

1. Объясните схему процесса решения творческих задач
Любая задача является творческой, то есть инженерной, если для её решения необходима изобретательность, эвристический склад ума. Поэтому слово «инженер» здесь употребляется не как нарицательная специальность, а как указание на творческий характер технических задач.
Под задачей Д. Пойа понимает следующее: «задача предполагает необходимость сознательного поиска соответствующего средства для достижения ясно видимой, но непосредственно недоступной цели. Решение задачи означает нахождение этого средства».
Решение - это процесс, хотя часто это слово понимается и как результат. На входе процесса, в нашем случае статистического моделирования, находится матрица исходных данных (при однофакторном моделировании - статистическая выборка) и эвристическая модель представлений, гипотез, идей и мыслей о структуре (каркасе) взаимодействий между переменными (столбцами или строками матрицы).
В более сложных случаях учитываются связи даже между отдельными значениями переменных (взаимная связность при отсутствии независимости между учитываемыми факторами), то есть между клетками матрицы (таблицы) данных.
Первое требование понятно всем, так как если нет данных, то существует только постановка задачи моделирования и необходимо собрать эти количественные данные, то есть сформировать матрицу данных. Конечно же, здесь возникает множество вариантов стратегий поведения: во-первых, воспользоваться таблицами данных других исследователей; во-вторых, собрать то, что имеется и возможно иметь в данной информационной среде; в-третьих, провести планирование эксперимента по сбору данных (в инженерной экологии и природопользовании используются текущие или прошлые данные без планирования экспериментов, по не экспериментальным данным или же по так называемому методу эволюционного эксперимента).
Вот тут то и подключается второе требование - это наличие содержательного описания матрицы данных. Без этого данные превращаются просто в неорганизованное множество чисел. Поэтому смысловые коды-отображения всегда, хотя бы на минимальном уровне (констатация фактов), должны быть приведены в публикациях, отчетах и других информационных документах. Эти эвристические модели, представленные в текстовой форме на естественном языке, могут быть и неточными, даже иногда ложно объясняющими результаты наблюдений.
В истории науки немало примеров, когда матрицы данных объяснялись другими учеными гораздо позже их создателей. Ныне такая же ситуация сложилась в тех отраслях науки, когда огромные массивы количественных данных приводились и ныне приводятся только в табличных формах (экология, экономика, социология и др.).
Таким образом, процесс сбора качественной и количественной информации зависит от постановки задачи, уровня компетентности исследователя и других факторов. Если стратегия моделирования основывается на «чужих» данных, то учитывается их достоверность и полнота. Если она предусматривает проведение экспериментов, то вначале необходима максимально полная проработка концептуальной модели, то есть необходимо уделить внимание вначале эвристике.
Данные несут знания (если, конечно, нет каких-то сомнений в достоверности самих первичных данных). Вот это свойство эвристичности, например, количественных данных в табличной форме, необходимо использовать как важнейший ресурс в ходе содержательного пояснения и структурной идентификации исходной математической модели, выраженной в виде устойчивой закономерности.
Известно, что в природе явления и процессы носят всегда статистический (вероятностный), а не детерминистский (однозначно меняющийся) характер. Эта статистика, как и колебания атомов в молекуле относительно самих себя внутри твердого какого-то тела, имеет изменчивый характер. Чем больше «температура» в процессе моделирования по хаотичности сведений, тем больше колеблются элементы информации (фреймы, порции и пр.) по изменчивости количественных знаний и по силе взаимосвязей между факторами.
На рис. приведена схема процесса решения творческих (инженерных) задач с использованием ПЭВМ.
По этой схеме некоторый реальный процесс (явление - это есть мгновенный срез процесса) должен быть описан по определенной методике мысленного эксперимента путем последовательного (циклического) изучения и постепенного уяснения задачи (в нашем случае задачи получения добротной математической модели по статистическим данным). В процессе изучения происходит отображение реального исследуемого процесса на определенные понятия и опыт исследователя.
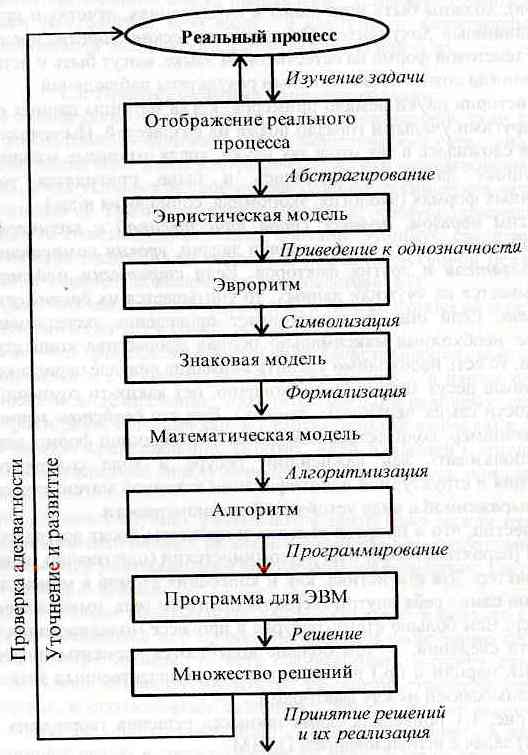
Этот этап является наиболее психологически трудным, так как прежде всего здесь значительна опасность ложной эвристической идентификации фактов и факторов (переложение свойств объекта в категории факторов) и их взаимодействии. Поэтому необходима многократная повторность (если один исследователь) или применение экспертных методов для проверки адекватности мысленного отображения исследуемого процесса.
Путем абстрагирования (на следующем этапе), то есть исключения материальной ткани от ее функционального каркаса, создается словесное описание исследуемого объекта. Такое сочинение на заданную тему образует эвристическую модель. Она, как правило, содержит мало количественных данных, но содержит много известных и предполагаемых априори знаний. Однако это сочинение содержит также много двусмысленностей, что характерно для естественного языка и неясностей (зависит от стиля писателя), а иногда и непонятных выражений (отличия в терминах) и т.п.
Для повышения определенности описания и однозначности терминов необходимо составить эвроритм, т.е. алгоритм в интуитивном смысле. В этой модели элементами являются четкие по конструкции словосочетания (схема на рис. 1. 1 является эвроритмом).
Остальные этапы по схеме на рис. 1.1 хорошо известны. При построении знаковых моделей применяются общепринятые символы и условные обозначения.
Качественное (эвристическая модель, эвроритм) и количественное (числовые значения факторов) в процессе моделирования могут соотноситься по-разному. Это зависит от подготовленности информации, от опыта исследователя и многих других особенностей. Рассмотрим только наиболее характерные отношения по предельным значениям условной оси «определенность - неопределенность».
Очевидно, что полная неопределенность в качественной и количественной исходной информации приводит к дилетантству, к поверхностным или общим неконкретным рассуждениям. Особенно этот случай важен тогда, когда одну и ту же задачу вместе решают специалист и математик-программист. В этом случае между ними не получится технологического взаимодействия.
Поэтому лучше всего, если в одном исследователе имеются свойства и специалиста и программиста (на уровне пользователя третьего уровня) ПЭВМ. Тогда можно рассмотреть три варианта сочетания предельных значений информированности:
1) количественные данные известны, а качественные знания о задаче неизвестны (неопределенны были в прошлом, утеряны со временем или просто не публиковались): поэтому это задачи на восстановление сущности по количественным данным;
количественные данные неизвестны, но содержательная часть в виде рабочей гипотезы высокой вероятности существования определена: это класс задач, чаще всего расставляемых исполнителям руководителями в сферах управления, науки, техники, экономической теории, инженерной экологии и др., то есть задачи на восстановление количественных данных (по новым экспериментам, систематизации известных статистических данных и т.д.);
количественная и качественная информация по задаче определена; это - задачи на моделирование или перемоделирование (если конструкции моделей ранее были приняты па основе аппроксимационных позиций, например, в виде полиномов, вообще не имеющих физического смысла).
В первом случае применяют существующие знания для объяснения таблиц данных. При моделировании могут быть использованы известные математические конструкты. Хотя из самой матрицы данных можно «выловить» какое-то содержание, но в основном здесь применяют методы аппроксимации линеаризуемыми математическими функциями. Если по минимуму содержательности, получаемой из анализа самой таблицы, можно сделать заключение о соответствии данных устойчивому закону распределения (выполняют дисперсионный и корреляционный анализы, проверку на устойчивые законы распределения), то в этом случае возможно применение методов идентификации.
В реальных задачах полной неопределенности в содержательности не бывает, поэтому здесь моделирование вполне возможно.
Во втором случае речь идет о логичности и доказательности только самой рабочей гипотезы. Во многих областях науки накоплены типовые содержательные ситуации, по которым можно судить о характере будущих количественных данных. Ни один эксперимент не проводится без эвристического предположения об ориентировочных оптимумах, границах изменчивости факторов и других условиях. В этом случае восстановление количественных данных - как говорят - «дело техники».
Многие объекты исследования, несомненно, подчиняются устойчивым законам (недобросовестность в описании содержания и получении исходных данных мы исключаем) развития, строения и взаимодействия. Поэтому эвристическое понимание существенно облегчается и практически накоплен такой богатый материал по первому случаю, что необходима просто состыковка данных со знаниями.
В чистом виде случай содержательного моделирования, без приведения числовых данных, очень распространен. Во многих случаях достаточно просто попять характер явления или процесса, а для принятия управленческих решений иногда количественных данных даже и не требуется. Однако массовость этого случая превышает все разумные меры, поэтому необходимо какое-то рациональное соответствие между всеми тремя случаями моделирования.
В третьем случае структурная определенность математической модели наиболее высока и достоверна для формирования знаний и теорий. Вот этот процесс качественно-количественного анализа и синтеза называется эвристико-статистическим моделированием или просто статистическим моделированием.
Здесь структурная определенность находится на первом месте, а количественная интерпретация рабочей гипотезы - на втором. Тогда критериями адекватности становятся:
1) понимание сущности объекта и предмета моделирования;
2) добротность, полнота и оперативность получения исходных количественных данных, сформированных в виде таблицы.