

Протокол smtp (Simple Mail Transfer Protocol)
Разработан для обмена почтовыми сообщениями в Internet. SMTP не зависит от транспортной среды и может использоваться для доставки почты в сетях с протоколами, отличными от TCP/IP.
Взаимодействие в рамках SMTP строится по принципу двусторонней связи, которая устанавливается между отправителем и получателем почтового сообщения. При этом отправитель инициирует соединение и посылает запросы на обслуживание, а получатель - отвечает на эти запросы. Фактически отправитель выступает в роли клиента, а получатель - сервера.
Канал связи устанавливается непосредственно между отправителем и получателем сообщения. При таком взаимодействии почта достигает абонента в течении нескольких секунд после отправки.
В список дисциплин, разрешенных SMTP, входит, кроме отправки почты, еще и прямая рассылка сообщений. В этом случае сообщение будет отправляться не в почтовый ящик, а непосредственно на терминал пользователя, если пользователь в данный момент находится за своим терминалом.
Для отладки или проверки соединения по SMTP можно использовать telnet. Для этого вслед за адресом машины следует ввести номер порта, например:
telnet mail.biysk.ru 25
25-ый порт используется в Internet для обмена сообщениями по протоколу SMTP. В интерактивном режиме пользователь сам изображает клиента SMTP и может просмотреть реакцию удаленной машины на его действия.
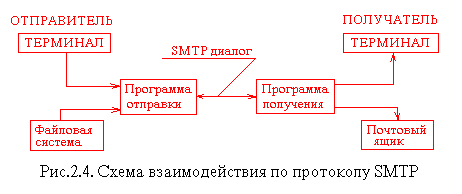
Почтовый клиент
Outlook Express.
Структура экрана.
Почтовый клиент
Outlook Express.
Экран письма при его просмотре.
Почтовый клиент
Outlook Express.
Подготовка письма
Почтовый клиент
Outlook Express.
Подготовка ответа (ответ автору письма).
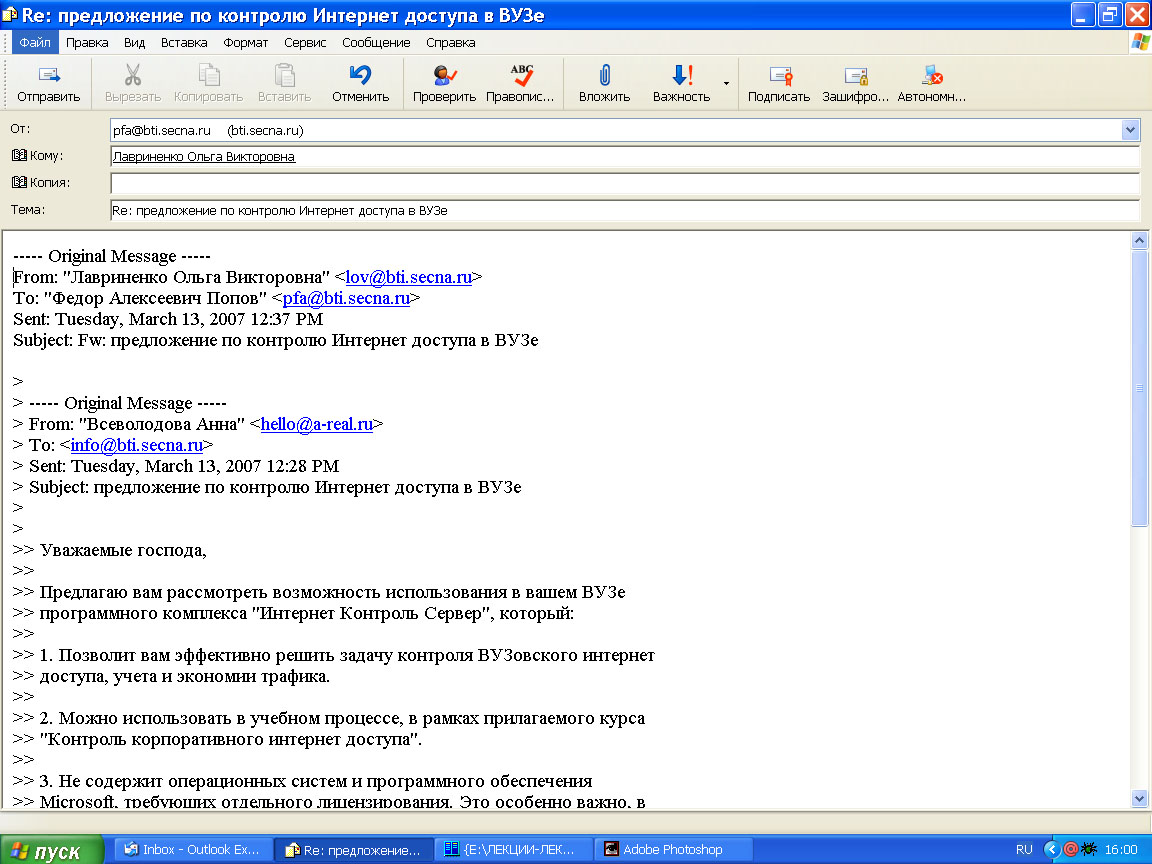
Почтовый клиент
Outlook Express.
Подготовка ответа (ответ всем – автору и получателям).
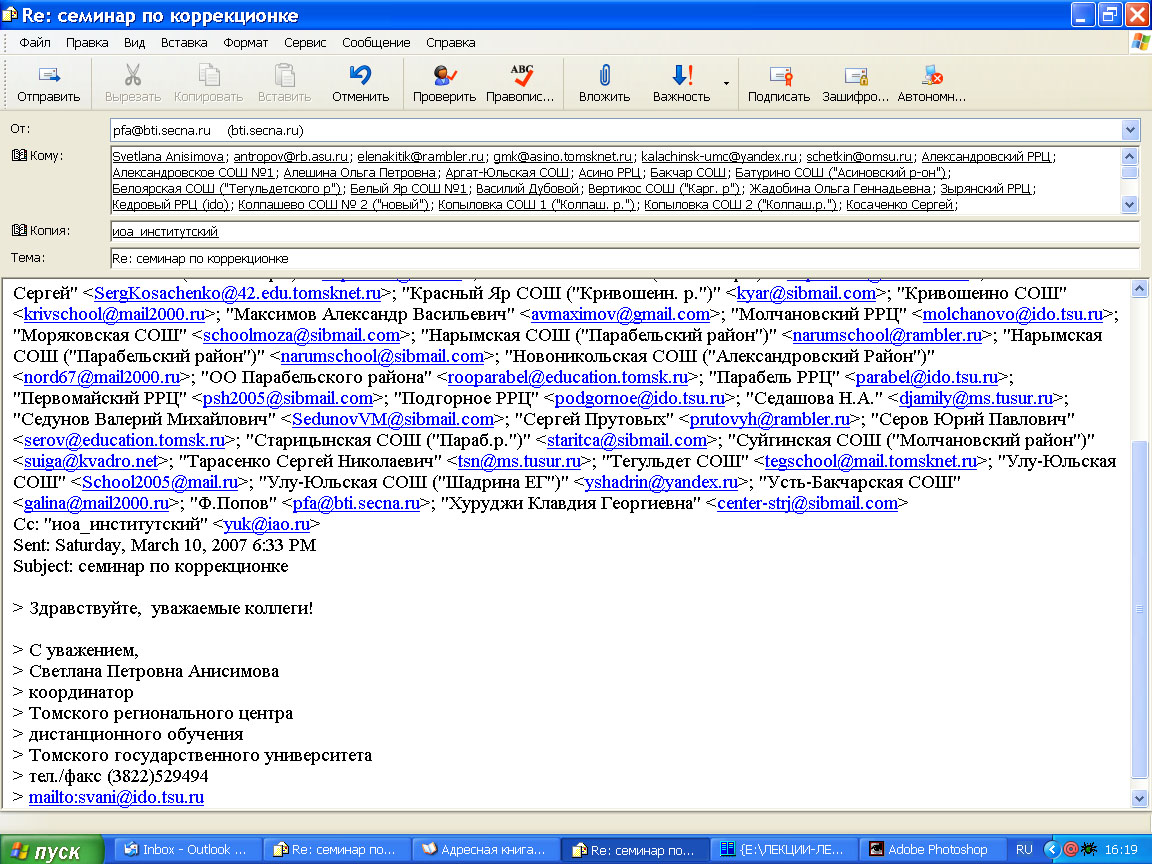
Почтовый клиент
Outlook Express.
Адресная книга.
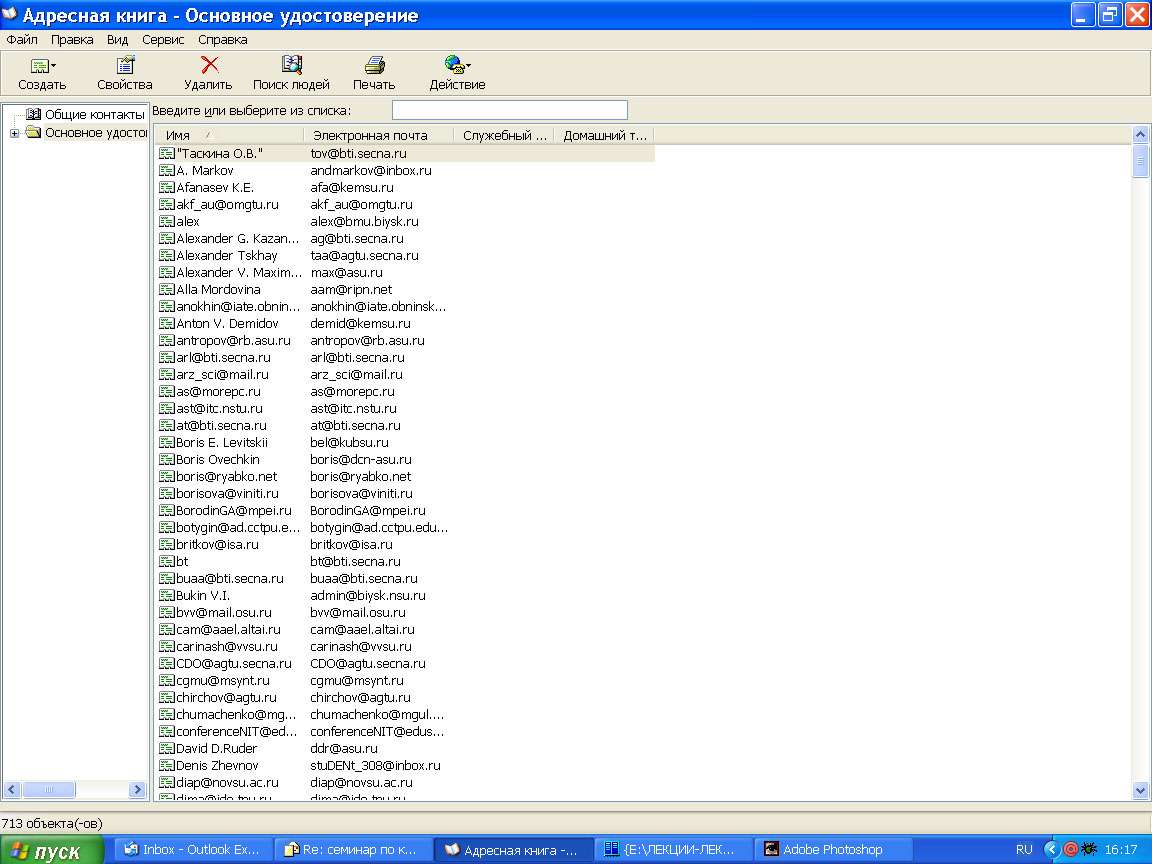
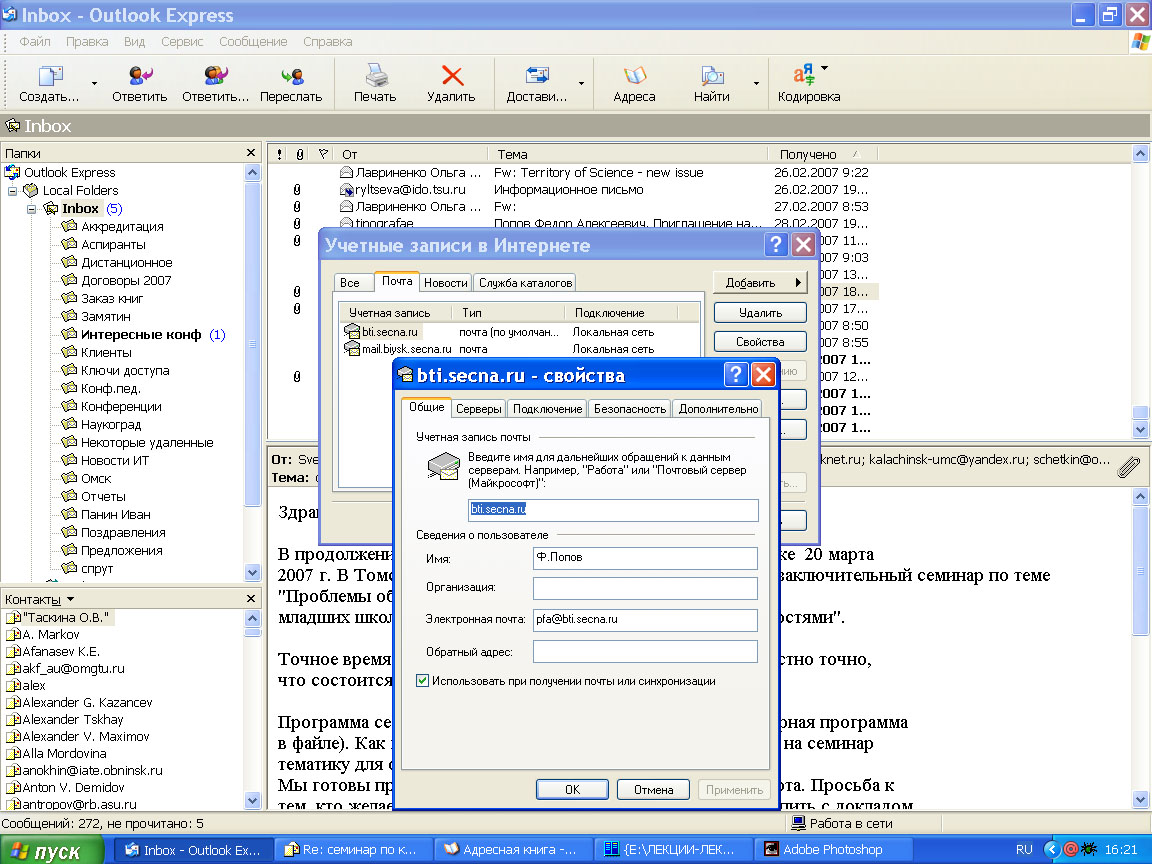
Почтовый клиент
Outlook Express.
Учетные записи.
Первоначальная настройка.
Форматы текстовых и графических файлов
Текстовые файлы— наиболее распространенный тип данных не только в Internet, но и во всем компьютерном мире. Существуют два фактора, осложняющих работу с текстами.
Первый— чрезвычайно большое количество символов, требующихся для поддержки различных языков. Американские программисты для работы со 128 символами используют набор символов US ASCII. Важно помнить, что более 250 символов необходимы только для того, чтобы управиться с парой десятков европейских языков, базирующихся на латинском алфавите. Для поддержки других алфавитов — кириллицы, греческого, иврита, арабского, санскрита и т. д. — дополнительно требуется еще более сотни символов, китайский, японский и корейский языки добавляют к этому списку еще более десяти тысяч иероглифов.
Другая сложность - чисто текстовые данные встречаются все реже. Распечатываемые документы содержат графики, диаграммы, примечания, заголовки и при этом используются различные шрифты. Онлайновые документы, в свою очередь, могут включать мультипликацию, ссылки на сетевые базы данных и звуковое сопровождение. В результате комбинации различных типов данных образуются документы мультимедиа. Текстовый формат — так как он обычно используется как базовый — является стартовой точкой многих форматов документов мультимедиа. Многие из тех форматов, о которых пойдет речь ниже — не просто текстовые форматы, более корректно их следовало бы называть форматами документа. Подобные форматы предоставляют остов для комбинирования текстовых, графических и других форм данных.
Большинство пользователей уверены в том, что А и А это один и тот же символ, несмотря на то, что выглядят они по разному. Для уточнения внешнего вида соответствующего символа используют термин глиф. Так, несмотря на то, что все эти глифы А, А, А, А, А, А, представляют собой один и тот же символ, видно, что они разные. Говоря более точно, глиф — это специфическае визуальное представление символа.
Как правило, нужно, чтобы смотрелся хорошо весь текст, а не один знак, то есть имеет смысл говорить о подборке символов. В американском английском она должна содержать пятьдесят две прописных и строчных символа, десять цифр и знаки пунктуации. Такую подборку называют репертуаром (repertoire), соответствующий набор глифов, по одному для каждого из символов, называют шрифтом.
В разных странах и языках используются различные репертуары символов. Удобнее всего использовать для кодирования символов числа от нуля до 255 (всевозможные значения одного байта). Правда, имея в распоряжении только 256 чисел, нельзя дать уникальный код любому символу. Поэтому были разработаны различные наборы кодов символов. Набор кодов символов ISO Latin 1 был создан организацией ISO (International Organization for Standardization, Международная организация по стандартизации) для представления всех символов, необходимых для языков, использующих латинский алфавит. Прочие наборы кодов пытаются охватить другие группы символов.
Самый простой способ кодирования символов базируется на едином наборе кодов символов, содержащим 256 (или менее) кодов. В текстовом файле, закодированным таким образом, можно взять любой байт и посмотреть в таблице, какой символ соответствует этому значению байта. Если один текстовый файл использует сразу несколько наборов кодов символов, все усложняется. В этом случае должны использоваться специальные коды символов, информирующие программу просмотра файла о том, когда она должна переключиться на другой набор кодов символов. В международном стандарте ISO 2022 описывается один из способов переключения между наборами кодов символов. Отметим, что в этом случае просмотреть правильно содержимое файла можно только с его начала!
Такие языки, как китайский, содержат значительно больше 256 символов, поэтому для кодирования каждого из них используют несколько байтов. При таком кодировании используются разнообразные подходы. В одном из вариантов каждому символу соответствует один байт, а для представления всего спектра символов используется несколько наборов кодов. При другом подходе каждому символу соответствует несколько байтов. Для экономии места зачастую эти два подхода комбинируются: некоторые символы кодируются с помощью одного байта, другие - двух или более байтов.
Обобщеним этих подходов является стандарт Unicode (ISO 10646). В Unicode для кодирования символов используется диапазон чисел от нуля до 65 536. Такой широкий диапазон позволяет представлять в численном виде символы языка людей из любого уголка планеты. Многие международные стандарты для обеспечения поддержки нескольких языков стремятся к соблюдению Unicode.
Текстовые файлы могут содержать простые (plain text) или размеченные тексты (markup text).
Существует два способа разметки - физическая и логическая. При использовании физической разметки указывается точный вид каждого фрагмента текста. Например, «центрованный текст, 14-м кеглем, жирный, сжатый, гарнитура Futura». При логической разметке текста указывается логическое значение данного фрагмента, например, «это заголовок главы».
Эти два способа предназначаются для использования в разных ситуациях. Чтобы распечатать текст на принтере, необходимо использовать физическую разметку. То есть должно быть принято решение о размере полей, формате примечаний, а также о величине абзацного отступа в начале каждого параграфа.
При обмене информацией используют логическое оформление текста. При печати документа или выводе его на экран логический формат будет конвертироваться в соответствующий физический формат. Логическое оформление крайне важно, например, в случае обмена электронными документами или при создании и публикации объемных трудов. Многие издатели хранят книги в электронном виде, используя SGML (Standard Generic Markup Language, стандартный обобщенный язык разметки документов). Это помогает упростить процесс создания книги, позволяет легко изменять размер книги и ее формат, обеспечивает независимость от оборудования печати.
Преобразование логической разметки в физическую осуществляется с помощью таблицы стилей (style sheet). В таблице стилей просто перечисляются способы отображения каждого логического элемента.
Для сохранения разметки можно использовать один из трех подходов.
Можно сохранить разметку, включив ее описание в текст. Например, представив фрагмент текста: «...принять правильное решение ...» в виде «... принять <bold> правильное <endbold> решение...». Преимущество такого подхода в том, что файл по-прежнему остается текстовым и его легко передавать с компьютера на компьютер. Наиболее известные способы разметки:
• HyperText Markup Language (HTML), использующийся в Worid Wide Web,
• TROFF, применяющийся в документации Unix,
• SGML (Standard Generic Markup Language).
Можно сохранить разметку, передавая изображение каждой страницы. Таким образом работают факс-машины, они создают графическое изображение каждой страницы и передают его. Популярным форматом для такого представления документов является PostScript. Несмотря на то, что это текстовый формат, его крайне сложно преобразовать таким образом, чтобы содержимое файла можно было отредактировать.
Третий способ сохранения разметки— разработка особых файлов, содержащих не только текст, но и информацию о том, как он должен быть оформлен. Большинство текстовых процессоров и настольных издательских систем используют такой подход. Основная сложность заключается в том, что в результате почти все текстовые процессоры и настольные издательские системы используют свои форматы.