

4.4. Сортування.
Сортування - це процес, який дозволяє впорядкувати множину подібних даних у порядку зростання або убування.
Алгоритми сортування достатньо досліджені та вивчені. Різні підходи до сортування мають різні характеристики. Хоча деякі з методів в середньому можуть бути краще інших, жоден з методів не може бути ідеальним, тому кожен програміст повинен мати в своєму розпорядженні декілька різних типів сортування.
Кожен алгоритм сортуванні можна розбити на три частини:
порівняння, що визначає впорядкованість пари елементів;
перестановку, яка змінює місцями пару елементів;
власне алгоритм сортування, який виконує порівняння та перестановку елементів до тих пір, поки всі елементи множини не будуть впорядковані.
Алгоритми методами бульбашки, вибору та включення ми розглянули раніше при вивченні масивів. Звернемо свою увагу на інші методи.
Метод Шелла.
Цей метод запропонував Donald Lewis Shell в 1959 p. Спочатку треба усунути масовий безлад в масиві, порівнюючи елементи, які далеко стоять один від одного. Далі інтервал між елементами, які порівнюються, поступово зменшується до одиниці. На останніх стадіях сортування зводиться до перестановки сусідніх елементів.
Весь масив розбивається на частини. Візьмемо деяке число t і розглянемо тільки ті елементи початкового набору, індекс яких буде кратний t: i=t, 2t,3t, ....
Розглянемо наступний набір даних:
-6,5,0,13,-9,4,8,-15,9,9,3,1
Порівнювати будемо за таким набором t=9, 5,3,2, 1.
Таблиця 4.1. Таблиця сортування за методом Шелла
і |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
t=9 |
-6 |
5 |
0 |
13 |
-9 |
4 |
8 |
-15 |
9 |
9 |
3 |
1 |
|
-6 |
5 |
0 |
13 |
-9 |
4 |
8 |
-15 |
9 |
9 |
3 |
1 |
|
-6 |
3 |
0 |
13 |
-9 |
4 |
8 |
-15 |
9 |
9 |
5 |
1 |
t=5 |
-6 |
3 |
0 |
13 |
-9 |
4 |
8 |
-15 |
9 |
9 |
5 |
1 |
|
-6 |
3 |
0 |
13 |
-9 |
4 |
8 |
-15 |
9 |
9 |
5 |
1 |
|
-6 |
3 |
0 |
13 |
-9 |
4 |
1 |
-15 |
9 |
9 |
5 |
8 |
|
-6 |
3 |
-15 |
13 |
-9 |
4 |
1 |
0 |
9 |
9 |
5 |
8 |
|
-6 |
3 |
-15 |
9 |
-9 |
4 |
1 |
0 |
13 |
9 |
5 |
8 |
|
-6 |
3 |
-15 |
9 |
-9 |
4 |
1 |
0 |
13 |
9 |
5 |
8 |
|
-6 |
3 |
-15 |
9 |
-9 |
4 |
1 |
0 |
13 |
9 |
5 |
8 |
t=3 |
-6 |
3 |
-15 |
9 |
-9 |
4 |
1 |
0 |
13 |
9 |
5 |
8 |
|
-6 |
3 |
-15 |
1 |
-9 |
4 |
9 |
0 |
13 |
9 |
5 |
8 |
|
-6 |
-9 |
-15 |
1 |
0 |
4 |
9 |
3 |
13 |
9 |
5 |
13 |
|
-6 |
-9 |
-15 |
1 |
0 |
4 |
9 |
3 |
8 |
9 |
5 |
13 |
t=2 |
-6 |
-9 |
-15 |
1 |
0 |
4 |
9 |
3 |
8 |
9 |
5 |
13 |
|
-15 |
-9 |
-6 |
1 |
0 |
4 |
5 |
3 |
8 |
9 |
9 |
13 |
t=l |
-15 |
-9 |
-6 |
1 |
0 |
3 |
5 |
4 |
8 |
9 |
9 |
13 |
|
-15 ' |
-9 |
-6 |
0 |
1 |
3 |
4 |
5 |
8 |
9 |
9 |
13 |
Єдиною характеристикою сортування Шелла є приріст - відстань між елементами, що впорядковують, в залежності від проходження. В кінці приріст завжди дорівнює одиниці - метод завершується звичайним сортуванням вставками, але саме послідовність приростів визначає ріст ефективності.
Одним з найкращим є послідовність, яка була представлена Р.Седжвіком. Його послідовшсть має вид
inc[S] =
 9*2s
-9*2
9*2s
-9*2![]() +1 якщо
s
парне
+1 якщо
s
парне
8*2s-6*2![]() +1
якщо
s
непарне
+1
якщо
s
непарне
При використанні такого приросту середня кількість операцій O(n7/6 ), найгіршому випадку - порядку O(n4/3).
Приведемо один з варіантів програм реалізації метода Шелла.
int increment (long inc[], long size)
{
intpl,p2,p3,s;
Pl=p2=p3=l;
s=-l;
do
{ if (++s%2)
inc[s]=8*pl-6*p2 + l;
else
inc[s]=9*pl-9*p3+l;
p2*=2;
p3*=2;
pl*=2;
} while (3*inc[s]<size);
return s>0? -s: 0;
}
template <class T>
void shellSort(T a[], long size){
long inc, i,j, seg[40];
int s;
// обчислення послідовності прирісту
s= increment(seg, size);
 while
(s>=0)
while
(s>=0)
{//сортування включенням з інкрементами іпс[]
inc=seg[s--];
for (i=inc; i<size; i++)
{Ttemp=a[i];
for (j=i-inc; (j>=0)&&(a[j]>temp); j-=inc)
a[j+inc] = a[j];
a[j+inc]=temp;
}
}
}
Сортування злиттям.
Сортування злиттям використовується в тих випадках, коли треба відсортувати послідовний файл, що не поміщається цілком в основній пам'яті. Розглянемо саме поняття злиття. Нехай існують два відсортованих в порядку зростання масивів Р та Q. Крім того є порожній масив R, який треба заповнити значеннями масивів Р та Q в порядку зростання. Для злиття виконуються наступні дії: порівнюють р[1] та q[l], менше значення записується в г[1]. Нехай це будер p[1]. Тодір p[2] порівнюється з q[l], і менше з них заноситься в г[2]. Далі процес повторюється до кінця одного з масивів. В кінці роботи "хвіст" того масиву, що залишився, переписується в масив г.
Для сортування злиттям масиву а[1], а[2], ..., а[n] створюється парний масив b[l], b[2], .... b[n]. На першому кроку виконується злиття елементів а[1] та а[n] з розміщенням результатів у b[l], b[2], злиття елементів а[2], а[n-1] з розміщенням результатів в b[3], b[4],..., злиття елементів а[n/2], а[n/2+1] з розміщенням результату в b[n-l], b[n]. На другому кроку виконується злиття пар b[l], b[2] та b[n-l], b[n] з розміщенням результату в а[1], а[2], а[3], а[4], і т.п.
Таблиця 4.2. Приклад сортування злиттям.
крок |
масив |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
0 |
а |
-6 |
5 |
0 |
13 |
-9 |
4 |
8 |
-15 |
9 |
9 |
3 |
1 А. |
1 |
b |
-б |
1 |
3 |
5 |
0 |
9 |
9 |
13 |
-15 |
-9 |
4 |
8 |
2 |
а |
-6 |
1 |
4 |
8 |
-15 |
-9 |
3 |
5 |
0 |
9 |
9 |
13 |
3 |
b |
-6 |
0 |
|
4 |
8 |
9 |
9 |
13 |
-15 |
-9 |
3 |
5 |
4 |
а |
-15 |
-9 |
-6 |
0 |
1 |
3 |
4 |
5 |
8 |
9 |
9 |
13 |
Робоча функція методу злиття оцінюється як O(n*1nn). Але об'єм пам'яті при цьому дорівнює 2 *n.
Приклад програми методу злиттям.
#include <iostream.h>
#include <conio.h>
void sort (int x[20], int y[20], int z[40], int rl, int r2)
{
int i=j=k=0, min;
if(rl>r2)
min=r2
else min=rl;
for (; i<min|| j<min; ++k)
{
if x[i]>y[j]
{z[k]=y[j];++j;}
else if (x[i]<y[j])
{z[k]=xfij; ++k}
else {z[k]=x[i]; ++k;
z[k]=y[j]; ++k}
}
For (i=0; i<k; ++i)
cout <<z[i] <<end1;
}
void main()
{
int a[20], b[20], c[40], i, razml, razm2;
clrscr();
cout <<введіть розмір масиву а" << end1;
сіn >>razm1;
cout <<"введіть масив а";
for (i=0; i<rozml; ++i)
{ сіn >>а[і];
cout << end1;
}
соut<<"введіть розмір масиву b" << end1;
сіn >> razm2;
cout << "введіть масив b";
for (i=0; i<rozm2; ++i)
{cin >>b[i];
cout << end1;
} sort (a,b,c,razml, razm2);
getch()
}
Пірамідальне сортування.
Назвемо пірамідою послідовність елементів h1, h2,..., hn, таку, що
hi< h2i
hi < h2i+1
для будь-якого і.
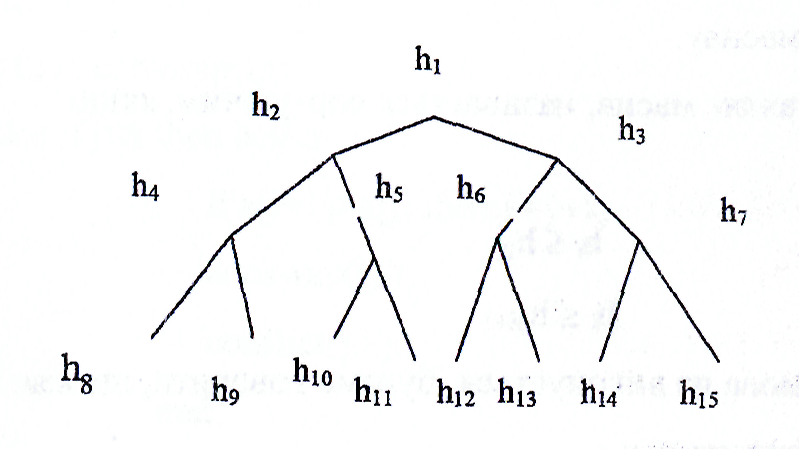
рис.4.3. Розташування елементів масиву в "піраміді".
Для того, щоб добавити новий елемент в дерево, треба:
новий елемент X розташовуємо в вершину дерева;
порівнюємо елементи справа та зліва: вибираємо найменший;
якщо цей елемент менше X - змінюємо їх місцями та переходимо до кроку 2. Інакше кінець процедури.
Розглянемо приклад виконання сортування методом піраміди. Нехай дано масив h1 h2,..., ha Елементи hт/2+1... hn вже утворюють нижній ряд піраміди, тому що не існує індексів і, j : j=2*i (або j=2*i+l). Тут впорядковувати непотрібно. На кожному кроку добавляється новий елемент зліва та просіюється на місце.
Фаза перша: побудова піраміди.
Для масиву А=( 45, 13, 24, 31, 11, 28, 49, 40, 19, 27 ) дерево має вид
13
45
24



31
11
28
49
40
27
19
Фаза друга: сортування масиву.
Дерево, що представляє масив, називається сортуючим, якщо виконується умова
hi< h2i
hi < h2i+1
Якщо для деякого і ця умова не виконується, будемо говорити, що має місце "сімейний" конфлікт у трикутнику і.
Як на першому, так і на другому етапах елементарна дія алгоритму полягає в вирішенні сімейного конфлікту: якщо найбільший із синів більше, ніж батько, то переставляється і цей син. В результаті перестановки може виникнути новий конфлікт у тому трикутнику, куди переставлений батько. У такий спосіб можна говорити про конфлікт роду у піддереві з коренем у вершиш і. Конфлікт роду вирішується послідовним вирішенням сімейних кофліктів проходом по дереву вниз. Конфлікт роду вирішено, якщо прохід закінчився, або ж в результаті перестановки не виник новий сімейний конфлікт.
Робоча функція алгоритму O(n*log2n/2).
Приклад програми методу піраміди:
var a: array[1..10] of real;
k,n,l: integer,
procedure conswap(i,j:integer);
var b:real;
begin
if a[i]<a[j] then begin
b:=a[i]; a[i]:=a[j]; a[i]:=b;
end
end;
procedure confiict(i,k: integer);
var j: integer;
begin
j:=2*i;
if j=k then conswap(i, j)
else if j<k then begin
if a[j+l]>a[j] thenj=j+l;
conswap(i,j);
conflict(j,k);
end
end;
procedure sorttree(i: integer);
begin if i<=n div 2 then begin
sorttree(2*i); sorttree(2*i+l); conflict(i,n);
end
end;
begin
writeln ('vv n');
readln(n);
writeln('vv mas a');
for l:=l to n do
read(a[l]);
sorttree(l);
for k:= n downto 2 do begin
conswap(k,l); conflict(l,k-l);
end;
for 1:=1 to n do
write(a[l]:4:0);
end.
Порозрядне сортування.
Це сортування змістовно відрізняється від методів, які ми розглянули раніше. По-перше, цей метод зовсім не використовує порівняння елементів, які сортуються. По друге, ключ, за яким відбувається сортування, необхідно поділити на частини, розряди числа. Наприклад, слово можна поділити по літерам, число - по цифрам.
До сортування треба знати дві параметри: k та m, де
k - кількість розрядів в самому довгому ключі;
m - розрядність даних: кількість можливих значень розряду числа.
При сортуванні російських слів m =33. Якщо в самому довгому слові 10 літер, то к= 10.
Для шістнадцятирічних чисел m=16, якщо в якості розряду приймати цифру, та m=256, якщо використовувати ділення по байтам.
Ці параметри неможна змінювати в процесі виконання алгоритму.
Порозрядне сортування для списків.
Нехай елементи лінійного списку L є k-розрідні десяткові числа, розрядність максимального числа наперед відомо. Позначимо d(j,n) - j-y справа цифру числа n, яку можна визначити таким чином:
d(j,n)=
[![]() ]%10
]%10
Нехай L0, L1, …., L9 - допоміжні списки, спочатку порожні. Порозрядне сортування складається з двох процесів, ікі мають назву розподілення та збірка та виконуються для j= 1, 2,..., k.
Фаза розподілення розносить елементи L: елементи li списку L послідовно додаються в списки Lm, де m=d(j,li). Таким чином отримуємо десять списків, в кожному з яких j-ті розряди чисел однакові та дорівнюють m.
Фаза збірки складається з об'єднання списків L0, L1 ..., L9 в загальний список
L= L0 => L1 =>L2 => .. =>L9.
Розглянемо приклад роботи алгоритму на списку
0![]() 8
12
56
7
26
44
97
2
37
4
3
3
45
10
8
12
56
7
26
44
97
2
37
4
3
3
45
10
Максимальне число має дві цифри, тож розрядність даних k=2.
Перший прохід, j=l.
Розподілення по першій цифрі справа:
L0: 0 10
L1: порожньо
L2: 12 2
L3: 3 3
L4:44 4
L5:45
L6: 56 26
L7: 7 97 37
L8:8
L9: порожньо
Збірка: з'єднуємо списки L1 один за одним:
L: 0 10 12 2 3 3 44 4 45 56 26 7 97 37 8
Другий прохід j=2. Розподілення по другій цифрі справа:
L0: 0 2 3 3 4 7 8
L1:10 12
L2:26 *
L3: 37
L4: 44 45
L5:56
Le: порожньо
L7: порожньо
Ls: порожньо
L9:97
Збірка:
L 0 2 3 3 4 7 8 10 12 26 37 44 45 56 97
Сортування можна організувати таким чином, щоб не використовувати додаткової пам'яті за допомогою покажчиків.
Приклад програми:
typedef struct slist _{
long val;
struct slist_ *next;
} slist;
//
slist *radix_list(slist *1, int t)
{
//
inti,j, d, m=l;
slist *temp, *out, *head[10], *tail[10];
out=l;
for (j=l; j<=t; J++)
{ for (i=0; i<=9; i++0
{head[i]= (tail[i]=NULL;
while (1 != NULL)
{d=((intXl->vaVm))%(int)l0;
temp = tail[d];
if (head[d]==NULL) head [d] = 1;
l->lnext;
temp->next= NULL;
}
for (i=0; i<=9; i++)
if (headfi] != NULL) break;
l=head[i];
temp = tailp];
for(d=i+l;d<=9;d++)
{ if(head[d] NNULL)
{temp->next=head[d];
temp = tail[d];
}
}
m*=10;
return (out);
}
Порозрядне сортування для масивів sourse[7].
Розглянемо масив
7, 9, 8, 5,4, 7, 7.
Як видно, k=1.
Алгоритм наступний:
Створити масив з m елементів (лічильників).
Присвоїти count[i] кількість елементів sourse, що дорівнює і. Для цього:
а. виконати ініціалізацію count[] нулями,
б. пройти по sourse від початку до кінця, для кожного числа збільшуючи елемент count з відповідним номером. Для нашого прикладу. count[]= {0, 0, 0, 0,1,1,0, 0,3,1,1} /
Присвоїти count[i] значення , яке дорівнює сумі всіх елементів до даного
count[]= {0,0, 0,0,1, 2, 2, 2, 5, 6}
Розставити елементи в масив.
Для кожного числа source[i] ми знаємо, скільки чисел менше нього - це значення зберігається в count[sourse[i]]. Таким чином нам відомо місце числа в упорядкованому масиві: якщо є k чисел менше заданого, то воно повинне стояти на позиції k+1. Виконуючи прохід по масиву soursefj зліва направо, одночасно заповнюючи вихідних масив dest:
for(i=0;i<n;i++)
{
c = sourse[i];
dest [count[c]] =c;
count[c]++;
}
Таким чином, число c=source[i] ставиться на місце count[c], який збільшує значення позиції для наступного числа с, якщо таке буде. Цикли займають (n+m) часу та пам'яті.
Для сортування чисел, що мають k цифр, треба виконати декілька проходів від молодшого розряду до старшого. Робоча функція алгоритму O(k(n+m)).