

3.1 Блочное кодирование
Входная информация при блочном кодировании разделяется на блоки, содержащие по k символов каждый, которые по определенному закону преобразуются кодером в n-символьные блоки, причем выбирается n>k.
Отношение кодирующих символов R = k/n носит название скорости кодирования – coding rate. Величина R<1 является мерой избыточности, вносимой кодером.
Обычно блочный кодер с параметрами k, n обозначается (n,k), где первым символом n – обозначают число символов в выходном блоке кодера, а k – число символов во входном блоке. В системах сотовой связи используются двоичные символы входной и выходной последовательностей (двоичные кодеры).
Пример двоичного блочного кодера [n=5, k=4, R = k/n = 0,8].
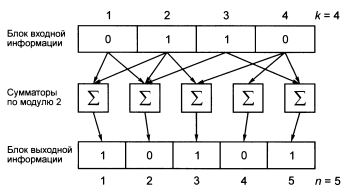
Рисунок 14 - Двоичный блочный кодер (5,4)
Каждый бит блока выходной информации (на выходе сумматоров по модулю 2) получается как сумма по модулю 2 нескольких бит (от одного до k) выходного блока, для чего используется n сумматоров по модулю 2, алгоритм которых приведен в след таблице 1:
Таблица 1 - Алгоритм работы блочного кодера (5,4)

Следует отметить, что один из сумматоров (второй справа) является вырожденным, т.к. на его вход поступает лишь одно слагаемое. Как видно из рисунка 14, и следующего рисунка:
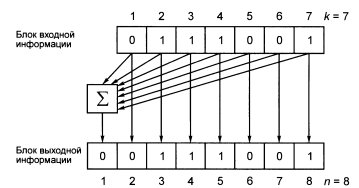
Рисунок 15 - Систематический блочный кодер
отличительной особенностью систематического кодера является то, что в состав блока выходной информации включается блок входной информации. Простейший систематический блочный кодер (рисунок 15) реализует операцию кодирования, состоящую в том, что на выход, кроме копии входного, поступает лишь один избыточный бит, который является суммой по модулю 2 всех бит входного блока.
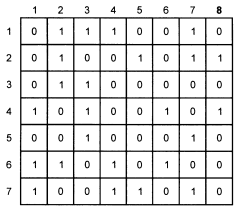
Рисунок 16 - Побайтовый контроль четности
Этот избыточный бит называется кодом контроля четности, т.к. число символов в выходном блоке, с учетом контрольного бита, четное n = 8. Для 8-битового блока двоичной информации рисунок 16, может быть назван схемой побайтного контроля четности. Используя схему 16, имеется возможность обнаружить ошибку при помощи блочного кода, а затем – возможность ее исправить.
3.2 Сверточное кодирование
При сверточном кодировании величина k последовательных символов (K = 5 в след. примере) входной информационной последовательности по k=2 бит в каждом символе участвует в образовании n-битовых (n=4) символов выходной последовательности при n>k, причем каждый символ входной последовательности приходится по одному символу выходной последовательности (рисунок 17).
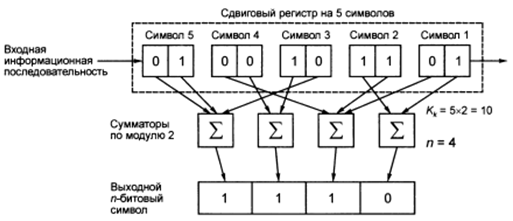
Рисунок 17 - Схема сверточного кодера (4,2,5)
Каждый бит выходной последовательности получается как результат суммирования по модулю 2 (от двух до Kk бит, т.е. от 2 до 5х2 = 10 бит) K (K=5) входных символов, для чего используется n (n=4) сумматоров по модулю 2.
Для данной схемы (рисунок 17) – сверточного кодера типа (n,k,K), где параметры кодера: n – число сумматоров по модулю 2, число бит выходной последовательности: n=4; k – число бит в каждом символе входной информационной последовательности: k=2; K – число символов входной информационной последовательности или длина ограничения.
Параметр K определяет длину сдвигового регистра (в символах), содержимое которого участвует в формировании одного выходного символа (сдвиговый регистр на 5 символов), вид кодера запишется (4,2,5) = (n,k,K), при скорости кодирования R = k/n = 2/4 = 0,5. Следует отметить, что после того, как очередной выходной символ сформирован (например, на рисунке 17 сформирован первый n=4 битовый символ), входная последовательность из состояния K(0,1) = 5, K(0,0) = 4, K(0,1) = 3, K(1,1) = 2, K(0,1) = 1 сдвигается на один символ вправо, т.е. вместо K = 5 имеем K(0,1) = 4, и т.д., в результате чего символ K(0,1) = 1 выходит за пределы регистра.
Символы 2…5 далее перемещаются вправо, каждый на место соседнего, в результате чего по каждому шагу смещения символов входной информационной последовательности формируется новый выходной n-битовый символ, т.е. в данном случае 10-битовая входная информационная последовательность «сворачивается» в 4-битовую выходную последовательность, а из 5 входных символов (по 2 бита в каждом) формируется один выходной n = 4-битовый символ.
Если число бит в символах сдвигового регистра входной информационной последовательности k = 1, т.е. символы однобитовые (а не двухбитовые, как в данном примере), то такой кодер называется двоичным.