и процедурных), индексов, пользователей, ролей, представлений.
Сосредоточимся на путях устранения этих недостатков и расширении класса виртуальных моделей, которые могут быть реализованы в УМД.
Проблема сложности запросов в одной из наших реализаций была решена за счёт создания претрансляторов из языка Query-by-Example (QBE) для виртуальной базы в запросы к реальным таблицам для СУБД Oracle и Caché. Запросы всегда пишутся в виртуальной базе, и имеется возможность проконтролировать исполняемый запрос. Заметим, что можно было бы использовать претранслятор из языка SQL и транслировать запрос в любой язык, принятый во вмещающей СУБД. Важно лишь, чтобы пользователь обращался непосредственно только к виртуальной базе.
На рисунке 12.7. представлен пример запроса на языке QBE к виртуальным таблицам УМД в реализованном варианте транслятора в Oracle. Имена с двумя знаками подчеркивания в первой и последней позиции обозначают переменные.

Рис. 12.7.
Транслятор создаёт запрос к виртуальным таблицам УМД на языке SQL:
SELECT emp.ename, emp.job, emp.sal, emp.deptno, dept.dname
FROM emp, dept
WHERE emp.deptno=dept.deptno;
Он транслируется в представленный ниже запрос к реальным таблицам УМД, использующий соединения таблиц:
SELECT T1.VAL,T2.VAL,T3.VAL,T4.VAL,T5.VAL
FROM TC T1, TC T2, TC T3, TC T4, TC T5, TC T6, TC T7, TC T8
WHERE T1.COLUMN_NAME='ENAME' AND T1.TABLE_NAME='EMP' AND T1.SCHEME_NAME='SCOTT'
AND T2.COLUMN_NAME='JOB' AND T2.TABLE_NAME='EMP' AND T2.SCHEME_NAME='SCOTT'
AND T3.COLUMN_NAME='SAL' AND T3.TABLE_NAME='EMP' AND T3.SCHEME_NAME='SCOTT'
AND T4.COLUMN_NAME='DEPTNO' AND T4.TABLE_NAME='EMP' AND T4.SCHEME_NAME='SCOTT'
AND T5.COLUMN_NAME='DNAME' AND T5.TABLE_NAME='DEPT' AND T5.SCHEME_NAME='SCOTT'
AND T6.COLUMN_NAME='DEPTNO' AND T6.TABLE_NAME='EMP' AND T6.SCHEME_NAME='SCOTT'
AND T7.COLUMN_NAME='DEPTNO' AND T7.TABLE_NAME='DEPT' AND T7.SCHEME_NAME='SCOTT'
AND T8.COLUMN_NAME='SAL' AND T8.TABLE_NAME='EMP' AND T8.SCHEME_NAME='SCOTT'
AND T1.STRING_NUMBER=T2.STRING_NUMBER AND T1.STRING_NUMBER=T3.STRING_NUMBER
AND T1.STRING_NUMBER=T4.STRING_NUMBER AND T1.STRING_NUMBER=T6.STRING_NUMBER
AND T1.STRING_NUMBER=T8.STRING_NUMBER AND T2.STRING_NUMBER=T3.STRING_NUMBER
AND T2.STRING_NUMBER=T4.STRING_NUMBER AND T2.STRING_NUMBER=T6.STRING_NUMBER
AND T2.STRING_NUMBER=T8.STRING_NUMBER AND T3.STRING_NUMBER=T4.STRING_NUMBER
AND T3.STRING_NUMBER=T6.STRING_NUMBER AND T3.STRING_NUMBER=T8.STRING_NUMBER
AND T4.STRING_NUMBER=T6.STRING_NUMBER AND T4.STRING_NUMBER=T8.STRING_NUMBER
AND T5.STRING_NUMBER=T7.STRING_NUMBER AND T6.STRING_NUMBER=T8.STRING_NUMBER
AND (T6.VAL=T7.VAL AND TO_NUMBER(T8.VAL)>10000);
Схема, в которой выполняется этот запрос, соответствует схеме, представленной на рис.12.6, но с другими названиями таблиц и столбцов. В частности, таблица «Данные» носит название «TC». Из-за использования многократных соединений таблицы данных с собой в дальнейшем будем говорить о методе соединений. Конечно, такого рода запросы выполняются гораздо медленнее традиционных. Заметим, что писать вручную подобные запросы было бы крайне неудобно, но ещё труднее выполнять их проверку.
Второй способ обращения к реальным таблицам УМД – использование метода Т. Кайта для транспонирования строк в столбцы. Рассмотренный выше запрос к виртуальным таблицам emp и dept, после трансляции в запрос к реальным таблицам УМД будет иметь следующий вид:
SELECT T1.ENAME,T1.JOB,T1.SAL,T1.DEPTNO,T2.DNAME
FROM (SELECT STRING_NUMBER,
MIN(DECODE(COLUMN_NAME,'ENAME',VAL)) ENAME, MIN(DECODE(COLUMN_NAME,'JOB',VAL)) JOB,
MIN(DECODE(COLUMN_NAME,'SAL',VAL)) SAL, MIN(DECODE(COLUMN_NAME,'DEPTNO',VAL)) DEPTNO
FROM TC
WHERE TABLE_NAME='EMP'
AND SCHEME_NAME='TEST'
GROUP BY STRING_NUMBER) T1,
(SELECT STRING_NUMBER,
MIN(DECODE(COLUMN_NAME,'DNAME',VAL)) DNAME,
MIN(DECODE(COLUMN_NAME,'DEPTNO',VAL)) DEPTNO
FROM TC
WHERE TABLE_NAME='DEPT'
AND SCHEME_NAME='TEST'
GROUP BY STRING_NUMBER) T2
WHERE T1.DEPTNO=T2.DEPTNO
AND T1.SAL>10000;
Такой запрос в СУБД Oracle выполняется гораздо быстрее, чем составленный по первому методу. Кроме того, можно повысить быстродействие путем добавления индексов на таблицу данных. Конечно, это частичное решение проблемы быстродействия, и рекомендация по использованию УБД остаётся прежней: только инструментальные средства и часть базы с постоянно меняющимися структурами данных.
Интерфейс прототипа использующего метод Кайта представлен на рис. 12.8. В окне слева представлен набор виртуальных таблиц, входящих в схему (в примере это TEST), в которой он в данный момент работает. Справа находится область построения запросов на языке QBE. Внизу пользователь видит транслированный запрос на языке SQL, метод по которому проводилась трансляция, количество строк результата и сам результат. Имеется возможность экспорта и импорта виртуальной базы в реальную.
Используя пункт меню «УСБД» (Универсальная Схема Базы Данных) пользователь имеет возможность:
загружать/выгружать таблицы РМД в/из УСБД;
открывать и использовать другие схемы УМД;
создавать и удалять схемы УМД.
В позиции меню Файл > Настройки пользователь может изменять метод трансляции и другие опции системы.
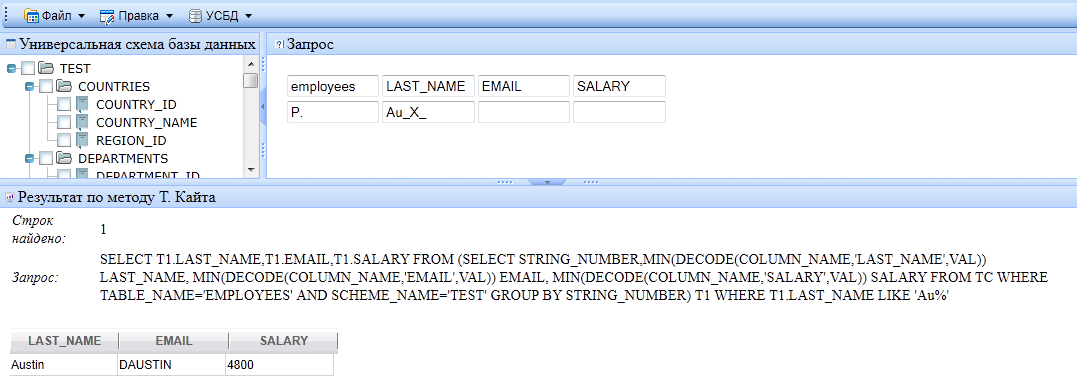
Рис. 12.8. Пример выполнения запроса
В системах управления базами данных реляционного типа активность проявляется при наступлении события из некоторого жестко заданного списка. Приспособить ее для работы в УМД невозможно, т.к. событий, связанных с виртуальной схемой для СУБД не существует. Для реализации декларативных ограничений целостности в УМД необходимо добавить таблицу с описанием этих ограничений, информация в которой аналогична описанию декларативных ограничений в словаре системы управления реляционными базами данных (рис. 12.9). Она содержит следующие поля: владелец, имя_ограничения, тип_ограничения, имя_таблицы_для_которой_действует_ограничение, условие_поиска, правило_удаления, статус, связано_с_представлением. Для таблиц Таблица и Данные (рис. 12.6) необходимо добавить триггеры на события DML. В зависимости от обрабатываемой виртуальной таблицы эти триггеры вызывают процедуры, реализующие декларативные ограничения целостности на виртуальные таблицы. Для каждого типа декларативного ограничения целостности определена одна параметрическая процедура, реализующая это ограничение.

Рис. 12.9. УМД с поддержкой декларативных ограничений целостности
Процедурные ограничения целостности в виртуальной базе представлены триггерами. Каждый триггер можно привязать только к одной таблице или представлению. Для реализации процедурных ОЦ в УМД предлагается два варианта. В первом используется пакет DBMS_SQL. К УМД добавляется таблица описания триггеров, в которую записываются транслированные триггеры при загрузке таблицы из РМД в УМД. Трансляции в теле триггера подвергаются только SQL-выражения, а также ссылки на реальные таблицы. Остальной код на PL/SQL остается в прежнем состоянии. Для таблиц Таблица и Данные создаётся по одному триггеру на каждый из возможных двенадцати типов триггеров или 4 триггера (с фразой “inserting or updating or deleting”), которые будут находить соответствующие типы триггеров по таблице Триггер, проверять соответствие условию и исполнять тело триггера с помощью пакета DBMS_SQL. Если тело триггера представляет собой вызов процедуры, то для процедуры РМД создается аналог в схеме УМД с транслированным телом по тем же правилам, что и для триггера. В таблице Триггер хранится информация, аналогичная хранимой в словаре СУРБД. Примерная схема такой реализации представлена на рис. 12.10.

Рис. 12.10. Первый вариант УМД с поддержкой процедурных ОЦ
При втором подходе для каждого триггера из РМД создается соответствующий триггер в УМД. Так же, как и в первом подходе, изначально к УМД добавляется таблица описания триггеров, которая будет использоваться только для обратной выгрузки триггера в РМД. В ней хранится информация, аналогичная хранимой в словаре СУРБД. Для каждого триггера РМД в схеме УМД создается аналогичный триггер, но при этом транслируется часть when и тело триггера. Триггерам РМД на события DDL в УМД соответствуют триггеры на события DML. В части when всегда будет условие на то, что в текущем запросе участвует виртуальная таблица и схема. Если часть when триггера РМД непустая, то она транслируется и добавляется к условию. Тело триггера также необходимо транслировать, причем трансляции необходимо подвергнуть только SQL-выражения, а также ссылки на реальные таблицы. Остальной код на PL/SQL остается в прежнем состоянии. Если тело триггера представляет собой вызов процедуры, то для процедуры РМД создается аналог в схеме УМД с транслированным телом по тем же правилам, что и для триггера. Схема реализации (рис. 12.11) получается довольно близкой к предыдущей (рис. 12.10).
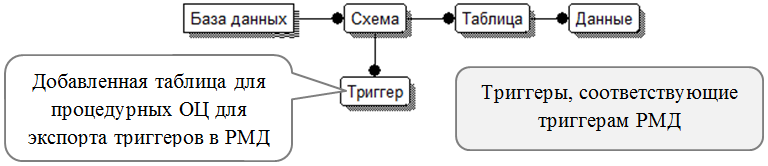
Рис. 12.11. Второй вариант УМД с поддержкой процедурных ОЦ
Для реализации представлений в УМД также необходимо добавить таблицу описания представлений. При загрузке представления его запрос транслируется в запрос к УМД и записывается в таблицу Представление (рис. 12.12). Так же, как в случае с триггерами, с реализацией представлений возможны два варианта. Первый вариант основан на триггере с событием select. Наличие претранслятора в архитектуре системы позволяет определять эквиваленты триггеров на любые события, в том числе и на выборку данных.
При выполнении запроса транслятор заменяет название представления в части from на inline-view с запросом, записанным в таблице Представление, который был транслирован для УМД. Далее запрос исполняется как обычно.

Рис. 12.12. Первый вариант УМД с поддержкой представлений
Второй вариант предполагает создание реальных представлений РМД работающих с таблицами УМД (рис. 12.13), полученных на основе текста запроса представления реляционной модели, транслированного для УМД. В этом случае придется менять логику работы транслятора.
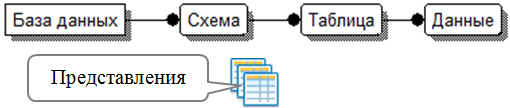
Рис. 12.13. Второй вариант УМД с поддержкой представлений
Чтобы разграничить схемы и права доступа так, чтобы пользователь мог работать только со своей схемой, необходимо в схему УМД добавить таблицу, описывающую пользователя. В простейшем случае эта таблица будет содержать поля: имя пользователя, пароль, открыта ли учетная запись (0/1). Эта таблица будет справочником для таблицы Схема, у которой будет поле, ссылающееся на пользователя.
Далее необходимо создать триггер на logon, который будет по подключившемуся пользователю находить соответствующую ему схему и запомнит ее. Далее для таблиц Схема, Таблица и Данные определяются политики DBMS_RLS, которые будут возвращать в качестве предиката: scheme_name in (<определенные по пользователю схемы>). В таком варианте пользователю может соответствовать несколько схем. В остальном логика работы УМД остается неизменной.
Если мы захотим использовать несколько пользователей и схем, то придется добавить еще одну таблицу, содержащую объектные права. На основе таблицы права доступа можно создать (изменить) политики DBMS_RLS, которые будут реагировать на различные команды DML. Иллюстрация описанного подхода представлена на рис. 12.14.

Рис. 12.14. УМД с поддержкой пользователей
Реализовать сегментацию таблиц в УМД можно способом, подобным описанным выше, а именно, добавлением таблицы описания разделов виртуальных таблиц (рис. 12.15). В таком случае необходимо будет на этапе трансляции определять, есть ли разделы в данной таблице и в какой раздел попадают значения, удовлетворяющие условиям поиска, – некое подобие индекса. Если же для таблицы не определены разделы, то транслировать запросы к ней можно как обычно.
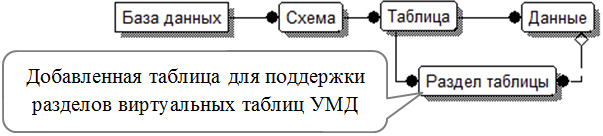
Рис. 12.15. УМД с поддержкой сегментации таблиц
Полная схема УМД, включающая все расширения, представлена на рис. 12.16.
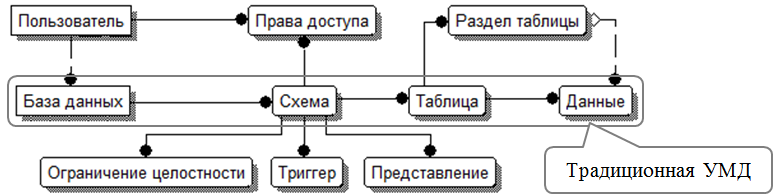
Рис. 12.16. Расширенная УМД
Можно реализовать также объектно-реляционную модель, модели графов и сетей.
Полуструктурированные данные могут быть реализованы с использованием универсальных моделей данных. При этом необходимо учесть, что УМД не только эмулирует реляционную схему, имеющую сравнительно небольшое число таблиц – до сотен или немногих тысяч. В УМД можно легко реализовать очень большие схемы. Поэтому каждый объект базы можно реализовать в виде отдельной таблицы, связав дополнительным полем объекты одного класса. Минимальный путеводитель в такой базе может быть вообще пустым, точнее сдержать всего два узла.
Подведём итоги. Универсальная модель на базе табличной может быть применена для создания подсхем с данными, структуры которых невозможно предусмотреть заранее, Её удобно использовать в инструментальных средствах разработки информационных систем. Возможно эмулирование других моделей.
Частично или полностью можно преодолеть три основных недостатка УМД:
неприемлемая сложность написания запросов (устранено);
очень низкое быстродействие (частично устранено);
отсутствие ряда важных хранимых объектов, без которых полноценная работы в этой модели невозможна: ограничения целостности, триггеры, представления, схемы и пользователи (устранено).
Отметим, что описанная реализация УМД потребовала использования весьма нестандартной семантики.
Модели, эмулированные в иерархической модели данных
СУБД Caché обладает уникальными особенностями, которые позволяют существенно расширить её возможности. Использование двух моделей – объектной и реляционной, обычная вещь в сегодняшних базах данных. Неразрывная связь этих моделей – явление уникальное. Ещё важнее то, что СУБД имеет эффективный язык для работы с деревьями, позволяющий организовывать многопоточную работу, но иерархическая модель данных не организована. Это позволяет, используя COS, расширить возможности СУБД Caché за счет введения практически любых моделей данных и усилить технологическое оснащение программирования за счет разработки транслятора для любой парадигмы.
Как и в реализации полуструктурированной модели, описанной выше, для эмулирования в иерархической модели необходимо деревья Caché пополнить различными ссылками. При этом в двухсторонних (т.е. неориентированных) ссылках при добавлении ссылки из одного узла на другой в последнем должна автоматически появляется ссылка на первый узел. Это обеспечивает навигацию по любым путям.
Обратим внимание на то, что универсальная модель данных, представленная на рис. 12.6, это дерево с четырьмя уровнями ”схема” (это корень), “таблица”, “столбец”, “данные” (имеется в виду значение в ячейке на пересечении строки и столбца). Отсюда понятно, как эмулировать модели табличного типа, объектные и объектно-реляционные модели.
Сети можно хранить двумя способами. Узлы сети и их значения находятся на первом уровне дерева. В первом случае (будем говорить о подходе от значений) информация о том, что элементы (a1,a2,...,an) находятся в ориентированном отношении с именем ρ, хранится как часть значения узла a1. Во втором варианте (подход от индексов) – в индексах потомков узла a1. Если сеть хранится в глобале ^P, то такое отношение будет храниться как узел ^P(a1,a2,...,an) со значением ρ. Если этот набор узлов связан несколькими отношениями, то они перечисляются в значении узла ^P(a1,a2,...,an) через запятую. Если отношение неориентированное, то информация о нем хранится в каждом из узлов, участвующих отношении.
На рис. 12.17а) в качестве примера показана сеть из трех узлов, представляющих трех человек – Алексея, Васю и Машу. На рис. 4б) изображено дерево, представляющее эту сеть при хранении ссылок в индексах дерева. На рис. 4в) – та же сеть, но расположенная в дереве с хранением информации о ссылках в значениях узлов. Первым элементом этого списка значений будет элемент, характеризующий узел сети, но не отношения, в которые он входит (на рис. 4б) и 4в) эта часть представлена многоточием). На четных позициях, начиная со второй, помещаются имена отношений, на следующих за ними нечетных – списки узлов, входящих в отношения с предшествующим именем. Выбор такого представления обусловлен тем, что поиск по равенству выполняется непосредственно функцией $ListFind.
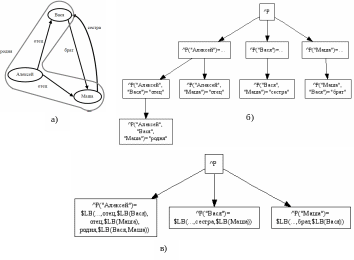
Рисунок 12.17. Пример сети и два подхода к её хранению.
Моделирование отношений произвольной арности позволяет представлять гиперграфы и семантические сети. Можно представлять наборы N=<A,K,N,U,f>, где
A – конечное множество вершин;
B – множество кортежей < a1,a2,...,an >, где a1,a2,...,an A. Каждый кортеж соответствует вершинам сети, которые находятся в некотором отношении;
T – конечное множество имен отношений;
U – мультимножество, состоящее из элементов u(TB);
f(а) – функция, которая каждой вершине аA ставит в соответствие некоторое значение. Это значение, в зависимости от интерпретации может быть и набором параметров и именем функции, которую нужно вызвать.
Как уже упоминалось, в неориентированных отношениях каждый узел содержит ссылки на все остальные узлы, связанные этим отношением. Из-за большой избыточности такого представления предлагается использовать следующий подход. В дереве создается два поддерева: одно – для хранения узлов, другое – для неориентированных отношений. Ориентированные отношения хранятся как обычно, а неориентированные как ссылки на одноуровневые деревья, узлами которых являются имена узлов, состоящих в данном отношении. На рис. 12.18а) изображен гиперграф, а на рис. 12.18б) – дерево, представляющее этот гиперграф. Ориентированные отношения хранятся в нем в узлах, как описано выше. На неориентированные отношения дается только ссылка. Эта ссылка представляет собой список из двух элементов: первый – это имя отношения, а второй – номер набора элементов для этого отношения. Теоретически эти наборы могут быть использованы несколько раз, но если набор узлов для одного из этих отношений изменился то, чтобы сослаться на него, придется либо создавать новый, либо искать равный среди уже существующих.
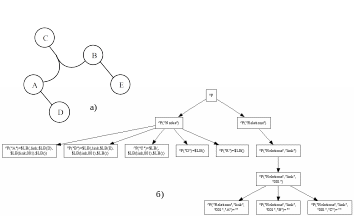
Рисунок 12.18. Гиперграф и его реализация в Caché
На основе предложенного подхода в Caché могут быть реализованы двудольные графы сетей Петри. Необходимо организовать представление фишек и создать автомат, обеспечивающий работу сети.
Фишки, в том числе разносортные, представляются значениями узлов. В варианте с хранением сети в одном глобале индексы мест сети Петри получают префикс “P_”, а переходы снабжаются префиксом “B_”. В результате автоматической сортировки узлов все переходы располагаются левее всех мест. Естественно, в реализации использовано ограничение “ребра между однотипными узлами не существуют”. Возможны два варианта обхода сети – синхронный и асинхронный. Синхронный обход может бытьреализован методом, использующим функцию $Order, которая в цикле перебирает всех потомков корневого узла, представляющих переходы сети. Для каждого такого узла анализируется возможность перехода и при положительном решении переход выполняется.
Для изменения порядка обхода узлов, представляющих переходы, достаточно расширить префикс. Изменение порядка обхода при необходимости может быть выполнено «на ходу» путем переписывания графа. Другой вариант – задание списка вершин для обхода параметром метода, выполняющего обход.
Асинхронный обход моделируется набором фоновых процессов, запускаемых операторами job. Каждый процесс следит за одним или несколькими переходами и через заданный интервал времени пытается выполнить свой переход. Задержки введены для уменьшения нагрузки процессора.
Пример простой сети Петри, и её представление в Caché приведены на рис. 12.19. В значениях узла первый элемент для переходов – пустая строка, а для мест – количество фишек. “link” – имя отношения, необходимое для организации ссылки.
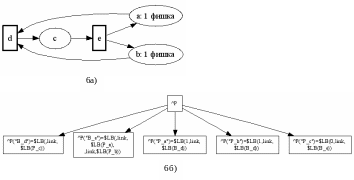
Рисунок 12.19. Сеть Петри и её реализация в Caché .