

2.2. Алгоритм навчання хебба
Сигнальний метод навчання Хебба полягає в зміні ваги за таким правилом:
![]() ,(2.1)
,(2.1)
де
![]() – вихідне значення нейрона і шару
(п–1),
– вихідне значення нейрона і шару
(п–1),
![]() – вихідне значення нейрона j
шару (п),
– вихідне значення нейрона j
шару (п),
![]() і
і
![]() – ваговий коефіцієнт сина пса, що з’єднує
ці нейрони в ітераціях t
i t-1
відповідно; η –коефіцієнт швидкості
навчання. Тобто при навчанні за цим
методом підсилюються зв’язки між
збудженими нейронами.
– ваговий коефіцієнт сина пса, що з’єднує
ці нейрони в ітераціях t
i t-1
відповідно; η –коефіцієнт швидкості
навчання. Тобто при навчанні за цим
методом підсилюються зв’язки між
збудженими нейронами.
Диференційний метод навчання Хебба базується на наступному правилі:
![]() (2.2)
(2.2)
де
![]() і
і
![]() – вихідне значення нейрона і шару
(п–1) в ітераціях t
i t-1
відповідно,
– вихідне значення нейрона і шару
(п–1) в ітераціях t
i t-1
відповідно,
![]() і
і
![]() – аналогічно для нейрона j
шару (п). Тобто сильніше навчаються
синапси, що з’єднують ті нейрони, виходи
яких найбільш динамічно змінилися убік
збільшення.
– аналогічно для нейрона j
шару (п). Тобто сильніше навчаються
синапси, що з’єднують ті нейрони, виходи
яких найбільш динамічно змінилися убік
збільшення.
Повний алгоритм навчання Хебба має вигляд:
На стадії ініціалізації усім ваговим коефіцієнтами присвоюються невеликі випадкові значення.
На входи ШНМ подається вхідний образ, і сигнали збудження поширюються по всіх шарах, тобто для кожного нейрона розраховується зважена сума його вході, до якої потім застосовується активаційна (передатна) функція нейрона, у результаті чого отримується його вихідне значення , j=0..Мj-1, де Мj – число нейронів у шарі j, n = 0.. N-1, а N – число шарів у мережі.
На підставі отриманих значень вхідних сигналів нейронів за (2.1) або (2.2) модифікуються ваги.
Якщо вихідні значення ШНМ не за стабілізувалися з заданою точністю, перейти крок b).
На кроці b) поперемінно пред’являються всі образи з вхідного набору.
ШМН після навчання здатна узагальнювати схожі образи, відносячи їх до одного класу, що дозволяє визначити топологію самих класів у вихідному шарі. Для приведення відгуків ШНМ до зручного представлення її доповнюють ще одним шаром, що відображає вихідні реакції в необхідні образи, наприклад, за алгоритмом навчання одношарового перцептрона.
2.3. Алгоритм навчання кохонена
Цей алгоритм навчання без учителя передбачає підстроювання синапсів на підставі їхніх значень на попередній ітерації:
![]() .(3.1)
.(3.1)
Навчання зводиться до мінімізації різниці між вхідними сигналами нейрона, що надходять з виходів нейронів попереднього шару , і ваговими коефіцієнтами його синапсів.
Повний алгоритм навчання має приблизно таку ж структуру, як і у методах Хебба, але на кроці с) з усього шару вибирається нейрон, значення синапсів якого максимально схожі з вхідним образом, і модифікація ваги (3.1) проводиться тільки для нього. При цьому всі інші нейрони шару можуть гальмуватися. Іноді нейрони, що занадто часто „перемагають”, примусово виключаються з розгляду, щоб „зрівняти права” усіх нейронів шару. (Наприклад, включається нейрон, який тільки що „переміг”).
Для SOM після вибору із шару п нейрона j навчаються за (3.1) не тільки він, але й його сусіди, що розташовані в околиці R. Величина R на перших ітераціях дуже велика, тобто навчаються всі нейрони, але з часом вона зменшується до нуля, визначаючи групу нейронів , що відповідають кожному класу.
2.4. Алгоритм навчання процедурою зворотного поширення помилки
Даний алгоритм використовує певну зовнішню ланку, що надає ШНМ, крім вхідних, і цільові вихідні образи, які створюються на попередньому етапі для кожного вхідного образу експертами. Тому такі алгоритми називаються алгоритмами навчання з учителем.
Оцінка реакції прихованих нейронів виробляється обчисленням зваженого значення помилки, знайденої для шару ефекторів. За вагову функцію використовують поточні значення ваги проекційних зв’язків, які йдуть від прихованих нейронів до ефекторів. Помилка немовби поширюється в зворотному діючому ззовні стимулу напрямку. Якщо прихованих шарів декілька перелік помилок наводять для кожного, починаючи з шару ефекторів.
Цільовою функцією помилки ШНМ, що мінімізується, є величина:
![]() ,(4.1)
,(4.1)
де
![]() - реальний вихідний стан нейрона j
вихідного шару N ШНМ
при подачі на її входи р-ого образу;
- реальний вихідний стан нейрона j
вихідного шару N ШНМ
при подачі на її входи р-ого образу;
![]() - ідеальний (цільовий) стан цього нейрона.
- ідеальний (цільовий) стан цього нейрона.
Підсумок ведеться за всіма нейронами вихідного шару і за всіма оброблюваними ШНМ образами. Мінімізація здійснюється за методом градієнтного спуску, тобто ваги модифікуються таким чином:
![]() ,(4.2)
,(4.2)
де
![]() -
ваговий коефіцієнт синапсу, що з’єднує
і тий нейрон шару п-1 з j-тим
нейроном шару п, η –коефіцієнт
швидкості навчання (0<η<1). Похідну
з (4.2) можна подати у вигляді:
-
ваговий коефіцієнт синапсу, що з’єднує
і тий нейрон шару п-1 з j-тим
нейроном шару п, η –коефіцієнт
швидкості навчання (0<η<1). Похідну
з (4.2) можна подати у вигляді:
![]() ,(4.3)
,(4.3)
де
![]() -
вихідний сигнал нейрона j,
-
вихідний сигнал нейрона j,
![]() - зважена сума його вхідних сигналів
(аргумент активаційної функції).
- зважена сума його вхідних сигналів
(аргумент активаційної функції).
Очевидно,
![]() =
=![]() .
.
![]() вказує на те, що
похідна активаційної функції за її
аргументом повинна бути визначена по
всій осі абсцис. (Наприклад, якщо за
активаційну функцію взяти гіперболічний
тангенс, то
=1-s2).
вказує на те, що
похідна активаційної функції за її
аргументом повинна бути визначена по
всій осі абсцис. (Наприклад, якщо за
активаційну функцію взяти гіперболічний
тангенс, то
=1-s2).
![]() ,(4.4)
,(4.4)
Тут підсумовування за k виконується серед нейронів шару (п+1)
Позначимо![]() ,
тоді
,
тоді
![]() .(4.5)
.(4.5)
Для вихідного шару N
![]() .(4.6)
.(4.6)
Тоді (4.2) приймає
вигляд: ![]() . (4.7)
. (4.7)
Повний алгоритм навчання ШМН за процедурою зворотного поширення помилки має вигляд:
Подати на входи ШНМ один з можливих образів в режимі звичайного функціонування мережі.
Розрахувати
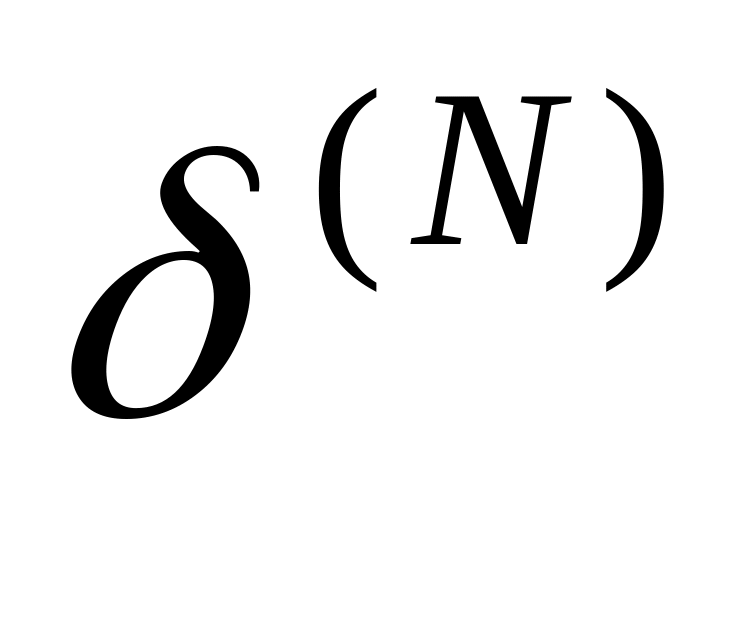 для вихідного шару за (4.6).
для вихідного шару за (4.6).Розрахувати зміни ваг
 для
вихідного шару за (4.5) та (4.7).
для
вихідного шару за (4.5) та (4.7).Розрахувати
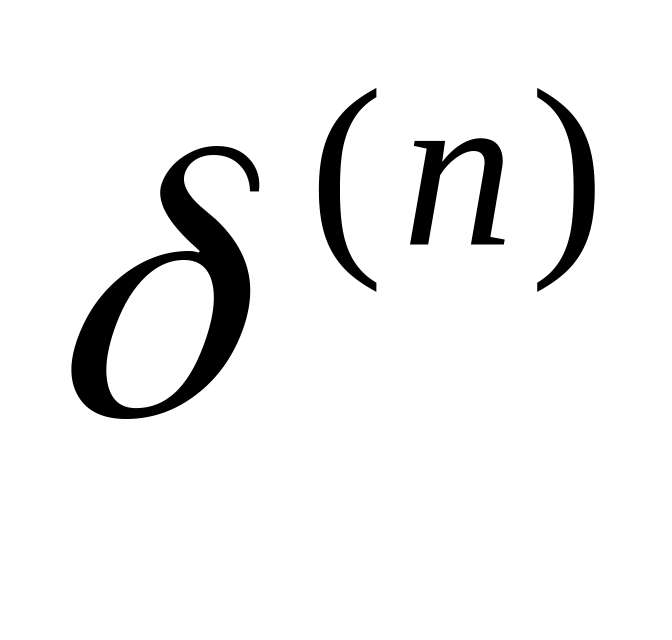 та
та
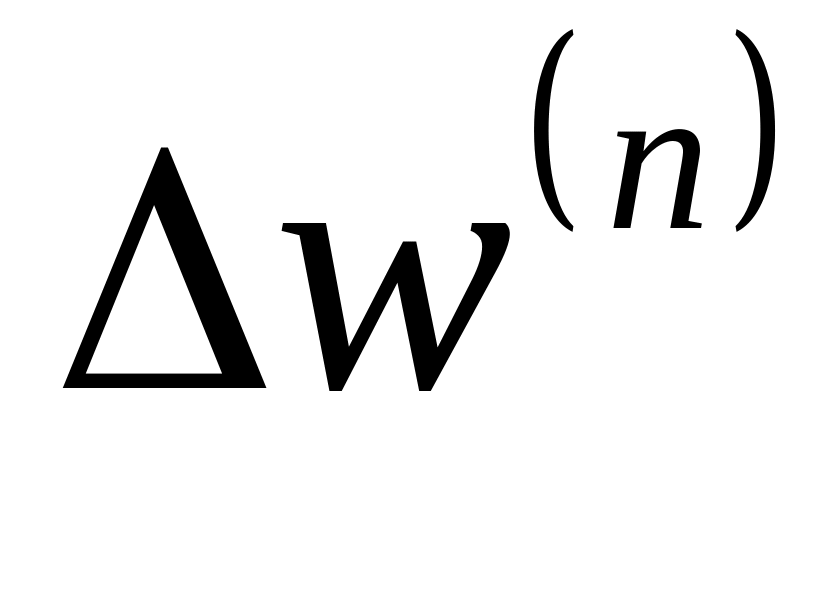 за (4.5) та (4.7) для всіх інших шарів
n=N-1..1.
за (4.5) та (4.7) для всіх інших шарів
n=N-1..1.Скоригувати вагу всіх синапсів у ШНМ
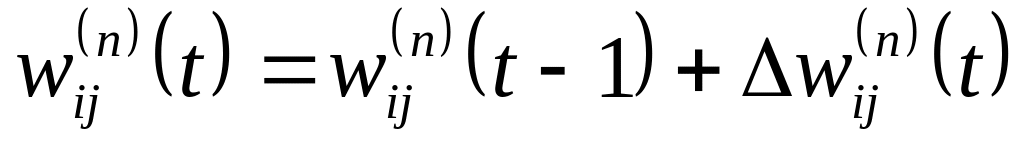 .
.Якщо помилка істота, перейти на а).
ШНМ на кроці 1 поперемінно у випадковому порядку подаються всі тренувальні образи.
Неітеративні ШНМ:
1. Мережа Хопфілда.
Рік розробки:
1982. Автор: Хопфілд. Галузь
застосування: П ошук
і відновлення даних за їхніми фрагментами.
ошук
і відновлення даних за їхніми фрагментами.
Опис: Мережа однорідна і симетрична. Складається з єдиного шару нейронів, кількість яких є одночасно кількістю входів і виходів ШНМ. Кожен нейрон пов’язаний синапсами з усіма іншими нейронами, а також має один вхідний синапс для введення сигналу. Вхідні сигнали утворюються на аксонах. Вхідні сигнали і реакції є компонентами загального вектора станів ШНМ, що запам’ятовуються при навчанні.
На стадії ініціалізації ШНМ вагові коефіцієнти синапсів задаються як:
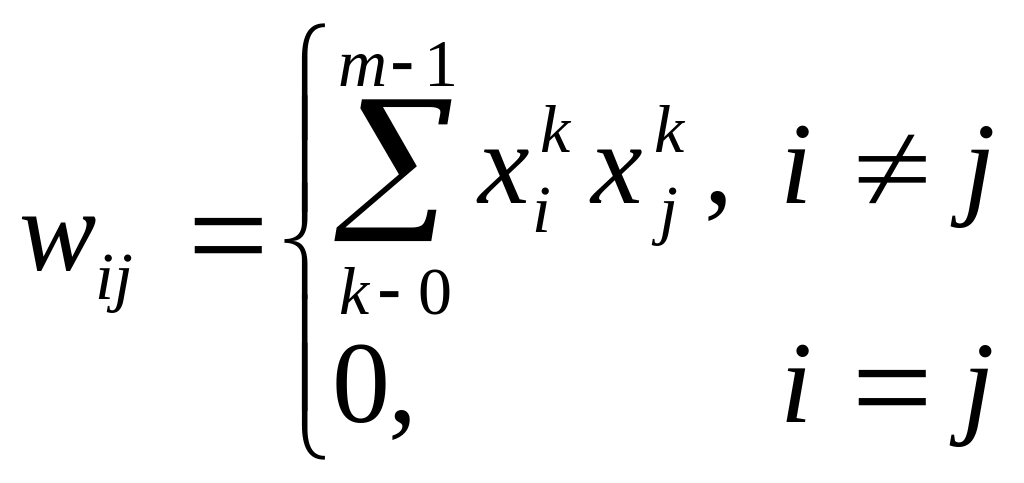
Алгоритм функціонування має наступний вигляд:
На входи мережі подається невідомий сигнал. yi(p)=x, i=0..n-1.
Розраховуємо новий стан нейронів
 ,
j=0..n-1 і нові значення аксонів
yj(p+1)=f[sj+1],
де f – активаційна
функція у вигляді стрибка.
,
j=0..n-1 і нові значення аксонів
yj(p+1)=f[sj+1],
де f – активаційна
функція у вигляді стрибка.Якщо вхідні значення аксонів змінилися, то перехід на пункт 2, інакше – кінець.
2. Карти Кохонена, що само організуються (Self-Organizing Maps- SOM)
Рік розробки:
1980. Автор: Кохонен. Галузь
застосування: В ідображення
однієї діляки на іншу.
ідображення
однієї діляки на іншу.
О пис:
SOM – різновид ШМН, в
яких не змінюється структура мережі, а
тільки підстроюються синапси. Нейрони
розташовуються у вузлах двовимірної
мережі з прямокутними або шестикутними
осередками. При цьому кожен нейрон –
це п-мірний вектор-стовпець. Алгоритм
функціонування є одним з варіантів
кластеризації багатовимірних векторів.
При цьому в ході навчання модифікується
не тільки нейрон-переможець, але й його
сусіди в меншій мірі. За рахунок цього
SOM можна вважати одним
з методів проекціювання багатовимірного
простору простір з меншою розмірністю,
Вектори схожі у вихідному просторі,
виявляються поруч і на отриманій карті.
Величина взаємодії визначається
відстанню між нейронами на карті (див.
рисунок)
пис:
SOM – різновид ШМН, в
яких не змінюється структура мережі, а
тільки підстроюються синапси. Нейрони
розташовуються у вузлах двовимірної
мережі з прямокутними або шестикутними
осередками. При цьому кожен нейрон –
це п-мірний вектор-стовпець. Алгоритм
функціонування є одним з варіантів
кластеризації багатовимірних векторів.
При цьому в ході навчання модифікується
не тільки нейрон-переможець, але й його
сусіди в меншій мірі. За рахунок цього
SOM можна вважати одним
з методів проекціювання багатовимірного
простору простір з меншою розмірністю,
Вектори схожі у вихідному просторі,
виявляються поруч і на отриманій карті.
Величина взаємодії визначається
відстанню між нейронами на карті (див.
рисунок)
3. Мережа зустрічного поширення (Counterpropogation)
Р ік
розробки: 1986. Автор: Хетч-Нильсен.
Галузь застосування: Стиск даних
оцінка, ефективності капіталовкладень.
ік
розробки: 1986. Автор: Хетч-Нильсен.
Галузь застосування: Стиск даних
оцінка, ефективності капіталовкладень.
Опис: Має два шари з послідовними зв’язками: шар Кохонена (навчається без учителя методом змагання) і шар Гроссенберга (навчається із учителем, використовуючи бажані значення виходів).
4. Мережа зворотного поширення помилки (Back propogation)
Р ік
розробки: 1974. Автор: Вербос,
Паркер, Румельхард. Галузь застосування:
Синтез мови, адаптивний контроль руху
роботів, оцінка ефективності
капіталовкладень.
ік
розробки: 1974. Автор: Вербос,
Паркер, Румельхард. Галузь застосування:
Синтез мови, адаптивний контроль руху
роботів, оцінка ефективності
капіталовкладень.
Опис: Нульовий шар виконує розподільні функції. Вхідний сигнал проходить через нього до нейронів прихованого шару. І кожен нейрон наступних шарів видає сигнали уі і помилки δі=yi-di, де di ідеальне значення вихідного сигналу.
МІСТКІСТЬ ШНМ
Місткістю ШНМ називають кількість образів, запропонованих на її входи, які вона спроможна розпізнати.
У мережі Хопфілда кількість запам’ятованих образів не може перевищувати 14% від кількості нейронів. При наближенні до цієї межі з’являються неправдиві атрактори, що перешкоджають конвергенції до запам’ятованих станів. Можлива втрата стаціонарності.
Для ШНМ із двома шарами (вихідним та прихованим) детермінована місткість Cd оцінюється так:
![]() ,
,
де
![]() - кількість ваг, що повлаштовуються,
- кількість ваг, що повлаштовуються,
![]() - кількість нейронів у вихідному шарі.
При чому дана оцінка використовується
для мереж, де кількість входів
- кількість нейронів у вихідному шарі.
При чому дана оцінка використовується
для мереж, де кількість входів
![]() і нейронів у прихованому шарі
і нейронів у прихованому шарі
![]() задовольняє нерівностям:
задовольняє нерівностям:
+ > ,
/ >1000.
Проте, дана оцінка використовувалась для ШНМ з активаційними функціями у вигляді порога, а місткість ШМН зі гладкими функціями значно більша. Те, що дана оцінка детермінована, вказує на можливість її використання абсолютно для всіх можливих вхідних образів, які можуть бути подані входами. Насправді розподіл вхідних образів, як правило, має певну регулярність, що дозволяє ШМН робити узагальнення і таким чином збільшувати реальну місткість. Якщо розподіл невідомий, то говорити про реальну місткість можна тільки приблизно, але вона разів у два може перевищувати детерміновану.
Для ШМН, де більше двох шарів, місткість залишається відкритою.
Необхідна потужность вихідного шару ШНМ, що виконує остаточну класифікацію образів, розраховується з кількості класів образів. Наприклад, для двох класів достатньо одного виходу (при цьому кожний логічний рівень 1 або 0 позначатиме окремий клас), для 4 класів достаньмо 2 виходи и т.д.
Проте надійність результатів роботи такої ШНМ не дуже велика. Для її підвищення бажано ввести надмірність виділення кожному класу одного нейрона у вихідному шарі або, ще краще, декількох, кожний з яких навчається визначати приналежність образу до класу зі своїм ступенем достовірності. Такі ШНМ дозволяють класифікувати вхідні образи, об’єднані у нечіткі (розмиті або такі, що перетинаються) множини. Ця властивість наближає ШМН до умов реального життя.