

6.3Ефективне кодування
Раніше відзначалось, що в більшості випадків букви повідомлень перетворяться в послідовності двійкових символів, без врахування статистичних характеристик повідомлень.
Враховуючи статистичні властивості джерела повідомлення, можна мінімізувати середнє число двійкових символів, потрібних для представлення однієї букви повідомлення, що за відсутності шуму дозволяє зменшити час передачі або об’єм пам’яті запам'ятовуючого пристрою.
Таке ефективне кодування базується на основній теоремі Шенона для каналів без шуму. Шенон довів, що повідомлення, складені з букв деякого алфавіту, можна закодувати так, що середнє число двійкових символів на букву буде скільки завгодно близьке до ентропії джерела цих повідомлень, але не менше цієї величини.
Теорема не вказує конкретного способу кодування, але з неї виходить, що при виборі кожного символу кодової комбінації необхідно прагнути, щоб він ніс максимальну інформацію. Отже, кожен символ повинен набувати значень 0 і 1 по можливості з рівними ймовірностями і кожен вибір має бути незалежний від значень попередніх символів.
Для випадку відсутності статистичного взаємозв'язку між буквами конструктивні методи побудови ефективних кодів вперше були запропоновані Шеноном і Фено. Їх методики суттєво не відрізняються і тому відповідний код отримав назву коду Шенона – Фено.
Код будується наступним чином: букви алфавіту повідомлень виписуються в таблицю в порядку убування ймовірностей. Потім вони поділяються на дві групи так, щоб суми ймовірностей в кожній з груп були б по можливості однакові. Всім буквам верхньої половини як перший символ приписується 0, а всім нижнім 1. Кожна з отриманих груп у свою чергу розбивається на дві підгрупи з однаковими сумарними ймовірностями і так далі Процес повторюється доти, поки в кожній підгрупі залишиться по одній букві.
Розглянемо алфавіт з восьми букв. Ясно, що при звичайному кодуванні (не враховує статистичних характеристик) для представлення кожної букви потрібно три символи.
Найбільший ефект стискування отримується у разі, коли ймовірності букв є цілочисельними відємними степенями двійки. Середнє число символів на букву в цьому випадку точно дорівнює ентропії. Переконаємося в цьому, обчисливши ентропію
![]() , (5.2)
, (5.2)
і середнє число символів на букву
![]() (5.3)
(5.3)
де
![]() – число символів в кодовій комбінації,
що відповідає букві
– число символів в кодовій комбінації,
що відповідає букві
![]() .
.
Приклад 5.2
Характеристики такого ансамблю і коди букв представлені в таблиці. 5.2.
Таблиця 5.2 – Характеристика ансамблю
Букви |
Ймовірність |
Кодові комбінації |
Ступень розбиття |
|
1/2 |
0 |
1 |
|
1/4 |
01 |
2 |
|
1/8 |
001 |
3 |
|
1/16 |
0001 |
4 |
|
1/32 |
00001 |
5 |
|
1/64 |
000001 |
6 |
|
1/128 |
0000001 |
7 |
|
1/128 |
0000000 |
|
Ентропія складе:
![]()
середнє число символів на букву
![]()
У більш
загальнішому випадку для алфавіту з
восьми букв середнє число символів на
букву буде менше трьох, але більше
ентропії алфавіту
![]() .
.
Наприклад для ансамблю, приведеного в таблиці 5.3, ентропія дорівнює 2,76, а середнє число символів на букву 2,84.
Отже, деяка надлишковість в послідовностях символів залишилася. З теореми Шенона виходить, що цю надлишковість також можна усунути, якщо перейти до кодування чималими блоками.
Таблиця 5.3 – Характеристика ансамблю
Букви |
Ймовірність |
Кодові комбінації |
Ступень розбиття |
|
0,22 |
11 |
2 |
|
0,20 |
101 |
3 |
|
0,16 |
100 |
1 |
|
0,16 |
01 |
4 |
|
0,10 |
001 |
5 |
|
0,10 |
0001 |
6 |
|
0,004 |
00001 |
7 |
|
0,002 |
00000 |
|
Розглянемо
повідомлення, утворені за допомогою
алфавіту, що складається всього з двох
букв
і
з ймовірністю появи відповідно
![]() і
і
![]() .
.
Оскільки ймовірність не рівна, то послідовність з таких букв володітиме надлишковістю. Проте при побуквеному кодуванні жодного ефекту не отримаємо. Дійсно на передачу кожної букви треба або 1, або 0, в той час як ентропія дорівнює 0,47.
При кодуванні блоків, що містять по дві букви, отримаємо коди показані у таблиці 5.4.
Таблиця 5.4 – Характеристика ансамблю при двобуквених блоках
Блоки |
Ймовірність |
Кодові комбінації |
Ступень розбиття |
|
0,81 |
1 |
1 |
|
0,09 |
01 |
2 |
|
0,09 |
001 |
3 |
|
0,01 |
000 |
|
Кодування
блоків, що містять по три букви, дає ще
більший ефект. Відповідний ансамбль і
коди приведені в таблиці 5.5. Середнє
число символів на блок дорівнює 1,59, а
на букву 0,53, що всього на 12% більше
ентропії. Теоретичний мінімум
![]() може бути досягнутий при кодуванні
блоків, що включають нескінченну
кількість букв:
може бути досягнутий при кодуванні
блоків, що включають нескінченну
кількість букв:
![]() .
(5.4)
.
(5.4)
Таблиця 5.5 – Характеристика ансамблю при трьохбуквених блоках
Блоки |
Ймовірність |
Кодові комбінації |
Ступень розбиття |
|
0,729 |
1 |
1 |
|
0,081 |
011 |
3 |
|
0,081 |
010 |
2 |
|
0,081 |
001 |
4 |
|
0,009 |
00011 |
6 |
|
0,009 |
00010 |
5 |
|
0,009 |
00001 |
7 |
|
0,001 |
00000 |
|
Слід підкреслити, що збільшення ефективності кодування при укрупненні блоків не пов'язане з врахуванням все більш далеких статистичних зв'язків, оскільки нами розглядалися алфавіти з некорельованими буквами. Підвищення ефективності визначається лише тим, що набір ймовірностей, що отримується при укрупненні блоків, можна ділити на більш близьки по сумарним ймовірностям підгрупи.
Розглянута нами методика Шенона – Фено не завжди приводить до однозначної побудови коди. Адже при розбитті на підгрупи можна зробити більшою по ймовірності як верхню, так і нижню підгрупи.
Таблицю 5.3 можна було б розбити інакше, наприклад, так, як це показано в таблиці 5.6.
При
цьому середнє число символів на букву
виявляється рівним 2,80. Таким чином,
побудований код може виявитися не
найкращим. При побудові ефективних
кодів з основою
![]() невизначеність стає ще більшою.
невизначеність стає ще більшою.
Від вказаного недоліку вільна методика Хаффмена. Вона гарантує однозначну побудову коду з найменшим для даного розподілу ймовірностей середнім числом символів на букву.
Для двійкової коду методика зводиться до наступного. Букви алфавіту повідомлень виписуються в основний стовпець в порядку убування ймовірностей. Дві останні букви об'єднуються в одну допоміжну букву, якій приписується сумарна ймовірність. Ймовірності букв, що не брали участь в об'єднанні, і отримана сумарна ймовірність знову розташовуються в порядку убування ймовірностей в додатковому стовпці, а дві останні об'єднуються. Процес продовжується доти поки не отримаємо єдину допоміжну букву з ймовірністю, рівній одиниці.
Таблиця 5.6 – Інтерпретація характеристика ансамблю
Букви |
Ймовірність |
Кодові комбінації |
Ступень розбиття |
|
0,22 |
11 |
2 |
|
0,20 |
10 |
1 |
|
0,16 |
011 |
4 |
|
0,16 |
010 |
3 |
|
0,10 |
001 |
5 |
|
0,10 |
0001 |
6 |
|
0,04 |
00001 |
7 |
|
0,02 |
00000 |
|
Методика пояснюється прикладом, що міститься у в таблиці 5.7. Значення ймовірностей прийняті ті ж, що і в ансамблі таблиці 5.3.
Таблиця 5.7 – Перетворення для побудова коду за методикою Хаффмена

Для складання кодової комбінації, відповідній даному повідомленню, необхідно прослідити шлях переходу повідомлення по рядках і стовпцях таблиці.
Для наочності будується кодове дерево. З точки, відповідній ймовірності 1, прямують дві гілки, причому гілці з більшою ймовірністю привласнюється символ 1, а з меншою 0. Таке послідовне галуження продовжуємо доти, поки не дійдемо до ймовірності кожної букви. Кодове дерево для алфавіту букв, що розглядається в прикладі таблиці 5.7, наведено на рис.5.2.
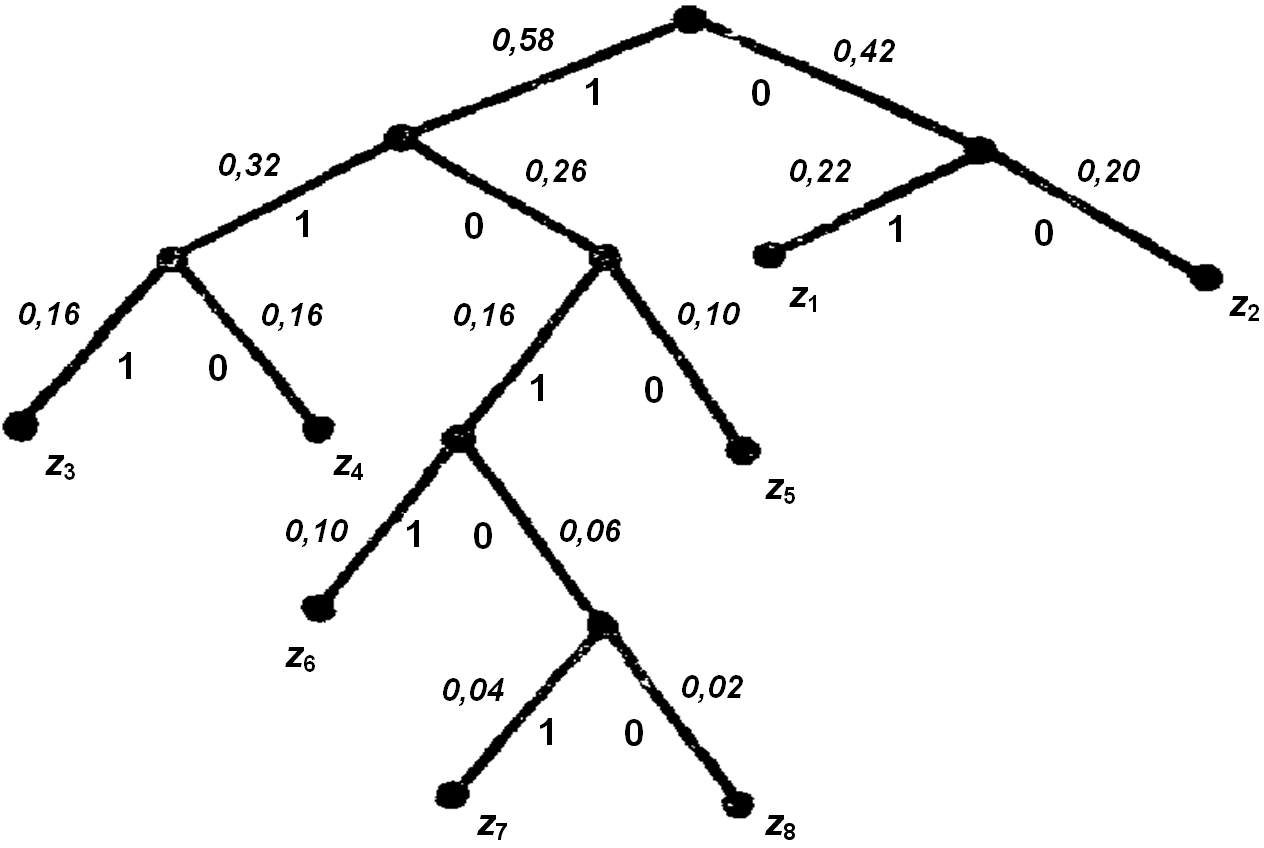
Рисунок 5.2 – Кодове дерево згідно таблиці 5.7, за методом Хаффмена
Тепер, рухаючись по кодовому дереву зверху вниз, можна записати для кожної букви відповідну їй кодову комбінацію:
|
|
|
|
|
|
|
|
01 |
00 |
111 |
110 |
100 |
1011 |
10101 |
10100 |
Розглянувши методики побудови ефективних кодів, неважко переконатися в тому, що ефект досягається завдяки привласненню коротших кодових комбінацій ймовірнішим буквам і довших менш ймовірним буквам. Таким чином, ефект пов'язаний з відмінністю в кількості символів кодових комбінацій. А це приводить до труднощів при декодуванні. Звичайно, для розрізнення кодових комбінацій можна ставити спеціальний роздільний символ, але при цьому значно знижується ефект, оскільки середня довжина кодової комбінації по суті збільшується на символ.
Доцільніше забезпечити однозначне декодування без введення додаткових символів. Для цього ефективний код необхідно будувати так, щоб жодна комбінація коду не збігалася з початком більш довгої комбінації. Коди, що задовольняють цій умові, називаються префіксними кодами. Послідовність комбінацій префіксного коду, наприклад, коду
|
|
|
|
00 |
01 |
101 |
100 |
декодується однозначно:
100 |
00 |
01 |
101 |
101 |
101 |
00 |
|
|
|
|
|
|
|
Послідовність комбінацій непрефіксного коду, наприклад
|
|
|
|
00 |
01 |
101 |
010 |
(комбінація 01 є початком комбінації 010), може бути декодована по-різному:
00 |
01 |
01 |
01 |
010 |
101 |
|
|
|
|
|
|
00 |
010 |
101 |
010 |
101 |
|
|
|
|
|
або
00 |
01 |
010 |
101 |
01 |
01 |
|
|
|
|
|
|
Неважко переконатися, що коди, отримувані в результаті вживання методики Шенона – Фено або Хаффмена, є префіксними.
Розглянемо деякі методи ефективного кодування у випадку корельованої послідовності букв.
Декореляция вихідної послідовності може бути здійснена шляхом укрупнення алфавіту букв. Повідомлення, що підлягають передачі розбиваються на двух-, трьох-, або l-буквені поєднання, ймовірність яких відома
![]() .
.
Кожному поєднанню ставиться у відповідність кодова комбінація по методиці Шенона — Фено або Хаффмена.
Недолік такого методу полягає в тому, що не враховуються кореляційні зв’язки між буквами, що входять до складу наступних, що йдуть один за одним поєднань. Недолік виявляється тим менше, чим більше букв входить в кожне поєднання.
Вказаний недолік усувається при кодуванні по методу діаграм, триграм або l-грам. Умовимося називати l-грамою поєднання з l суміжних букв повідомлення.
Тепер в процесі кодування l-грамма безперервно переміщається по тексту повідомлення
 .
.
Кодове позначення кожної чергової букви залежить від l-1 попередніх букв і визначається по ймовірності різних l-грам на підставі методики Шенона — Фено або Хаффмена.
Конкретне значення l вибирається залежно від міри кореляційного зв’язку між буквами або складності технічної реалізації кодуючих і декодуючих пристроїв.
Слід підкреслити особливості систем ефективного кодування. Одна з них обумовлена відмінністю в довжині кодових комбінацій. Якщо моменти зняття інформації з джерела не керовані (наприклад, при безперервному знятті інформації з запам'ятовуючого пристрою на магнітній стрічці), кодуючий пристрій через рівні проміжки часу видає комбінації різної довжини. Оскільки лінія зв'язку використовується ефективно лише у тому випадку, коли символи надходять до неї з постійною швидкістю, то на виході кодуючого пристрою має бути передбачений буферний пристрій. Він накопичує символи по мірі надходження і видає їх в лінію зв'язку з постійною швидкістю. Аналогічний пристрій необхідний і на приймальній стороні.
Друга особливість пов'язана з виникненням затримки в передачі інформації.
Найбільший ефект досягається при кодуванні довгими блоками, а це приводить до необхідності накопичувати букви, перш ніж поставити їм у відповідність певну послідовність символів. При декодуванні затримка виникає знову. Загальний час затримки може бути великий, особливо при появі блоку, ймовірність якого мала. Це слід враховувати при виборі довжини кодованого блоку.
Ще одна особливість полягає в специфічному впливі завад на достовірність прийому. Одиночна помилка може перевести кодову комбінацію, що передається, в іншу, не рівну їй по довжині. Це спричинить неправильне декодування цілого ряду подальших комбінацій, що називають треком помилки.
Спеціальними методами побудови ефективного коду трек помилки прагнуть звести до мінімуму .