

Набор инструкций, совмещающий процедуры обработки и пересылки;
Одно- и двухтактное исполнение вычислительных команд;
7-ступенчатый конвейер по выполнению 32– и 64–разрядных инструкций;
Расширенные возможности по динамическому диапазону обрабатываемых данных, позволяющие обрабатывать данные в 8/16/32/64–разрядных форматах с фиксированной точкой, 32-разрядном формате с плавающей точкой в стандарте IEEE754, либо программно в формате с плавающей точкой 32Е16 (расширенный формат);
Аппаратные меры повышения точности и динамического диапазона (блочная плавающая точка; режим насыщения; инструкции преобразования форматов);
Аппаратная поддержка программных циклов;
Общий объём памяти программ и данных DSP-кластера – 320 Кбайт:
PRAM (DSP0) – 8К 32-разрядных слов;
PRAM (DSP1) – 8К 32-разрядных слов;
Xyram – 64к 32-разрядных слов;
Подвижная граница между памятью программ и данных: память программ PRAM каждого DSP-ядра может иметь объем от 32 до 128 Кбайт, общая для 2-х DSP-ядер память данных XYRAM объемом от 64 до 256 Кбайт; при распределении памяти выделяемый объем памяти одинаков для обоих ядер;
Доступ DSP–ядер ко всему адресному пространству микросхемы - адресуемым регистрам и памяти;
Встроенный кодер Хаффмана (JPEG) для более эффективного сжатия изображений;
Встроенный в каждый DSP 32-разрядный интервальный таймер, работающий от частоты DSP;
Максимальная пропускная способность коммутатора ядер с памятью – 512 бит за такт;
Максимальная скорость обмена внешних устройств с памятью кластера – 64 бит за такт;
Пиковая суммарная производительность DSP-кластера (на частоте 250 МГц):
в формате плавающей точки (24E8, стандарт IEEE754): 4000 MIPS, что соответствует 16 операциям с плавающей точкой (IEEE754) за 1 такт;
в формате фиксированной точки (int32): 4000 MIPS, что соответствует 64 32-битным операциям с фиксированной точкой за 1 такт;
в формате фиксированной точки (int16): 16000 MIPS, что соответствует 64 16-битным операциям с фиксированной точкой за 1 такт;
в формате фиксированной точки (int8): 24000 MIPS, что соответствует 96 байтным операциям с фиксированной точкой за 1 такт.
Структурная схема 2-ядерного DSP-кластера DELcore-30MM приведена на рисунке 4.
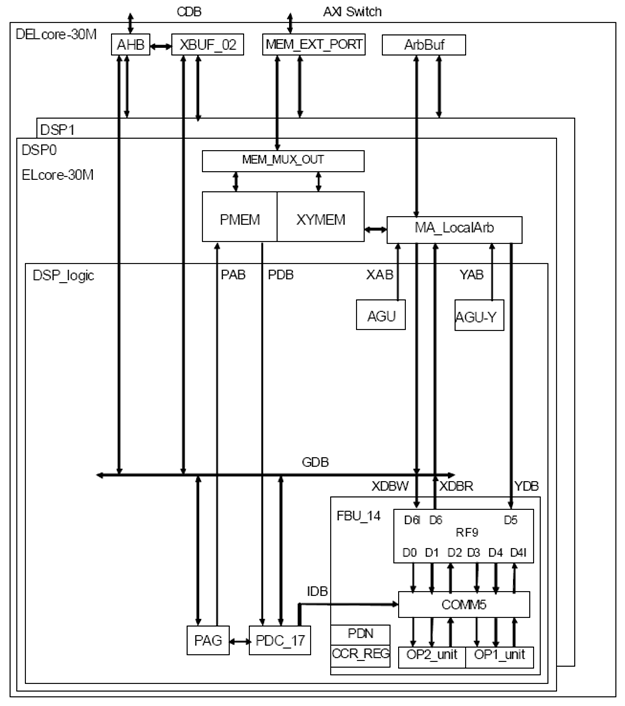
Рис. 4. Структурная схема DELcore-30MM
На схеме обозначены:
DSP0 – DSP1 – два DSP-ядра ELcore-30М;
PMEM – память программ;
XYMEM – память данных;
AHB – контроллер шины CDB (slave);
MEM_EXT_PORT, MEM_MUX_OUT – распределенный контроллер AXI Switch (slave);
XBUF_02 – буфер обмена (регистровый файл 32 слова по 64 разряда, 6 портов);
ArbBuf, MA_LocalArb – распределенный арбитр;
DSP_logic – вычислительное ядро;
AGU, AGU-Y – адресные генераторы памяти данных;
PAG – адресный генератор памяти программ;
PDC_17 – программный декодер;
RF9 – регистровый файл 16 слов по 128 разрядов, 9 портов;
COMM5 – коммутатор входных данных операционных устройств;
OP1_unit, OP2_unit – операционные (вычислительные) устройства;
CCR_REG, PDN – регистры признаков результата операции и параметра денормализации.
Операционные устройства состоят из:
Умножитель-сдвигатель для форматов с фиксированной точкой (MS/SH);
Умножитель для формата с плавающей точкой IEEE-754 (FMU);
Арифметическое устройство для форматов с фиксированной точкой (AU), включая логическое устройство (LU) и узел битовой обработки(BFU);
Арифметическое устройство для формата с плавающей точкой (FASU).
Кластер DSP организован как система с асимметричным доступом к памяти (NUMA). Общее адресное пространство кластера состоит из локальных памятей XYRAM0, XYRAM1 каждого из DSP ядер. Таким образом, вся память разбита на 2 сегмента, при этом для каждого DSP ядра есть ближний (свой) сегмент памяти, обращения к которому в случае, если нет конфликтов с другим ядром, не приводят к простою ядра. Другой же сегмент для него является дальним (чужим) и обращения к нему могут приводить к простоям ядра даже в отсутствии конфликтов между ядрами. Обращения к чужому сегменту памяти проходит через очередь обращений.
Операция записи является буферизованной, т.е. в отсутствии конфликтов между ядрами запись в дальний сегмент памяти не приводит к простою ядра. Физически запись в память происходит не сразу после исполнения инструкции, а через время, требуемое для прохождения данных по очереди обращений и на разрешение конфликтов (в отсутствии конфликтов запись корректных данных в дальнюю память осуществляется через 2 такта после исполнения инструкции записи в память).