

Процессорная шина
Любой процессор архитектуры x86CPU обязательно оснащён процессорной шиной. Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском и так далее. Так, классическая схема организации внешнего интерфейса процессора (используемая, к примеру, компанией Intel в своих процессорах архитектуры х86) предполагает, что параллельная мультиплексированная процессорная шина, которую принято называть FSB (Front Side Bus), соединяет процессор (иногда два процессора или даже больше) и контроллер, обеспечивающий доступ к оперативной памяти и внешним устройствам. Этот контроллер обычно называют северным мостом, он входит в состав набора системной логики (чипсета).
Используемая Intel в настоящее время эволюция FSB – QPB, или Quad-Pumped Bus, способна передавать четыре блока данных за такт и два адреса за такт. То есть за каждый такт синхронизации шины по ней может быть передана команда либо четыре порции данных (напомним, что шина FSB–QPB имеет ширину 64 бит, то есть за такт может быть передано до 4х64=256 бит, или 32 байт данных). Итого, скажем, для частоты FSB, равной 200 МГц, эффективная частота передачи адреса для выборки данных будет эквивалентна 400 МГц (2х200 МГц), а самих данных – 800 МГц (4х200 МГц)3.
Но, для многочисленных мелких запросов, где данные в большинстве своём умещаются в одну 64-байтную порцию (и, соответственно, не используются возможности DDR или QDR/QPB), на чтение/запись - важна именно частота тактирования.
В архитектуре же AMD64 (и её микроархитектуре K8), используемой компанией AMD в своих процессорах линеек Athlon 64/Sempron/Opteron, применён революционно новый подход к организации интерфейса центрального процессора – здесь имеет место наличие в самом процессоре нескольких отдельных шин. Одна (или две – в случае двухканального контроллера памяти) шина служит для непосредственной связи процессора с памятью, а вместо процессорной шины FSB и для сообщения с другими процессорами используются высокоскоростные шины HyperTransport. Преимуществом данной схемы является уменьшение задержек (латентности) при обращении процессора к оперативной памяти, ведь из пути следования данных по маршруту «процессор – ОЗУ» (и обратно) исключаются такие весьма загруженные элементы, как интерфейсная шина и контроллер северного моста.
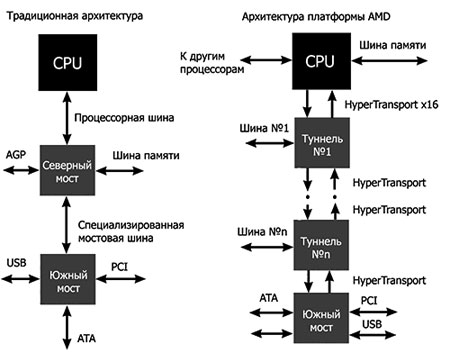
Рисунок 1 - Различия реализации классической архитектуры и АМD-K8
Также отличием архитектуры К8 является отказ от асинхронности, то есть обеспечение синхронной работы процессорного ядра, ОЗУ и шины HyperTransport, частоты которых привязаны к «шине» тактового генератора (НТТ), которая в этом случае является опорной. Таким образом, для процессора архитектуры К8 частоты ядра и шины HyperTransport задаются множителями по отношению к НТТ, а частота шины памяти выставляется делителем от частоты ядра процессора.
Пример: для системы на базе процессора Athlon 64-3000+ (1,8 ГГц) с установленной памятью DDR-333 стандартная частота ядра (1,8 ГГц) достигается умножением на 9 частоты НТТ, равной 200 МГц, стандартная частота шины HyperTransport (1 ГГц) – умножением НТТ на 5, а частота шины памяти (166 МГц) – делением частоты ядра на 11.
В классической же схеме с шиной FSB и контроллером памяти, вынесенным в северный мост, возможна (и используется) асинхронность шин FSB и ОЗУ, а опорной частотой для процессора выступает частота тактирования (а не передачи данных) шины FSB, частота же тактирования шины памяти может задаваться отдельно.
Пример: процессор Intel Celeron 1,7GHz Willamette с заявленной на коробке частотой шины FSB-QPB 400 МГц, тем не менее, имеет коэффициент умножения 17 (1700=100*17), а не 4,5.
Основные принципы работы FSB
FSB изначально является многоагентной шиной, это значит, что в классической архитектуре Intel есть главный агент — центральный процессор ЦП, который соединяется с узловым агентом — северным мостом — по фронтальной шине. Последнюю также можно называть внешней или процессорной. Когда речь идет о многоядерной (многопроцессорной) системе, то вычислительные ядра, одновременно присутствующие на внешней шине FSB, представляются симметричными агентами. Однако в любом случае факультативно приоритет на фронтальной шине FSB имеет северный мост — агент набора микросхем системной логики, который можно также именовать центральным агентом или агентом, умеющим откладывать транзакции. Кроме того, в классической архитектуре стоит говорить о «двух с половиной» типах агентов, ведь наряду с симметричным и центральным агентами существует еще и так называемый «снупинг-агент» (от слова snooping — подглядывание, вынюхивание), чью роль исполняет процессор с задачей наблюдения за работой других агентов. Конечно, шинная топология компьютерной платформы предусматривает и другие важные резиденты, например южный мост, который отвечает за операции ввода-вывода, и оперативную память, но общение с такого рода компонентами происходит уже не по шине FSB.
Итак, любая передача данных на процессорной шине является транзакцией, состоящей из нескольких фаз. Первая ступень — это фаза арбитража (Arbitration), вторая — фаза запроса (Request), третья — фаза снупинга (Snoop). Четвертая стадия — это фаза ответа (Response), которая несет в себе информацию о том, не было ли ошибки (Error) и будет ли передача данных, что может выливаться в появление пятого этапа — фазы передачи данных (Data transfer). Последней ступени в транзакции может и не быть (если данные не должны передаваться), но фазы арбитража, запроса, снупинга и ответа присутствуют обязательно. К тому же все этапы транзакций выполняются на шине конвейерным методом.
Подобная конвейеризация фаз позволяет работать на процессорной шине сразу нескольким агентам, ведь при выполнении любых транзакций шина FSB практически не блокируется и остается доступна. Но в один момент времени на шине могут конвейеризироваться не более 12 транзакций, которые отслеживаются в специальной очереди IOQ (In-Order Queue — упорядоченная очередь) на шине.
Так как шина FSB является общей, то для ее корректного функционирования потребуется еще и распределение приоритетов по агентам, за которое собственно и отвечает фаза арбитража. Так, центральный агент (северный мост) в случае необходимости, очевидно, должен иметь больший приоритет по отношению к симметричным агентам (например, ядра Kentsfield), распределяющими между собой приоритеты по времени обращения к процессорной шине. И если в череде транзакций от симметричных агентов появится специальный запрос от северного моста системной логики, то это обращение в шине может обладать внеочередным правом на исполнение.

HyperTransport
HyperTransport – это прежде всего технология, управлением спецификациями и продвижением которой занимается HyperTransport Technology Consortium, куда входят такие компании, как Advanced Micro Devices (AMD), Alliance Semiconductor, Apple Computer, Broadcom Corporation, Cisco Systems, NVIDIA, PMC-Sierra, Sun Microsystems, Transmeta и ещё более 140 малых и больших компаний.
Основные особенности и возможности, предоставляемые технологией HyperTransport
Технология HyperTransport – это последовательная (пакетная) связь, построенная по схеме peer-to-peer (точка-точка), обеспечивающая высокую скорость при низкой латентности (low-latency responses). HyperTransport имеет оригинальную топологию на основе линков, тоннелей, цепей (цепь – последовательное объединение нескольких туннелей) и мостов (мост выполняет маршрутизацию пакетов между отдельными цепями), что позволяет этой архитектуре легко масштабироваться. Иными словами, HyperTransport призвана упростить внутрисистемные сообщения (передачи) посредством замены существующего физического уровня передачи существующих шин и мостов, а также снизить количество узких мест и задержек. При всех этих достоинствах HyperTransport характеризуется также малым числом выводов (low pin counts) и низкой стоимостью внедрения. HyperTransport поддерживает автоматическое определение ширины шины, допуская ширину от 2 до 32 бит в каждом направлении, использует Double Data Rate, или DDR (данные посылаются как по переднему, так и по заднему фронтам сигнала синхронизации), кроме того, она позволяет передавать асимметричные потоки данных к периферийным устройствам и от них.
Несмотря на присутствие такого параметра, как ширина, шина HyperTransport является последовательной, что не позволяет соотносить ширину шины с её разрядностью.

Рисунок 2 - Топология шины HyperTransport
Самые известные решения c использованием HyperTransport:
шина, созданная по технологии HyperTransport, является основной шиной, используемой в процессорах восьмого поколения компании AMD – Athlon 64 и Opteron, а также внутри поддерживающих их устройств: концентратора ввода-вывода (I/O hub) AMD-8111, AMD-8131 PCI-X tunnel и AMD-8151 AGP 3.0 graphics tunnel
SiPackets предлагает мост между HyperTransport и PCI (HyperTransport-to-PCI bridge)

Рисунок 3 - Использование шины НyperТransport на примере двухпроцессорной системы на базе AMD Opteron
PCI
PCI – шина для подключения периферийных устройств к материнской плате компьютера – находится внутри практически каждого компьютера и, несмотря на моральное устаревание и уже недостаточную пропускную способность, продолжает оставаться основной шиной для подключения к системе внешних устройств. Тем не менее, она сдаёт позиции новой последовательной шине PCI-Express.
В 1991 году компания Intel представила первую спецификацию системной шины PCI – Peripheral Component Interconnect (дословно: взаимосвязь периферийных компонентов). А в 1993 году уже началось активное продвижение на рынок шины PCI 2.0, которая дала толчок увеличению числа ориентированных на неё продуктов и довольно быстро вытеснила изрядно устаревшие к тому времени шины ISA и EISA.
Причины успеха PCI – это гораздо большая скорость и возможность динамического конфигурирования периферийных устройств, подключённых к PCI (чего не было в ISA), то есть распределения ресурсов между периферийными устройствами наиболее приемлемым в данный момент времени образом и без постороннего вмешательства.
Основные тактико-технические характеристики PCI 2.0:
частота шины – 33,33 МГц, передача синхронная
разрядность шины – 32 бит
пиковая пропускная способность – 133 Мбит/с
адресное пространство памяти – 32 бит (4 Гбайт)
адресное пространство портов ввода-вывода – 32 бит (4 Гбайт)
количество подключаемых устройств – до четырёх (для увеличения их количества используется мост PCI-to-PCI)
конфигурационное адресное пространство (для одной функции) 256 байт
напряжение 3,3 или 5 В
Ещё большее распространение получил стандарт 2.2.
Отличия PCI 2.2 от 2.0:
возможность одновременной работы нескольких устройств bus-master (так называемый конкурентный режим)
появление универсальных карт расширения, способных работать как в слотах 5 В, так и в 3,3 В
появились расширения PCI66 и PCI64 (ширина шины может быть увеличена до 64 бит, а также допускается разгон тактовой частоты до 66 МГц – вдвое по сравнению с PCI 2.0)
сделанные в соответствии с этими стандартами карты расширения имеют универсальный разъём и способны работать практически во всех более поздних разновидностях слотов шины PCI, а также, в некоторых случаях, и в слотах 2.1
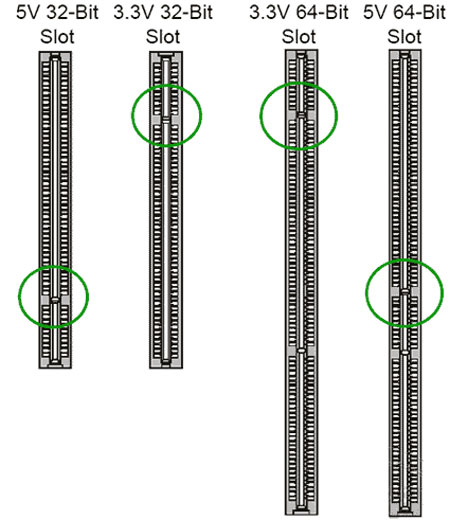
Рисунок 4 – Разъемы PCI