

Методика наблюдений и метод учета урожая
Учет урожая проводился сопряжено с закладкой почвенных разрезов, согласно методике полевого опыта с делянок площадью 1 м2. Для этого в производственных посевах зерновых культур в четырехкратной повторности отобраны снопы, которые доставлялись в лабораторию и в лаборатории проводился разбор снопа.
Такой спряженный учет урожая позволяет определить зависимость эффективного плодородия от потенциального, т.е. как зависит определяемая урожайность от изученных свойств почв.
Статистические методы обработки полученных результатов
Для статистической обработки таких параметров почв, как мощность гумусового горизонта, содержание гумуса, подвижных форм азота, фосфора и обменного калия, поглощенных оснований, содержания физической глины и ила, а так же выявления тенденций их изменения были использованы следующие алгоритмы:
Средняя арифметическая – х = X/n ,
где n – число значений Х
Дисперсия S2 = (Х –
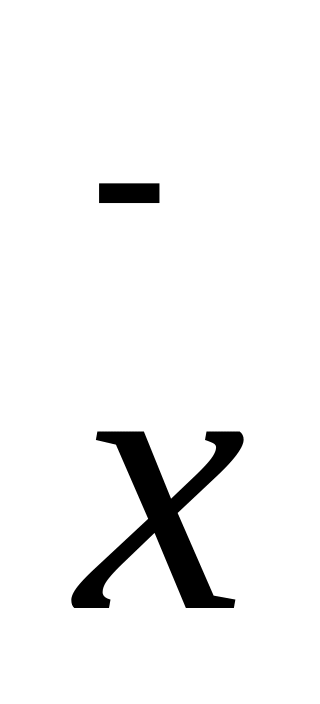 )2/n-1
)2/n-1Стандартное отклонение – S =
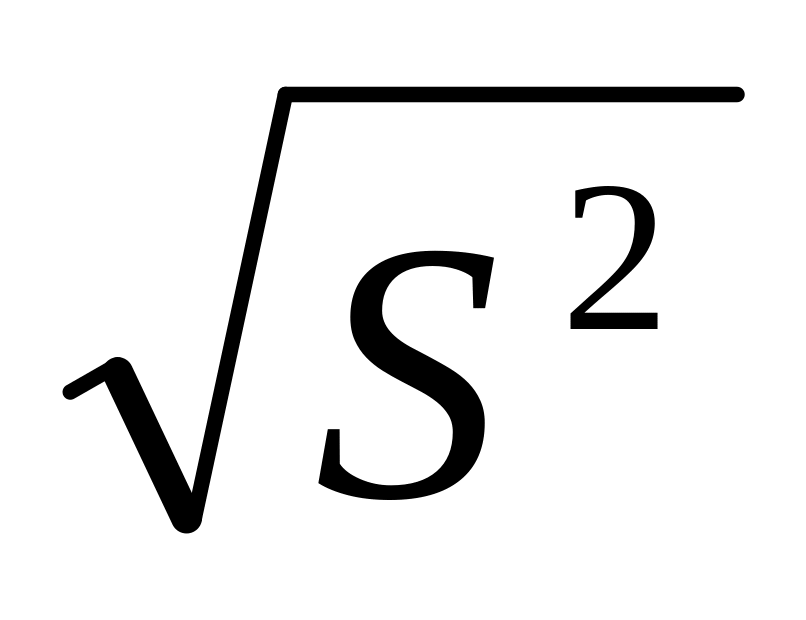 ;
;Коэффициент вариации – V = S100/X;
Ошибка средней - Sx = S/
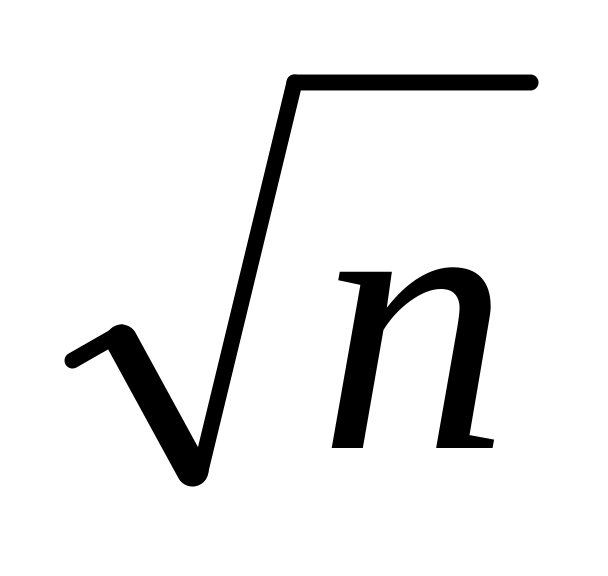 ;
(Доспехов, 1979).
;
(Доспехов, 1979).
Для установления связей между большим разнообразием показателей (экспозицией, крутизной, длинной склонов, видовым разнообразием почв, морфологическими, физическими, физико-химическими свойствами почв и урожайностью зерновых культур) использован информационно-логический анализ в модификации Ю.Т. Пузаченко, Л.О. Корпачевского, Н.А. Взнуздаева (1970). Помимо этих авторов этот анализ использовался в работах Л.М. Бурлаковой (1973). В основу данного анализа положены представления об измеримости информации, передаваемой изучаемому явлению, как от одного параметра, так и от их совокупности.
Если обозначить изучаемое явление через А, то каждое его значение можно выразить через а1, а2, …, аk или в общей форме через аi. Таким образом, если А обозначает весь набор возможных параметров, то аi обозначает отдельный ранг параметра. Не зная закономерностей изменения А, мы можем принять, что появление аi – есть случайное событие, тогда частота появления каждого ранга А= аi – есть оценка условной вероятности р(а1), р(а2)., р(аk). Вероятность аi находится по формуле р(аi)=Nai/N, где Nai – число случаев появления аi, N – общее число наблюдений. Наше суждение о появлении того или иного параметра явления в какой-то мере неопределенно. Величину этой неопределенности можно оценить количественно. Она обозначается как Н(А) = ∑р(аi)Log2р(аi), т.е. неопределенность появления разных значений А равна сумме произведений вероятности появления каждого ранга р(аi) на двоичный логарифм этой же вероятности. Если изучается зависимость явления А от фактора В мы составляем свое распределение явления А. В этом случае вероятность рангов а1, а2 ., ак в каждом ранге В обозначается через р(аi/bj). Для каждого вj можно рассчитать неопределенность Н(А/вj), которая равна ∑р(аi/bj)Log2р(аi/bj). Если между А и В есть зависимость, то Н(А) = Н(А/bj). Разность этих величин служит мерой того, насколько наше суждение об А при bj становится более определенным, чем при значении только распределения А. Эта мера обозначается как I(А/bj) и называется информацией об А, содержащейся в bj. Количество информации поступающей от В к А оценивается как ∑р(bj)I(А/bj), т.е. сумма произведения вероятности ранга bj Т(А,В). Значение Т(А,В) зависит не только от связи между А и В, но и от величины их неопределенностей. Чем больше неопределенность В, тем больше информации передается к явлению А. Для устранения влияния величины неопределенности вводится коэффициент эффективности передачи информации от фактора В к явлению А – К(А,В), который равен К(А,В)=Т(АВ)/Н(В). Наибольшее значение имеет фактор с наибольшим коэффициентом К. Таким образом, при помощи К можно установить степень влияния каждого параметра на изучаемое явление и расположить их по мере убывания коэффициента эффективности канала связи (К).