

1.2. Традиційні файлові системи
Незважаючи на те, що файлові системи баз даних давно застаріли, усе-таки є кілька причин, чому з ними варто познайомитися.:
Розуміння проблем, які властиві файловим системам, може запобігти їх повторення в СКБД. Інакше кажучи, варто врахувати досвід минулих помилок. Насправді, слово "помилки" у даному випадку звучить трохи зневажливо і не дає ніякого представлення про ту корисну роботу, що виконувалася протягом багатьох років. Проте воно дає зрозуміти, що існують і інші, більш ефективні способи керування даними.
Знати принципи роботи файлових систем не тільки дуже корисно, але і необхідно при виконанні переходу від файлової системи до системи баз даних.
1.2.1. Підхід, який використовується у файлових системах БД
Файлові системи БД - набір програм, що виконують для користувачів деякі операції, наприклад створення звітів. Кожна програма визначає свої власні дані і керує ними.
Файлові системи були першою спробою комп'ютеризувати відомі усім ручні картотеки. Подібна картотека (чи підшивка документів) у деякій організації могла містити всю зовнішню і внутрішню документацію, зв'язану з яким-небудь проектом, продуктом, задачею чи клієнтом. Звичайно таких папок буває дуже багато, вони позначаються і зберігаються в одному чи декількох шафах. З метою безпеки шафи можуть закриватися на замок чи знаходитися в приміщеннях, що охороняються . У кожного з нас є у будинку деяка подоба такої картотеки, що містить підшивки документів, що представляють собою рахунки, гарантійні талони, рецепти, страхові і банківські документи і т. і. Якщо нам знадобиться якась інформація, буде потрібно переглянути картотеку від початку до кінця, щоб знайти шукані зведення. Більш витончений підхід передбачає використання в такій системі деякого алгоритму індексування, що дозволяє прискорити пошук потрібних зведень. Наприклад, можна використовувати спеціальні роздільники чи окремі папки для різних логічно, зв'язаних типів об'єктів.
Ручні картотеки дозволяють успішно справлятися з поставленими задачами, якщо кількість збережених об'єктів невелике. Вони також цілком підходять для роботи з великою кількістю об'єктів, які потрібно тільки зберігати і витягати. Однак вони зовсім не підходять для тих випадків, коли потрібно встановити перехресні зв'язки чи виконати обробку зведень. Наприклад, у типовому агентстві, по здачі в оренду об'єктів нерухомості може бути заведений окремий файл для кожного об'єкта, що здається в оренду чи продається, для кожного потенційного покупця чи орендаря, а також для кожного співробітника компанії. Розглянемо тепер, які дії потрібно виконати, щоб відповісти на приведені нижче питання:
Які з виставлених на продаж об'єктів із трьома спальнями мають сад і гараж?
Які з квартир, що здаються в оренду, розташовані в межах трьох миль від центра міста?
Яка середня ціна будинку?
Яка середня орендна плата за квартиру з двома спальнями?
Чому дорівнює загальна річна заробітна плата всіх співробітників?
Яким був щомісячний оборот від продажів нерухомості торік?
Яким був оборот минулого місяця в порівнянні з прогнозованими показниками в цьому місяці?
Яким буде очікуваний щомісячний оборот у наступному фінансовому році?
У наш час клієнтам, менеджерам і іншим співробітникам з кожним днем потрібно усе більше і більше інформації. У деяких областях діяльності існують навіть правові норми на щомісячні, щоквартальні і річні звіти. Ясно, що ручна картотека зовсім не підходить для виконання роботи подібного типу. Файлові системи були розроблені у відповідь на потребу в одержанні більш ефективних способів доступу до даних. Однак, замість організації централізованого сховища всіх даних підприємства, був використаний децентралізований підхід, при якому співробітники кожного відділу за допомогою фахівців з обробки даних (ОД) працюють зі своїми власними даними і зберігають їх у своєму відділі.
Щоб зрозуміти основні принципи такого підходу, ми розглянемо його на прикладі навчального проекту DreamHome.
Співробітники відділу реалізації відповідають за продаж і оренду нерухомості. Наприклад, якщо клієнт звертається у відділ реалізації компанії з пропозицією здати в оренду приналежної йому об'єкт нерухомості, то йому потрібно заповнити форму, подібну представленій на мал.1.1а. У ній указуються такі зведення про об'єкт нерухомості, як адреса і кількість кімнат, а також інформація про власника. Крім того, співробітники відділу реалізації обробляють запити від потенційних орендарів, кожний з який повинний заповнити форму, подібну представленій на мал.1.1б.

З
 а
допомогою співробітників відділу
обробки даних (ОД) співробітники
відділу реалізації створили інформаційну
систему для керування даними про оренду
нерухомості. Ця система складається з
трьох показаних у табл. 1.1 - 1.3 файлів з
даними про нерухомість (Property for Rent),
власників (Owner) і орендарів (Renter).
Для простоти викладу опустимо деталі,
що відносяться до співробітників
компанії, різним її відділенням і
власникам нерухомості, що представляє
собою юридичні особи.
а
допомогою співробітників відділу
обробки даних (ОД) співробітники
відділу реалізації створили інформаційну
систему для керування даними про оренду
нерухомості. Ця система складається з
трьох показаних у табл. 1.1 - 1.3 файлів з
даними про нерухомість (Property for Rent),
власників (Owner) і орендарів (Renter).
Для простоти викладу опустимо деталі,
що відносяться до співробітників
компанії, різним її відділенням і
власникам нерухомості, що представляє
собою юридичні особи.
Співробітники відділу контрактів
відповідають за оформлення договорів
про оренду нерухомості. Якщо клієнт
згодний орендувати деякий об'єкт, що
здається в о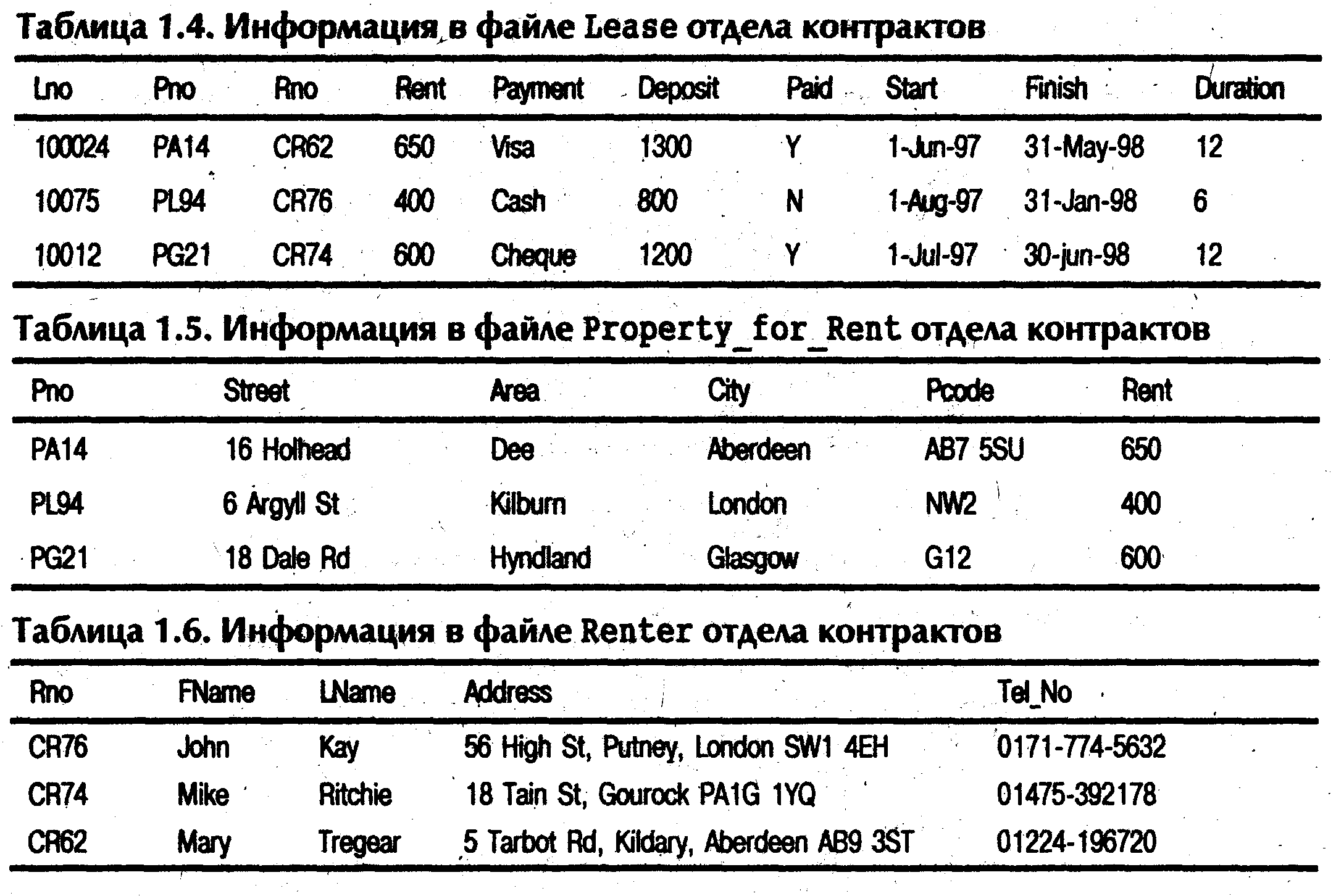 ренду,
то одним зі співробітників відділу
реалізації заповнюється форма, показана
на мал.1.2. У ній указуються всі необхідні
зведення про орендаря й об'єкт, що
здається в оренду, нерухомості. Ця форма
передається у відділ контрактів,
співробітники якого привласнюють
договору номер і вносять додаткові
зведення про оплату і тривалість оренди.
За допомогою співробітників відділу
ОД співробітники відділу контрактів
створили для себе інформаційну систему
обліку договорів про оренду. Ця система
складається з трьох файлів, представлених
у табл. 1.4 - 1.6. Файли містять зведення
про договори (Lease), об'єктах нерухомості
(Property for Rent) і орендарях (Renter), що
багато в чому подібні з даними в
інформаційній системі відділу реалізації.
ренду,
то одним зі співробітників відділу
реалізації заповнюється форма, показана
на мал.1.2. У ній указуються всі необхідні
зведення про орендаря й об'єкт, що
здається в оренду, нерухомості. Ця форма
передається у відділ контрактів,
співробітники якого привласнюють
договору номер і вносять додаткові
зведення про оплату і тривалість оренди.
За допомогою співробітників відділу
ОД співробітники відділу контрактів
створили для себе інформаційну систему
обліку договорів про оренду. Ця система
складається з трьох файлів, представлених
у табл. 1.4 - 1.6. Файли містять зведення
про договори (Lease), об'єктах нерухомості
(Property for Rent) і орендарях (Renter), що
багато в чому подібні з даними в
інформаційній системі відділу реалізації.

У цілому, ця ситуація схематично може бути представлена так, як показано на мал.1.3. На цій схемі кожен відділ звертається до своїх власних даних за допомогою спеціалізованих програм. Набір програм кожного відділу дозволяє вводити дані, працювати з файлами і генерувати деякий фіксований набір спеціалізованих звітів. Найважливішим є та обставина, що фізична структура і методи збереження записів файлів з даними жорстко визначені в коді програм.
Аналогічні приклади можна знайти й в інших відділах. Наприклад, у розрахунковому секторі бухгалтерії зберігаються зведення про зарплату кожного співробітника, поміщені у файл наступного формату:
Staff_Salary (Staff Number, First Name, Last Name, Address, Sex, Date of Birth, Salary, National Insurance Number, Branch Number)
У відділі кадрів також зберігається інформація про персонал, але вона представлена у файлі іншого формату:
Staff (Staff Number, First Name, Last Name, Address, Telephone Number, Position, Sex, Date of Birth, Salary, National Insurance Number, Branch Number)
З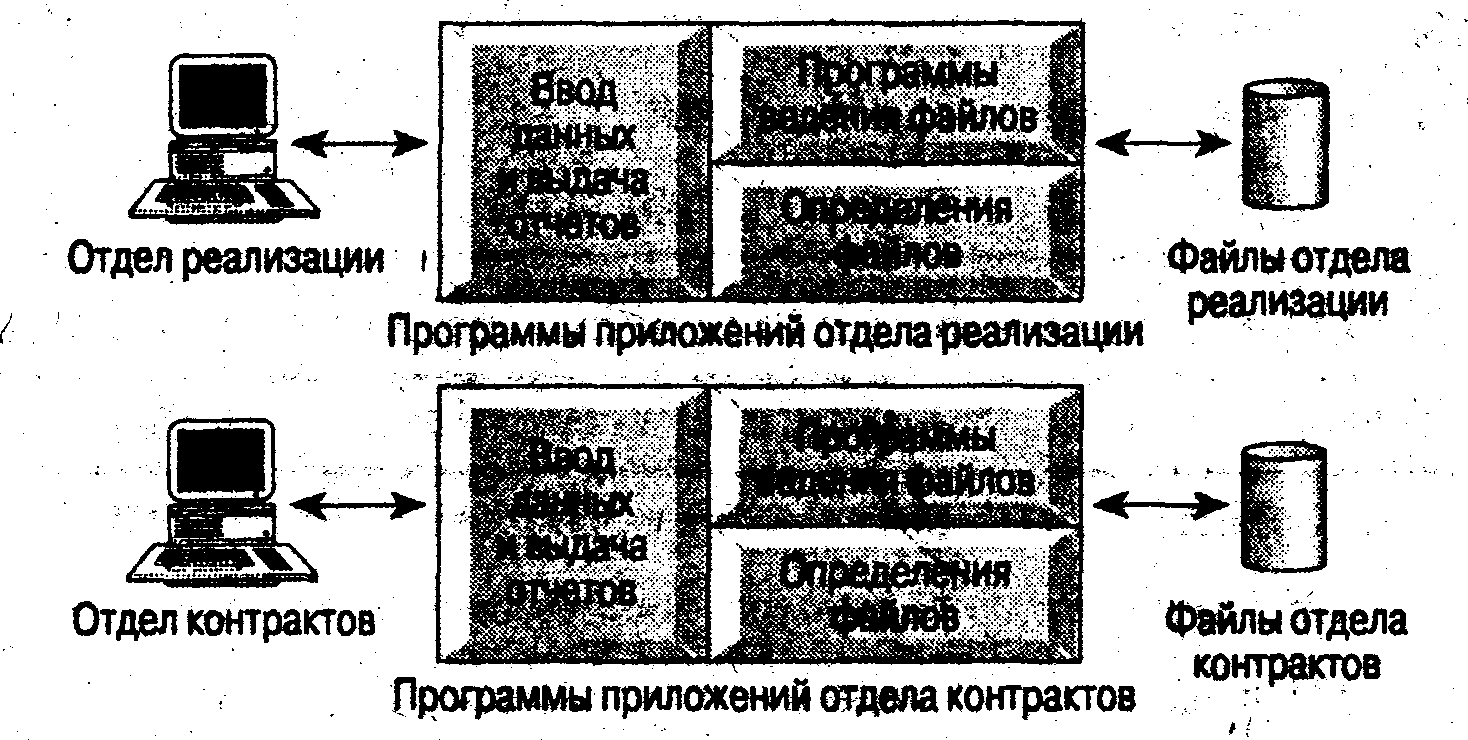 овсім
очевидно, що дуже велика кількість даних
у відділах дублюється і це дуже характерно
для будь-яких файлових систем. Перш ніж
почати обговорення недоліків цього
підходу, було б корисно познайомитися
з термінологією, яка використовується
у файлових системах. Файл є простим
набором записів (record), що містять
логічно зв'язані дані. Наприклад, файл
Ргорerty_for_Rent зміст якого представлено
в табл.1.1, містить шість записів, по
однієї для кожного об'єкту, що здається
в оренду, нерухомості. Кожен запис
містить логічно зв'язаний набір з одного
чи декількох полів (field), кожне з який
представляє деяку характеристику
об'єкту що моделюється. З табл.1.1 видно,
що поля файлу Property_for_Rent представляють
такі характеристики об'єктів, що здаються
в оренду, як адреса, тип об'єкта і кількість
кімнат.
овсім
очевидно, що дуже велика кількість даних
у відділах дублюється і це дуже характерно
для будь-яких файлових систем. Перш ніж
почати обговорення недоліків цього
підходу, було б корисно познайомитися
з термінологією, яка використовується
у файлових системах. Файл є простим
набором записів (record), що містять
логічно зв'язані дані. Наприклад, файл
Ргорerty_for_Rent зміст якого представлено
в табл.1.1, містить шість записів, по
однієї для кожного об'єкту, що здається
в оренду, нерухомості. Кожен запис
містить логічно зв'язаний набір з одного
чи декількох полів (field), кожне з який
представляє деяку характеристику
об'єкту що моделюється. З табл.1.1 видно,
що поля файлу Property_for_Rent представляють
такі характеристики об'єктів, що здаються
в оренду, як адреса, тип об'єкта і кількість
кімнат.
Puc. 1.3. Схема обробки даних е-файловой системі
Файли відділу реалізації
Property_for_Rent (Property Number, Street, Area, City, Post Code; Property Type, Number of Rooms, Monthly Rent, Owner Number)
Owner (Owner Number, First Name, Last Name, Address Telephone Number)
Renter (Renter Number, First Name, Last Name, Address, Telephone Number, Preferred Type, Maximum Rent)
Файли відділу контрактів
Lease (Lease Number, Property Number, Renter Number, Monthly Rent, Payment Method, Deposit, Paid, Rent Start Date, Rent Finish Date, Duration)
Property_For_Rent (Property Number, Street, Area, City, Post Code, Monthly Rent)
Renter (Renter Number, First Name, Last Name, Address, Telephone Number)
1.2.2. Обмеження, властиві файловим системам
Такого короткого опису файлових систем цілком достатньо для того, щоб зрозуміти суть властивих їм обмежень, що перераховані нижче.
• Поділ і ізоляція даних.
• Дублювання даних.
• Залежність від даних.
• Несумісність файлів.
• Фіксовані запити/швидке збільшення кількості програм.
Поділ і ізоляція даних
Коли дані ізольовані в окремих файлах, доступ до них дуже ускладнений. Наприклад, для створення списку всіх будинків, що відповідають вимогам потенційних орендарів, попередньо потрібно, створити тимчасовий файл зі списком орендарів, що бажають орендувати нерухомість типу "будинок". Потім у файлі “Власність_В_Оренду” варто здійснити пошук об'єктів нерухомості типу “будинок” орендною платою нижче встановленого орендарем максимуму. Виконувати подібну обробку даних у файлових системах досить складно. Для витягу відповідної поставленим умовам інформації програміст повинний організувати синхронну обробку двох файлів. Труднощі істотно зростають, коли необхідно витягти дані з більш ніж двох файлів.
Із за децентралізованої роботи з даними, проведеної в кожнім відділі незалежно від інших відділів, у файловій системі фактично заохочується безконтрольне дублювання даних, і це, у принципі, неминуче. Безконтрольне дублювання даних небажано по наступним двом причинам:
Дублювання даних супроводжується неощадливою витратою ресурсів, оскільки на введення надлишкових даних потрібно витрачати додаткові час і гроші. Більш того, для їхнього збереження необхідно додаткове місце в зовнішній пам'яті, що зв'язано з додатковими накладними витратами. У багатьох випадках дублювання даних можна уникнути за рахунок спільного використання файлів.
Ще більш важливим є той факт, що дублювання даних може привести до порушення їхньої цілісності. Інакше кажучи, дані, у різних відділах можуть стати суперечливими. Наприклад, розглянемо описаний вище випадок дублювання даних у розрахунковому секторі бухгалтерії і відділі кадрів. Якщо співробітник переїде в інший будинок і зміну адреси буде зафіксовано тільки у відділі кадрів, то повідомлення про зарплату буде надіслано йому за старою адресою, тобто помилковою. Більш серйозна проблема може виникнути, якщо деякий співробітник одержить підвищення по службі з відповідним збільшенням заробітної плати. І знову-ж, якщо цю зміну буде зафіксовано тільки в інформації відділу кадрів, залишившись не проведеним у файлах розрахункового сектора, те даний співробітник помилково буде одержувати колишню заробітну плату. При виявленні подібної помилки для її виправлення буде потрібно витратити додатковий час і засоби. Обидва цих приклади демонструють протиріччя, що можуть виникнути при дублюванні даних. Оскільки не існує ніякого автоматичного способу відновлення даних одночасно у файлах відділу кадрів, і у файлах розрахункового сектору, неважко передбачати, що подібні протиріччя час від часу обов'язково будуть виникати. Навіть якщо співробітники розрахункового сектора після одержання повідомлень про подібні зміни будуть негайно їх вносити, усе рівно існує імовірність неправильного введення змінених даних.