

Методика изучения темы «Обработка текстовой информации».
Тема является первой в базовом курсе, относящейся к содержательной линии «Информационные технологии». В каждом тематическом разделе этой линии учитель должен четко различать теоретическое и технологическое содержание. Теоретическое содержание включает в себя вопросы представления различных видов информации в памяти ЭВМ, структурирования данных, постановки и методов решения информационных задач с помощью технологических средств данного типа. Сюда же следует отнести более подробное изучение принципов работы отдельных устройств компьютера, расширяющее представления учащихся об архитектуре ЭВМ. Технологическое содержание - это знакомство и освоение приемов работы с конкретными прикладными программными системами: редакторами, СУБД, табличными процессорами и пр.
Знакомство учеников с каждым новым для них видом информационных: технологий должно начинаться с рассказа об их областях применения. Желательно, чтобы изучение каждого прикладного программного средства затрагивало следующие его стороны: данные, среду (интерфейс), режим работы, команды управления.
При изучении темы «Обработка текстовой информации» удобно пользоваться следующей схемой:
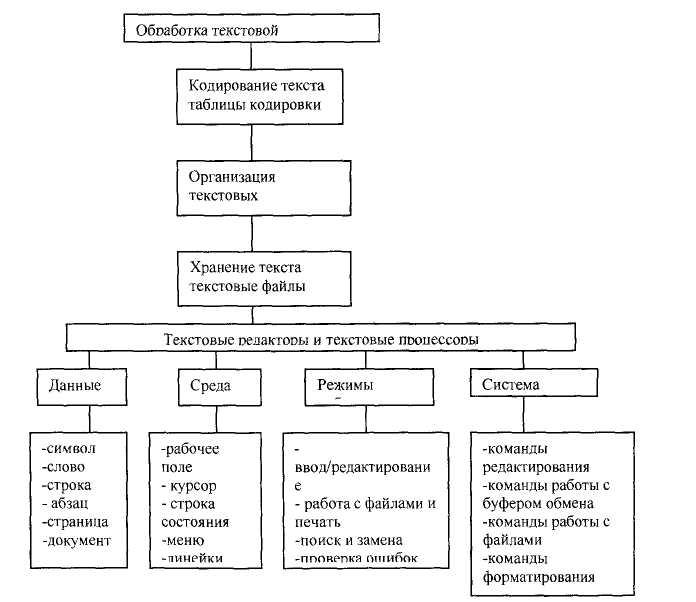
Цели изучения темы в базовом курсе информатики:
Познакомить учащихся со способами представления и организации текстов в компьютерной памяти. Раскрыть назначение текстовых редакторов. Обучить детей основным приемам работы с текстовым редактором.
Изучаемые вопросы:
1. Кодирование текстов.
2. Структура текстового документа.
3. Текстовые файлы.
4. Текстовые редакторы и текстовые процессоры.
5. Практическая работа с текстовым редактором.
1. Кодирование текстов.
Начать объяснение следует с напоминания того, что компьютер может работать с четырьмя видами информации: текстовой, графической, числовой и звуковой. Термин «текстовая информация» и «символьная информация» используются как синонимы. С точки зрения компьютера текст - это последовательность символов, входящих в компьютерный алфавит.
Первая задача - познакомить учеников с символьным алфавитом компьютера. Они должны знать, что:
• Алфавит компьютера включает в себя 256 символов;
• Каждый символ занимает 1 байт памяти;
Необходимо отметить, что каждый символ в памяти компьютера представлен 8-ми разрядным двоичным кодом. Существует 256 различных 8-ми разрядных комбинаций из «0» и «1». Удобство побайтового кодирования очевидно, поскольку байт - наименьшая адресуемая часть памяти, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста.
Далее следует ввести понятие о таблице кодировки. Таблица кодировки - это стандарт, ставящий в соответствие каждому символу алфавита свой порядковый номер. Наименьший номер - 0, наибольший - 256. Двоичный код символа, это его порядковый номер в двоичной системе счисления. Международным стандартом стала система кодов ASCII. От учеников не нужно требовать запоминания кодов символов. Однако некоторые принципы организации кодовых таблиц они должны знать. Необходимо рассмотреть с учащимися таблицу кодов ASCII. Проводя анализ таблицы кодов ASCII важно отметить соблюдение лексикографического порядка в расположении букв латинского алфавита, а также цифр. На этом принципе основана возможность сортировки символьной информации.
В качестве дополнительной информации можно рассказать о том, что проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, то есть в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65 536 символов и можно внести всевозможные национальные алфавиты.
В разделе 1.3 части II учебника Семакин «Информатик базовый курс» рассматривается иной подход к проблем кодирования текста в компьютерной памяти. Этот подход основа на применении алгоритма Д. Хаффмана. Суть его состоит в том, что длина двоичного кода у разных символов может быть разная. Чем чаще символ встречается в тексте, тем его код короче и наоборот — чем символ более «редкий», тем его код длиннее Перекодирование текста из байтового кода путем применения алгоритма Д. Хаффмана позволяет существенно сокращать объем памяти, занимаемый текстом.