

14.6. Імітація вертикальної машини в адресному середовищі
Розглянемо концепцію надбудови інформаційної машини в адресному середовищі, тобто в архітектурі традиційного комп’ютера на базі ідеї віртуальної машини, що становить основну ідею qWord. Чому саме qWord? Просто це єдина відома нам (може і взагалі єдина) система такої властивості, що має і достатньо просту ідею і прозору реалізацію настільки, щоб на її базі спробувати пояснити хоч щось зрозуміле. Все інше достатньо складне, оснащене додатковими ідеями і умовностями і тому як початковий матеріал для концепції представляється просто безнадійним.
Але попереджаємо відразу!
При всій очевидній простоті ідеї, навіть примітивності, висловити її в осяжному обсязі матеріалу, так, щоб була ясна концепція в цілому вельми складно.
Доводиться тільки сподіватися на зацікавленість читача і те, що він має певне уявлення про пристрій і qWord і базової М-системи (нині званої Cache’). Щоб не редагувати раніше написаний текст збережемо колишню назву в цьому розділі як синонім.
Ідею або принцип побудови qWord можна зобразити у вигляді рис. 14.2.
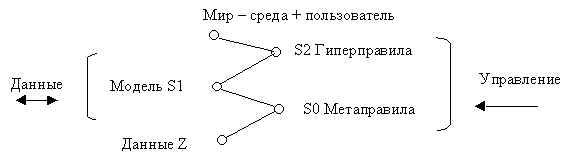
Рис.14.2 Пристрій qWord.
Дані Z – сукупність (бібліотека, банк даних) структур у М-системі.
S0 - метаправила, бібліотека програм, що породжують зв’язки між структурами Z; зауважимо – між структурами, тобто це “каталог бібліотеки”.
S1 – структура моделі даних, стан зв’язків, організуючих структури даних Z у “спостережувану модель” в кожному акті звернення до БД шляхом налагодження параметрів процедур із S0 і параметрів зв’язку між цими процедурами.
S2 – набір структур – гіперправил, що забезпечують вибір виду моделі залежно від конкретного акту звернення до БД і параметрів обігу.
Малюнок у цілому – “мнемоніка дії W-граматики”.
Спілкування з прикладною системою, створеною в середовищі qWord, відбувається шляхом навігації в моделі (або моделях) S1, яка де-факто є віртуальною, тобто в кожному акті спілкування спрацьовує конкретне налагодження однієї з множини моделей, при цьому самі структури даних Z не змінюються, тобто не переміщаються в пам’яті ні самі дані, ні зв’язки на рівні Z.
Сама ж модель “збирається” згідно гіперправилам S2 відповідно до запиту, або “успадковується” за умовчанням від попереднього сеансу.
Структура Z реалізується в М-системі {247. Строго за визначенням системи і мови М (В.Кирстен. “Від ANS MUMPS до ISO M-технології”, Видавництво СП.АРМ, СПб, 1995).} і, в загальному випадку, є деякою побудовою (рис. 14.3).

Рис. 14.3. Побудова структури Z
Z* (S) – двовимірне поле “власне даних”, фізичних записів;
S*(S1,S2) – ключ (в загальному випадку двовимірний);
N(P) – імена (узагальнені, залежні від параметрів).
Ім’я з параметрами задає значення ключа з поля S – поля значень ключів, а дані адресуються вже значеннями ключа.
Складніші структури надбудовуються за тією ж схемою.
Звернемо увагу, що поле значень ключів – віртуальне, задані лише його межі, граничні значення. Кількість полів S’ в S* визначається кількістю імен N(P), а “позиція” S’ в S* - значенням параметрів (Р) імені, тобто способом складання цього імені, але саме значення ключа при кожному зверненні до даних обчислюється інтерпретатором М-системи.
Сам список імен, словник системи – поле не віртуальне, а реальне, “часткова віртуальність” словника, тобто свобода, що дає можливість надбудовувати складніші структури, задається параметризацією. Таким чином є тришарова, трирівнева структура, що містить два рівні даних різного рангу “склеєних” віртуальним (процедурним) шаром, що забезпечує встановлення поточної відповідності між даними за допомогою інтерпретації.
Тим самим маємо функціонально-повну метаструктуру у визначенні за ТСУ, оскільки вона “мимовільно виникає” в будь-якій організованій системі. Структури S0 (метаправила) і S1 (“модель”) влаштовані так само, оскільки реалізовані теж в М-системі.
Кожна з них є процедурою (можливо складну, “зібрану” в процесі виконання), яка “зверху” одержує завдання (ім’я з параметризацією, деякий набір даних) і генерує “вниз” також набір даних (імен з параметрами).
Цей ланцюжок інтерпретації “закінчується внизу”, на рівні “власне даних” і забезпечує їх підстановку в спостережувану (в даному сеансі) модель даних. Тобто прикладна система в qWord є функціонально-повною системою класу И3 (в термінології ТСУ), що містить три рівні метаструктур стандартного тришарового типу {248. Цілком заслужено такі структури назвати структурами М-типу. Тим самим прийняти, що ці структури є не тільки умовністю формалізму М-мови за визначенням, наприклад, публікації В.Кірстена, але є об’єктивно загальнозначущими логічними структурами, реаліями самої природи, феномена інформації!}.
Наголосимо на важливому моменті: S0 і S1 – структури повністю віртуальні на відміну від базової – Z.
Для кожного акту звернення до БД інтерпретується тільки один набір параметрів S0, тобто тільки одна точка в багатовимірному просторі інтерпретації даних і лише одна точка – стан моделі S1 для всього сеансу (або частини сеансу).
У цілому віртуальною виявляється не тільки модель даних, але і реалізація цієї моделі. Треба відзначити, що ця віртуальність ніяк не позначається на, прикладних властивостях утиліт продукту, виконаного в qWord, якщо розглядати його як традиційну, звичну інформаційну систему баз даних, хоч би і дуже динамічну, здібну до існування в “вічнозеленому” режимі, в режимі безперервної зміни навіть самої моделі даних.
Це відбувається тому, що і механізм qWord і базові М-структури реалізовані по строгій логіці граматик, що породжують, що гарантує невиразність на рівні подання (зовнішнього) обчислюваних і запам’ятовуються значень, якщо ця відмінність не обумовлена і не відзначена спеціально.
Тобто основні якості продукту: можливість роботи на чисто логічному рівні моделі, позбавляюча користувача від необхідності “тримати в голові” всю ієрархію, механіку організації БД і можливість міняти чи будувати модель даних “по ходу роботи” абсолютно не залежать від “віртуальності реалізації” моделі.
Але всі спроби зробити систему “розумнішою”, наприклад, реалізувати властивість “самоструктурування”, тільки привели до переконання, що “рухатися нікуди”, неможливе її подальше принципове удосконалення.
З іншого боку з’явилося інтуїтивне переконання, що “власне дані” як би й ні при чому, структура прикладної ІС визначається тільки зв’язками.
І в цілому, загалом так воно і є:
“рухатися нікуди” тому, що структура функціонально повна, в ній і так вже є все, що встановлене
 ;
;“самоструктуруватися” не може, оскільки віртуальні структури (а дві метаструктури чисто віртуальні) дійсно нічого “самі зробити не можуть”;
нарешті, не тільки зв’язки”, але і зв’язки теж”.
Інакше кажучи, залишивши модель даних віртуальної по ідеї, треба зробити її реалізацію реальної, тобто декларативною структурою, або, з іншої точки зору, дати можливість системі “пам’ятати і відчувати саме себе і запам’ятовувати свій життєвий досвід” – а інакше “вчитися”, “самоорганізовуватися” просто ні на чому.
Тобто, крім структур S1 (моделі) і S0 (прив’язки моделі до даних), треба створити і підтримувати декларативні М структури, подібні Z, які і будуть “пам’яттю системи про себе самій”, її життєвим досвідом і матеріалом для самонавчання. Але, що істотне, за ієрархією не “над”, а “збоку”, а, значить, відповідно треба організувати і роботу цих структур.
Кожне ім’я (моделі і/або компоненти) забезпечується набором параметрів (імен), що є ключами. Значення ключів – значення параметрів.
Значення “власне даних” цього рівня – значення вхідних параметрів для наступного рівня S0. Сам рівень S0 повинен бути влаштований за тим же принципом.
Далі, аналогічно пристрою Z (базової М-структури), повинен бути реалізований працюючий скрито, за умовчанням, механізм балансування (симетризації) дерев, тобто структур, що запам’ятовують досвід, “історію життя”.
Абсолютно новий механізм, якого ні в М-системі, ні в qWord явно і автономно немає – механізм “вертикальної навігації”. Механізм цей повинен реалізовувати наступні задачі (роботи):
при кожному акті спілкування видавати реакцію автоматично на основі “моделі власного досвіду”, тобто поточного стану декларативного відображення S1 і S0, якщо явно не вказано, що цей акт спілкування є “показ нового”, навчання;
давати можливість прослідити, на рівні якої із структур S1, S0 або Z виникає невідповідність при незадовільній реакції системи, тобто система повинна уміти відповісти “незнайоме поняття”, не “знаю, як застосувати поняття”, або “немає фактичних даних”.
Зрозуміло, для цього треба розробити відповідний інтерфейс і головна проблема тут – подання як самих структур, так і їх ієрархії.
Якщо говорити про реалізацію, то, очевидно, що основна проблема і трудність якраз у виробленні цього уявлення, у виборі способів як “зобразити” багатовимірну модель даних, “модель інтерпретації моделі даних”, щоб від цього була реальна користь для користувача прикладної системи. Можна бути абсолютно упевненим, що робота з розробки такого інтерфейсу зажадає не менше зусиль і витрат, ніж потрібно для реалізації концепції, скажімо, WINDOWS.
Тут ми повинні припинити хід міркувань, щоб знову поставити ключове питання “навіщо?” Яку реальну користь можна отримати з дуже чималих затрат?
На рівні очевидності можна побачити тільки один аспект. Якщо ми маємо справу з розподіленою інформаційною системою, обслуговуючою достатньо складну, “багату” модель об’єкту (або сукупність об’єктів), то наявність декларативного подання моделі, її інтерпретації і їх історії дозволить вести поточний аналіз розподілу загального поля даних і зв’язків між його (поля) частинами.
А це прямо означає, що можна різко підвищити надійність системи і скоротити трафік переміщення масивів даних. Із законів структур напряму витікає, що в сталому режимі виявляються розподіленими, прив’язаними до локалізованих підсистем, загальний трафік обмінів при цьому складе в середньому 1/8 від загального обсягу даних, тобто 12,5%. Для порівняння – в мережній моделі даних середній трафік повинен складати більше 50% {249. Напевно в реалізації Cache’ якраз ця “багатовимірна модель” і реалізована, але, повторюємо, як – невідомо. Треба помітити, що в ефективності (економічності) якраз і прихована головна небезпека. Знижувати перепускну спроможність фізичних каналів до теоретичного рівня не можна, це може привести до руйнування системи. Середнє значення трафіка зовсім не гарантує від виникнення, хоча і рідкісного, критичних потоків того ж рівня, що і в повнозв’язній мережі (типу усі-зі-всіми).}. В решті аспектів і в осяжній перспективі користь від цієї моделі в основному пізнавальна ж.
Реалізація
всієї структури інформаційної системи
класу
![]() в декларативному, тобто в реальному, а
не віртуальному вигляді, створює основу
для подальшої надбудови “вертикальної
машини”.
в декларативному, тобто в реальному, а
не віртуальному вигляді, створює основу
для подальшої надбудови “вертикальної
машини”.
Шляхи і засоби достатньо добре відомі, вивчені і освоєні, залишається тільки вирішити сакраментальні питання – “навіщо і як цим користуватися?”.
Сподіватися на те, що можна побудувати інформаційні системи, що працюють в основному за рахунок “самонавчання в процесі” цілком можливо і реально, але це буде вже зовсім інша технологія інформаційних систем.
Наявність “дублюючої інформаційної вертикалі” – це можливість прямого програмування системи, тобто використання знайомих і якось освоєних технологій. У разі відмови від “процедурної вертикалі” треба створювати технологію (у великому, у значенні цілого) “вирощування, виховання і навчання” інформаційних систем. Кому, коли і навіщо це знадобиться? Але це питання не цієї книги.
Справа знову в узгодженні структур, які разом іменуються “сума технологій”. Повторимо знову наше заклинання: що є, то технологія, інше буде після, коли прийде час.
Знову, між реаліями життя і інженерною реалізацією проекту системи, для “фундаментальної аксіоматичної теорії” не залишається місця, сам проект, його реалізація – він сам для себе і “фундаментальна теорія” теж.
Le meilleur des mondes possibles.
{250. Якнайкращий з можливих світів (фр.),
А. Шопенгауер, Світ як воля.}