

Расчетная таблица
Номер предприятия |
Выпуск продукции, тыс. ед. х |
Затраты на производство, млн. руб. у |
|
|
|
|
1 2 3 4 5 6 7 |
1 2 4 3 5 3 4 |
30 70 150 100 170 100 150 |
30 140 600 300 850 300 600 |
1 4 16 9 25 9 16 |
900 4900 22500 10000 28900 10000 22500 |
331,1 67,9 141,6 104,7 178,4 104,7 141,6 |
Итого |
22 |
770 |
2820 |
80 |
98890 |
770 |
Система нормальных уравнений будет иметь вид:
![]()
Решив ее, получим:
![]() .
.
Уравнение регрессии примет вид:
![]()
Подставив в уравнение значения х, найдем теоретические значения у. В данном случае параметр не имеет экономического смысла.
Тесноту связи
изучаемых явлений оценивает линейный
коэффициент парной корреляции
![]() для линейной
регрессии (-1 ≤
для линейной
регрессии (-1 ≤
![]() ≤
1):
≤
1):
![]()
![]() ,
,
где
![]() - среднее квадратическое отклонение в
ряду x,
- среднее квадратическое отклонение в
ряду x,
![]() -
среднее квадратическое отклонение в
ряду y.
-
среднее квадратическое отклонение в
ряду y.
Линейный коэффициент корреляции как измеритель тесноты линейной связи признаков связан не только с коэффициентом регрессии b, но и с коэффициентом эластичности, который является показателем силы связи, выраженным в процентах.
Коэффициент
эластичности отражает,
на сколько процентов изменится значение
y
при изменение значения фактора на 1%.
Коэффициент эластичности рассчитывается
как
![]() .
.
Обобщающий
(средний) коэффициент эластичности
рассчитывается для среднего значения
![]() :
:
![]()
![]()
и показывает, на сколько процентов изменится y относительно своего среднего уровня при росте x на 1% относительно своего среднего уровня.
Точечный коэффициент эластичности рассчитывается для конкретного значения x=x0:
![]()
![]()
и показывает, на
сколько процентов изменится y
относительно своего уровня y(x0)
при увеличении
![]() на 1% от уровня x0.
на 1% от уровня x0.
Для оценки качества подбора линейной функции рассчитывается коэффициент детерминации. Коэффициент детерминации – это квадрат линейного коэффициента парной корреляции; он характеризует долю дисперсии результативного признака у, объясняемую регрессией, в общей дисперсии результативного признака:
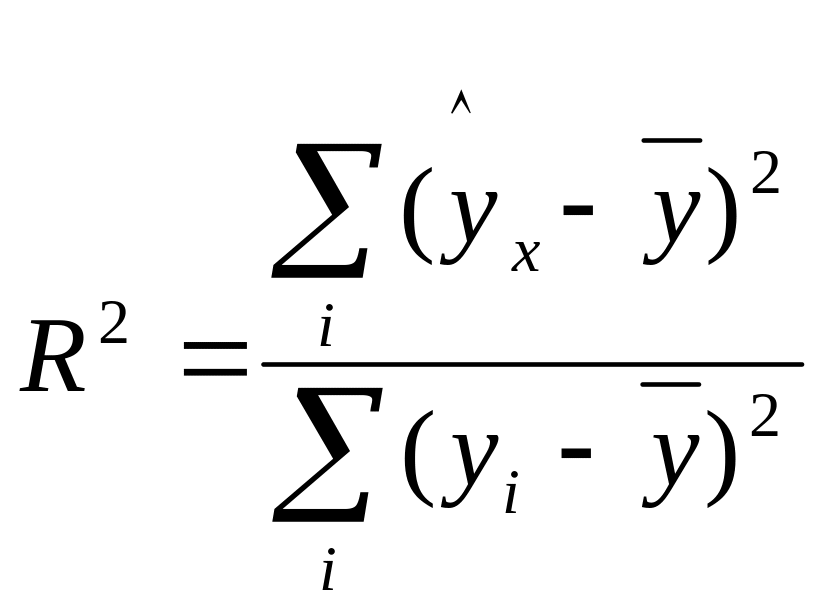 ,
,
где
![]()
![]() - сумма квадратов отклонений, обусловленная
регрессией
- сумма квадратов отклонений, обусловленная
регрессией
(факторная);
![]() -
общая сумма квадратов отклонений.
-
общая сумма квадратов отклонений.
Чем больше доля объясненной вариации, тем соответственно меньше роль прочих факторов и, следовательно, линейная модель хорошо аппроксимирует исходные данные, и ею можно воспользоваться для прогноза значений результативного признака. Иначе, чем ближе коэффициент детерминации к 1, тем в большей степени уравнение регрессии пригодно для прогнозирования.
После того как уравнение линейной регрессии найдено, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Проверка значимости уравнения регрессии осуществляется путем расчета F-критерия Фишера. F-тест состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Непосредственному расчету F-критерия предшествует анализ дисперсии. Центральное место в нем занимает разложение общей суммы квадратов отклонений на две части: объясненную (факторную) и остаточную:
 ,
,
где
 - остаточная сумма квадратов отклонений.
- остаточная сумма квадратов отклонений.
Любая сумма
квадратов отклонений связана с числом
степеней свободы df,
т.е. с числом свободы независимого
варьирования признака. Число степеней
свободы связано с числом единиц
совокупности n
и с числом определяемых по ней констант.
Применительно к исследуемой проблеме
число степеней свободы должны показать,
сколько независимых отклонений из n
возможных
![]() требуется для образования данной суммы
квадратов. Так, для общей суммы квадратов
требуется для образования данной суммы
квадратов. Так, для общей суммы квадратов
![]() необходимо (n-1)
независимых отклонений, ибо по совокупности
из n
единиц после
расчета среднего уровня свободно
варьируют лишь (n-1)
число
отклонений. Например, имеем ряд значений
у:
1, 2, 3, 4, 5.
необходимо (n-1)
независимых отклонений, ибо по совокупности
из n
единиц после
расчета среднего уровня свободно
варьируют лишь (n-1)
число
отклонений. Например, имеем ряд значений
у:
1, 2, 3, 4, 5.
![]() ,
и тогда n
отклонений от среднего составят: -2; -1;
0; 1; 2. Поскольку сумма отклонений равна
нулю (
,
и тогда n
отклонений от среднего составят: -2; -1;
0; 1; 2. Поскольку сумма отклонений равна
нулю (![]() ),
то свободно варьируют лишь четыре
отклонения, а пятое отклонение может
быть определено, если четыре предыдущие
известны.
),
то свободно варьируют лишь четыре
отклонения, а пятое отклонение может
быть определено, если четыре предыдущие
известны.
При расчете
объясненной, или факторной, суммы
квадратов
![]() используются теоретические (расчетные)
значения результативного признака,
найденные по линии регрессии. При
заданном объеме наблюдений по х
и у
факторная сумма квадратов при линейной
регрессии зависит только от одной
константы коэффициента регрессии b,
то данная сумма квадратов имеет одну
степень свободы.
используются теоретические (расчетные)
значения результативного признака,
найденные по линии регрессии. При
заданном объеме наблюдений по х
и у
факторная сумма квадратов при линейной
регрессии зависит только от одной
константы коэффициента регрессии b,
то данная сумма квадратов имеет одну
степень свободы.
Существует равенство между числом степеней свободы общей, факторной и остаточной суммами квадратов. Число степеней свободы остаточной суммы квадратов при линейной регрессии составляет n-2. Число степеней свободы для общей суммы квадратов определяется числом единиц, и поскольку мы используем среднюю вычисленную по данным выборки, то теряем одну степень свободы, т.е. dfобщ = n – 1.
Разделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений или дисперсию на одну степень свободы:
 ;
;
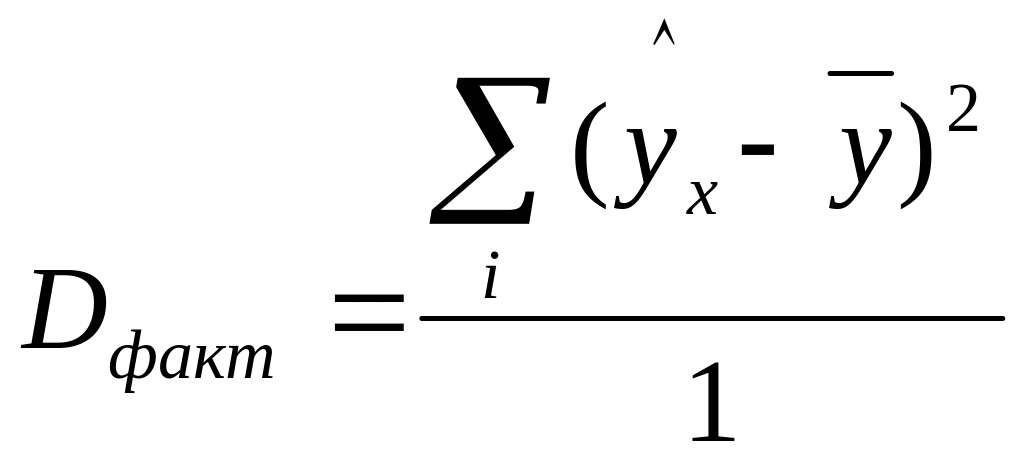 ;
;
 .
.
Определение дисперсии на одну степень свободы приводит дисперсии к сравниваемому виду. Сопоставляя факторную и остаточную дисперсии на одну степень свободы, получим величину F- отношения, т.е. критерий F:
![]() .
.
При линейной связи возможно использование формул:
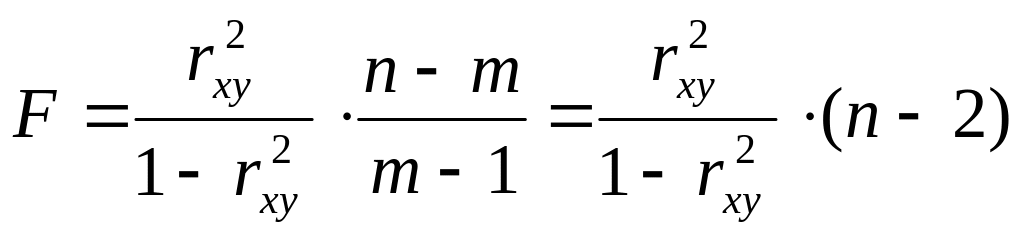 или
или
 ,
,
где m – число параметров в уравнении регрессии;
(m-1) – число степеней свободы для факторной дисперсии;
n – число наблюдений;
(n-m) – число степеней свободы для остаточной дисперсии.
Вместо числа параметров уравнения регрессии m можно использовать число коэффициентов регрессии k, которое на единицу меньше m, т.е. k=(m−1).
Вычисленное значение F- отношения признается достоверным (отличным от единицы), если оно больше табличного значения F-критерия. В этом случае нулевая гипотеза об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи:
Fтабл‹ Fфакт, гипотеза Н0 отклоняется.
Fтабл
– это
максимально возможное значение критерия
под влиянием случайных факторов при
данных степенях свободы (![]() )
и уровне значимости
)
и уровне значимости
![]() ,
который принимается равным 0,05 или 0,01.
,
который принимается равным 0,05 или 0,01.
Если же величина F окажется меньше табличной, то вероятность нулевой гипотезы выше заданного уровня и она не может быть отклонена без риска сделать неправильный вывод о наличии связи.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t-критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Н0 о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путем сопоставления их значений с величиной стандартной ошибки:
![]() ;
;
![]() .
.
Стандартные ошибки параметров линейной регрессии и коэффициент корреляции определяются по формулам:
 ,
,
где S2 – остаточная дисперсия на одну степень свободы;
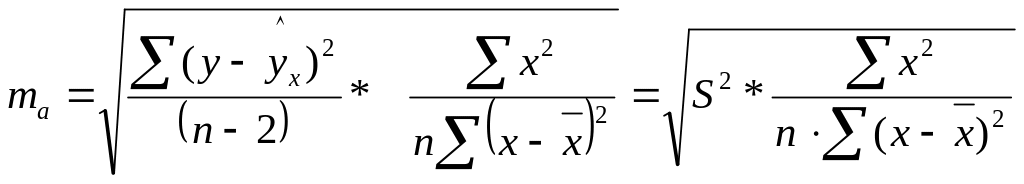 ;
;
![]()
Сравнивая фактическое tфакт и критическое (табличное) значения t-статистики tтабл (при определенном уровне значимости и числе степеней свободы (n-2)) – принимаем или отвергаем гипотезу Н0. Если tтабл < tфакт, то Н0 отклоняется, т.е. a, b, rxy не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если tтабл > tфакт, то гипотеза Н0 не отклоняется и признается случайная природа формирования a, b, rxy.
Рассмотренную
формулу оценки коэффициента корреляции
рекомендуется применять при большом
числе наблюдений, а также если rxy
не близко
к +1 или –1. Если же величина rxy
близка к +1, то распределение его оценок
отличается от нормального, или
распределения Стьюдента, так как величина
коэффициента корреляции ограничена
значения от –1 до +1. Для устранения
данного затруднения Р.Фишер ввел
вспомогательную величину z,
связанную с rxy
следующим
соотношением:
![]() .
При изменении rxy
от –1 до +1 величина z
изменятся от
.
При изменении rxy
от –1 до +1 величина z
изменятся от
![]() до
до
![]() ,
что соответствует нормальному
распределению.
,
что соответствует нормальному
распределению.
Стандартная ошибка величины z рассчитывается по формуле:
![]() .
.
Для расчета
доверительного интервала определяем
предельную
ошибку
![]() для каждого показателя:
для каждого показателя:
![]()
Формулы для расчета доверительных интервалов имеют следующий вид:
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значения.
Прогнозное
значение yp
определяется путем подстановки в
уравнение регрессии
![]() соответствующего (прогнозного) значения
xp.
Вычисляется
стандартная ошибка прогноза
соответствующего (прогнозного) значения
xp.
Вычисляется
стандартная ошибка прогноза
![]() :
:
 .
.
Величина стандартной
ошибки достигает минимума при xp=![]() и возрастает по мере того, как «удаляется»
от
в любом направлении. Можно ожидать
наилучшие результаты прогноза, если
признак-фактор находится в центре
области наблюдений х.
и возрастает по мере того, как «удаляется»
от
в любом направлении. Можно ожидать
наилучшие результаты прогноза, если
признак-фактор находится в центре
области наблюдений х.
Доверительный интервал прогноза:
![]() ;
;
![]() ;
;
![]() ,
,
где
![]() .
.
Однако так как
фактические значений у
варьируют около среднего значения
![]() ,
индивидуальные значения у
могут отклоняться от
на величину случайно ошибки
,
индивидуальные значения у
могут отклоняться от
на величину случайно ошибки
![]() ,
дисперсия которой оценивается как
остаточная дисперсия на одну степень
свободы S2.
Поэтому
ошибка предсказываемого индивидуального
значения у
должна включать не только стандартную
ошибку, но и случайную ошибку. Средняя
ошибка прогнозируемого индивидуального
значения составит:
,
дисперсия которой оценивается как
остаточная дисперсия на одну степень
свободы S2.
Поэтому
ошибка предсказываемого индивидуального
значения у
должна включать не только стандартную
ошибку, но и случайную ошибку. Средняя
ошибка прогнозируемого индивидуального
значения составит:
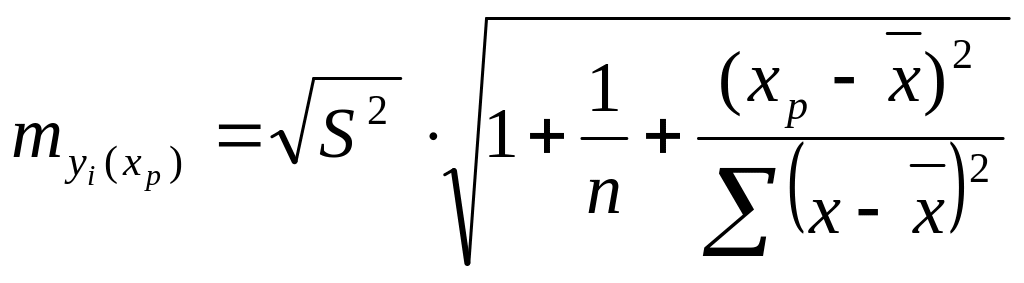 .
.
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций.
Нелинейные регрессии делятся на два класса:
регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам;
регрессии, нелинейные по оцениваемы параметрам.
Регрессии, нелинейные по объясняющим переменным:
полиномы разных степеней:
![]() ;
;
равносторонняя гипербола:
![]() .
.
Линеаризация,
которая состоит в замене нелинейных
объясняющих переменных новыми линейными
переменными, приводит нелинейную
регрессию к виду линейной. Например, в
параболе второй степени:
![]() ,
заменяем переменную х2
на
z,
и получаем
двухфакторное уравнение линейной
регрессии:
,
заменяем переменную х2
на
z,
и получаем
двухфакторное уравнение линейной
регрессии:
![]() .
.
Полином любого порядка может быть сведен к линейной регрессии с последующим применением методов оценивания параметров и проверки гипотез.
Среди класса нелинейных функций, параметры которых без особых затруднений оцениваются с помощью метода наименьших квадратов (МНК), выступает равносторонняя гипербола: , которая может быть использована, например, для характеристики связи удельных расходов сырья, материалов и топлива с объемом выпускаемой продукции.
Линеаризация
происходит путем замены
![]() на z,
что приводит к линейному уравнению
регрессии вида:
на z,
что приводит к линейному уравнению
регрессии вида:
![]() .
.
Регрессии нелинейные по оцениваемым параметрам представлены ниже:
степенная –
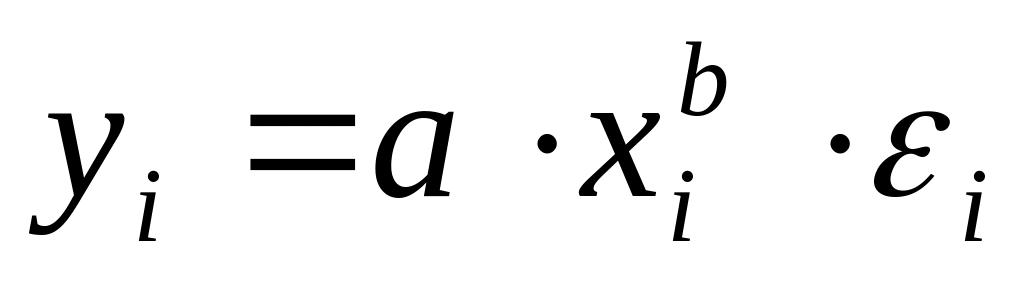 ;
;показательная –
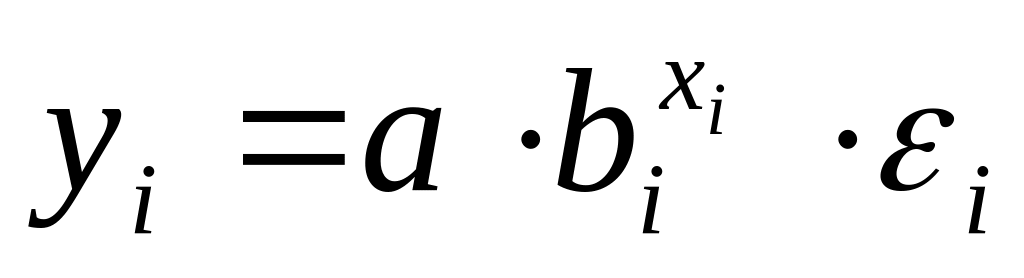 ;
;экспоненциальная –
 .
.
Степенная функция
является примером нелинейной по
параметрам регрессии. Данная модель
нелинейна относительно оцениваемых
параметров, т.к. включает параметры a
и b
неаддитивно. Однако ее можно считать
внутренне линейной, так как логарифмирование
приводит его к линейному виду:
![]() .
.
При исследовании взаимосвязей среди функций, использующих ln y, в эконометрике преобладают степенные зависимости – это кривые спроса и предложения, кривые освоения для характеристики связи между трудоемкостью продукции и масштабами производства в период освоения выпуска нового вида изделий, а также зависимость валового национального дохода от уровня занятости.
Для оценки параметров степенной функции применяется МНК к линеаризованному уравнению , т.е. решается система нормальных уравнений:
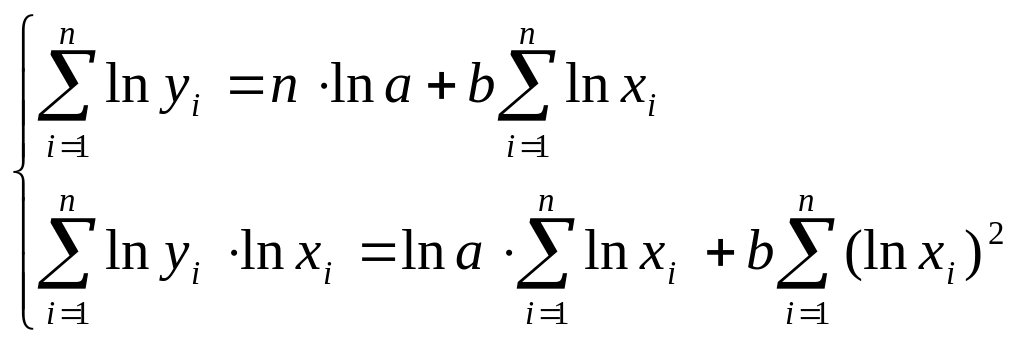
Параметр b определяется непосредственно из системы, а параметр a – косвенным путем после потенцирования величины ln a.
Так как в виде степенной функции изучается не только эластичность спроса, но и предложения, то обычно параметром b<0 характеризуется эластичность спроса, а параметром b>0 – эластичность предложения.
Ниже представлены формулы расчета коэффициентов эластичности (табл. 1.2).
Таблица 1.2.