

4.3 Структуры данных и их представление в озу
Можно указать ряд причин, поясняющих необходимость и удобство использования данных, организованных в некоторую структуру:
- отражение в организации данных логики задачи, объективно существующей взаимосвязи и взаимообусловленности между данными;
- оптимизация последовательности обработки данных;
- широкое применение при обработке данных циклических конструкций – в них при переборе нельзя автоматически менять имя переменной, однако можно изменять индексы;
- неудобство использования большого количества одиночных данных, поскольку это ведет к необходимости использования многих имен.
Перечисленные причины приводят к тому, что в современных языках и системах программирования резервируется широкий спектр различных структур данных и предусмотрена возможность создания структур удобных и необходимых пользователю
Общие замечания по структурам данных:
- логический уровень организация данных отражается в тексте программы – им определяется порядок обработки данных;
- физический уровень представления структур в ОЗУ имеет всего две разновидности: последовательные списки и связные списки; на внешнем ЗУ (ВЗУ) все структуры представляются в виде файлов;
- обработка данных возможна только после их размещения в ОЗУ; с ВЗУ определены только операции записи/чтения;
- идентификаторы, как и у одиночных данных, существуют только в тексте программы и на этапе трансляции переводятся в адреса ячеек памяти.
Примеры структур данных: массив, список, стек, дерево.
Массив – упорядоченная линейная совокупность однородных данных.
Комментарии к определению:
упорядоченная элементы массива пронумерованы;
линейная все элементы массива равноправны;
«однородных» если массив формируется из элементарных данных, то это могут быть данные лишь одного какого-то типа, например, массив чисел или массив символов ( A: array [1…N] of real).
Количество индексов, определяющих положение элемента в массиве, называется мерностью массива.
Если индекс единственный, массив называется одномерным (вектор). Для записи элементов одномерного массива используется обозначение mj, в языках программирования m[j].
Массив, элемент которого имеет 2 индекса, называется двумерным или матрицей (например, g[i, j], где i – номер строки, j – номер столбца, на пересечении которых находится данный элемент).
Максимальное значение индексов определяет размер массива. Размер массива указывается в блоке описания программы, поскольку при исполнении программы для хранения элементов массива резервируется необходимый объем памяти.
Допустимый набор операций над элементами массива определяется типом данных, из которых массив сформирован.
Структура информационного массива определяется один раз на этапе его создания и в процессе использования уже не изменяется.
Что касается количества записей в структурированном информационном массиве, то при представлении его в ОЗУ компьютера возможны 2 ситуации: либо под него выделяется область ОЗУ фиксированного размера, либо размер области при необходимости может меняться.
В первом варианте в начале работы программы происходит резервирование областей ОЗУ для хранения информационных массивов. В процессе выполнения программы могут меняться значения элементов массива, но не его размер. По этой причине в случае, когда размер массива не известен заранее, приходится осуществлять избыточное резервирование, что приводит к нерациональному использованию памяти компьютера.
Информационные массивы, допускающие изменение размера (но не структуры) называются динамическими. В этом случае данные могут иметь последовательное или связное представление в ОЗУ.
Размещение массива в оперативной памяти происходит в один блок ячеек с последовательными адресами (последовательное представление).
№ элемента массива |
№ ячейки ОЗУ |
Содержание |
1 |
3000 |
А[1] |
2 |
3012 |
A[2] |
3 |
3024 |
A[3] |
…. |
… |
… |
N |
3000+(N-1) 12 |
A[N] |
Данные (отдельные элементы массива) размещаются в соседних последовательно расположенных ячейках памяти. На размещение одного элемента может потребоваться несколько ячеек (машинное слово), но их количество одинаково для каждого элемента. Физический порядок следования полностью соответствует логическому. Такая совокупность записей называется последовательным списком.
Для двумерных массивов запись также производится в один последовательный блок. При этом автоматически реализован алгоритм пересчета индексов элемента в соответствующий адрес.
Списки. Список – это набор записей, выстроенных в определенной последовательности.
В отличие от массивов, имеющих статическую природу, списки, как правило, более динамичны по отношению к количеству записей. Для размещения списков в ОЗУ используется связное представление данных. Оно основано на том, что к записи добавляется дополнительное поле, в котором размещается указатель адреса, то есть ссылка на то место в ОЗУ, где располагается следующая запись.
При этом физический порядок размещения записей не соответствует логическому – записи располагаются в любых свободных ячейках ОЗУ, причем не обязательно подряд. Такие структуры называются связными списками.
И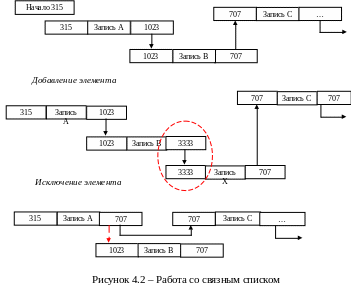 х
удобство состоит в гибкости структуры
– без перезаписи остальных элементов
можно легко добавлять новые или исключать
имеющиеся – для этого достаточно
изменить состояние поля указателя
адреса (рисунок 4.2).
х
удобство состоит в гибкости структуры
– без перезаписи остальных элементов
можно легко добавлять новые или исключать
имеющиеся – для этого достаточно
изменить состояние поля указателя
адреса (рисунок 4.2).
Указатель начала списка называется HeadPointer (HP), конца списка – NIL (пустой указатель).
Недостаток описанного способа представления информационного массива в ОЗУ состоит в том, что в нем невозможно напрямую обратиться к нужной записи – поиск ее осуществляется по цепочке переходов, безусловно, увеличивая время доступа к данным.
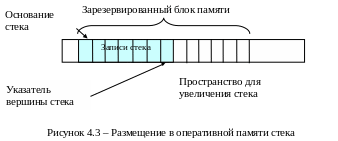
Стеки. Стек – это список, в котором добавление и удаление элементов идет только на одном конце. Следствием такого ограничения является то, что последний добавленный элемент всегда будет удален первым – из-за этого стеки называют структурами LIFO (Last In, First Out).
Тот конец стека, где добавляются и удаляются элементы, называется вершиной. Другой конец называют основанием стека. Процесс добавления записи в стек называется проталкиванием (push), а процесс удаления - выталкиванием (рop).
Работа со стеком иллюстрирует общую идею приложений, использующих процесс выхода из некоторой ситуации путем выполнения действий, которые привели нас туда, в обратном порядке – «откат», вызов процедур и т.п.
Для реализации стека в памяти ОЗУ обычно резервируют блок смежных ячеек памяти достаточного размера, чтобы вместить стек с учетом его увеличения или уменьшения. Решение о размере этого блока зачастую является критическим.
По мере проталкивания и выталкивания записей вершина стека перемещается вперед и назад в пределах зарезервированного блока. Для того, чтобы отслеживать положение вершины, ее адрес хранится в дополнительной ячейке памяти, называемой указателем стека (Stack Pointer) (рисунок 4.3).
Контрольные вопросы
1. Приведите классификационные признаки и соответствующую классификацию данных.
2. Как размещаются в оперативной памяти элементарные данные?
3. Что такое массив? Как размещается массив в памяти компьютера?
4. Что представляет собой связный список?
5. Проиллюстрируйте на примере, как происходит добавление элемента в связный список? удаление элемента из списка?
6. Как выполняются операции добавления/удаления в двунаправленном связном списке?
7. Где используются стеки?