

Распознавание образов / Lection_RECOGNITION / LECTURE1 / Лекция1
.docЛекция 1 Введение в распознавание образов
Распознавание образов является важным разделом искусственного интеллекта. В настоящее время это - сложившиеся научное и практическое направление, связанное с решением широкого круга задач, относящихся к проблемам распознавания.
1. Образы и распознавание образов
Образы, с которыми мы встречаемся могут быть разбиты на две категории: абстрактные и конкретные. Примером абстрактных образов могут быть идеи и аргументы. Распознавание таких образов относится к концептуальному распознаванию, которое в данном курсе не рассматривается.
Примером конкретного распознавания является распознавание букв, символов, рисунков, биологических изображений, трехмерных физических объектов, речевых сигналов, электрокардиограмм, электрокардиограмм, сейсмических волн. Некоторые из этих образов - пространственные, другие - временные.
Последние два десятилетия основной интерес был направлен на два основных типа проблем распознавания:
1) Механизм распознавания, осуществляемый живыми организмами. Психологи, физиологи, биологи и нейрофизиологи приложили много усилий для изучения того, как живые организмы воспринимают объекты. Многое из результатов этих исследований отражено в литературе по бионике и другим близким областям.
2) Развитие теории и практики компьютерного решения данной задачи.
Это направление, в котором активно работают как инженеры, так и прикладные математики. Здесь нет единой теории, которая позволила бы решить все виды задач распознавания образов. Большинство методов имеют проблемную ориентацию и примеры решения конкретных задач, связанных с распознаванием изображений и речевых сигналов составляют цель данного курса.
2. Структура системы распознавания образов
2.1. Три фазы в распознавании образов.
В распознавании образов мы можем разделить общую задачу на три фазы:
- получение данных
- предварительная обработка данных
- принятие решения о классификации.
На рис.1 приведено концептуальное представление проблемы распознавания образов. В фазе получения данных аналоговые данные из физического мира собираются с помощью соответствующих преобразователей и превращаются в цифровой формат для компьютерной обработки. На этом этапе физические переменные превращаются в ряд измеримых данных, показанных на рисунке как x(r), если физические переменные представляют собой звук (или интенсивность света) и преобразователь - микрофон (фотоэлемент). Измеренные данные затем используются как вход на второй фазе (предобработка данных) и образуют ряд классификационных признаков на выходе.
Третья фаза - это классификатор, который представляет собой решающую функцию. На рисунке 1.2 показана схематическая диаграмма мультиспектрального сканера и системы анализа данных. Ряд данных ..........- представляют собой пространство признаков и пространство классификации.
Представление образов и приближение их к машинному распознаванию
Представление в виде многомерной векторной формы.
В предыдущем разделе рассмотрено получение данных, измеренных после извлечения данных. Если данные, которые должны быть проанализированы. являются физическими объектами или изображениями, устройство получения данных может быть телевизионной камерой, камерой с высоким разрешением, мультиспектральным сканером или другим устройством.
Одной из функций предобработки данных является преобразование визуального образа в электрический образ или преобразование ряда дискретных данных в математический образ, так чтобы данные было удобно обрабатывать на компьютере. Результатом такой предобработки будет вектор образа, который представляется как точка в пространстве образов.
Чтобы пояснить эту идею рассмотрим простое визуальное изображение как вход системы.
Если изображение сканируется 12-канальным сканером, мы получим для одной точки изображения 12 величин, каждая соответствует отдельной спектральной характеристике. Если изображение рассматривается как цветное, могут быть получены три основных цветовых компоненты, каждая соответствует красному, зеленому и голубому спектральному диапазону. Каждая спектральная компонента может быть рассмотрена как переменная в n-мерном пространстве, известная как пространство образов, каждый образ представляется как точка в пространстве образов.
Соответственно вектор образа представляется как
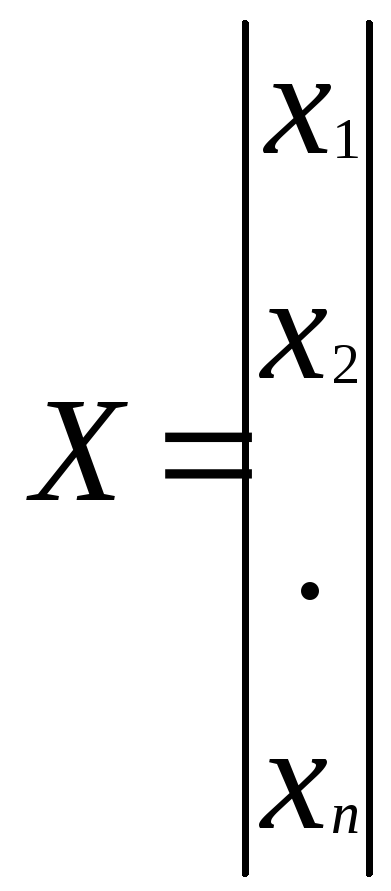 , где
, где
n - представляет размерность. Если n3 пространство может быть проиллюстрировано графически.
Пространство образов X может быть описано набором из m векторов образов ( будем называть их паттернами (pattern=vectors), такое что
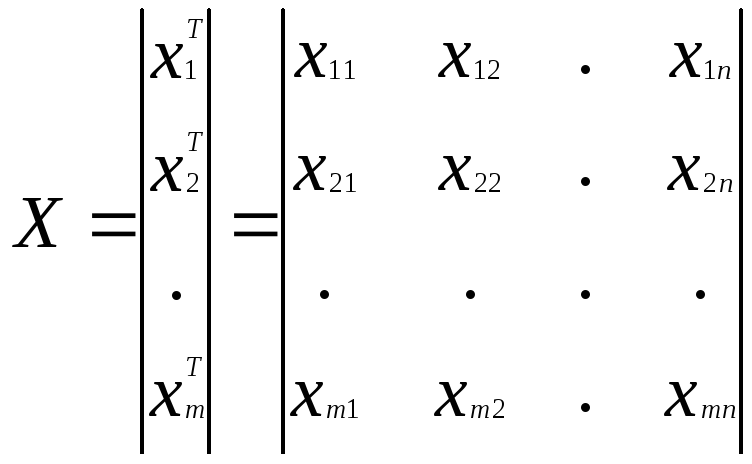
где Т означает транспонирование:
![]() i=1,2,...,m.
i=1,2,...,m.
Блок извлечения признаков осуществляет редукцию размерности. Он преобразует исходные данные в подходящую форму (feature vectors) для использования в процессоре принятия решений для классификации. Очевидно вектор признаков представляется как
![]() ,
i=1,2,...,m.
,
i=1,2,...,m.
имеет меньшую размерность (r n).
Процессор принятия решений на рис 1,2 обрабатывает вектор образа и дает решение о классификации. Как мы обсуждали ранее, вектор образа располагается в пространстве образов как точки и образы, принадлежащие одному классу будут объединены вместе в кластеры. Каждый кластер представляет отдельный класс и кластеры из точек представляют различные классы образов. Принятие решений классификатором осуществляется с помощью ряда решающих функций, определяющих к какому классу относится образ.
Выход решающего процессора определяет классификационное пространство. Оно будет иметь размерность M, если входные образы классифицируются на M классов. Для простейшего случая двух классов M=2. Для аэрофото итерации M может быть равно 10 и более, для распознавания английского алфавита M=26. Однако для случая китайского алфавита M может быть больше 10000. В этом случае требуется другое представление классификатора.
Как препроцессор, так и решающий процессор выбирается пользователем или разработчиком.
Коэффициенты или веса, используемые в процессоре решений вычисляются на базе набора априорных статистических данных об образах, которые должны быть классифицированы или получаются в процессе фазы обучения. В течение фазы обучения обучающая выборка представляется в решающий процессор и коэффициенты подбираются так, чтобы на каждом паттерне получить правильное решение.
Эта процедура может быть названа адаптивным или обучающим процессором. Отметим, что большинство распознающих систем не являются адаптивными on-line, это имеет место только в фазе обучения.
Отметим, что предобработка и решающие алгоритмы не должны быть изолированы друг от друга. Часто схема предобработки должна быть изменена так, чтобы сделать принятие решений более эффективным.
Как было указано ранее, априорные знания для коррекции классификатора на основе некоторых векторов данных необходимы для фазы обучения в решающем процессоре. Такие вектора данных называются прототипами и обозначаются как:
 k=1,2,...,M;
m=1,2,...,Nk
k=1,2,...,M;
m=1,2,...,Nk
где k=1,2,...,M указывает номер соответствующего класса ; m=1,2,...,Nk указывают m-ый прототип класса k; и i=1,2,...,n указывает i-ую компонету в n-мерном k векторе образа M, Nk, и n обозначают соответственно, число классов образов, число прототипов в k-ом классе k и размерность вектора образа.
Прототипы из одного класса обладают некоторыми общими свойствами, поэтому они кластеризуются в некоторой области в пространстве образов. Рис.1.3 показывает простейшие 2-х мерные пространства образов.
Рис.1.3. Простое двумерное пространство образов
Прототипы
![]() кластеризуются
в 1,
прототипы другого класса
кластеризуются
в 1,
прототипы другого класса
![]() кластеризуются
в другой области пространства образов
2;
N1,
N2
-
число прототипов в классах 1,
2
соответственно.
кластеризуются
в другой области пространства образов
2;
N1,
N2
-
число прототипов в классах 1,
2
соответственно.
Проблема классификации будет просто состоять в нахождении разделяющей поверхности, которая будет разделять известные прототипы на правильные классы. Ожидается, что эта разделяющая поверхность будет способна правильно классифицировать другие неизвестные образы на правильные классы.
Так как образы, принадлежащие различным классам будут кластеризоваться в различных областях пространства образов, расстояние между образами как мера подобия между образами в n-мерном пространстве может быть использовано для классификации.
Основные свойства расстояния (distance metrics) могут быть описаны следующим образом:
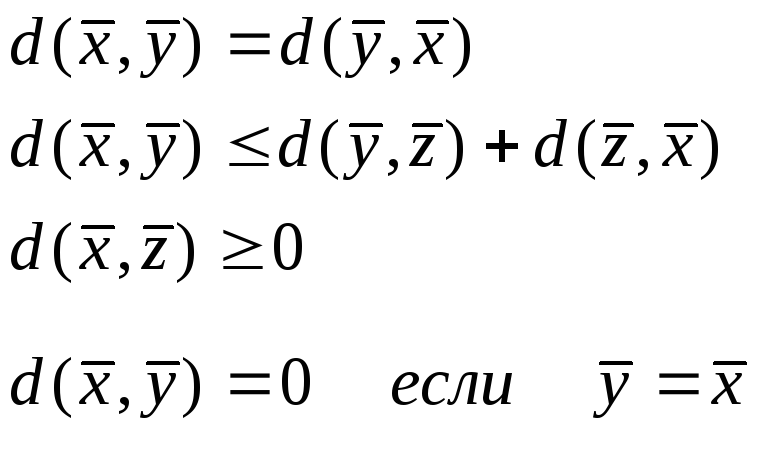
где
![]() -
вектора образов, d(
) -означает
функцию расстояния.
-
вектора образов, d(
) -означает
функцию расстояния.
Подробное рассмотрение этого подхода будет сделано далее.
Лингвистическая форма описания
Рассмотренный выше подход к классификации основывается на векторах признаков. Распознавание каждого образа обычно выполняется путем разделения признакового пространства на области. Этот подход обычно называется теоретическим подходом к решению. Основа этого подхода состоит в эффективном представлении данных в векторной форме.
Однако имеются образы, чьи структурные свойства превалируют в их описаниях. Для таких образов, вероятно, более эффективным будет подход, называемый синтаксическим распознаванием образов. Основой этого подхода является декомпозиция образа на подобразы или примитивы . Распознавание каждого образа обычно выполняется путем разбора структуры образа согласно синтаксическим правилам. Рис.1.4а показывает простой графический образ, состоящий из треугольников и пирамид. Сторона F и треугольник T являются частями объекта А. Треугольники T1 и T2 есть части объекта B.
Рис. 1.4.
Пол и стена образуют фон сцены. Объекты А и B вместе с фоном образуют целую сцену, как показано на рис.1.4а. Рис.1.4 в показывает ее иерархическое представление.
изображение человеческих хромосом является хорошим примером использования синтаксического описания, ввиду их сильной структурной регулярности.
Структурное представление в виде графа:
Грамматический разбор снизу вверх обходим по часовой стрелке:
Структурное описание ??? хромосомы:
Здесь могут быть вариации длины плеч (arms), но основные формы будут те же самые для некоторых типов хромосом, таких как:
Некоторые замечания по использованию теоретического и
синтаксического подхода
Как указывалось выше имеются два подхода - теоретический подход к принятию решения и синтаксический (или структурный) подход. Очевидно выбор каждого подхода зависит от конкретной задачи. Если данные хорошо описываются в виде вектора измерений, то теоретический подход более удобен. В случае, когда структурная информация более богата, то очевидно имеет смысл использовать структурное описание.
Однако во многих задачах можно объединить эти подходы. В частности, для получения описания примитивов можно использовать классификатор, основанный на теоретическом подходе, особенно при обработке искаженных или зашумленных изображений. Далее получив решение о наличии определенных примитивов мы можем применить синтаксический метод.
Примеры использования распознавания образов
Предсказание погоды
В предсказании погоды весьма важным является использование контурных карт распределения атмосферного давления в данной области.
Рис. 1.6. Примеры контурных карт распределения атмосферного давления
На основе опыта работы по предсказанию погоды выделено около 15 типов карт распределения давления, связанных с различной погодой. задача состоит в классификации наблюдаемой карты давления с использованием соответствующих эталонных карт. Для решения этой задачи используется корреляционный метод и метод главных компонент. Изучается возможность использования синтаксического метода классификации, основанного в виде строки и / или дерева описаний.
1.3.2. Распознавание рукописных символов
Эта задача очень важна для автоматической обработки почтовых отправлений, различных бланков учета и т.д. Трудность этой задачи состоит в огромной вариабельности рукописных символов, написанных как разными людьми, так и одним и тем же человеком.
Рис.1.7.
Существует достаточно много систем распознавания рукописных символов. В частности, описана система для распознавания 121 символа, в том числе 52 прописных и строчных букв, 10 цифр и других символов.
1.3.3. Распознавание речи
Распознавание речи имеет многочисленные применения. Это могут быть системы командного управления промышленными установками, автомобилями, компьютером. Широкое применение имеет распознавание слитной речи - автоматическая диктовка текстов. Примерная структура системы распознавания речи показана на рис. 1.8.
Рис. 1.8.
В системе распознавание речи электрические сигналы, полученные от микрофона, поступают в компьютер через аналого-цифровой преобразователь. Затем пропускаются через цифровой фильтр с полосой пропускания 200 - 7500 гц. ,после этого вычисляются специфические параметры, такие как спектральная плотность, мощность, локальные пики спектра, дающие общий образ спектра сигнала. Далее выполняется временная сегментация речевого сигнала и фонемное распознавание. Ошибки сегментации и фонемного распознавания корректируются предварительно запомненными правилами коррекции. Затем определяется максимальное подобие с эталонами слов, хранящихся в словаре и принимается окончательное решение.
1.3.4. Медицинские приложения
Задачи распознавания в медицине очень разноообразны. Сюда относится:
- распознавание состояния сердечной деятельности на основе анализа электрокардиограмм:
- распознавание состояния мозговой деятельности на основе обработки электроэнцефалограмм:
- распознавание легочных заболеваний на основе обработки рентгенограмм.