

Лекции по сетям ЭВМ / Лекция 16
.doc
Л
 екция
6: Избыточное
кодирование в цифровых каналах связи
екция
6: Избыточное
кодирование в цифровых каналах связи
(4 часа)
План занятия:
|
Время |
№ п/п |
Содержание раскрываемого вопроса: |
|
35 мин. |
1. |
Принципы помехоустойчивого кодирования |
|
35 мин. |
2. |
Перемежение канальных кодов в каналах с замираниями |
1. Принципы помехоустойчивого кодирования
В каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно.
Для того чтобы код обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность.
Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно.
Принципы помехоустойчивого кодирования
В
теории помехоустойчивого кодирования
важным является вопрос об использовании
избыточности для корректирования
возникающих при передаче ошибок. Здесь
удобно рассмотреть блочные моды, в
которых всегда имеется возможность
выделить отдельные кодовые комбинации.
Напомним, что для равномерных кодов,
которые в дальнейшем только и будут
изучаться, число возможных комбинаций
равно
![]() ,
где
п
–
значностъ кода. B
обычном некорректирующем коде без
избыточности, например, в коде Бодо
число комбинаций М
выбирается
равным числу сообщений алфавита источника
Мо
и
все комбинации используются для передачи
информации. Корректирующие коды строятся
так, чтобы число комбинаций М
превышало
число сообщений источника М0.
Однако в этом случае лишь М0
комбинаций
из общего числа используется для передачи
информации. |Эти комбинации называются
разрешенными,
а
остальные М-М0
комбинаций
носят название запрещенных.
На
приемном конце в декодирующем устройстве
известно, какие комбинации являются
разрешенными и какие запрещенными.
Поэтому если переданная разрешенная
комбинация в результате ошибки
преобразуется в некоторую запрещенную
комбинацию, то такая ошибка будет
обнаружена, а при определенных условиях
исправлена. Естественно, что ошибки,
приводящие к образованию другой
разрешенной комбинации, не обнаруживаются.
,
где
п
–
значностъ кода. B
обычном некорректирующем коде без
избыточности, например, в коде Бодо
число комбинаций М
выбирается
равным числу сообщений алфавита источника
Мо
и
все комбинации используются для передачи
информации. Корректирующие коды строятся
так, чтобы число комбинаций М
превышало
число сообщений источника М0.
Однако в этом случае лишь М0
комбинаций
из общего числа используется для передачи
информации. |Эти комбинации называются
разрешенными,
а
остальные М-М0
комбинаций
носят название запрещенных.
На
приемном конце в декодирующем устройстве
известно, какие комбинации являются
разрешенными и какие запрещенными.
Поэтому если переданная разрешенная
комбинация в результате ошибки
преобразуется в некоторую запрещенную
комбинацию, то такая ошибка будет
обнаружена, а при определенных условиях
исправлена. Естественно, что ошибки,
приводящие к образованию другой
разрешенной комбинации, не обнаруживаются.
Различие
между комбинациями равномерного кода
принято характеризовать расстоянием,
равным
числу символов, которыми отличаются
комбинации одна от другой. Расстояние
![]() между
двумя комбинациями
между
двумя комбинациями
![]() и
и
![]() определяется
количеством единиц в сумме этих комбинаций
по модулю два. Например,
определяется
количеством единиц в сумме этих комбинаций
по модулю два. Например,
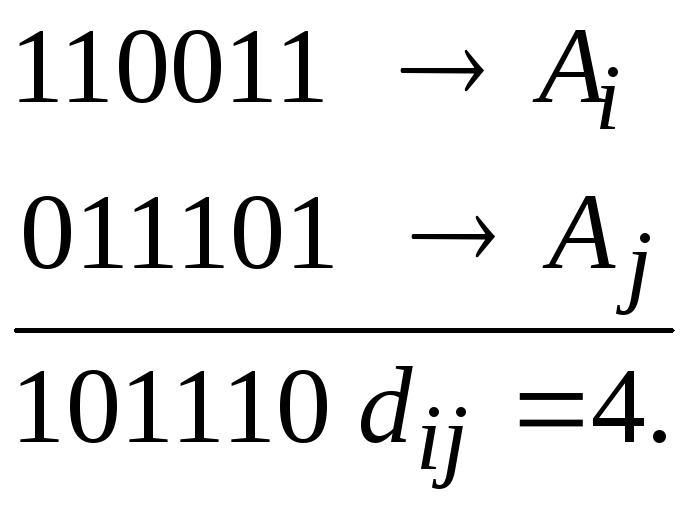
Для
любого кода
![]() .
Минимальное
расстояние между разрешенными комбинациями
в данном коде называется кодовым
расстоянием d
(Хеминговым расстоянием).
.
Минимальное
расстояние между разрешенными комбинациями
в данном коде называется кодовым
расстоянием d
(Хеминговым расстоянием).
Расстояние
между комбинациями
![]() и
и
![]() условно обозначено на рис. 1а, где показаны
промежуточные комбинации, отличающиеся
друг от друга одним символом. B
общем случае некоторая пара разрешенных
комбинаций Ар1
и Ар2,
разделенных кодовым расстоянием d,
изображается
на прямой рис. 1б, где точками указаны
запрещенные комбинации. Для того чтобы
в результате ошибки комбинация Ар1
преобразовалась
в другую разрешенную комбинацию Ар2,
должно
исказиться d
символов.
При искажении меньшего числа символов
комбинация Aр1
перейдет
в запрещенную комбинацию и ошибка будет
обнаружена. Отсюда следует, что ошибка
всегда обнаруживается, если ее кратность,
т. е. число искаженных символов в кодовой
комбинации,
условно обозначено на рис. 1а, где показаны
промежуточные комбинации, отличающиеся
друг от друга одним символом. B
общем случае некоторая пара разрешенных
комбинаций Ар1
и Ар2,
разделенных кодовым расстоянием d,
изображается
на прямой рис. 1б, где точками указаны
запрещенные комбинации. Для того чтобы
в результате ошибки комбинация Ар1
преобразовалась
в другую разрешенную комбинацию Ар2,
должно
исказиться d
символов.
При искажении меньшего числа символов
комбинация Aр1
перейдет
в запрещенную комбинацию и ошибка будет
обнаружена. Отсюда следует, что ошибка
всегда обнаруживается, если ее кратность,
т. е. число искаженных символов в кодовой
комбинации,
![]() . (1)
. (1)

Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация в этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d = 2.
Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
![]() ,
(2)
,
(2)
где
Ро
–
вероятность искажения одного символа.
Так как обычно
![]() ,
то вероятность многократных ошибок
уменьшается с увеличением их кратности,
при этом более вероятны меньшие расстояния
do.
В
этих условиях исправление ошибок может
производиться по следующему правилу.
Если принята запрещенная комбинация,
то считается переданной ближайшая
разрешенная комбинация. Например, пусть
образовалась запрещенная комбинация
Ао
(см.
рис. 26), тогда принимается решение, что
была передана комбинация Ap1.
Это
правило декодирования для указанного
распределения ошибок является оптимальным,
так как оно обеспечивает исправление
максимального числа ошибок. Напомним,
что аналогичное правило используется,
в теории потенциальной помехоустойчивости
при оптимальном приеме дискретных
сигналов, когда решение сводится к
выбору того переданного сигнала, который
в наименьшей степени отличается от
принятого. Нетрудно определить, что при
таком правиле декодирования будут
исправлены все ошибки кратности
,
то вероятность многократных ошибок
уменьшается с увеличением их кратности,
при этом более вероятны меньшие расстояния
do.
В
этих условиях исправление ошибок может
производиться по следующему правилу.
Если принята запрещенная комбинация,
то считается переданной ближайшая
разрешенная комбинация. Например, пусть
образовалась запрещенная комбинация
Ао
(см.
рис. 26), тогда принимается решение, что
была передана комбинация Ap1.
Это
правило декодирования для указанного
распределения ошибок является оптимальным,
так как оно обеспечивает исправление
максимального числа ошибок. Напомним,
что аналогичное правило используется,
в теории потенциальной помехоустойчивости
при оптимальном приеме дискретных
сигналов, когда решение сводится к
выбору того переданного сигнала, который
в наименьшей степени отличается от
принятого. Нетрудно определить, что при
таком правиле декодирования будут
исправлены все ошибки кратности
![]() .
(3)
.
(3)
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3.
Возможно
также построение таких кодов, в которых
часть ошибок исправляется, а часть
только обнаруживается. Так, в соответствии
с рис. 2в ошибки кратности
![]() исправляются, а ошибки, кратность которых
лежит в пределах
исправляются, а ошибки, кратность которых
лежит в пределах
![]() ,
только
обнаруживаются. Что касается ошибок,
кратность которых сосредоточена в
пределах
,
только
обнаруживаются. Что касается ошибок,
кратность которых сосредоточена в
пределах
![]() ,
то
они обнаруживаются, однако при их
исправлении принимается ошибочное
решение – считается переданной комбинация
Ар2
вместо Aр1
или
наоборот.
,
то
они обнаруживаются, однако при их
исправлении принимается ошибочное
решение – считается переданной комбинация
Ар2
вместо Aр1
или
наоборот.
Существуют
двоичные системы связи, в которых
решающее устройство выдает, кроме
обычных символов 0 и 1, еще так называемый
символ стирания
![]() .
Этот символ соответствует приему
сомнительных сигналов, когда затруднительно
принять определенное решение в отношении
того, какой из символов 0 или 1 был передан.
Принятый символ в этом случае стирается.
Однако при использовании корректирующего
кода возможно восстановление стертых
символов. Если в кодовой комбинации
число символов
.
Этот символ соответствует приему
сомнительных сигналов, когда затруднительно
принять определенное решение в отношении
того, какой из символов 0 или 1 был передан.
Принятый символ в этом случае стирается.
Однако при использовании корректирующего
кода возможно восстановление стертых
символов. Если в кодовой комбинации
число символов
![]() оказалось равным gc,
причем
оказалось равным gc,
причем
![]() ,
(4)
,
(4)
а
остальные символы приняты без ошибок,
то такая комбинация полностью
восстанавливается. Действительно, для
восстановления всех символов
![]() необходимо перебрать всевозможные
сочетания из gc
символов
типа 0 и 1. Естественно, что все эти
сочетания, за исключением одного, будут
неверными. Но так как в неправильных
сочетаниях кратность ошибок
необходимо перебрать всевозможные
сочетания из gc
символов
типа 0 и 1. Естественно, что все эти
сочетания, за исключением одного, будут
неверными. Но так как в неправильных
сочетаниях кратность ошибок
![]() ,
то согласно неравенству (1) такие ошибки
обнаруживаются. Другими словами, в этом
случае неправильно восстановленные
сочетания из gc
символов
совместно с правильно принятыми символами
образуют запрещенные комбинации и
только одно сочетание стертых символов
даст разрешенную комбинацию, которую
и следует считать как правильно
восстановленную.
,
то согласно неравенству (1) такие ошибки
обнаруживаются. Другими словами, в этом
случае неправильно восстановленные
сочетания из gc
символов
совместно с правильно принятыми символами
образуют запрещенные комбинации и
только одно сочетание стертых символов
даст разрешенную комбинацию, которую
и следует считать как правильно
восстановленную.
Если gc>d-1, то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие коды обычно используются для корректирования ошибок малой кратности.
Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М0 увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
![]() , (5)
, (5)
что, в свою очередь, требует избыточного числа символов r=n-k, где k – количество символов в комбинации кода без избыточности. Можно ввести понятие .избыточности кода и количественно определить ее как
![]() , (6)
, (6)
При
независимых ошибках
вероятность определенного сочетания
g
ошибочных
символов в n-значной
кодовой комбинации выражается формулой
(2), а количество всевозможных сочетаний
g
ошибочных
символов в комбинации зависит от ее
длины и определяется известной формулой
числа сочетаний
![]() .
Отсюда
полная вероятность ошибки кратности
g,
учитывающая
все сочетания ошибочных символов,
равняется
.
Отсюда
полная вероятность ошибки кратности
g,
учитывающая
все сочетания ошибочных символов,
равняется
![]() (7)
(7)
Используя (7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
![]()
и вероятность правильного корректирования ошибок
![]() .
.
Здесь суммирование производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
![]() .
(8)
.
(8)
Анализ формулы (8) показывает, что при малой величине Ро и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь.
Вероятность
Рош,
избыточность
![]() и число символов п
являются
основными характеристиками корректирующего
кода, определяющими, насколько удается
повысить помехоустойчивость передачи
дискретных сообщений и какой ценой это
достигается.
и число символов п
являются
основными характеристиками корректирующего
кода, определяющими, насколько удается
повысить помехоустойчивость передачи
дискретных сообщений и какой ценой это
достигается.
Общая
задача, которая ставится при создании
кода, заключается в достижении наименьших
значений Рош
и
![]() .
Целесообразность применения того или
иного кода зависит также от сложности
кодирующих и декодирующих устройств,
которая, в свою очередь, зависит от п.
Во
многих практических случаях эта сторона
вопроса является решающей. Часто,
например, используются коды с большой
избыточностью, но обладающие простыми
правилами кодирования и декодирования.
.
Целесообразность применения того или
иного кода зависит также от сложности
кодирующих и декодирующих устройств,
которая, в свою очередь, зависит от п.
Во
многих практических случаях эта сторона
вопроса является решающей. Часто,
например, используются коды с большой
избыточностью, но обладающие простыми
правилами кодирования и декодирования.
В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках.
В настоящее время известно большое количество корректирующих кодов, отличающихся как принципами построения, так и основными характеристиками. Рассмотрим их простейшую классификацию, дающую представление об основных группах, к которым принадлежит большая часть известных кодов. На рис. 2 показана схема, поясняющая классификацию, проведенную по способам построения корректирующих кодов.
Все известные в настоящее время коды могут быть разделены на две большие группы: блочные и непрерывные. Блочные коды: характеризуются тем, что последовательность передаваемых символов разделена на блоки. Операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно.
Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов.
В свою очередь, линейные коды могут быть разбиты на два подкласса: систематические и несистематические. Bce двоичные систематические коды являются групповыми. Последние характеризуются принадлежностью кодовых комбинаций к группе, обладающей тем свойством, что сумма по модулю два любой пары комбинаций снова дает комбинацию, принадлежащую этой группе. Линейные коды, которые не могут быть отнесены к подклассу систематических, называются несистематическими.
2. Межсимвольное перемежение канального кода
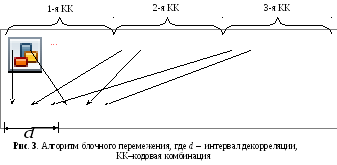
Известно, что перемежение представляет собой эффективный метод борьбы с группирующимися ошибками в канале с замираниями. Идея метода заключается в «рассеянии» символов кодовой комбинации (рис. 3): символы должны находиться друг от друга на таком расстоянии [называемом интервалом декорреляции ошибок d (см. рис. 3)], чтобы быть подверженными независимым замираниям. При независимых замираниях символы, пораженные пакетом ошибок, распределяются по всему сообщению, и появляется возможность восстановить данные с помощью исходного кода, исправляющего ошибки.
Известно несколько типов перемежителей, реализующих диагональное, межблоковое, блоковое перемежение и др. варианты.
Наиболее простым является реализация блокового перемежения, строящая на принципе формирования прямоугольной матрицы (рис. 4), состоящей из n-разрядных строк (n – длина кодовой комбинации), с которой осуществляется поразрядной считывание каждого столбца через d разрядов (размер блока определяет интервал декорреляции ошибок).
О ценка
эффективности перемежения
ценка
эффективности перемежения
Учитывая использование каналов связи действующих радиолиний с малой избыточностью, рассмотрим вариант без избыточного кода. В случае без избыточного канального кода вероятность ошибки приема кодовой комбинации в канале с релеевскими замираниями определяется обобщенным выражением
![]() ,
(9)
,
(9)
где
![]() –
априорная вероятность попадания
–
априорная вероятность попадания
![]() – бита кодовой комбинации на участок
замирания;
– бита кодовой комбинации на участок
замирания;
![]() –
априорная вероятность попадания
–
априорная вероятность попадания
![]() – бита кодовой комбинации на участок
усиления;
– бита кодовой комбинации на участок
усиления;
![]() – условная вероятность безошибочного
приема одного бита информации при
условии попадания
– условная вероятность безошибочного
приема одного бита информации при
условии попадания
![]() -го
бита кодовой комбинации на участок
замирания;
-го
бита кодовой комбинации на участок
замирания;
![]() ,
где
,
где
![]() определяется видом манипуляции;
определяется видом манипуляции;
![]() – условная вероятность безошибочного
приема одного бита информации при
условии попадания
– условная вероятность безошибочного
приема одного бита информации при
условии попадания
![]() -го
бита кодовой комбинации на участок
усиления;
-го
бита кодовой комбинации на участок
усиления;
![]() ,
где
,
где
![]() определяется видом манипуляции;
определяется видом манипуляции;
![]() – длина кодовой комбинации.
– длина кодовой комбинации.
О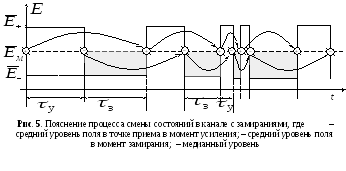 пределим
априорные вероятности
пределим
априорные вероятности
![]() и
и
![]() .
Для разработанной модели интервалы
участков замирания и усиления следуют
строго последовательно друг за другом.
При этом сами интервалы распределены
по экспоненциальному закону с
интенсивностью смены
.
Для разработанной модели интервалы
участков замирания и усиления следуют
строго последовательно друг за другом.
При этом сами интервалы распределены
по экспоненциальному закону с
интенсивностью смены
![]() (рис.
5).
(рис.
5).
Следовательно,
поток переключений в то или иное состояние
радиоканала будет пуассоновским. Исходя
из этого, число смен состояний
![]() на определенном интервале времени
на определенном интервале времени
![]() будет распределено по закону Пуассона:
будет распределено по закону Пуассона:
![]() .
(10)
.
(10)
На
основе формулы (10) определена вероятность
попадания
![]() -го
бита кодовой комбинации на интервал
замирания и усиление (см. рис. 5), в
результате получим:
-го
бита кодовой комбинации на интервал
замирания и усиление (см. рис. 5), в
результате получим:
![]() .
(11)
.
(11)
Следует
заметить, что при
![]() ,
,
![]() ,
в связи с чем выражение (11) можно заменить
приближенной формулой
,
в связи с чем выражение (11) можно заменить
приближенной формулой
![]() .
(12)
.
(12)
В частности, для ЧМ2 данное выражение примет вид (рис. 6):
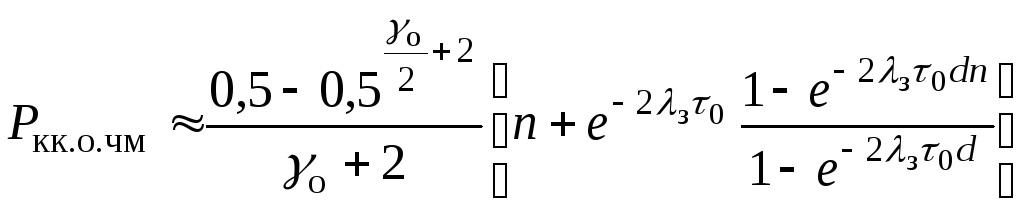 .
.
И з
рис. 6 видно, что крутизна спада при
перемежении достигается на более высоких
скоростях манипуляции, исходя из чего
следует, что использование метода
перемежения будет наиболее эффективным
при наименьших значениях
з
рис. 6 видно, что крутизна спада при
перемежении достигается на более высоких
скоростях манипуляции, исходя из чего
следует, что использование метода
перемежения будет наиболее эффективным
при наименьших значениях
![]() .
.
-
Наибольшая эффективность межсимвольного перемежения достигается при большей скорости манипуляции и меньшей длине канального кода. При этом требуется решать компромисс, так как для достижения максимального выигрыша большей скорости манипуляции соответствует большая длина канального кода.
-
Канальным кодам меньшей длины соответствует больший интервал декорреляции, т.е. с увеличением длины кода эффективность использования метода межсимвольного перемежения в декаметровых радиоканалах снижается.
© Орощук И.М.
Орощук И.М.