

1) Методы статистического описания
Наиболее простой случай возникает тогда, когда наши данные могут быть представлены одной переменной. Используемые для этого методы объединяются в группу под названием одномерный статистический анализ.
Одномерный статистический анализ. Данный анализ включает в себя анализ распределения частот; расчет данных о распределении переменной, представленных в форме графиков; оценку параметров распределения (меры центральной тенденции и меры рассеяния).
1) Достаточно простым и удобным приемом анализа количественных данных является построение распределения частот. В зависимости от используемой шкалы применяют разные методы. Для шкалы наименований подсчитывают число ответов в каждом классе и строят таблицу распределения.
Например, переменная «Семейное положение» может принимать следующие значения: женат/замужем, холост/не замужем, разведен/разведена, вдовец/вдова.
Предположим, всего было 30 респондентов, и один из них отказался отвечать на данный вопрос. Тогда таблица распределения частот, выраженных в абсолютных и относительных числах (доли, проценты), может иметь следующий вид.
Таблица 9
Семейное положение |
Частоты |
Доли |
Проценты |
Женат/замужем |
16 |
0,53 |
53,3 (55,2) |
Холост/не замужем |
4 |
0,13 |
13,3 (13,8) |
Разведен/разведена |
7 |
0,23 |
23,3 (24,1) |
Вдова/вдовец |
2 |
0,07 |
6,7 (6,9) |
Данные отсутствуют |
1 |
0,03 |
3,3 |
Всего |
30 |
1,0 |
99,9 (100) |
Анализируя таблицу, мы сравниваем между собой категории и видим, как они представлены в нашей выборке. Нас чаще всего интересуют не абсолютные значения, а относительные (доли, проценты). Тогда хорошо видно, что в нашей выборке немногим более половины респондентов находятся в браке, а около четверти – в разводе. Относительные значения удобны еще и тем, что позволяют легко сопоставлять данные по двум выборкам разного объема. Если выборки различаются размерами, то мы предварительно вычисляем относительные значения, а затем сравниваем.
Процентное выражение предпочтительнее доли, поскольку с целыми числами работать удобнее, чем с дробями. Но по существу проценты и доли – это эквивалентные единицы наподобие рубля и копейки. Относительные единицы позволяют сравнивать не только аналогичные показатели, полученные на разных выборках, но и качественно различные показатели между собой. Последний столбец в таблице 9 представляет данные в процентах. Обратим внимание, что итог у нас оказался несколько меньше ста процентов из-за округлений при вычислениях. Поскольку данные по одному индивиду отсутствуют, можно пересчитать проценты без этой пустой категории, полагая теперь N = 29 (объем выборки принято обозначать латинской буквой N). Скорректированные данные представлены в скобках.
Для шкалы порядка и интервальной шкалы обычно данные представляют в сгруппированном виде, так как иначе образуется очень много классов. Например, мы исследуем возрастной состав той же группы из тридцати человек. Если она не однородна в этом отношении, данные окажутся «размазанными». Тогда мы их группируем, выбирая определенный интервал (обычно десять лет), и вносим в таблицу обобщенные данные. Интервал (шаг) выбирается с учетом характера данных и задач анализа. Отметим, что группировка данных приводит к потере части информации. Но зато мы добиваемся ее лучшей обозримости. Таблица распределения, которая в результате получится, может выглядеть следующим образом.
Таблица 10
Данные о возрастном составе группы
Возрастная группа |
Частоты |
% |
Накопленные частоты |
Накопленные % |
20–29 |
12 |
40,0 |
12 |
40,0 |
30–39 |
8 |
26,7 |
20 |
66,7 |
40–49 |
5 |
16,7 |
25 |
83,4 |
50–59 |
3 |
10,0 |
28 |
93,4 |
60–69 |
2 |
6,7 |
30 |
100,1 |
Всего |
30 |
100,1 |
30 |
100,1 |
В первом столбце представлены возрастные интервалы. Обратим внимание, что они не пересекаются. Во втором и третьем столбцах, соответственно, – частоты и проценты. Глядя на них, мы видим, что возрастной состав группы неоднородный: в ней преобладают молодые люди. В четвертом и пятом столбцах частоты и проценты отображены в суммарной форме, которая применима для упорядоченных шкал (порядка, интервалов). Частоты и проценты суммируются по всем предыдущим категориям. При такой форме представления данных хорошо видно, сколько человек или какая доля выборки находятся ниже (или выше) определенного уровня. В нашем примере 25 человек из 30, или 83,4 %, моложе пятидесяти лет.
2) Данные о распределении переменной представляем в форме графиков. Рассмотрим четыре типа графиков, которые чаще всего используются в случае одномерного распределения. Для номинальных шкал обычно применяют столбиковые диаграммы. Число столбиков соответствует числу категорий. Высота каждого столбика отражает частоту встречаемости данной категории. Все столбики рисуются одинаковой ширины и не соприкасаются друг с другом. Порядок их расположения на горизонтальной оси может быть любым. Для представления долей и процентов удобны круговые диаграммы. Весь круг соответствует единице или ста процентам, а величина каждого сектора отражает представительство соответствующей категории.
Для наглядного представления измеренных данных шкал порядка и интервальных шкал используются так называемые гистограммы и полигоны. Гистограмма похожа на столбиковую диаграмму, только на горизонтальной оси в этом случае указываются границы интервалов. Столбики примыкают друг к другу. Высота столбика соответствует наблюдаемой частоте. Гистограмму легко преобразовать в полигон. Для этого середины вершин каждого столбца соединяются между собой прямыми отрезками. Получается ломаная линия, повторяющая контур, образуемый столбиками. Гистограмма удобна для изображения особенностей одного распределения. Преимущество полигона заключается в том, что на одном графике можно представить несколько полигонов и затем сравнивать между собой разные выборки.
3) Оценка параметров распределения. Вычисляются показатели, которые позволяют дать еще более сжатое описание наблюдаемых значений. Эти показатели распадаются на две основные группы:
• меры центральной тенденции;
• меры рассеяния.
Меры центральной тенденции указывают на расположение среднего, или типичного, значения признака, вокруг которого сгруппированы остальные наблюдения. Понятие среднего, центрального, значения в статистике, как и в повседневной жизни, подразумевает нечто «ожидаемое», «обычное», «типичное». Наиболее часто используют так называемое среднее (арифметическое). В случае метрической шкалы его вычисляют, как известно, путем суммирования значений всех наблюдений и деления полученной суммы на общее число наблюдений. В случае сгруппированных данных (шкала интервалов) поступают следующим образом: находят середину каждого интервала, это значение умножают на частоту, полученные величины складывают и делят на общее число наблюдений.
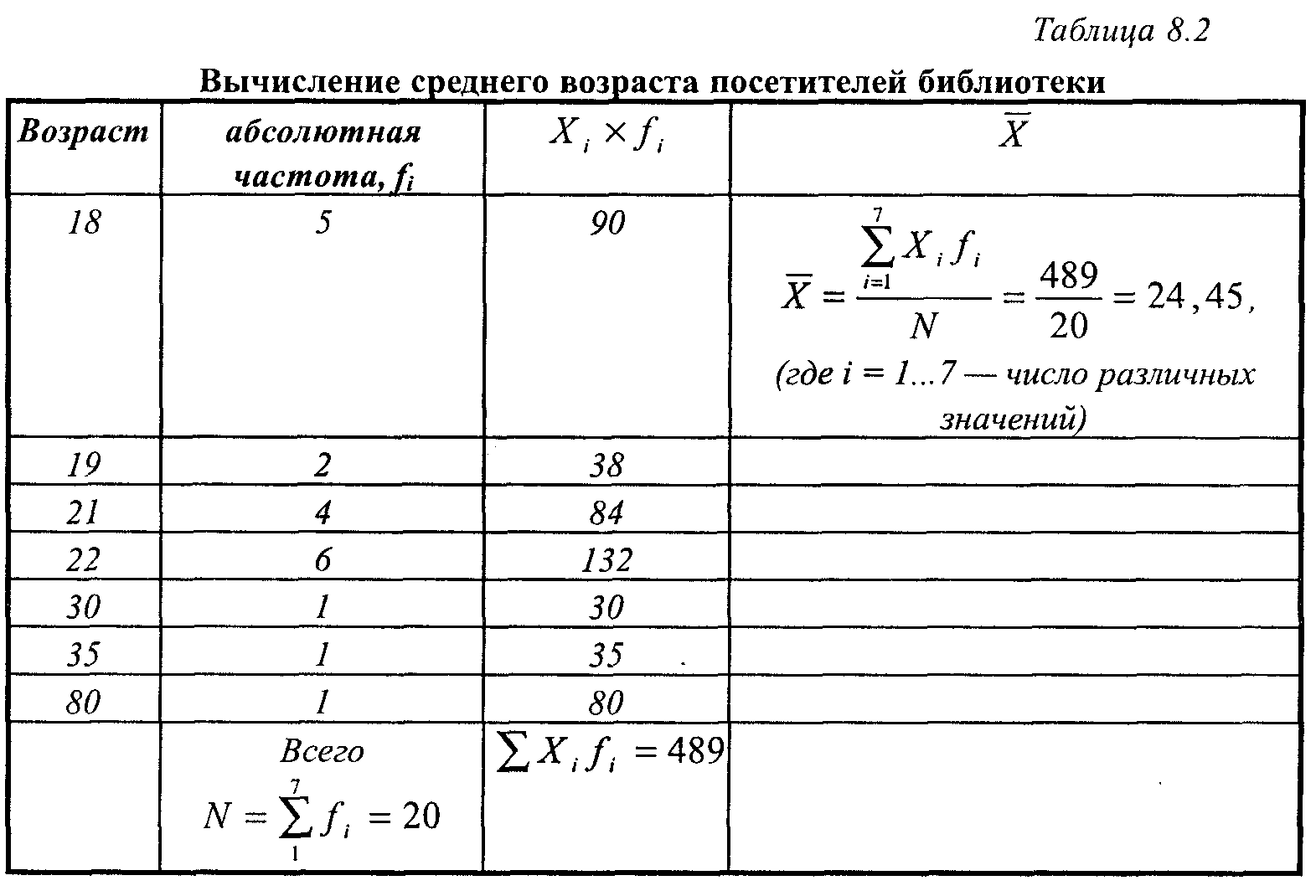
Рассматриваемый показатель характеризует область распределения, в которой концентрируются наиболее типичные представители изучаемой выборки. Это справедливо лишь для тех случаев, когда распределение близко к нормальному. При таком распределении основная масса значений концентрируется в его средней части, а любые отклонения встречаются тем реже, чем дальше они отстоят от центра. Например, распределение такого признака, как рост человека, в целом близко к нормальному: больше всего людей среднего роста, а очень высокие и очень маленькие попадаются довольно редко. Средняя величина удобна для сравнения двух выборок или двух популяций. Пример приведен в таблице 11.
Таблица 11
Вычисление среднего возраста посетителей библиотеки
Две другие меры центральной тенденции – это мода (Мо) и медиана (Мd). В качестве моды берется значение, которое чаще всего встречается в распределении. Моду специально вычислять не надо. Достаточно сгруппировать данные и выбрать тот класс, в который попадает больше всего наблюдений. В разобранном выше примере (табл. 9) лучше всего представлена категория семейных людей. Это и есть мода для данной выборки. Встречаются распределения, имеющие не одну, а две моды. Распределение такого типа называется бимодальным. Чаще всего это указывает на то, что выборка является неоднородной: в ней присутствуют два типа объектов. Констатация такого факта обычно наводит нас на мысль разбить всю выборку на две подгруппы и рассмотреть их отдельно.
Медиана (Md) – это значение, которое делит упорядоченное множество данных пополам, так что одна половина наблюдений оказывается меньше медианы, а другая – больше. Иными словами, медиана – это 50-й процентиль распределения. Как мы уже видели, при работе с большим массивом данных удобнее всего искать медиану, построив на основании частотного распределения распределение накопленных частот (или построив распределение накопленных процентов на основании распределения процентов). Если число значений в группе наблюдений четное, то медианой будет среднее двух центральных значений.
Когда распределение имеет нормальный вид (то есть оно симметрично), его среднее арифметическое значение и медиана совпадают. Когда же распределение асимметрично (скошено), медиана лучше схватывает его центральную тенденцию. Выбор подходящей меры центральной тенденции определяется как характером распределения, так и характером используемых данных.
Качественные данные (шкала наименований) допускают использование только моды. Для ранжированных данных (шкала порядка, интервалов) допустимо использование и моды, и медианы. Количественные данные (метрические шкалы) можно описывать любым из трех показателей. На практике чаще всего вычисляют среднее арифметическое значение.
Меры рассеяния характеризуют степень разброса данных вокруг некоторого среднего значения. Мы говорим о значительном рассеянии тогда, когда многие значения сильно отклоняются от воображаемого центра распределения. Специалисты по математической статистике говорят, что в этом случае данные «размазаны». Про распределение, характеризующееся малым разбросом, говорят, пользуясь аналогией из области стрельбы, что данные ложатся «кучно». Понятно, что в первом случае среднее значение оказывается более информативным показателем, чем во втором случае, то есть оно лучше описывает выборку в целом.
Например, в кордебалет идет строгий отбор танцовщиц по росту. В результате рассеяние показателей роста в этой группе людей значительно меньше, чем по популяции в целом. Зная средний рост балерины, можно быть уверенным, что реальный рост любой балерины будет очень близок к нему.
Как оценить степень рассеяния значений переменной? Здесь тоже существуют разные способы, выбор которых в каждом конкретном случае определяется характером данных – их типом и распределением. Некоторое представление о рассеянии мы получаем, когда рассматриваем крайние члены распределения. Расстояние между ними называется размахом.
Например, в разобранном выше примере (табл. 9) выборка включает индивидов, чей возраст колеблется в пределах от двадцати до семидесяти лет. Общий размах составляет пятьдесят лет. Большинство людей (40 %) – моложе тридцати лет, но в выборку попали два человека, которым уже за шестьдесят. Если мы вычислим показатель центральной тенденции по формуле среднего арифметического, то получим значение 36,5. Так как распределение сильно скошено, этот показатель сильно отличается от моды (Mo = 25 лет). Медиана в этом случае лежит между этими двумя значениями (Md = 33,3).
Для более точной оценки рассеяния в случае измерений по шкале равных интервалов используется показатель, называемый дисперсия. В этом случае учитывается отклонение каждого индивидуального значения от среднего в одну или в другую сторону. Нас интересует сумма таких отклонений. Но в случае симметричного распределения эта сумма всегда обращается в нуль, поскольку положительные и отрицательные отклонения взаимно гасятся. Сумма квадратов отклонений от среднего, деленная на количество наблюдений, дает значение дисперсии.
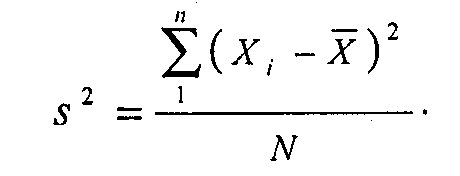
Если извлечь из дисперсии квадратный корень, то мы получим еще одну меру рассеяния – стандартное отклонение (Sx), которое также называют среднеквадратическим отклонением. Удобство этого показателя в том, что он выражается в тех же единицах, что и сами измеренные величины:
![]()
Рассмотренный показатель очень удобен, когда форма распределения близка к той, которая называется нормальным распределением.
Мы уже упоминали этот термин. Сейчас поясним, что он означает. Нормальное распределение – это такое распределение непрерывного признака, которое симметрично относительно среднего значения, и если откладывать его значения на графике, то кривая имеет вид колокола. Рост человека оказывается одним из признаков, обнаруживающих распределение, хорошо описываемое нормальной кривой. Если мы измеряем рост многих людей, например призывников в армию, а затем на основе этих данных строим график, то мы получаем нормальную кривую. С точки зрения анализа данных нормальное распределение привлекательно тем, что его можно исчерпывающе описать через два параметра – значение среднего и стандартного отклонения (дисперсии). Вместо тысяч значений – всего два числа. Чрезвычайно эффективный метод сжатия информации.
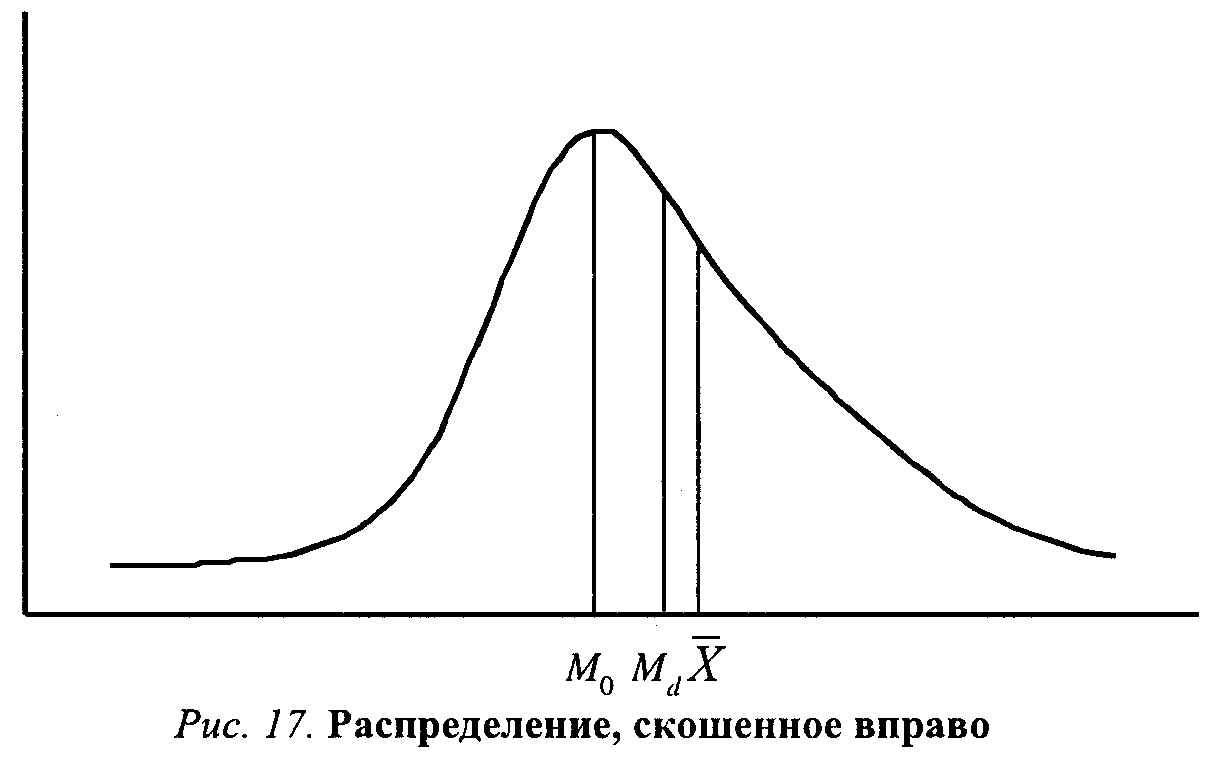
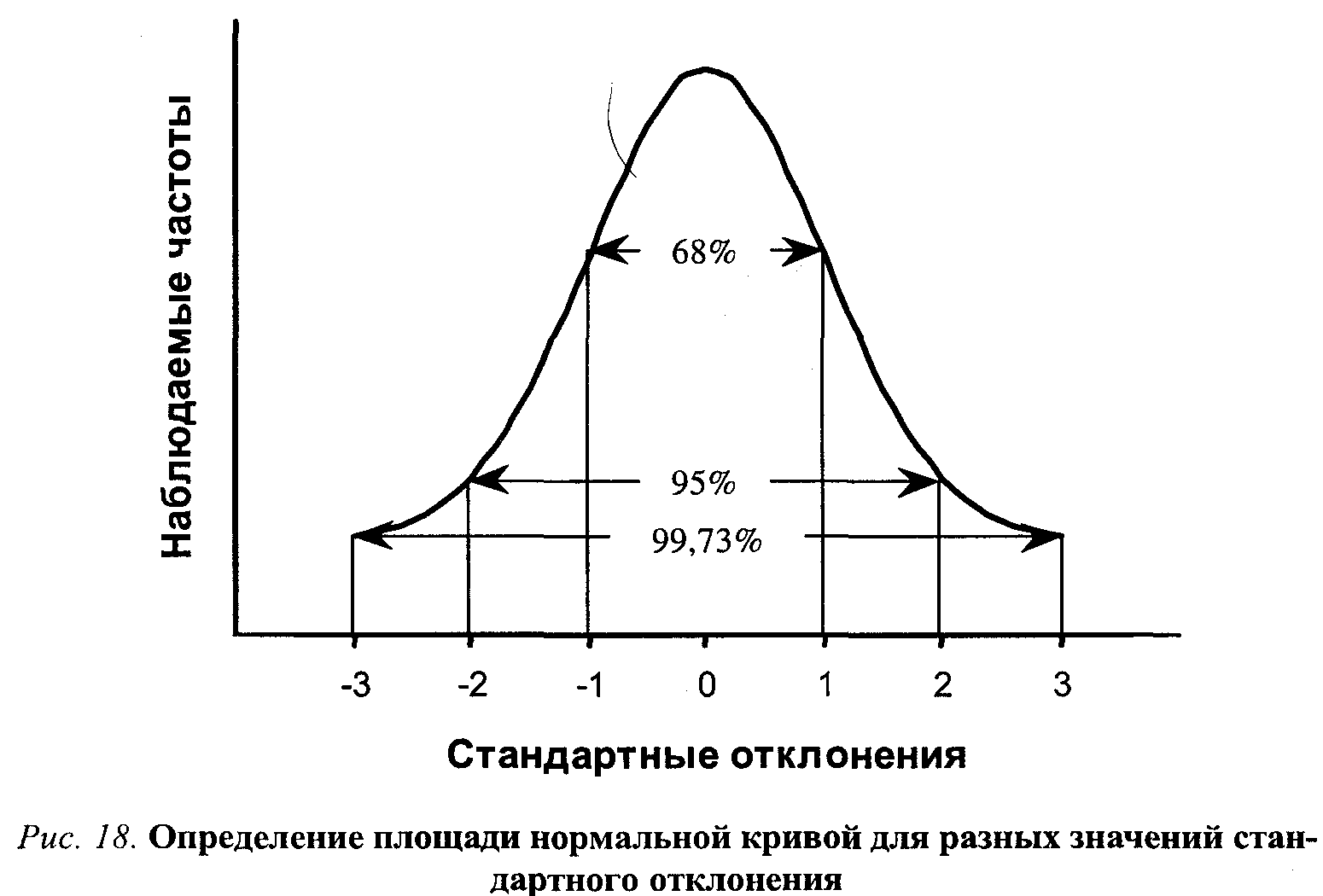
Рис. 2. Распределение, скошенное вправо Рис. 3. Определение площади нормальной
кривой для разных значений стандартного
отклонения
Стандартное отклонение действительно позволяет четко задавать критерии для выявления статистической нормы. Это возможно благодаря тому, что свойства нормального распределения хорошо известны и достаточно просто описываются. Так, известно, что в диапазоне одного стандартного отклонения в обе стороны от среднего оказывается примерно 68 % всех наблюдений, а если взять два стандартных отклонения, то этот участок распределения покроет около 95 % всех случаев. Значит, за этот диапазон выходит всего 5 % возможных наблюдений.
Проинтерпретируем это содержательно. Что значит «высокий человек»? С точки зрения статистики человек, рост которого превышает средний рост по данной популяции более чем на величину одного стандартного отклонения, может считаться высоким. А того, чей рост выделяется в положительную сторону более чем на два стандартных отклонения, следует отнести к категории очень высоких, ведь такой рост будет встречаться не чаще, чем в трех случаях из ста.
Используя свойства нормального распределения, можно ввести строгие количественные критерии, определяющие, что такое «нормальный вес», «нормальная острота зрения» и т. д. Психологические тесты тоже создаются с опорой на эти статистические закономерности. Нормы для оценки результатов испытаний выводят эмпирически с использованием аппарата математической статистики, т.е. трудность заданий подбирается таким образом, чтобы распределение результатов решения тестовых задач (число правильных ответов) описывалось нормальным законом. Затем строится шкала, где среднему значению соответствует сто баллов, а стандартное отклонение равно пятнадцати баллам. Также построен известный показатель – коэффициент интеллектуального развития (по-английски IQ). Человек, у которого этот показатель ниже 70, считается умственно отсталым, а человека с показателем выше 130 относят к категории особо умственно одаренных.
Мы подробно разобрали случай, когда анализируется характер распределения одной переменной. Эти приемы очень важны, поскольку на них основаны все другие виды статистического анализа.