

Серверы доступа к данным
Серверы доступа к данным обслуживают базу данных и отдают данные по запросам. Один из самых простых серверов подобного типа — LDAP (англ. Lightweight Directory Access Protocol — облегчённый протокол доступа к спискам).
Для доступа к серверам баз данных единого протокола не существует, однако все серверы баз данных объединяет использование единых правил формирования запросов — язык SQL (англ. Structured Query Language — язык структурированных запросов).
Службы обмена сообщениями
Службы обмена сообщениями позволяют пользователю передавать и получать сообщения (обычно — текстовые).
В первую очередь это серверы электронной почты работающие по протоколу SMTP. SMTP-сервер принимает сообщение и доставляет его в локальный почтовый ящик пользователя или на другой SMTP-сервер (сервер назначения или промежуточный). На многопользовательских компьютерах, пользователи работают с почтой прямо на терминале (или веб-интерфейсе). Для работы с почтой на персональном компьютере, почта забирается из почтового ящика через серверы, работающие по протоколам POP3 или IMAP.
Для организации конференций существует серверы новостей, работающие по протоколу NNTP.
Для обмена сообщениями в реальном времени существуют серверы чатов, стандартный чат-сервер работает по протоколу IRC — распределенный чат для интернета. Существует большое количество других чат-протоколов, например ICQ или Jabber.
Серверы удаленного доступа
Серверы удаленного доступа, через соответствующую клиентскую программу, обеспечивают пользователя консольным доступом к удаленной системе.
Для обеспечения доступа к командной строке служат серверы telnet, RSH, SSH.
Графический интерфейс для Unix-систем — X Window System, имеет встроенный сервер удаленного доступа, так как с такой возможностью разрабатывался изначально. Иногда возможность удаленного доступа к интерфейсу Х-Window неправильно называют «X-Server» (этим термином в X-Window называется видеодрайвер).
Стандартный сервер удаленного доступа к графическому интерфейсу Microsoft Windows называется терминальный сервер.
Некоторую разновидность управления (точнее мониторинга и конфигурирования), также, предоставляет протокол SNMP. Компьютер или аппаратное устройство для этого должно иметь SNMP-сервер.
Игровые серверы
Игровой сервер, служат для одновременной игры нескольких пользователей в единой игровой ситуации. Некоторые игры имеют сервер в основной поставке и позволяют запускать его в невыделенном режиме (то есть позволяют играть на машине, на которой запущен сервер).
Серверные решения
Серверные решения — операционные системы и/или пакеты программ оптимизированные под выполнение компьютером функций сервера и/или содержащие в своем составе комплект программ для реализации типичного набора сервисов.
Примером серверных решений можно привести Unix-системы, изначально предназначенные для реализации серверной инфраструктуры.
Также необходимо выделить пакеты серверов и сопутствующих программ (например комплект веб-сервер/PHP/MySQL для быстрой развертки хостинга) для установки под Windows (для Unix свойственна модульная или «пакетная» установка каждого компонента, поэтому такие решения редки, но они существуют. Наиболее известное — LAMP).
В интегрированных серверных решениях установка всех компонентов выполняется единовременно, все компоненты в той или иной мере тесно интегрированы и предварительно настроены друг на друга. Однако в этом случае, замена одного из серверов или вторичных приложений (если их возможности не удовлетворяют потребностям) может представлять проблему.
Серверные решения служат для упрощения организации базовой ИТ-инфраструктуры компаний, то есть для оперативного построения полноценной сети в компании в том числе и «с нуля». Компоновка отдельных серверных приложений в решение подразумевает, что решение предназначено для выполнения большинства типовых задач; при этом значительно снижается сложность развертывания и общая стоимость владения ИТ-инфраструктурой, построенной на таких решениях.
Rластер — группа компьютеров, объединённых высокоскоростными каналами связи и представляющая с точки зрения пользователя единый аппаратный ресурс.
Один из первых архитекторов кластерной технологии Грегори Пфистер дал кластеру следующее определение: «Кластер — это разновидность параллельной или распределённой системы, которая:
состоит из нескольких связанных между собой компьютеров;
используется как единый, унифицированный компьютерный ресурс».
Обычно различают следующие основные виды кластеров:
отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой доступности)
кластеры с балансировкой нагрузки (Load balancing clusters)
вычислительные кластеры (High perfomance computing clusters)
grid-системы
Обозначаются аббревиатурой HA (англ. High Availability — высокая доступность). Создаются для обеспечения высокой доступности сервиса, предоставляемого кластером. Избыточное число узлов, входящих в кластер, гарантирует предоставление сервиса в случае отказа одного или нескольких серверов. Типичное число узлов — два, это минимальное количество, приводящее к повышению доступности. Создано множество программных решений для построения такого рода кластеров.
Отказоустойчивые кластеры и системы вообще строятся по трем основным принципам:
с холодным резервом или активный/пассивный. Активный узел выполняет запросы, а пассивный ждет его отказа и включается в работу, когда таковой произойдет. Пример — резервные сетевые соединения, в частности, Алгоритм связующего дерева. Например связка DRBD и HeartBeat.
с горячим резервом или активный/активный. Все узлы выполняют запросы, в случае отказа одного нагрузка перераспределяется между оставшимися. То естькластер распределения нагрузки с поддержкой перераспределения запросов при отказе. Примеры — практически все кластерные технологии, например, Microsoft Cluster Server. OpenSource проект OpenMosix.
с модульной избыточностью. Применяется только в случае, когда простой системы совершенно недопустим. Все узлы одновременно выполняют один и тот же запрос (либо части его, но так, что результат достижим и при отказе любого узла), из результатов берется любой. Необходимо гарантировать, что результаты разных узлов всегда будут одинаковы (либо различия гарантированно не повлияют на дальнейшую работу). Примеры — RAID и Triple modular redundancy.
Конкретная технология может сочетать данные принципы в любой комбинации. Например, Linux-HA поддерживает режим обоюдной поглощающей конфигурации(англ. takeover), в котором критические запросы выполняются всеми узлами вместе, прочие же равномерно распределяются между ними. [1]
[править]Кластеры распределения нагрузки
Принцип их действия строится на распределении запросов через один или несколько входных узлов, которые перенаправляют их на обработку в остальные, вычислительные узлы. Первоначальная цель такого кластера — производительность, однако, в них часто используются также и методы, повышающие надёжность. Подобные конструкции называются серверными фермами. Программное обеспечение (ПО) может быть как коммерческим (OpenVMS, MOSIX, Platform LSF HPC, Solaris Cluster Moab Cluster Suite, Maui Cluster Scheduler), так и бесплатным (OpenMosix, Sun Grid Engine, Linux Virtual Server).
[править]Вычислительные кластеры
Кластеры используются в вычислительных целях, в частности в научных исследованиях. Для вычислительных кластеров существенными показателями являются высокая производительность процессора в операциях над числами с плавающей точкой (flops) и низкая латентность объединяющей сети, и менее существенными — скорость операций ввода-вывода, которая в большей степени важна для баз данных и web-сервисов. Вычислительные кластеры позволяют уменьшить время расчетов, по сравнению с одиночным компьютером, разбивая задание на параллельно выполняющиеся ветки, которые обмениваются данными по связывающей сети. Одна из типичных конфигураций — набор компьютеров, собранных из общедоступных компонентов, с установленной на них операционной системой Linux, и связанных сетьюEthernet, Myrinet, InfiniBand или другими относительно недорогими сетями. Такую систему принято называть кластером Beowulf. Специально выделяют высокопроизводительные кластеры (Обозначаются англ. аббревиатурой HPC Cluster — High-performance computing cluster). Список самых мощных высокопроизводительных компьютеров (также может обозначаться англ. аббревиатурой HPC) можно найти в мировом рейтинге TOP500. В России ведется рейтинг самых мощных компьютеров СНГ.[1]
[править]Системы распределенных вычислений (grid)
Такие системы не принято считать кластерами, но их принципы в значительной степени сходны с кластерной технологией. Их также называют grid-системами. Главное отличие — низкая доступность каждого узла, то есть невозможность гарантировать его работу в заданный момент времени (узлы подключаются и отключаются в процессе работы), поэтому задача должна быть разбита на ряд независимых друг от друга процессов. Такая система, в отличие от кластеров, не похожа на единый компьютер, а служит упрощённым средством распределения вычислений. Нестабильность конфигурации, в таком случае, компенсируется больши́м числом узлов.
[править]Кластер серверов, организуемых программно
Кластер серверов (в информационных технологиях) — группа серверов, объединённых логически, способных обрабатывать идентичные запросы и использующихся как единый ресурс. Чаще всего серверы группируются посредством локальной сети. Группа серверов обладает большей надежностью и большей производительностью, чем один сервер. Объединение серверов в один ресурс происходит на уровне программных протоколов.
В отличие от аппаратного кластера компьютеров, кластеры организуемые программно, требуют:
наличия специального программного модуля (Cluster Manager), основной функцией которого является поддержание взаимодействия между всеми серверами — членами кластера:
синхронизации данных между всеми серверами — членами кластера;
распределение нагрузки (клиентских запросов) между серверами — членами кластера;
от умения клиентского программного обеспечения распознавать сервер, представляющий собой кластер серверов, и соответствующим образом обрабатывать команды от Cluster Manager;
если клиентская программа не умеет распознавать кластер, она будет работать только с тем сервером, к которому обратилась изначально, а при попытке Cluster Manager перераспределить запрос на другие серверы, клиентская программа может вообще лишиться доступа к этому серверу (результат зависит от конкретной реализации кластера).
Примеры программных кластерных решений
IBM Lotus Notes
HP MC/ServiceGuard
[править]Применение
В большинстве случаев, кластеры серверов функционируют на раздельных компьютерах. Это позволяет повышать производительность за счёт распределения нагрузки на аппаратные ресурсы и обеспечивает отказоустойчивость на аппаратном уровне.
Однако, принцип организации кластера серверов (на уровне программного протокола) позволяет исполнять по нескольку программных серверов на одном аппаратном. Такое использование может быть востребовано:
при разработке и тестировании кластерных решений;
при необходимости обеспечить доступность кластера только с учётом частых изменений конфигурации серверов — членов кластера, требующих их перезагрузки (перезагрузка производится поочерёдно) в условиях ограниченных аппаратных ресурсов.
[править]Программные средства
Широко распространённым средством для организации межсерверного взаимодействия является библиотека MPI, поддерживающая языки C и Fortran. Она используется, например, в программе моделирования погоды MM5.
Операционная система Solaris предоставляет программное обеспечение Solaris Cluster, которое служит для обеспечения высокой доступности и безотказности серверов, работающих под управлением Solaris. Для OpenSolaris существует реализация с открытым кодом под названием OpenSolaris HA Cluster.
Среди пользователей GNU/Linux популярны несколько программ:
distcc, MPICH и др. — специализированные средства для распараллеливания работы программ. distcc допускает параллельную компиляцию в GNU Compiler Collection.
Linux Virtual Server, Linux-HA — узловое ПО для распределения запросов между вычислительными серверами.
MOSIX, openMosix, Kerrighed, OpenSSI — полнофункциональные кластерные среды, встроенные в ядро, автоматически распределяющие задачи между однородными узлами. OpenSSI, openMosix и Kerrighed создают среду единой операционной системы между узлами.
Кластерные механизмы планируется встроить и в ядро DragonFly BSD, ответвившуюся в 2003 году от FreeBSD 4.8. В дальних планах также превращение её в среду единой операционной системы.
Компанией Microsoft выпускается HA-кластер для операционной системы Windows. Существует мнение, что он создан на основе технологии Digital Equipment Corporation, поддерживает до 16 (с 2010 года) узлов в кластере, а также работу в сети SAN (Storage Area Network). Набор API-интерфейсов служит для поддержки распределяемых приложений, есть заготовки для работы с программами, не предусматривающими работы в кластере.
Windows Compute Cluster Server 2003 (CCS), выпущенный в июне 2006 года разработан для высокотехнологичных приложений, которые требуют кластерных вычислений. Издание разработано для развертывания на множестве компьютеров, которые собираются в кластер для достижения мощностей суперкомпьютера. Каждый кластер на Windows Compute Cluster Server состоит из одного или нескольких управляющих машин, распределяющих задания и нескольких подчиненных машин, выполняющих основную работу. В ноябре 2008 представлен Windows HPC Server 2008, призванный заменить Windows Compute Cluster Server 2003.
Грид-вычисления (англ. grid — решётка, сеть) — это форма распределённых вычислений, в которой «виртуальный суперкомпьютер» представлен в виде кластеровсоединённых с помощью сети, слабосвязанных, гетерогенных компьютеров, работающих вместе для выполнения огромного количества заданий (операций, работ). Эта технология применяется для решения научных, математических задач, требующих значительных вычислительных ресурсов. Грид-вычисления используются также в коммерческой инфраструктуре для решения таких трудоёмких задач, как экономическое прогнозирование, сейсмоанализ, разработка и изучение свойств новых лекарств.
Грид с точки зрения сетевой организации представляет собой согласованную, открытую и стандартизованную среду, которая обеспечивает гибкое, безопасное, скоординированное разделение вычислительных ресурсов и ресурсов хранения[1] информации, которые являются частью этой среды, в рамках одной виртуальной организации.[2]
Грид является географически распределённой инфраструктурой, объединяющей множество ресурсов разных типов (процессоры, долговременная и оперативная память, хранилища и базы данных, сети), доступ к которым пользователь может получить из любой точки, независимо от места их расположения.[3]
Идея грид-компьютинга возникла вместе с распространением персональных компьютеров, развитием интернета и технологий пакетной передачи данных на основе оптического волокна (SONET, SDH и ATM), а также технологий локальных сетей (Gigabit Ethernet). Полоса пропускания коммуникационных средств стала достаточной, чтобы при необходимости привлечь ресурсы другого компьютера. Учитывая, что множество подключенных к глобальной сети компьютеров большую часть рабочего времени простаивает и располагает ресурсами, большими, чем необходимо для решения их повседневных задач, возникает возможность применить их неиспользуемые ресурсы в другом месте.
[править]Сравнение грид-систем и обычных суперкомпьютеров
Распределённые или грид-вычисления в целом являются разновидностью параллельных вычислений, которое основывается на обычных компьютерах (со стандартными процессорами, устройствами хранения данных, блоками питания и т. д.) подключенных к сети (локальной или глобальной) при помощи обычных протоколов, напримерEthernet. В то время как обычный суперкомпьютер содержит множество процессоров, подключенных к локальной высокоскоростной шине.
Основным преимуществом распределённых вычислений является то, что отдельная ячейка вычислительной системы может быть приобретена как обычный неспециализированный компьютер. Таким образом можно получить практически те же вычислительные мощности, что и на обычных суперкомпьютерах, но с гораздо меньшей стоимостью.
[править]Типы грид-систем
В настоящее время выделяют три основных типа грид-систем:
Добровольные гриды — гриды на основе использования добровольно предоставляемого свободного ресурса персональных компьютеров;
Научные гриды — хорошо распараллеливаемые приложения программируются специальным образом (например, с использованием Globus Toolkit);
Гриды на основе выделения вычислительных ресурсов по требованию (коммерческий грид, англ. enterprise grid) — обычные коммерческие приложения работают на виртуальном компьютере, который, в свою очередь, состоит из нескольких физических компьютеров, объединённых с помощью грид-технологий.
Облачные вычисления (англ. cloud computing), в информатике — это модель обеспечения повсеместного и удобного сетевого доступа по требованию к общему пулу конфигурируемых вычислительных ресурсов (например, сетям передачи данных, серверам, устройствам хранения данных, приложениям и сервисам — как вместе, так и по отдельности), которые могут быть оперативно предоставлены и освобождены с минимальными эксплуатационными затратами и/или обращениями к провайдеру. [1]
Потребители облачных вычислений могут значительно уменьшить расходы на инфраструктуру информационных технологий (в краткосрочном и среднесрочном планах) и гибко реагировать на изменения вычислительных потребностей, используя свойства вычислительной эластичности (англ. Elastic computing) облачных услуг.
Характеристики
Национальным институтом стандартов и технологий США зафиксированы следующие обязательные характеристики облачных вычислений[7]:
Самообслуживание по требованию (англ. self service on demand), потребитель самостоятельно определяет и изменяет вычислительные потребности, такие как серверное время, скорости доступа и обработки данных, объём хранимых данных без взаимодействия с представителем поставщика услуг;
Универсальный доступ по сети, услуги доступны потребителям по сети передачи данных вне зависимости от используемого терминального устройства;
Объединение ресурсов (англ. resource pooling), поставщик услуг объединяет ресурсы для обслуживания большого числа потребителей в единый пул для динамического перераспределения мощностей между потребителями в условиях постоянного изменения спроса на мощности; при этом потребители контролируют только основные параметры услуги (например, объём данных, скорость доступа), но фактическое распределение ресурсов, предоставляемых потребителю, осуществляет поставщик (в некоторых случаях потребители всё-таки могут управлять некоторыми физическими параметрами перераспределения, например, указывать желаемый центр обработки данных из соображений географической близости);
Эластичность, услуги могут быть предоставлены, расширены, сужены в любой момент времени, без дополнительных издержек на взаимодействие с поставщиком, как правило, в автоматическом режиме;
Учёт потребления, поставщик услуг автоматически исчисляет потреблённые ресурсы на определённом уровне абстракции (например, объём хранимых данных, пропускная способность, количество пользователей, количество транзакций), и на основе этих данных оценивает объём предоставленных потребителям услуг.
С точки зрения поставщика, благодаря объединению ресурсов и непостоянному характеру потребления со стороны потребителей, облачные вычисления позволяют экономить на масштабах, используя меньшие аппаратные ресурсы, чем требовались бы при выделенных аппаратных мощностях для каждого потребителя, а за счёт автоматизации процедур модификации выделения ресурсов существенно снижаются затраты на абонентское обслуживание.
С точки зрения потребителя, эти характеристики позволяют получить услуги с высоким уровнем доступности (англ. high availability) и низкими рисками неработоспособности, обеспечить быстрое масштабирование вычислительной системы благодаря эластичности без необходимости создания, обслуживания и модернизации собственной аппаратной инфраструктуры.
Удобство и универсальность доступа обеспечивается широкой доступностью услуг и поддержкой различного класса терминальных устройств (персональных компьютеров, мобильных телефонов, интернет-планшетов).
[править]Модели развёртывания
[править]Частное облако
Частное облако (англ. private cloud) — инфраструктура, предназначенная для использования одной организацией, включающей несколько потребителей (например, подразделений одной организации), возможно также клиентами и подрядчиками данной организации. Частное облако может находиться в собственности, управлении и эксплуатации как самой организации, так и третьей стороны (или какой-либо их комбинации), и оно может физически существовать как внутри, так и вне юрисдикции владельца.
[править]Публичное облако
Публичное облако (англ. public cloud) — инфраструктура, предназначенная для свободного использования широкой публикой. Публичное облако может находиться в собственности, управлении и эксплуатации коммерческих, научных и правительственных организаций (или какой-либо их комбинации). Публичное облако физически существует в юрисдикции владельца — поставщика услуг.
[править]Гибридное облако
Гибридное облако (англ. hybrid cloud) — это комбинация из двух или более различных облачных инфраструктур (частных, публичных или общественных), остающихся уникальными объектами, но связанных между собой стандартизованными или частными технологиями передачи данных и приложений (например, кратковременное использование ресурсов публичных облаков для балансировки нагрузки между облаками).
[править]Общественное облако
Общественное облако (англ. community cloud) — вид инфраструктуры, предназначенный для использования конкретным сообществом потребителей из организаций, имеющих общие задачи (например, миссии, требований безопасности, политики, и соответствия различным требованиям). Общественное облако может находиться в кооперативной (совместной) собственности, управлении и эксплуатации одной или более из организаций сообщества или третьей стороны (или какой-либо их комбинации), и оно может физически существовать как внутри, так и вне юрисдикции владельца.
[править]Модели обслуживания
[править]Программное обеспечение как услуга
Основная статья: SaaS
Программное обеспечение как услуга (SaaS, англ. Software-as-a-Service) — модель, в которой потребителю предоставляется возможность использования прикладного программного обеспечения провайдера, работающего в облачной инфраструктуре и доступного из различных клиентских устройств или посредством тонкого клиента, например, из браузера (например, веб-почта) или интерфейс программы. Контроль и управление основной физической и виртуальной инфраструктурой облака, в том числе сети, серверов, операционных систем, хранения, или даже индивидуальных возможностей приложения (за исключением ограниченного набора пользовательских настроек конфигурации приложения) осуществляется облачным провайдером.
[править]Платформа как услуга
Основная статья: PaaS
Платформа как услуга (PaaS, англ. Platform-as-a-Service) — модель, когда потребителю предоставляется возможность использования облачной инфраструктуры для размещения базового программного обеспечения для последующего размещения на нём новых или существующих приложений (собственных, разработанных на заказ или приобретённых тиражируемых приложений). В состав таких платформ входят инструментальные средства создания, тестирования и выполнения прикладного программного обеспечения — системы управления базами данных, связующее программное обеспечение, среды исполнения языков программирования — предоставляемые облачным провайдером.
Контроль и управление основной физической и виртуальной инфраструктурой облака, в том числе сети, серверов, операционных систем, хранения осуществляется облачным провайдером, за исключением разработанных или установленных приложений, а также, по возможности, параметров конфигурации среды (платформы).
[править]Инфраструктура как услуга
Основная статья: IaaS
Инфраструктура как услуга (IaaS, англ. IaaS or Infrastructure-as-a-Service) предоставляется как возможность использования облачной инфраструктуры для самостоятельного управления ресурсами обработки, хранения, сетей и другими фундаментальными вычислительными ресурсами, например, потребитель может устанавливать и запускать произвольное программное обеспечение, которое может включать в себя операционные системы, платформенное и прикладное программное обеспечение. Потребитель может контролировать операционные системы, виртуальные системы хранения данных и установленные приложения, а также ограниченный контроль набора доступных сервисов (например, межсетевой экран, DNS). Контроль и управление основной физической и виртуальной инфраструктурой облака, в том числе сети, серверов, типов используемых операционных систем, систем хранения осуществляется облачным провайдером.
[править]Технологии
Для обеспечения согласованной работы узлов вычислительной сети на стороне облачного провайдера используется специализированное промежуточное программное обеспечение, обеспечивающее мониторинг состояния оборудования и программ, балансировку нагрузки, обеспечение ресурсов для решения задачи[8].
Одним из основных решений для сглаживания неравномерности нагрузки на услуги является размещение слоя серверной виртуализации между слоем программных услуг и аппаратным обеспечением. В условиях виртуализации балансировка нагрузки может осуществляться посредством программного распределения виртуальных серверов по реальным, перенос виртуальных серверов происходит посредством живой миграции[8].
Структура кадрів Ethernet. Їх місце у стеках протоколів
Для Ethernet кадр має фіксовані поля. Структура кадру наведена на рис.
1.3, 1.4. Для технологій 10Base-s (2, Т), 100Base-s (ТX, FX ) відома трівалість одного біту, тому заранее можна сказати о трівалості передачі кадру рис. 5.1. След пам’ятати, якщо кадри передаються потоком, то між ними всегда задається міжкадровий інтервал рис. 5.1.

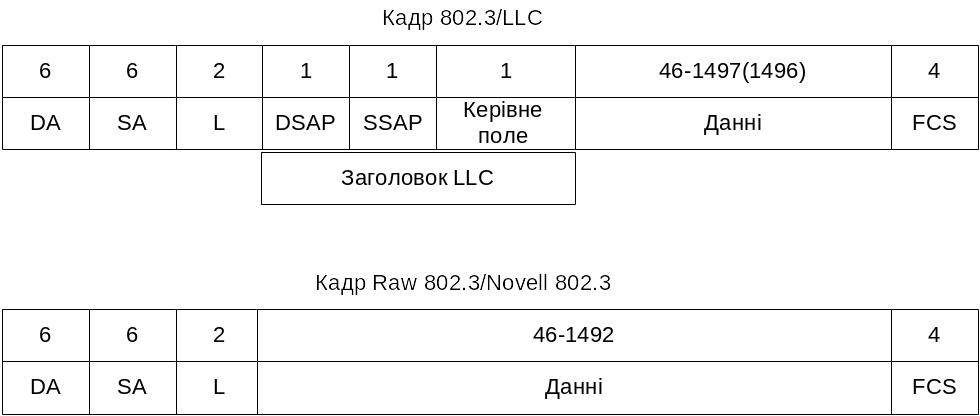
Рисунок 1.3 – Структура кадру Ethernet
Дані
Дані
Рисунок 1.4 – Структура кадру Ethernet 802.3, 802.2
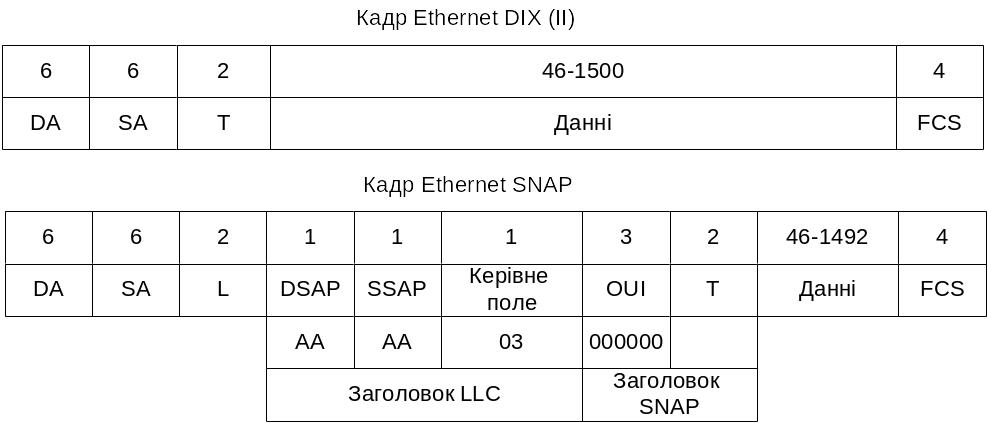
Рисунок 1.5 – Структура різних типів кадрів Ethernet DIX, SNAP
1). Протокол IEE802.3.
Структура кадру:
Преамбула - 8Б. Службова інформація (адреса і команди) - 14 Б Контрольна сума - 4Б. Мінімально припустимий розмір кадру - 46 Б. Максимально припустимий розмір кадру - 1500 Б
Таким чином, загальна службова інформація - 26 Б.
Час міжкадрового інтервалу - tF=9.6 мкс для 10Base-x відповідно для
100Base-x маємо t F =0.96 мкс.
2). Протокол ТСР.
Заголовок LTCP=24 Байт
Дані - (згідно MTU), але рекомендовано 512 Байт. Всього 536 Байт
Припустимий максимальний розмір дейтаграми = 65535 Байт.
Підтвердження посилається на кожен другий сегмент.
Таймер відкладеного підтвердження - 200 мс
Розмір вікна - 16КБ.
Якщо розірвано з'єднання, то повторний запит здійснюється через 0.5 с,
а згодом через 1 с. За замовчуванням повторне з'єднання - через 3 сек.
Сімейство протоколів HDLC та протокол HDLC
См. Вопрос 10
Мережі Frame Relay: концепції, область застосування, переваги, недоліки.
Frame Relay первоначально замышлялся как протокол для использования в интерфейсах ISDN, и исходные предложения, представленные в CCITT в 1984 г., преследовали эту цель. Была также предпринята работа над Frame Relay в аккредитованном ANSI комитете по стандартам T1S1 в США.
Крупное событие в истории Frame Relay произошло в 1990 г., когда Cisco Systems, StrataCom, Northern Telecom и Digital Equipment Corporation образовали консорциум, чтобы сосредоточить усилия на разработке технологии Frame Relay и ускорить появление изделий Frame Relay, обеспечивающих взаимодействие сетей. Консорциум разработал спецификацию, отвечающую требованиям базового протокола Frame Relay, рассмотренного в T1S1 и CCITT; однако он расширил ее, включив характеристики, обеспечивающие дополнительные возможности для комплексных окружений межсетевого об'единения. Эти дополнения к Frame Relay называют обобщенно local management interface (LMI) (интерфейс управления локальной сетью).
Основы технологии
Frame Relay обеспечивает возможность передачи данных с коммутацией пакетов через интерфейс между устройствами пользователя (например, маршрутизаторами, мостами, главными вычислительными машинами) и оборудованием сети (например, переключающими узлами). Устройства пользователя часто называют терминальным оборудованием (DTE), в то время как сетевое оборудование, которое обеспечивает согласование с DTE, часто называют устройством завершения работы информационной цепи (DCE). Сеть, обеспечивающая интерфейс Frame Relay, может быть либо общедоступная сеть передачи данных и использованием несущей, либо сеть с оборудованием, находящимся в частном владении, которая обслуживает отдельное предприятие.
В роли сетевого интерфейса, Frame Relay является таким же типом протокола, что и Х.25 . Однако Frame Relay значительно отличается от Х.25 по своим функциональным возможностям и по формату. В частности, Frame Relay является протоколом для линии с большим потоком информации, обеспечивая более высокую производительность и эффективность.
В роли интерфейса между оборудованием пользователя и сети, Frame Relay обеспечивает средства для мультиплексирования большого числа логических информационных диалогов (называемых виртуальными цепями) через один физический канал передачи, которое выполняется с помощью статистики. Это отличает его от систем, использующих только технику временного мультиплексирования (TDM) для поддержания множества информационных потоков. Статистическое мультиплексирование Frame Relay обеспечивает более гибкое и эффективное использование доступной полосы пропускания. Оно может
использоваться без применения техники TDM или как дополнительное средство для каналов,
уже снабженных системами TDM.
Другой важной характеристикой Frame Relay является то, что она использует новейшие достижения технологии передачи глобальных сетей. Более ранние протоколы WAN, такие как Х.25, были разработаны в то время, когда преобладали аналоговые системы передачи данных и медные носители. Эти каналы передачи данных значительно менее надежны, чем доступные сегодня каналы с волоконно-оптическим носителем и цифровой передачей данных. В таких каналах передачи данных протоколы канального уровня могут предшествовать требующим значительных временных затрат алгоритмам исправления ошибок, оставляя это для выполнения на более высоких уровнях протокола. Следовательно, возможны большие производительность и эффективность без ущерба для целостности информации. Именно эта цель преследовалась при разработке Frame Relay. Он включает в себя алгоритм проверки при помощи циклического избыточного кода (CRC) для обнаружения испорченных битов (из-за чего данные могут быть отвергнуты), но в нем отсутствуют какие-либо механизмы для корректирования испорченных данных средствами протокола (например, путем повторной их передачи на данном уровне протокола).
Другим различием между Frame Relay и Х.25 является отсутствие явно выраженного управления потоком для каждой виртуальной цепи. В настоящее время, когда большинство протоколов высших уровней эффективно выполняют свои собственные алгоритмы управления потоком, необходимость в этой функциональной возможности на канальном уровне уменьшилась. Таким образом, Frame Relay не включает явно выраженных процедур управления потоком, которые являются избыточными для этих процедур в высших уровнях. Вместо этого предусмотрены очень простые механизмы уведомления о перегрузках, позволяющие сети информировать какое-либо устройство пользователя о том, что ресурсы сети находятся близко к состоянию перегрузки. Такое уведомление может предупредить протоколы высших уровней о том, что может понадобиться управление потоком.
Стандарты Current Frame Relay адресованы перманентным виртуальным цепям (PVC), определение конфигурации которых и управление осуществляется административным путем в сети Frame Relay. Был также предложен и другой тип виртуальных цепей - коммутируемые виртуальные цепи (SVC). Протокол ISDN предложен в качестве средства сообщения между DTE и DCE для динамичной организации, завершения и управления цепями SVC. Как T1S1, так и CCITT ведут работу по включению SVС в стандарты Frame Relay.
Дополнения LMI
Помимо базовых функций передачи данных протокола Frame Relay, спецификация консорциума Frame Relay включает дополнения LMI, которые делают задачу поддержания крупных межсетей более легкой. Некоторые из дополнений LMI называют "общими"; считается, что они могут быть реализованы всеми, кто взял на вооружение эту спецификацию. Другие функции LMI называют "факультативными". Ниже приводится следующая краткая сводка о дополнениях LMI:
Сообщения о состоянии виртуальных цепей (общее дополнение).
Обеспечивает связь и синхронизацию между сетью и устройством пользователя, периодически сообщая о существовании новых PVC и ликвидации уже существующих PVC, и в большинстве случаев обеспечивая информацию о целостности PVC. Сообщения о состоянии виртуальных цепей предотвращают
отправку информации в"черные дыры", т.е. через PVC, которые больше не существуют.
Многопунктовая адресация (факультативное).
Позволяет отправителю передавать один блок данных, но доставлять его через сеть нескольким получателям. Таким образом, многопунктовая адресация обеспечивает эффективную транспортировку сообщений протокола маршрутизации и процедур резолюции адреса, которые обычно должны быть отосланы одновременно во многие пункты назначения.
Глобальная адресация (факультативное).
Наделяет идентификаторы связи глобальным, а не локальным значением, позволяя их использование для идентификации определенного интерфейса с сетью Frame Relay. Глобальная адресация делает сеть Frame Relay похожей на LAN в терминах адресации; следовательно, протоколы резолюции адреса действуют в Frame Relay точно также, как они работают в LAN.
Простое управление потоком данных (факультативное).
Обеспечивает механизм управления потоком XON/XOFF, который применим ко всему интерфейсу Frame Relay. Он предназначен для тех устройств, высшие уровни которых не могут использовать биты уведомления о перегрузке и которые нуждаются в определенном уровне управления потоком данных.
Форматы блока данных
Формат блока данных изображен на Рис. 14-1. Флаги ( flags ) ограничивают начало и конец блока данных. За открывающими флагами следуют два байта адресной ( address ) информации. 10 битов из этих двух байтов составляют идентификацию (ID) фактической цепи (называемую сокращенно DLCI от "data link connection identifier").
Центром заголовка Frame Relay является 10-битовое значение DLCI. Оно идентифицирует ту логическую связь, которая мультиплексируется в физический канал. В базовом режиме адресации (т.е. не расширенном дополнениями LMI), DLCI имеет логическое значение; это означает, что конечные усторойства на двух противоположных концах связи могут использовать различные DLCI для обращения к одной и той же связи.
Концепція маршрутизації у глобальних мережах. Протоколи груп DVA, LSA.
1 Маршрутизація
1.1 Проблеми маршрутизації в мережах
Маршрут - ланцюжок вузлів зв'язку, через які проходить повідомлення.
1.2 Визначення маршруту
Визначення маршруту може базуватися на різних показниках (величинах, що результирують з алгоритмічних обчислень по окремої змінної - наприклад, довжина маршруту) або комбінаціях показників. Програмні реалізації алгоритмів маршрутизації вираховують показники маршруту для визначення оптимальних маршрутів до пункту призначення.
Для полегшення процесу визначення маршруту, алгоритми маршрутизації
ініціалізують і підтримують таблиці маршрутизації, у яких утримується маршрутна інформація. Маршрутна інформація змінюється залежно від використовуваного алгоритму маршрутизації.
1.3 Транспортування даних
Наступне пересилання може бути або не бути головною обчислювальною машиною остаточного пункту призначення. Якщо ні,то наступним пересиланням, як правило, є інший роутер, що виконує такий же процес ухвалення рішення про комутацію. У міру того, як пакет просувається через об'еднанну мережу, його фізична адреса міняється, однак адреса протоколу залишається незмінним.
Уся процедура маршрутизації орієнтовані на те, що:
1. Повідомлення обов'язково повинне бути доставлене одержувачеві, при цьому не виключається можливість додаткового копіювання повідомлення й відправлення його по інших маршрутах.
2. Можливість підстроювання (адаптації) вибору маршруту залежно від стану
трафіка мережі. (Трафік - мережа доріг).
Вибір того або іншого алгоритму маршрутизації впливає на :
1. Час доставки пакетів.
2. Завантаження, створювану на мережу.
3. Витрати ресурсів у вузлах мережі (буферна пам'ять, час процесорної обробки).
З огляду на, що вибір процедури маршрутизації пов'язаний з поточним станом мережі, цей стан, у свою чергу, може залежати від наступних факторів:
1. Створення додаткового навантаження за рахунок передачі службової інформації, необхідної для пошуку маршруту.
2. Передача пакетів у напрямку, що не приводить до мінімального часу доставки.
3. Передача пакетів у вузол в'язі, що перебуває під великим навантаженням.
4. Зміна топології мережі.
5. Зміна пропускної здатності.
6. Зміна навантаження на лінію зв'язку.
Существуют так называемые «операторы связи», которые содержат собственные каналы и арендуют провайдерам доступ к ним. Собственность каждого оператора, включая все локальные сети провайдеров, подключенные к нему, принято называть «автономной системой». Автономная система – это ряд связанных между собой машин с единой внутренней политикой маршрутизации (IGP – Internal Gateway Protocol). Сами автономные системы посредством мощных каналов соединяются между собой, образуя единую сеть Internet. Но невозможно передать данные каждому маршрутизатору обо всех остальных роутерах. Поэтому принято выделять так называемые «пограничные шлюзы» автономной системы. Все шлюзы соединяются по единой магистрали и обмениваются данными посредством внешних протоколов маршрутизации (EGP – External Gateway Protocol).
К внутренним протоколам относятся RIP и OSPF.
Все протоколы обмена маршрутной информацией стека TCP/IP относятся к классу адаптивных протоколов, которые в свою очередь делятся на две группы, каждая из которых связана с одним из следующих типов алгоритмов:
дистанционно-векторный алгоритм (Distance Vector Algorithms, DVA),
алгоритм состояния связей (Link State Algorithms, LSA).
В алгоритмах дистанционно-векторного типа каждый маршрутизатор периодически и широковещательно рассылает по сети вектор расстояний от себя до всех известных ему сетей. Под расстоянием обычно понимается число промежуточных маршрутизаторов через которые пакет должен пройти прежде, чем попадет в соответствующую сеть. Может использоваться и другая метрика, учитывающая не только число перевалочных пунктов, но и время прохождения пакетов по связи между соседними маршрутизаторами. Получив вектор от соседнего маршрутизатора, каждый маршрутизатор добавляет к нему информацию об известных ему других сетях, о которых он узнал непосредственно (если они подключены к его портам) или из аналогичных объявлений других маршрутизаторов, а затем снова рассылает новое значение вектора по сети. В конце-концов, каждый маршрутизатор узнает информацию об имеющихся в интерсети сетях и о расстоянии до них через соседние маршрутизаторы.
Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях. В больших сетях они засоряют линии связи интенсивным широковещательным трафиком, к тому же изменения конфигурации могут отрабатываться по этому алгоритму не всегда корректно, так как маршрутизаторы не имеют точного представления о топологии связей в сети, а располагают только обобщенной информацией - вектором дистанций, к тому же полученной через посредников. Работа маршрутизатора в соответствии с дистанционно-векторным протоколом напоминает работу моста, так как точной топологической картины сети такой маршрутизатор не имеет.
Наиболее распространенным протоколом, основанным на дистанционно-векторном алгоритме, является протокол RIP.
Алгоритмы состояния связей обеспечивают каждый маршрутизатор информацией, достаточной для построения точного графа связей сети. Все маршрутизаторы работают на основании одинаковых графов, что делает процесс маршрутизации более устойчивым к изменениям конфигурации. Широковещательная рассылка используется здесь только при изменениях состояния связей, что происходит в надежных сетях не так часто.
Для того, чтобы понять, в каком состоянии находятся линии связи, подключенные к его портам, маршрутизатор периодически обменивается короткими пакетами со своими ближайшими соседями. Этот трафик также широковещательный, но он циркулирует только между соседями и поэтому не так засоряет сеть.
Протоколом, основанным на алгоритме состояния связей, в стеке TCP/IP является протокол OSPF.
Класифікація алгоритмів маршрутизації. Приклад реалізації.
Класифікація алгоритмів маршрутизації
Статичні або динамічні алгоритми
Статичні алгоритми маршрутизації взагалі навряд чи є алгоритмами. Розподіл статичних таблиць маршрутизації устанавливется адміністратором мережі до початку маршрутизації. Воно не міняється, якщо тільки адміністратор мережі не змінить його. Алгоритми, що використовують статичні маршрути, прості для розробки й добре працюють в оточеннях, де трафик мережі відносно передбачуваний, а схема мереж і відносно проста.
Динамічні алгоритми маршрутизації підбудовуються до обставин, що змінюються, мережі в масштабі реального часу. Вони виконують це шляхом аналізу вступників повідомлень про відновлення маршрутизації. Якщо в повідомленні вказується, що мало місце зміна мережі, програми маршрутизації перераховують маршрути й розсилають нові із про коректування маршрутизації. Такі повідомлення пронизують мережа, стимулюючи роутери заново проганяти свої алгоритми й відповідним чином змінювати таблиці маршрутизації. Приклад класифікації:
Статичні: прості, фіксовані,
Динамічні: адаптивні.
Є й інша класифікація, варіант 2
Алгоритми маршрутизації можуть бути класифіковані по типах. Наприклад,
алгоритми можуть бути:
• Однорівними або ієрархічними
• З інтелектом у головній обчислювальній машині або в роутері
· Внутрідоменними й междоменними
 ·
Алгоритмами
стану
каналу
або
вектора
відстаней
·
Алгоритмами
стану
каналу
або
вектора
відстаней
Класифікація алгоритмів маршрутизації. Приклад реалізації.