

2.3 Ldpc коды: декодирование
Из (2.4) видно, что, фиксируя переменную степень распределения кода, число дуг в фактор графе такого кода пропорционально n. Это важное свойство LDPC кодов, которое создает их декодирующую сложность линейно с длиной кода, с учетом фиксированного числа итераций. Это связано с тем, что декодирование производится путем передачи сообщения по дугам графа, следовательно, сложность одной итерации порядка Е.
Есть много различных алгоритмов передачи сообщений для LDPC кодов. Целью данного раздела является представление некоторых из этих алгоритмов декодирования. Мы начнем с алгоритма sum–product и, используя интерпретацию декодирования методом sum-product, нам станут понятны другие алгоритмы декодирования.
2.3.1 Алгоритм sum-product
В приложение A описывается алгоритм sum-product в общем виде. Рассматривая основную цель этой главы, мы ориентируемся на упрощенный случай, в котором переменные узлы имеют двоичное значение и функциональные узлы ограничены контролем четности. Не вдаваясь в детали, определим характер сообщений и упрощенные правила их корректировки. Затем мы используем это, чтобы сформировать объяснение декодирования LDPC кодов методом передачи сообщений.
Для
двоичных переменных узлов сообщение
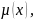 которое является функцией соседнего
переменного узла
которое является функцией соседнего
переменного узла
 имеет только два значения,
имеет только два значения,
 .
Когда сообщения являются функциями
условных вероятностных мер (pmfs),
.
Когда сообщения являются функциями
условных вероятностных мер (pmfs), ,
поэтому передача только одного из
сообщений
,
поэтому передача только одного из
сообщений
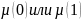 эквивалентна передаче функции
эквивалентна передаче функции
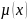 .
Равнозначно мы можем передавать
комбинации
такие, что
.
Равнозначно мы можем передавать
комбинации
такие, что
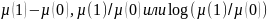 .
Последняя величина
.
Последняя величина
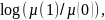 или
в случае pmfs
или
в случае pmfs
 известна,
как отношение логарифмического
правдоподобия (LLR) и
наиболее распространенным типом
сообщения, используемым в литературе.
Причина заключается в том, что здесь
методы корректировки просты и в
компьютерной реализации это можно
представить вероятностными значениями,
которые очень близки к нулю или очень
близки к единице, не вызывая ошибки в
погрешности. Здесь мы только приводим
методы корректировки, когда сообщения
LLR. Для сообщений, взамен
µ, мы используем m, чтобы различать общие
методы передачи сообщений и методы
передачи сообщений LLR.
Методы корректировки для других видов
сообщений можно найти в [29]. Обратите
внимание, что сообщение уже не функция,
а действительное число.
известна,
как отношение логарифмического
правдоподобия (LLR) и
наиболее распространенным типом
сообщения, используемым в литературе.
Причина заключается в том, что здесь
методы корректировки просты и в
компьютерной реализации это можно
представить вероятностными значениями,
которые очень близки к нулю или очень
близки к единице, не вызывая ошибки в
погрешности. Здесь мы только приводим
методы корректировки, когда сообщения
LLR. Для сообщений, взамен
µ, мы используем m, чтобы различать общие
методы передачи сообщений и методы
передачи сообщений LLR.
Методы корректировки для других видов
сообщений можно найти в [29]. Обратите
внимание, что сообщение уже не функция,
а действительное число.
Метод
корректировки узла контроля четности
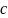

где
 представляет собой LLR
сообщение, отправленное из узла
представляет собой LLR
сообщение, отправленное из узла
 в узел b, и
в узел b, и
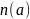 представляет собой представляет собой
совокупность всех соседних узлов
в графе.
представляет собой представляет собой
совокупность всех соседних узлов
в графе.
Метод корректировки переменного узла
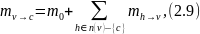
где
 является внутренним сообщением для
переменного узла
.
Внутреннее сообщение вычисляется из
наблюдаемого канала и без использования
избыточности в коде. Декодируемые
сообщения, как правило, посылаются как
внешние сообщения. Внешние сообщения
соответствуют структуре кода и изменяются
итерация за итерацией. Успешное
декодирование улучшает качество внешних
сообщений итерация за итерацией.
является внутренним сообщением для
переменного узла
.
Внутреннее сообщение вычисляется из
наблюдаемого канала и без использования
избыточности в коде. Декодируемые
сообщения, как правило, посылаются как
внешние сообщения. Внешние сообщения
соответствуют структуре кода и изменяются
итерация за итерацией. Успешное
декодирование улучшает качество внешних
сообщений итерация за итерацией.
На
рис. 2.3 показан фактор граф LDPC
кода в декодере. Здесь показаны внутренние
и внешние сообщения на переменный узел
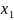 .
Здесь также изображено, что исходящие
сообщения на дугу
.
Здесь также изображено, что исходящие
сообщения на дугу
 ,
соединенные с узлом
(в данном случае
,
соединенные с узлом
(в данном случае
 ),
зависят от всех входящих сообщений на
этот узел, кроме входящих сообщений на
.
Это свойство является одним из основных
направлений анализа LDPC
кодов. На рис. 2.3 функциональные узлы на
левой стороне соответствуют каналу.
Эти функциональные узлы соединяют бит
передатчика с тем же битом приемника.
В зависимости от типа канала и модели
шума, эти функции могут быть вычислены.
),
зависят от всех входящих сообщений на
этот узел, кроме входящих сообщений на
.
Это свойство является одним из основных
направлений анализа LDPC
кодов. На рис. 2.3 функциональные узлы на
левой стороне соответствуют каналу.
Эти функциональные узлы соединяют бит
передатчика с тем же битом приемника.
В зависимости от типа канала и модели
шума, эти функции могут быть вычислены.
MAP решение (примерное MAP решение соответствует наличию циклов) для переменного узла может быть сделано на основании следующего метода решения
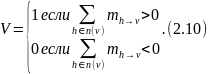
Если
 ,
то обе
,
то обе
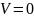 и
и
 имеют одинаковые вероятности и решение
может быть осуществлено случайно.
имеют одинаковые вероятности и решение
может быть осуществлено случайно.
В оставшейся части этой работы, когда мы ссылаемся на алгоритм sum-product, мы имеем в виду упрощенный случай для двоичного кода с контролем четности, если не указано иное.
Рисунок
2.3: Внутренние и внешние сообщения на
переменном узле
 А также внутренние сообщения, которые
влияют на исходящее сообщение на
переменном узле
.
А также внутренние сообщения, которые
влияют на исходящее сообщение на
переменном узле
.
2.3.2 Интерпретация алгоритма sum-product
Когда
сообщение LLR положительно
это означает, что
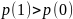 ,
и как только величина этого сообщения
возрастает, сообщение становится более
надежным. В алгоритме sum-product
(и других алгоритмах передачи сообщений)
сообщения, которые переменный узел
посылает своим соседним проверочным
узлам, представляет собой его утверждение
об их значении вместе с мерой надежности.
Кроме того, сообщение, которое проверочный
узел посылает на переменный соседний
узел, есть утверждение о значении этого
переменного узла вместе с некоторой
мерой надежности.
,
и как только величина этого сообщения
возрастает, сообщение становится более
надежным. В алгоритме sum-product
(и других алгоритмах передачи сообщений)
сообщения, которые переменный узел
посылает своим соседним проверочным
узлам, представляет собой его утверждение
об их значении вместе с мерой надежности.
Кроме того, сообщение, которое проверочный
узел посылает на переменный соседний
узел, есть утверждение о значении этого
переменного узла вместе с некоторой
мерой надежности.
В sum-product декодере переменной узел получает утверждение, что все соседние проверочные узлы знают о нем. Переменный узел обрабатывает эти сообщения (в данном случае простое суммирование) и посылает корректирующие утверждения о себе обратно в соседние проверочные узлы. Это может быть понятно, когда достоверность сообщений от переменного узла увеличивается с получением числа (наиболее правильного) утверждений о себе. Это очень похоже на многократный код, который получает составные утверждения для одиночного бита из канала и, следовательно, способный сделать более надежное решение.
Основная задача проверочного узла заставить своих соседей удовлетворять четности. Таким образом, для соседнего переменного узла , он обрабатывает утверждения других соседних переменных узлов о себе и посылает сообщение узлу , которое указывает на утверждение этого проверочного узлов об узле . Знак этого сообщения выбирается так, чтобы воздействовать на контроль четности и его величина зависит от надежности других входящих сообщений.
Вследствие этого, подобно переменному узлу, исходящее сообщение от проверочного узла соответствует обработке всех входящих дуг, кроме одной, которая получает исходящее сообщение. Однако, в отличие от переменного узла, проверочный узел получает утверждение всех соседних переменных узлов про их собственные значения. В результате, надежность исходящего сообщения даже меньше, чем у наименее надежного входящего сообщения. Другими словами, надежность сообщения уменьшается на проверочных узлах. Это также может быть проверено по (2.8), где величина исходящего сообщения меньше, чем у входящих сообщений.
Так, в простых словах, на проверочном узле, мы воздействуем на соседние переменные узлы, чтобы удовлетворить даже проверку четности за счет потери надежности в сообщениях, но на переменном узле мы усиливаем надежность. Этот процесс повторяется многократно, чтобы очистить ошибок, вводимых каналом.
Следуя этой интерпретации алгоритма sum-product, другие алгоритмы декодирования могут быть описаны, как по существу делающие то же самое с меньшей точностью и, возможно, менее сложно.
2.3.3 Другие алгоритмы декодирования
В этом разделе мы представляем ряд важных алгоритмов передачи сообщений, которые по существу являются приближениями алгоритма sum-product. Здесь не показан полный перечень таких алгоритмов, но здесь охвачено большинство алгоритмов, которые будут использоваться в последующих главах этой работы.
Алгоритм min-sum:
В
алгоритме min-sum
метод корректировки на переменном узле
такой же, как в алгоритме sum-product
(2.9), но метод корректировки на проверочном
узле
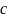 упрощается
упрощается
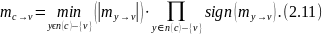
Обратите
внимание, что
 результата
результата
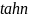 аппроксимируется как минимум абсолютного
значения результирующего знака. Эта
аппроксимация становится более точной
величиной, когда величина сообщения
увеличивается. Таким образом, в последующих
итерациях, когда величина сообщения
обычно большая, низкая вероятность
ошибочного декодирования этого алгоритма
является почти такой же, как и алгоритма
sum-product.
аппроксимируется как минимум абсолютного
значения результирующего знака. Эта
аппроксимация становится более точной
величиной, когда величина сообщения
увеличивается. Таким образом, в последующих
итерациях, когда величина сообщения
обычно большая, низкая вероятность
ошибочного декодирования этого алгоритма
является почти такой же, как и алгоритма
sum-product.
Алгоритм декодирования Галлагера А:
В этом алгоритме, введенном Галлагером [11], сообщение принадлежит алфавиту {0, 1}. Другими словами, используется не программная информация.
Метод корректировки на проверочном узле :

где ⨁ представляет сумму по модулю два двоичных сообщений.
На
переменном узле
,
исходящее сообщение
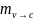 с такое же, как и внутреннее сообщение,
если все внешние сообщения не согласны
с внутренним сообщением. В этом случае
исходящее сообщение такое же, как и
внешние сообщения. Другими словами
с такое же, как и внутреннее сообщение,
если все внешние сообщения не согласны
с внутренним сообщением. В этом случае
исходящее сообщение такое же, как и
внешние сообщения. Другими словами
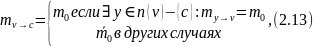
где
является внутренним двоичным сообщением
и
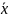 представляет собой дополнение к двоичной
величине
представляет собой дополнение к двоичной
величине
 .
.
В оставшейся части этой работы мы ссылаемся на алгоритм декодирования Галлагера А. Алгоритм имеет худшее исполнение по сравнению с программными методами декодирования, введенными выше, но вычислительно гораздо менее сложный.
Алгоритм декодирования Галлагера Б:
Этот алгоритм также принадлежит Галлагеру и, подобно Алгоритму А, все сообщения имеют двоичное значение. Единственная разница между этим алгоритмом и Алгоритм А это метод корректировки переменного узла. На переменном узле исходящее сообщение
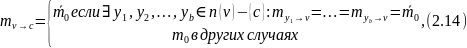
где
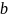 целое число в диапазоне
целое число в диапазоне
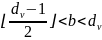 .
Здесь, исходящее сообщение переменного
узла такое же, как внутреннее сообщение,
кроме
внешних сообщений, противоречащих друг
другу. Значение
может меняться от одной итерации к
другой. Оптимальное значение
для равномерного
.
Здесь, исходящее сообщение переменного
узла такое же, как внутреннее сообщение,
кроме
внешних сообщений, противоречащих друг
другу. Значение
может меняться от одной итерации к
другой. Оптимальное значение
для равномерного
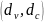 LDPC
кода вычисляется по Галлагеру [11], и
наименьшее число
,
для которого
LDPC
кода вычисляется по Галлагеру [11], и
наименьшее число
,
для которого

где
 и
и
 переходные вероятности канала (внутренняя
величина ошибки в сообщении) и внешняя
величина ошибки в сообщении, соответственно.
С этого момента, мы будем ссылаться на
алгоритм Галлагера Б как на Алгоритм
Б.
переходные вероятности канала (внутренняя
величина ошибки в сообщении) и внешняя
величина ошибки в сообщении, соответственно.
С этого момента, мы будем ссылаться на
алгоритм Галлагера Б как на Алгоритм
Б.
Мы докажем в главе 3, что алгоритм Б является наилучшим из возможных алгоритмов передачи двоичных сообщений равномерных LDPC кодов. Для неравномерных LDPC кодов, мы также покажем, что алгоритм Б самый оптимальный среди всех двоичных алгоритмов передачи сообщений, когда узлы в фактор графе кода не имеют информации об узловых степенях в их местном районе.
В обоих алгоритмах А и Б, сообщения не несут программную информацию. Поэтому не удивительно, что низкая вероятность ошибочного декодирования этих двух алгоритмов, по сравнению с алгоритмом sum-product, низкого качества. Но, конечно, они вычислительно гораздо дешевле. По мере того, как программа декодера (например, декодер sum-product) стремится по направлению сближения, величина сообщений становится очень большой, поэтому программная информация становится менее полезной. Мы используем эту особенность в главе 7, чтобы ускорить процесс декодирования, позволяя декодеру выбрать свой метод декодирования на каждой итерации, и мы увидим, что декодер стремится перейти на алгоритмы аппаратного декодирования в последующих итерациях.
2.4 LDPC коды: анализ
Прежде чем изучать методы анализа LDPC кодов, мы обсудим принцип итеративного декодирования, чтобы стала ясна цель такого анализа.

Рисунок 2.4: Принцип итеративного декодирования.
Итеративный декодер на каждой итерации использует два источника информации передаваемого кодового слова: информация из канала (внутренняя информация), а также информацию из предыдущей итерации (внешняя информация). От этих двух источников информации алгоритм декодирования пытается получить более качественную информацию о передаваемом кодовом слове, с помощью этих данных как внешней информации для следующей итерации (см. рис. 2.4). В успешном декодировании внешняя информация становится все лучше и лучше по мере того, как декодер производит итерацию. Таким образом, во всех методах анализа итеративного декодера статистика внешних сообщений на каждой итерации изучаема.
Изучение эволюции pdf из внешних сообщений итерация за итерацией представляет собой наиболее полный анализ (известный как плотность эволюции). Однако, в качестве приближенного анализа можно проследить за эволюцией представителей этой плотности.
2.4.1 Анализ LDPC кодов Галлагера
В первоначальных работах Галлагера LDPC коды считались равномерными и декодирование предполагало использование двоичных сообщений (алгоритмы А и Б). Галлагер проводил анализ декодера в таких ситуациях [11]. Основной идеей его анализа является характеристика величины ошибок в сообщениях в каждой итерации с точки зрения ситуации в канале и величины ошибки в сообщениях в предыдущей итерации. Другими словами, при анализе Галлагера, эволюция величины ошибки в сообщениях изучаема, она также эквивалентна плотности эволюции, потому что pmf двоичных сообщений является одномерной, т. е. она может быть описана одним параметром.
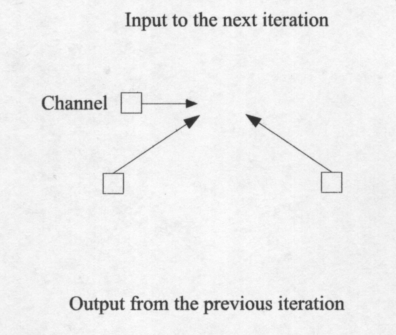
Рисунок 2.5: Дерево декодирования глубины один для равномерного (3, 6) LDPC кода.
Анализ Галлагера базируется на предположении, что входящие сообщения на переменный (проверочный) узел являются независимыми. Хотя это предположение верно, только если граф без циклов, это доказано в [12], где ожидаемая низкая вероятность ошибочного декодирования кода сводится к случаю без циклов по мере увеличения длины блока кода.
2.4.2 Дерево декодирования
Рассмотрим
скорректированное сообщение от
переменного узла
степени
для проверки узла в декодере. Это
сообщение вычисляется из
 входящих сообщений и канального сообщения
к
входящих сообщений и канального сообщения
к
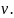 Те
входящих сообщения на самом деле являются
исходящими сообщениями некоторых
проверочных узлов, которые корректируются
ранее. Рассмотрим одно из таких сообщений
вместе с его проверочным узлом
степени
.
Исходящее сообщение этого проверочного
узла рассчитывается из
Те
входящих сообщения на самом деле являются
исходящими сообщениями некоторых
проверочных узлов, которые корректируются
ранее. Рассмотрим одно из таких сообщений
вместе с его проверочным узлом
степени
.
Исходящее сообщение этого проверочного
узла рассчитывается из
 входящих сообщений к
.
Можно повторить эту процедуру для всех
проверочных узлов, связанных с
,
чтобы сформировать дерево декодирования
одной глубины. Пример такого дерева
декодирования для равномерного (3, 6)
LDPC кода показан на рис. 2.5. Продолжая
таким же образом, можно получить дерево
декодирования любой глубины. На рис.
2.6 показан пример дерева декодирования
глубины два для неравномерного LDPC кода.
Очевидно, что для неравномерных кодов
декодирование деревьев с корнем на
разных переменных узлах различно.
входящих сообщений к
.
Можно повторить эту процедуру для всех
проверочных узлов, связанных с
,
чтобы сформировать дерево декодирования
одной глубины. Пример такого дерева
декодирования для равномерного (3, 6)
LDPC кода показан на рис. 2.5. Продолжая
таким же образом, можно получить дерево
декодирования любой глубины. На рис.
2.6 показан пример дерева декодирования
глубины два для неравномерного LDPC кода.
Очевидно, что для неравномерных кодов
декодирование деревьев с корнем на
разных переменных узлах различно.

Рисунок 2.6: Дерево декодирования глубины два для неравномерного LDPC кода.
Обратите
внимание, что, когда фактор граф является
деревом, сообщения в дереве декодирования
любой глубины независимы. Если фактор
граф имеет циклы и его объем
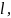 то до глубины
то до глубины
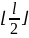 сообщения в дереве декодирования
являются независимыми. Таким образом,
независимое предположение верно до
итераций и является приближенным для
дальнейших итераций.
сообщения в дереве декодирования
являются независимыми. Таким образом,
независимое предположение верно до
итераций и является приближенным для
дальнейших итераций.
2.4.3 Плотность эволюции для LDPC кодов
В 2001 году Ричардсон и Урбанк расширили основную идею анализа LDPC кода, используемую для алгоритма А и В, а также BEC-декодирования других алгоритмов декодирования [13]. Учитывая общий случай, когда алфавит сообщения есть множество действительных чисел, они предложили методику, которая называется плотностью эволюции, которая отслеживает эволюцию pdf сообщения, итерация за итерацией.
Для того, чтобы определить плотность сообщений, они нуждались в особенности канала и декодирования, называются условиями симметрии. Условия симметрии требуют канал и декодирующие методы корректировки, которые удовлетворят некоторым свойствам симметрии следующим образом.
Канал симметрии: канал называется каналом с симметричным выходом, если

где
 есть условное pdf Y
исходного X.
есть условное pdf Y
исходного X.
Проверочный узел симметрии: метод корректировки проверочного узла симметричен, если
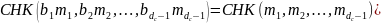
для
любой
 последовательности
последовательности
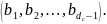 Здесь, CHK() является методом
проверочной корректировки, который
берет
сообщений для генерации одного выходного
сообщения.
Здесь, CHK() является методом
проверочной корректировки, который
берет
сообщений для генерации одного выходного
сообщения.
Переменный узел симметрии: метод корректировки переменного узла симметричен, если
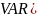
Здесь, VAR () является методом корректировки переменного узла, который берет сообщений вместе с каналом сообщения для генерации одного выходного сообщения.
Условия симметрии возникают потому, что, в соответствии с условиями симметрии, сходимость поведен декодера не зависит от передаваемых кодовых слов, в предположении линейного кода. Таким образом, можно предположить, что кодовое слово из одних нулей передается. При этом предположении, транспортировка сообщения для ‘0’ является верным сообщением и транспортировка сообщения для ‘1’является ошибочным сообщением, для сообщений величина ошибки может быть определена.
Аналитические разработки этого метода можно найти в [13], но во многих случаях она слишком сложна, чтобы быть полезным для непосредственного использования. На практике используется дискретная эволюция плотности [28]. Идея состоит в том, чтобы квантовать алфавит сообщения и использовать pmfs вместо pdfs, чтобы сделать компьютерную реализацию возможной. Качественное описание эволюции плотности и разработка дискретной эволюции плотности для алгоритма sum-product приведено в приложении Б.
Плотность эволюция не является специфическим для LDPC кодов. Это техника, которая может быть принята для других кодов, определенных на графах, связанных с итеративным декодированием. Тем не менее, она становится неразрешимой, когда учредительные коды являются сложными, например, в турбо-кодах. Даже в случае LDPC кодов с простейшим образующим кодом (простая проверка четности), этот алгоритм довольно интенсивных вычислений.
2.4.4 Порог декодирования LDPC кода
Из
разработки дискретной плотности эволюции
становится ясно, что для конкретных
переменных и распределения проверочной
степени плотность сообщений после
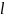 итераций является функцией только
состояния канала. В [13], Ричардсон и
Урбанк доказали, что это худший случай
состояния канала, для которого величина
ошибки в сообщении стремится к нулю, а
число итераций стремится к бесконечности.
Это состояние канала называется порогом
кода. Например, порог равномерного (3,
6) кода на канале AWGN по декодированию
sum-product
1,1015 дБ. Это означает, что если бесконечно
долгий (3, 6) код был использован на канале
AWGN, стремление к нулю количества ошибок
обеспечивается при
итераций является функцией только
состояния канала. В [13], Ричардсон и
Урбанк доказали, что это худший случай
состояния канала, для которого величина
ошибки в сообщении стремится к нулю, а
число итераций стремится к бесконечности.
Это состояние канала называется порогом
кода. Например, порог равномерного (3,
6) кода на канале AWGN по декодированию
sum-product
1,1015 дБ. Это означает, что если бесконечно
долгий (3, 6) код был использован на канале
AWGN, стремление к нулю количества ошибок
обеспечивается при
 более чем на 1,1015 дБ. Если состояние
канала хуже, чем порог, ненулевая величина
ошибок гарантирована. На практике, когда
используются коды конечной длины,
существует разрыв от производительности
к порогу, который растет по мере того,
как длина кода уменьшается.
более чем на 1,1015 дБ. Если состояние
канала хуже, чем порог, ненулевая величина
ошибок гарантирована. На практике, когда
используются коды конечной длины,
существует разрыв от производительности
к порогу, который растет по мере того,
как длина кода уменьшается.
Если порог кода равен пределу Шеннона, то код достигает своей пропускной способности.
2.4.5 Анализ диаграмм внешней передачи информации
Другой подход для анализа итерационного декодеров, в том числе кодов со сложной составляющей кодов, заключается в использовании диаграмм внешней передачи информации (EXIT) [22,38-40].
В анализе диаграмм EXIT, вместо того, чтобы отслеживать плотность сообщений, мы отслеживаем эволюцию одного параметра (мера успеха декодера) итерация за итерацией. Например, можно отслеживать SNR внешних сообщений [22,40], их вероятность ошибки [41] или взаимный обмен информацией между сообщениями и декодированными битами [38]. В литературе термин «EXIT диаграмма" обычно используется, когда взаимная информация является параметром, чья эволюция отслеживается. Здесь мы обобщили этот термин для отслеживания эволюции других параметров. Как станет ясно до конца этой работы, EXIT диаграммы, базирующиеся на основании отслеживания величины ошибки в сообщении, если не самые, то почти одни из самых практичных.
Чтобы
сделать наше короткое обсуждение EXIT
диаграмм более понятным, рассмотрим
EXIT диаграмму на основе отслеживания
размера ошибки в сообщении, то есть
того, что выражает уровень ошибки в
сообщении на выходе одной итерации
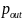 в исчислении размера ошибки в сообщении
на входе
в исчислении размера ошибки в сообщении
на входе
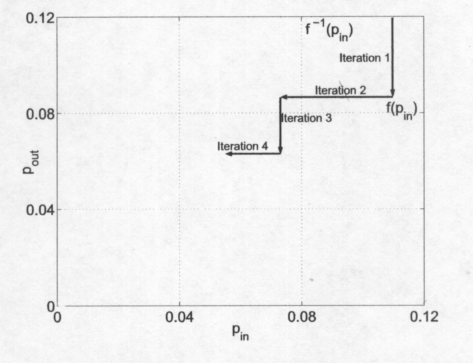
Рисунок 2.7: EXIT диаграмма, основывающаяся на величине ошибки в сообщении.
итерации
и размер ошибки в канале
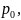 т.е.
т.е.
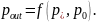
Для
фиксированного
эта функция может быть построена,
используя координаты
 .
Обычно EXIT диаграммы представлены
построением кривой
.
Обычно EXIT диаграммы представлены
построением кривой
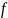 и обратной
и обратной
 .
Это делает визуализацию декодера более
простой, так как выход
от одной итерации перемещается на вход
.
Это делает визуализацию декодера более
простой, так как выход
от одной итерации перемещается на вход
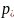 следующей. Рис. 2.7 показывает эту
концепцию. Каждая стрелка на рисунке
представляет собой одну итерацию
декодирования. Видно, что с помощью EXIT
диаграммы можно изучить, количество
итераций, необходимое для достижения
нужного размера ошибки в сообщении.
следующей. Рис. 2.7 показывает эту
концепцию. Каждая стрелка на рисунке
представляет собой одну итерацию
декодирования. Видно, что с помощью EXIT
диаграммы можно изучить, количество
итераций, необходимое для достижения
нужного размера ошибки в сообщении.
Если
«декодирующий туннель" EXIT
диаграммы закрыт, то есть, если для
некоторого
мы имеем
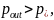 конвергенция не происходит. В таких
случаях мы говорим, что EXIT диаграмма
закрыта. Если EXIT диаграмма не закрыта,
мы говорим, что она открыта. Открытая
EXIT диаграмма всегда ниже
линии в 45 градусов. Порог конвергенции
конвергенция не происходит. В таких
случаях мы говорим, что EXIT диаграмма
закрыта. Если EXIT диаграмма не закрыта,
мы говорим, что она открыта. Открытая
EXIT диаграмма всегда ниже
линии в 45 градусов. Порог конвергенции
 является наихудшим состоянием канала,
при котором туннель открыт, т.е.
является наихудшим состоянием канала,
при котором туннель открыт, т.е.

Подобные формулировки и обсуждения могут быть сделаны для EXIT диаграммы на основании единицы измерения pdf сообщения.
Анализ EXIT диаграммы не столь точен, как плотность эволюции, потому что он отслеживает только один параметр, как представителя pdf. Для многих приложений, однако, EXIT диаграммы очень точны. Например, в [38], EXIT диаграммы используются для аппроксимации поведения итеративных турбо декодеров на гауссовском канале очень точно. В Главе 4, используя EXIT диаграммы, мы покажем, что порог сходимости для LDPC кода на AWGN канале может быть приближен до нескольких тысячных долей дБ от действительной величины. В той же главе, мы используем EXIT графи для разработки неравномерных LDPC кодов, которые выполнены не более чем на несколько сотых долей дБ хуже, чем те, которые скодированы с помощью плотности эволюции. Следует также заметить, что, когда pdf сообщений может быть действительно описана одним параметром, например, в ВЕС, анализ EXIT грдиаграммы эквивалентен плотности эволюции.
Методы получения EXIT диаграмм для турбо кодов описаны в [38,39]. Мы оставляем формальное определение и методы получения EXIT диаграмм для LDPC кодов по каналу AWGN в главе 4. Мы заканчиваем этот раздел, краткое сравнение между плотностью анализ эволюции и анализ EXIT диаграмм.
Плотность эволюции обеспечивает точный анализ бесконечно длинных кодов, и приближенный анализ конечных кодов. Анализ EXIT диаграмм является приближенным анализом даже для бесконечно длинных кодов, если только pdf из сообщения можно задать одним параметром. Таким образом, анализ EXIT диаграммы рекомендуется, только если однопараметрическая аппроксимация плотности сообщения достаточно точна.
С другой стороны, плотность эволюции вычислений и в некоторых случаях трудна в обработке. Анализ EXIT диаграммы быстр и применим ко многим итеративным декодерам. EXIT диаграммы визуализируют поведение итеративного декодера в простой форме и упрощают процесс кодирования LDPC кодов в линейном программировании [42].
В качестве примера и для пояснения обсуждения этой главы, анализ алгоритма А приводится в Приложении C.