

Пример №2.
В ходе работы по созданию различных предприятий регулярно приходится решать проблемы обоснования их организационно – штатной структуры: численности персонала, создания рабочих мест, порядка работы. Как правило, это делается «на глазок». В статье рассматриваются вопросы имитационного моделирования с использованием программного средства Arena 9.0 фирмы Rockwell Software на примере работы центра страхования автогражданской ответственности. Указанная модель является условной и отражает реальные процессы только в той мере, в какой это необходимо для иллюстрации возможностей средства Arena.
Основными этапами моделирования являются:
Сбор информации и подготовка исходных данных
Построение модели
Проведение расчетов на модели
Сбор информации и подготовка исходных данных
На этом этапе была обследована работа сотрудников страховой фирмы, определены функции персонала, нормативы их работы. Выполнен прогноз возможных входных потоков.
Обследование показало, что основными процессами системы являются следующие:
Страхование
прием заявлений на страхование, продление срока, досрочное прекращение;
проверка документов и автотранспорта;
оформление страхового полиса;
прием оплаты;
выдача страхового полиса;
консультации.
страховые выплаты:
прием заявлений на выплаты;
рассмотрение документов;
осмотр автотранспорта, имущества;
подготовка акта;
утверждение акта;
проведение страховых выплат.
В качестве объектов системы страхования были приняты:
руководитель – утверждает документы;
группа страхования - заключает договоры страхования;
группа выплат - оформляет страховые выплаты;
кассир – принимает и выплачивает деньги.
Среднее количество входных заявок, определенное в ходе обследования, приведено в таблице 1, а нормативы в таблице 2.
Таблица 1
Наименование документа |
Количество заявлений в сутки |
Интервал времени поступления, минуты |
||
лично |
по почте |
лично |
по почте |
|
Заявление и документы на страхование |
40 |
- |
20 |
- |
Вопросы |
10 |
- |
80 |
- |
Заявление и документы на выплаты |
4 |
0,4 |
2 |
20 |
Таблица 2
Вид работы |
Сотрудники |
Время выполнения работы, мин |
|||
Должность |
Кол-во |
Мин. |
Сред. |
Макс. |
|
Консультация |
Страховщик |
4 |
30 |
50 |
70 |
Оформление документов |
15 |
20 |
25 |
||
Выдача страхового полиса |
10 |
20 |
30 |
||
Прием документов на выплаты |
Инспектор |
1 |
10 |
15 |
20 |
Осмотр автотранспорта |
70 |
75 |
80 |
||
Рассмотрение документов, подготовка акта |
30 |
40 |
50 |
||
Утверждение акта |
Начальник |
1 |
50 |
60 |
70 |
Прием оплаты |
Кассир |
1 |
20 |
25 |
30 |
Выплаты |
20 |
25 |
30 |
||
2. ПОСТРОЕНИЕ МОДЕЛИ
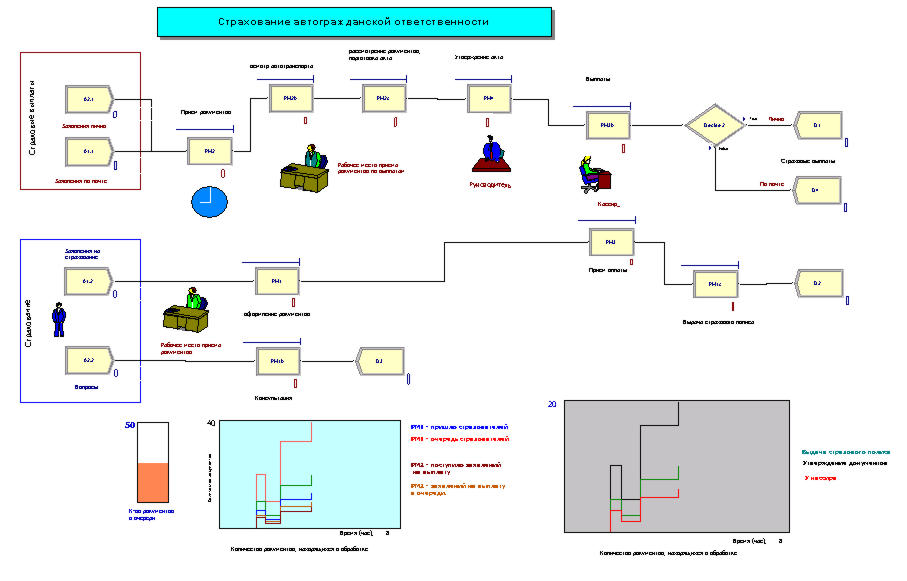
Построение модели начинается с создания схемы модели. Исходные данные для процесса страхования определяются с помощью блоков генерации исходных данных (Create). Источником данных являются страхователи, которые приносят «Заявления на страхование» (блок А1.2) или задают «Вопросы» (блок А2.2). Они подаются страховщикам, которые находятся на рабочих местах приема документов.
Выполнение работ отображается блоками процессов в виде прямоугольников. По каждому процессу можно задать закон распределения производительности, используемые ресурсы и другие показатели. По заявлениям страховщик выполняет «оформление документов» (РМ1), а по вопросам дает «консультации» (РМ1b). Консультации являются, по сути, выходными данными, а их результаты собираются в выходном блоке D3 (Dispose). Эта часть схемы отражена на рис.1.
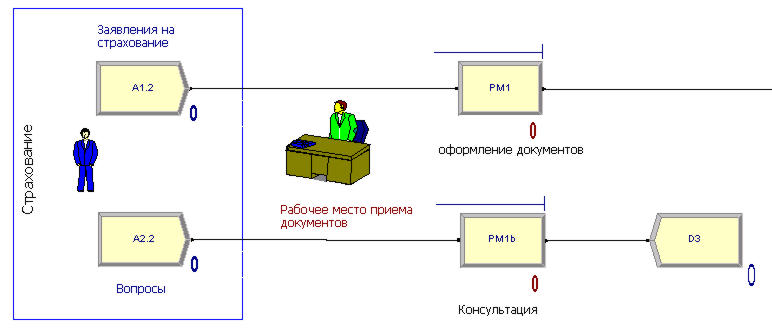
Дополним схему рисунком, который при проигрывании модели будет отражать состояние занятости страховщика: рис. 2а – когда он свободен, рис. 2b - когда он занят.
Рис. 2а
Рис. 2b
Аналогичным образом построим схему для процесса страховых выплат (рис. 3).
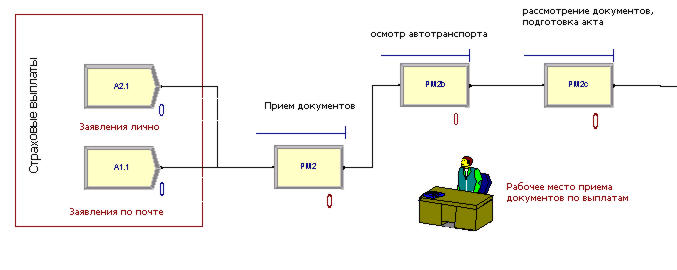
Заявления на выплаты могут поступать лично или высылаться по почте. Сотрудник группы выплат принимает документы, проводит осмотр автотранспорта, выполняет проверку материалов и подготавливает акт.
На завершающем участке схемы (Рис.4) отразим: утверждение актов на выплаты руководителем центра (РМ4), работу кассира по выплате страховки (РМ3b) и приему страховых премий (РМ3), выдачу страховых полисов в группе страхования (РМ1с).
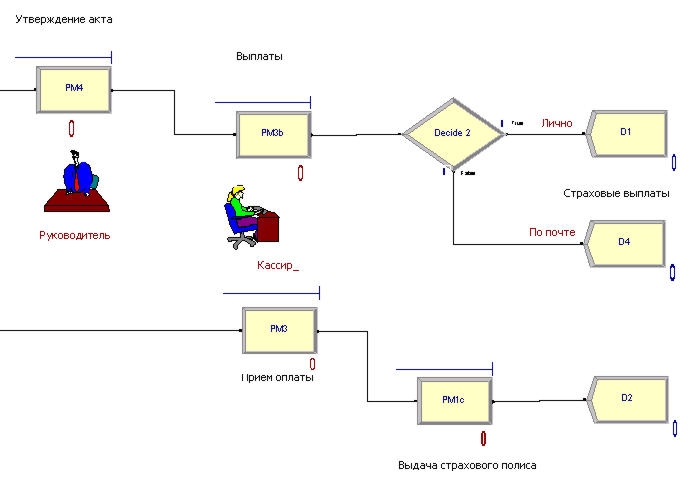
Для руководителя создадим расписание работы по утверждению документов - 1 час в конце рабочего дня (рис. 5).
Для документов, полученных лично, выплаты осуществляются непосредственно из кассы, а для документов, полученных по почте, отправляются почтовыми переводами. Чтобы отразить этот факт введем блок решения (Decide2), который будет распределять документы по разным выходным блокам в зависимости от способа их получения. Такие блоки могут, при необходимости, быть не только двух-, а и многопоточными.
В результате наша схема в целом будет иметь вид, отображенный на рис. 6. В ней также созданы макеты диаграмм, которые будут отражать динамику поступления документов и очереди на различных рабочих местах.
3. ПРОВЕДЕНИЕ РАСЧЕТОВ НА МОДЕЛИ
Для определения примерной численности персонала проведем несложный расчет.
В соответствии с принятыми исходными данными в группу страхования за одни сутки поступает 40 заявлений и 10 вопросов. Исходя из этого, требуемые трудозатраты составят:
40 х (0.75+0.08) + 10 х 0.25 = 35,7 чел-час
Если состав группы определить в 4 человека, то получим следующий коэффициент выполнения работ:
4 чел х 8 час = 32 чел-час. Коэф. выполнения работ = 0.9. То есть, таким составом работа в основном выполняется.
Проведем теперь расчеты на модели с учетом следующих организационных положений и нормативов:
рабочий день - 8 часов;
почта поступает 1 раз в сутки в 11 часов;
интервал времени между приходом заявителей распределяется по экспоненциальному закону;
время выполнения работ распределяется по треугольному закону.
При моделировании для 10 репликаций получим следующие результаты.
За день поступает в среднем 41 заявление, 11 вопросов и 6 заявлений на выплаты (из них 2 - по почте). Сотрудники оформляют 22 полиса, проводят 9 консультаций и 5 страховых выплат. В результате в группе страхования накапливается очередь 4 человека на оформление полисов и 3 человека на их получение. На страховые выплаты и в кассе очередей практически нет. В результате, коэффициент выполнения работ по оформлению полисов составляет 0,6. Среднее время ожидания в очереди на оформление полиса составляет – 2,7-4,4 час. А среднее время на оформление, - 1,3 - 1,6 час. Безусловно, такие показатели работы являются неприемлемыми. В реальной жизни заявители просто не будут так долго стоять в очереди, а просто уйдут. Получается, что ручной расчет является неточным и вводит нас в заблуждение. Это обусловлено тем, что он не учитывает вероятной неравномерности нагрузки, которая является случайной по своей природе.
Динамика поступления документов и очередей заявителей отражена на рис. 7,8.

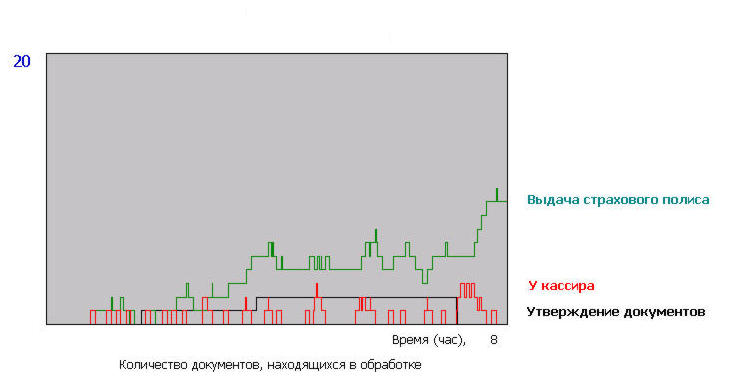
При отладке можно запустить модель в нужном темпе и посмотреть анимацию движения документов и работы персонала.
Теперь определим в состав группы страхования 6 человек. В результате получим следующее.
При том же объеме поступлений оформляется уже 35 полисов, проводится 11 консультаций и 5 страховых выплат. В группе страхования очередь составит теперь в среднем 0,4 человека на оформление полисов и 0,5 человека на их получение. Коэффициент выполнения работ по оформлению полисов - 0,87. Среднее время ожидания в очереди на оформление полиса составляет – 0,05 - 0,36 час, а время на оформление, - 1,3 - 1,6 час. Можно оценить и степень занятости персонала, которая будет для группы страхования - 0,75, группы выплат – 0,6, кассира – 0,4, руководителя – 0,0003 (конечно, только по утверждению документов, т.к. другие обязанности мы не рассматриваем). Такая численность представляется более приемлемой, чем предложенная первоначально.
При необходимости можно по заданному шаблону сформировать отчеты в формате MS Word, Excel по целому ряду показателей, например, таких как: время обработки документов на каждом рабочем месте, общее время выполнения работ, объемы входных и выходных потоков документов, количество документов в очереди и время ожидания на каждом рабочем месте, степень использования и занятости персонала и ресурсов. Результаты могут быть получены как среднее, минимальное и максимальное значение по итогам всех испытаний, а также по каждому испытанию отдельно.
Дальнейшие этапы в данной статье не рассматриваются, поскольку они выходят за рамки предмета обсуждения.
ОПИСАНИЕ НАСТРОЕК БЛОКОВ МОДЕЛИ
Начнем с описания объектов модели. Для этого откроем в навигаторе раздел Basic Process, щелкнем на Entity и заполним предлагаемую таблицу.

Создадим следующие типы объектов: Inform query - вопросы (информационный запрос); Registration Docs - Заявление на страхование; Declaration post - Заявление на возмещение, высланное по почте; Declaration person - Заявление на возмещение, поданное лично.
Следует отметить, что названия объектов должны быть записаны латинским шрифтом. Русский она не понимает. Но текстовые надписи на схеме можно делать русскими.
Зададим Начальную картинку для каждой сущности. Она задается описанием, которое можно выбрать из типового ниспадающего списка. При запуске модели, в ходе анимации, эти картинки будут отображать прохождение объектов по нашей модели. Например, вопросы будут выглядеть как желтые листочки, заявления, как синие.
Далее следуют стоимостные характеристики, которые в нашей модели не рассматриваются. Лично мне они непонятны и требуют специального изучения.
2. Создадим используемые ресурсы. Для этого откроем в навигаторе раздел Basic Process, щелкнем на Resource и заполним следующую таблицу.
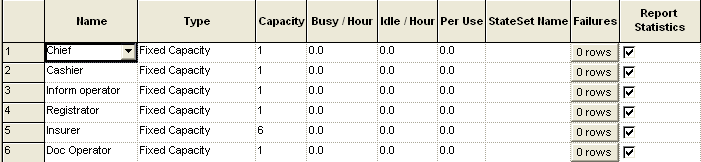
Name - имя ресурса. Ресурсами у нас будут должностные лица: Chief - руководитель; Cashier - кассир; Inform operator - оператор справочной; Registrator - регистратор; Insurer - страхователь; Doc Operator - оператор работы с документами.
Type - зададим тип путем выбора из ниспадающего списка одного из двух: фиксированное количество (Fixed Capacity) или может меняться по расписанию (Based on Schedule). Всех служащих мы сделаем фиксированными, а начальник будет работать по расписанию. Это значит, что он будет подписывать документы в определенное время (1 час в конце рабочего дня), а служащие будут заняты постоянно. Остальные его дела находятся вне рамок нашей модели.
Capacity - количество. Зададим его.
3. Создадим расписания. Для этого откроем в навигаторе раздел Basic Process, щелкнем на Schedule и заполним следующую таблицу.

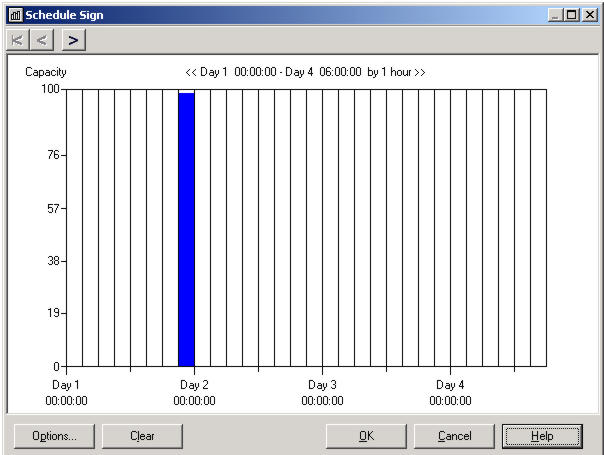
- Schedule Sign - расписание для подписи документов начальником. Format Type (Тип формата) - Duration (отрезок времени). Type (тип) - Capacity (количество). Задается для блока процесса. Scale Factor - масштабный множитель зададим равный 1. Durations (продолжительность) определяет график расписания. Если в этой ячейке щелкнуть дважды, то появится окно для создания графика. Для задания установок нажимаем кнопку Options. Там устанавливаем шаг по шкале Х (Time slot duration) равный 1 часу. Получится всего 8 шагов в сутки, т.к. в модели установлен 8-ми часовой рабочий день (Run - Setup - Replication Parameters - Hours Per Day = 8). Задаем интервал (Range) равным 30 временных шагов. Это означает, что на диаграмме будет отображаться 30 делений. Скорость движения календаря (Calendar speed) устанавливаем равной 1 шаг на клик (slots per click). Это означает, что при нажатии кнопки " > " календарь будет сдвигаться на одно деление. По оси Y задаем максимальное количество подписей, которое может сделать начальник за отведенный на это час, равное 100. Минимальное - 0. Когда расписание заканчивается (When at end of Schedule) оно должно начаться сначала (Repeat from beginning). На графике расписания щелкаем мышью внутри нужного отрезка времени и протягиваем до необходимого значения. Установим его равным 100. Можно было бы сделать подпись документов два раза в день по 0,5 часа. Тогда необходимо сделать шаг равным 0,5 часа, а значения в графике два раза по 50. Если щелкнуть правой кнопкой мыши в позиции Durations, то возникнет контекстное меню, из которого можно редактировать расписание через диалог или дополнительную таблицу значений.
- Schedule Post - расписание доставки почты. Для него тип будет Arrival (поступление). Он задается для блока инициирования.
Теперь приступим к созданию модели.
4. Сначала создадим блок инициирования (Create), который будет генерировать начальные события. Для этого перетянем пиктограмму Create из навигатора в поле модели. Щелкнув на нем заполним размещенную внизу таблицу. То же самое можно сделать щелкнув два раза на блоке и заполнив возникшее окно.

Name - имя блока: A1.2. Это будет генератор потока заявлений на страхование. Entity Type - Тип сущности выберем из ниспадающего списка уже созданных: Registration Docs - Заявление на страхование. Type - Random (Expo), т.е. распределение потока событий подачи заявлений будет определяться экспоненциальным законом. Его мы выберем из ниспадающего списка. Интенсивность поступления заявлений примем 0,2 ед. в час. Entities per Arrival - количество объектов, которые будут поступать в момент одного события равно 1. Это значит, что в каждом конверте (или у каждого заявителя) будет одно заявление. Теоретически может быть и по другому. Например, каждый заявитель может приносить несколько заявлений, скажем, по всем машинам своей фирмы.
Блок A2.2 будет определять поток вопросов (Inform query). Распределение потока будет также определяться экспоненциальным законом с характеристиками 0,8 вопроса в час.
Блок A1.1 будет определять поток заявлений на выплату страхового возмещения, поданных по почте. Тип сущности выберем из ниспадающего списка уже созданных: Declaration post. Type - Schedule (Расписание). То есть, почта будет приходить по расписанию, которое мы уже создали: Schedule Post. Entities per Arrival - количество объектов, которые будут поступать в каждый приход почтальона, равно 0,4. Это значит, что интенсивность поступления почты будет 0,4 заявления при каждой доставке. Реально это означает, что заявления почтальон будет приносить не всегда. За 10 приходов он будет приносить в среднем 4 заявления. В ходе моделирования это будут случайные события.
5. Далее создадим блок процесса "Оформление документов". Для этого перетянем пиктограмму прямоугольника (Process) из навигатора в поле модели. Щелкнув на нем заполним размещенную внизу таблицу.

Name - имя процесса: PM1. Имя здесь означает, что он будет выполнять функции оформления документов на рабочем месте № 1.
Type - тип процесса выбираем из ниспадающего списка. Он может быть стандартный (Standard) или представлять субмодель (Submodel). Субмодель позволяет внутри него разместить вложенную модель. В нашей модели мы ограничимся стандартными процессами.
Action - действие (операция). Возможны следующие виды действий: Delay - задержка, ресурсов не требует, а просто процесс длится определенное время. Seize Delay - сцепленная задержка: ресурс используется определенное время, а после использования не освобождается. Seize Delay Release - ресурс используется, а после использования освобождается. Для нашего процесса оформления документов выберем Seize Delay Release, поскольку ресурсом будет страхователь (Insurer), и он после использования освобождается (в отличие, например, от бутерброда, который повторно использовать невозможно).
Priority - приоритет, выберем средний (Medium(2)). Смысл выбора приоритета заключается в том, что если ресурс назначен для использования в нескольких процессах, то очередность его применения будет определяться приоритетом.
Resources - используемые ресурсы. Если два раза кликнуть на процессе, то возникнет окно свойств, в котором можно добавлять ресурсы. Добавим (add) из ранее созданного перечня страхователя (Insurer). В принципе на один процесс можно добавлять много ресурсов, но мы ограничимся одним (1 rows).
Delay Type - тип задержки. Будем считать, что задержка (т.е. время выполнения процесса с одним объектом - заявление) определяется треугольным законом с характеристиками: Min = 0,5; Value = 0, 75; Max = 1. На русском языке это означает, что время оформления документов случайным образом будет меняться от 0,5 до 1 часа. Вообще, выбор закона распределения случайной величины тема для отдельного разговора и относится больше к теории вероятностей. Поэтому, будем считать, что читателям известны ее основы. Arena предоставляет возможность выбора наиболее употребительных законов: нормального, треугольного, равномерного, экспоненциального и целого ряда других.
Allocation - распределение. Определяет, как время и стоимость процесса будут относиться к сущности. Возможно: Value added - добавляющие стоимость; Non-Value added - не добавляющие; Transfer - передаваемые. Не очень понятно, да?
Аналогичным образом создадим и опишем остальные процессы согласно схеме.
Для того чтобы связать блоки между собой используем Связь (Connection). Задать ее можно двумя способами. 1) Нажимаем кнопку Connect в верхней панели (или выбираем в меню Object - Connect) и проводим связь от одной точки привязки блока к точке другого. 2) Можно делать это автоматически при создании блока. Для этого выделим уже существующий (исходящий) блок. Тогда при перетаскивании из навигатора нового блока между ними автоматически образуется связь.
6. Проиллюстрируем создание и использование блока принятия решений (Decide)
Необходимость в блоке принятия решений возникает, когда потоки объектов разделяются. В нашем случае необходимо разделить ответы на заявления, поданные лично и пришедшие по почте. Блок Decide2 на нашей схеме будет определять каким образом мы будем передавать заявителю документы: пересылать по почте или выдавать лично. Эти характеристики задаются в таблице.
Name |
Type |
If |
Entity Type |
Decide2 |
2-way by Condition |
Entity Type |
Declaration person |
Выбираем тип блока 2-way by Condition. Это означает, что на выходе блока будут две ветви, а потоки будут распределяться по условию. Условие определяет, что если типом сущности (Entity Type) будет Личное Заявление на возмещение (Declaration person), то оно пойдет по ветке "да" (True). Значит Заявление по почте пойдет в другую ветвь (False).
Другими вариантами разветвлений могут быть: N-way by Condition - N-ветвей по условию; 2-way by Chance - две ветви случайно, т.е. надо указать процент случайного распределения; N-way by Chance - N-ветвей случайно.
7. Выходной блок (Dispose) используется для подсчета количества объектов на выходе. По завершении моделирования процесса рядом с ним возникнет число, показывающее, сколько объектов скопилось на выходе. У нас это будет количество страховых выплат по заявлениям, поданным лично и присланным по почте.