

Недостатки рекурсии
Основной недостаток рекурсии — это большое использование памяти в стеке. Рекурсия здорово ест ресурсы! При каждом вызове процедуры в стеке сохраняется адрес возврата, используемые регистры, параметры процедуры, а также может выделяться место для локальных переменных. Кроме того, на работу со стеком тратится дополнительное время, что может сделать рекурсию медленной.
К счастью, во многих случаях можно заменить рекурсию циклом. Старайтесь делать это везде, где возможно! Тот же самый факториал лучше вычислять в цикле. Сравните следующий код с рекурсивным вариантом:
; Процедура вычисления факториала в цикле
; вход: CX - число без знака
; выход: AX - результат
factorial_loop:
push bp ;Сохранение BP
mov bp,sp ;BP=SP
push cx ;Сохранение CX
mov cx,[bp+4] ;CX=параметр
xor ax,ax ;AX=0
inc ax ;AX=1
jcxz f_ret ;Если CX=0, выход из процедуры
f_lp:
mul cx ;Умножение
loop f_lp ;Команда цикла
f_ret:
pop cx ;Восстановление CX
pop bp ;Восстановление BP
ret 2 ;Возврат из процедуры
206-207.
Рассмотренные нами массивы представляют собой совокупность однотипных элементов. Но часто в приложениях возникает необходимость рассматривать некоторую совокупность данных разного типа как некоторый единый тип. Это очень актуально, например, для программ баз данных, где необходимо связывать совокупность данных разного типа с одним объектом. Особенно если база данных пишется на ассемблере :) По определению структура — это тип данных, состоящий из фиксированного числа элементов разного типа. Для использования структур в программе необходимо выполнить три действия:
Задать шаблон структуры. По смыслу это означает определение нового типа данных, который впоследствии можно использовать для определения переменных этого типа.
Определить экземпляр структуры. Этот этап подразумевает инициализацию конкретной переменной заранее определенной (с помощью шаблона) структурой.
Организовать обращение к элементам структуры.
Очень важно, чтобы вы с самого начала уяснили, в чем разница между описанием структуры в программе и ее определением. Описать структуру в программе означает лишь указать ее схему или шаблон; память при этом не выделяется. Этот шаблон можно рассматривать лишь как информацию для транслятора о расположении полей и их значении по умолчанию. Определить структуру — значит, дать указание транслятору выделить память и присвоить этой области памяти символическое имя. Описать структуру в программе можно только один раз, а определить — любое количество раз. Описание шаблона структуры Описание шаблона структуры имеет следующий синтаксис: имя_структуры STRUC <описание полей> имя_структуры ENDS Здесь <описание полей> представляет собой последовательность директив описания данных db, dw, dd, dq и dt. Их операнды определяют размер полей и, при необходимости, начальные значения. Этими значениями будут, возможно, инициализироваться соответствующие поля при определении структуры. Как мы уже отметили при описании шаблона, память не выделяется, так как это всего лишь информация для транслятора. Местоположение описания шаблона в программе может быть произвольным, но, следуя логике работы однопроходного транслятора, он должен быть расположен до того места, где определяется переменная с типом данной структуры. То есть при описании в сегменте данных переменной с типом некоторой структуры ее шаблон необходимо поместить в начале сегмента данных либо перед ним. Рассмотрим работу со структурами на примере моделирования базы данных о сотрудниках некоторого отдела. Для простоты, чтобы уйти от проблем преобразования информации при вводе, условимся, что все поля символьные. Определим структуру записи этой базы данных следующим шаблоном: ;описали шаблон стуктуры worker struc ;информация о сотруднике nam db 30 dup (' ') ;фамилия, имя, отчество sex db 'м';пол, по умолчанию 'м' - мужской position db 30 dup (' ') ;должность age db 2 dup(' ') ;возраст standing db 2 dup(' ') ;стаж salary db 4 dup(' ') ;оклад birthdate db 8 dup(' ') ;дата рождения worker ends Определение данных с типом структуры Для использования описанной с помощью шаблона структуры в программе необходимо определить переменную с типом данной структуры. Для этого используется следующая синтаксическая конструкция: [имя переменной] имя_структуры <[список значений]> Здесь:
имя переменной — идентификатор переменной данного структурного типа. Задание имени переменной необязательно. Если его не указать, будет просто выделена область памяти размером в сумму длин всех элементов структуры.
список значений — заключенный в угловые скобки список начальных значений элементов структуры, разделенных запятыми. Его задание также необязательно. Если список указан не полностью, то все поля структуры для данной переменной инициализируются значениями из шаблона, если таковые заданы. Допускается инициализация отдельных полей, но в этом случае пропущенные поля должны отделяться запятыми. Пропущенные поля будут инициализированы значениями из шаблона структуры. Если при определении новой переменной с типом данной структуры мы согласны со всеми значениями полей в ее шаблоне (то есть заданными по умолчанию), то нужно просто написать угловые скобки. К примеру: victor worker <>.
Для примера определим несколько переменных с типом описанной выше структуры. sotr1 worker <'Гурко Андрей Вячеславович',,'художник','33','15','1800','26.01.64'> sotr2 worker <'Михайлова Наталья Геннадьевна','ж','программист','30','10','1680','27.10.58'> sotr3 worker <'Степанов Юрий Лонгинович',,'художник','38','20','1750','01.01.58'> sotr4 worker <'Юрова Елена Александровна','ж','свяэист','32','2',,'09.01.66'> sotr5 worker <> ;здесь все значения по умолчанию Методы работы со структурой Идея введения структурного типа в любой язык программирования состоит в объединении разнотипных переменных в один объект. В языке должны быть средства доступа к этим переменным внутри конкретного экземпляра структуры. Для того чтобы сослаться в команде на поле некоторой структуры, используется специальный оператор — символ "." (точка). Он используется в следующей синтаксической конструкции: адресное_выражение.имя_поля_структуры Здесь:
адресное_выражение — идентификатор переменной некоторого структурного типа или выражение в скобках указывающее на ее адрес
имя_поля_структуры — имя поля из шаблона структуры. Это, на самом деле, тоже адрес, а точнее, смещение поля от начала структуры.
Теперь
примерчик...
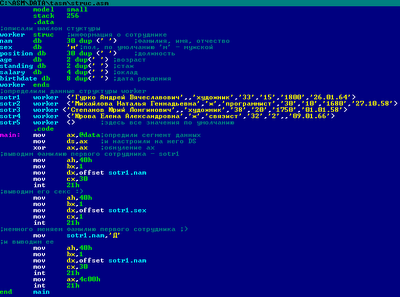 Эта
программа уже выводит на экран информацию
о первом сотруднике. Запускаем,
анализируем, просветляемся...
Давайте
представим, что сотрудников не четверо,
а намного больше, и к тому же их число и
информация о них постоянно меняются. В
этом случае теряется смысл явного
определения переменных с типом worker для
конкретных личностей.
Язык ассемблера
разрешает определять не только отдельную
переменную с типом структуры, но и массив
структур.
К примеру, определим массив
из 10 структур типа worker:
mas_sotr worker
10 dup (<>)
Дальнейшая работа с
массивом структур производится так же,
как и с одномерным массивом. Здесь
возникает несколько вопросов:
Как
быть с размером и как организовать
индексацию элементов массива?
Аналогично
другим идентификаторам, определенным
в программе, транслятор назначает имени
типа структуры и имени переменной с
типом структуры атрибут типа. Значением
этого атрибута является размер в байтах,
занимаемый полями этой структуры.
Извлечь это значение можно с помощью
оператор type.
После того как стал
известен размер экземпляра структуры,
организовать индексацию в массиве
структур не представляет особой
сложности.
К примеру, программа
выводит на экран содержимое поля sex всех
структур worker в массиве mas_sotr:
Эта
программа уже выводит на экран информацию
о первом сотруднике. Запускаем,
анализируем, просветляемся...
Давайте
представим, что сотрудников не четверо,
а намного больше, и к тому же их число и
информация о них постоянно меняются. В
этом случае теряется смысл явного
определения переменных с типом worker для
конкретных личностей.
Язык ассемблера
разрешает определять не только отдельную
переменную с типом структуры, но и массив
структур.
К примеру, определим массив
из 10 структур типа worker:
mas_sotr worker
10 dup (<>)
Дальнейшая работа с
массивом структур производится так же,
как и с одномерным массивом. Здесь
возникает несколько вопросов:
Как
быть с размером и как организовать
индексацию элементов массива?
Аналогично
другим идентификаторам, определенным
в программе, транслятор назначает имени
типа структуры и имени переменной с
типом структуры атрибут типа. Значением
этого атрибута является размер в байтах,
занимаемый полями этой структуры.
Извлечь это значение можно с помощью
оператор type.
После того как стал
известен размер экземпляра структуры,
организовать индексацию в массиве
структур не представляет особой
сложности.
К примеру, программа
выводит на экран содержимое поля sex всех
структур worker в массиве mas_sotr:
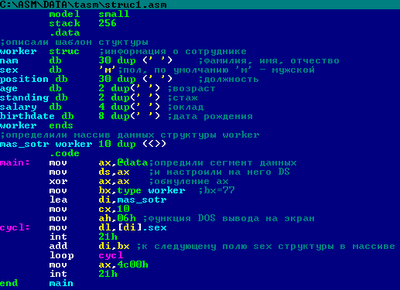
208.
юбопытный читатель к этому занятию, вероятно, попытался самостоятельно написать хотя бы несколько программ на ассемблере. Скорее всего, эти программы были предназначены для решения небольших, чисто исследовательских задач, но даже на примере этих маленьких по объему программ вам, наверное, стали очевидны некоторые из перечисленных здесь проблем:
плохое понимание исходного текста программы, особенно по прошествии некоторого времени после ее написания;
ограниченность набора команд;
повторяемость некоторых идентичных или незначительно отличающихся участков программы;
необходимость включения в каждую программу участков кода, которые уже были использованы в других программах;
и многое другое
Если бы мы писали программу на машинном языке, то данные проблемы были бы принципиально не решаемыми. Но язык ассемблера, являясь символическим аналогом машинного языка, предоставляет для их решения ряд средств. Основной целью, которая при этом преследуется, является повышение удобства написания программ. В общем случае эта цель достигается по нескольким направлениям за счет следующего:
расширения набора директив;
введения некоторых дополнительных команд, не имеющих аналогов в системе команд микропроцессора. За примером далеко ходить не нужно — команды setfield и getfield, которые скрывают от программиста рутинные действия и генерируют наиболее эффективный код;
введения сложных типов данных.
Но это все глобальные направления, по которым развивается сам транслятор от версии к версии. Что же делать программисту для решения его локальной задачи, для облегчения работы в определенной проблемной области? Для этого разработчики компиляторов ассемблера включают в язык и постоянно совершенствуют аппарат макросредств. Этот аппарат является очень мощным и важным.
В общем случае есть смысл говорить о том, что транслятор ассемблера состоит из двух частей — непосредственно транслятора, формирующего объектный модуль, и макроассемблера (рис. 1).

Рис. 1. Макроассемблер в общей схеме трансляции программы на TASM
Если вы знакомы с языком С или С++, то конечно помните широко применяемый в них механизм препроцессорной обработки. Он является некоторым аналогом механизма заложенного в работу макроассемблера. Для тех, кто ничего раньше не слышал об этих механизмах, поясню их суть. Основная идея — использование подстановок, которые замещают определенным образом организованную символьную последовательность другой символьной последовательностью. Создаваемая таким образом последовательность может быть как последовательностью, описывающей данные, так и последовательностью программных кодов. Главное здесь то, что на входе макроассемблера может быть текст программы весьма далекий по виду от программы на языке ассемблера, а на выходе обязательно будет текст на чистом ассемблере, содержащем символические аналоги команд системы машинных команд микропроцессора.
Таким образом, обработка программы на ассемблере с использованием макросредств неявно осуществляется транслятором в две фазы(рис. 1). На первой фазе работает часть компилятора, называемая макроассемблером, функции которого на идейном уровне мы описали чуть выше. На второй фазе трансляции работает непосредственно ассемблер, задачей которого является формирование объектного кода, содержащего текст исходной программы в машинном виде.
Далее мы обсудим основной набор макросредств, доступных при использовании компилятора TASM. Отметим, что большинство этих средств доступно и в компиляторе с языка ассемблера фирмы Microsoft. Обсуждение начнем с простейших средств и закончим более сложными.
Псевдооператоры equ и =
К простейшим макросредствам языка ассемблера можно отнести псевдооператоры equ и "=" (равно). Их мы уже неоднократно использовали при написании программ. Эти псевдооператоры предназначены для присвоения некоторому выражению символического имени или идентификатора. Впоследствии, когда в ходе трансляции этот идентификатор встретится в теле программы, макроассемблер подставит вместо него соответствующее выражение. В качестве выражения могут быть использованы константы, имена меток, символические имена и строки в апострофах. После присвоения этим конструкциям символического имени его можно использовать везде, где требуется размещение данной конструкции.
Синтаксис псевдооператора equ:
имя_идентификатора equ строка или числовое_выражение |
Синтаксис псевдооператора “=”:
имя_идентификатора = числовое_выражение |
Несмотря на внешнее и функциональное сходство псевдооператоры equ и “=” отличаются следующим:
из синтаксического описания видно, что с помощью equ идентификатору можно ставить в соответствие как числовые выражения, так и текстовые строки, а псевдооператор “=” может использоваться только с числовыми выражениями;
идентификаторы, определенные с помощью “=”, можно переопределять в исходном тексте программы, а определенные с использованием equ — нельзя.
Ассемблер всегда пытается вычислить значение строки, воспринимая ее как выражение. Для того чтобы строка воспринималась именно как текстовая, необходимо заключить ее в угловые скобки: <строка>. Кстати сказать, угловые скобки являются оператором ассемблера, с помощью которого транслятору сообщается, что заключенная в них строка должна трактоваться как текст, даже если в нее входят служебные слова ассемблера или операторы. Хотя в режиме Ideal это не обязательно, так как строка для equв нем всегда трактуется как текстовая.
Псевдооператор equ удобно использовать для настройки программы на конкретные условия выполнения, замены сложных в обозначении объектов, многократно используемых в программе, более простыми именами и т. п. К примеру:
masm model small stack 256 ;размерность массива mas_size equ 10 ;переименовать регистр akk equ ax ;адресовать элемент массива mas_elem equ mas[bx][si] .data ;описание массива из 10 байт: mas db mas_size dup (0) .code mov akk,@data ;фактически mov ax,@data mov ds,akk ;фактически mov ds,ax ... mov al,mas_elem ;фактически — mov al,mas[bx][si] |
Псевдооператор “=” удобно использовать для определения простых абсолютных (то есть не зависящих от места загрузки программы в память) математических выражений. Главное условие то, чтобы транслятор мог вычислить эти выражения во время трансляции. К примеру:
.data adr1 db 5 dup (0) adr2 dw 0 len = 43 len = len+1 ;можно и так, через предыдущее определение len = adr2-adr1 |
Как видно из примера, в правой части псевдооператора “=” можно использовать метки и ссылки на адреса — главное, чтобы в итоге получилось абсолютное выражение.
Компилятор TASM, начиная с версии 3.00, содержит директивы, значительно расширяющие его возможности по работе с текстовыми макросами. Эти директивы аналогичны некоторым функциям обработки строк в языках высокого уровня. Под строками здесь понимается текст, описанный с помощью псевдооператора equ.
Набор этих директив следующий:
директива слияния строк catstr: идентификатор catstr строка_1,строка_2,... — значением этого макроса будет новая строка, состоящая из сцепленной слева направо последовательности строк строка_1,строка_2,... В качестве сцепляемых строк могут быть указаны имена ранее определенных макросов. К примеру:
pre equ Привет,
name equ < Юля>
privet catstr pre,name ;privet= “Привет, Юля”
директива выделения подстроки в строке substr: идентификатор substr строка,номер_позиции,размер — значением данного макроса будет часть заданной строки, начинающаяся с позиции с номером номер_позиции и длиной, указанной в размер. Если требуется только остаток строки, начиная с некоторой позиции, то достаточно указать только номер_позиции без указания размера. К примеру:
;продолжение предыдущего фрагмента:
privet catstr pre,name ;privet= “Привет, Юля”
name substr privet,7,3 ;name=“Юля”
директива определения вхождения одной строки в другую instr: идентификатор instr номер_нач_позиции,строка_1,строка_2 — после обработки данного макроса транслятором идентификатору будет присвоено числовое значение, соответствующее номеру (первой) позиции, с которой совпадают строка_1 и строка_2. Если такого совпадения нет, то идентификатор получит значение 0;
директива определения длины строки в текстовом макросе sizestr: идентификатор sizestr строка — в результате обработки данного макроса значение идентификатор устанавливается равным длине строки.
-
;как продолжение предыдущего фрагмента:
privet catstr pre,name ;privet= “Привет, Юля”
len sizestr privet ;len=10
Эти директивы очень удобно использовать при разработке макрокоманд, которые являются следующим макросредством, предоставляемым компилятором ассемблера.
209.
Макрооператор & (амперсанд) нужен для того, чтобы параметр, переданный в качестве операнда макроопределению или блоку повторений, заменялся значением до обработки строки ассемблером. Так, например, следующий макрос выполнит команду PUSH EAX, если его вызвать как PUSHREG A:
pushreg macro letter
push e&letter&x
endm
Иногда можно использовать только один амперсанд — в начале параметра, если не возникает неоднозначностей. Например, если передается номер, а требуется создать набор переменных с именами, оканчивающимися этим номером:
irp number,<1,2,3,4>
msg&number db ?
endm
Макрооператор <> (угловые скобки) действует так, что весь текст, заключенный в эти скобки, рассматривается как текстовая строка, даже если он содержит пробелы или другие разделители. Как мы уже видели, этот макрооператор используется при передаче текстовых строк в качестве параметров для макросов. Другое частое применение угловых скобок — передача списка параметров вложенному макроопределению или блоку повторений.
Макрооператор ! (восклицательный знак) используется аналогично угловым скобкам, но действует только на один следующий символ, так что, если этот символ — запятая или угловая скобка, он все равно будет передан макросу как часть параметра.
Макрооператор % (процент) указывает, что находящийся за ним текст является выражением и должен быть вычислен. Обычно это требуется для того, чтобы передавать в качестве параметра в макрос не само выражение, а его результат.
Макрооператор ;; (две точки с запятой) — начало макрокомментария. В отличие от обычных комментариев текст макрокомментария не попадает в листинг и в текст программы при подстановке макроса. Это сэкономит память при ассемблировании программы с большим количеством макроопределений.
210-211.
Отличительной особенность FASM является очень гибкая и мощная поддержка макросов. В этой статье мы рассмотрим лишь основы создания макросов, так как эта тема довольно обширна и рассказать всё в одной статье не получится.
Что же такое макросы? Макросы — это шаблоны для генерации кода. Один раз создав макрос, мы можем использовать его во многих местах в коде программы. Макросы делают процесс программирования на ассемблере более приятным и простым, а код программы получается понятнее. Макросы позволяют расширять синтаксис ассемблера и даже добавлять собственные «команды», которых нет в процессоре.
Обработкой макросов занимается препроцессор FASM. Преобразование исходного кода в исполняемый код FASM выполняет в два этапа. Первый этап — препроцессирование, а второй — собственноассемблирование или компиляция. На первом этапе происходит вычисление всех числовых выражений, вместо констант и названий меток подставляются их фактические значения, вместо макросов подставляется сгенерированный код. На втором этапе все данные и машинные команды преобразуются в соответствующие байты, и в результате получается исполняемый файл требуемого формата.