

Дискриминантный анализ / DIALOG_D
.DOCДемонстрация работы с пакетом STATISTIKA .
Раздел дискриминантный анализ.
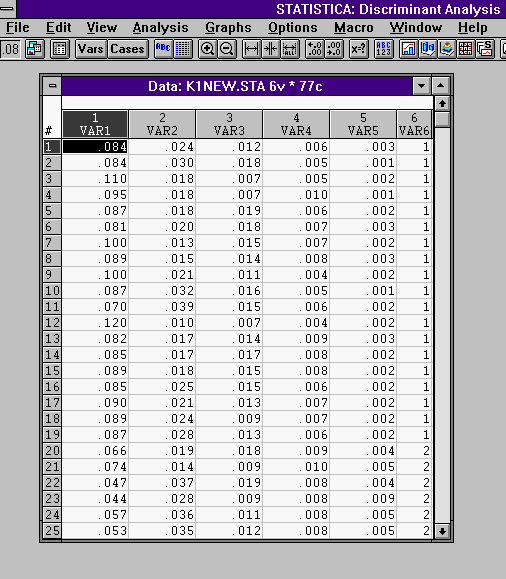
Демонстрацию работы пакета программ STATISTIKA рассмотрим на примере анализа данных медицинских исследований. Эти данные содержатся в файле k.sta. При проведении дискриминантного анализа разделим исходные данные на подготовительные (содержащиеся в файле k1new.sta) - для построения классификационной модели и контрольные (k2new.sta) - для оценки полученной модели.
После запуска пакета STATISTIKA и выбора раздела дискриминантного анализа необходимо задать имя файла с требуемой статистикой.

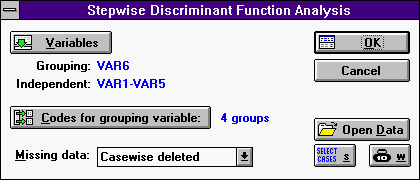
В опции Analysis выберем StartUp Panel (Ctrl-S) - появится окно пошагового дискриминантного анализа:

1. Нажмите кнопку Variables. Появится окно:

В этом окне выберем группируемую переменную, то есть переменную по которой будет проведена классификация, и список независимых переменных.
В нашем примере в качестве группируемой переменной выступает VAR6. Переменные VAR1-VAR5 - независимые переменные.
2. Кнопка Codes for grouping variables позволяет задать количество групп (выбрать интересующие значения группируемой переменной) в которые будут классифицироваться элементы выборки. По умолчанию, задается максимальное количество групп (по количеству возможных значений группируемой переменной). В нашем случае количество групп полагаем равным 4 (см. ниже).


3. Установим в missing data значение casewise deleted, то есть при анализе будем игнорировать выборки с отсутствующими данными.
4. После ввода необходимых данных нажмем OK.
Если для введенных данных возможно проведение дискриминантного анализа, то появится окно определение модели:







Нажмем кнопку Review...:

В этом окне можно просмотреть значения средних, стандартных отклонений и корреляций для всех переменных.
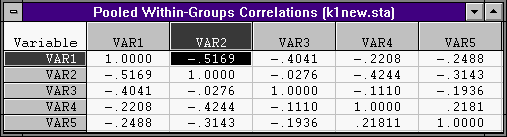
1. Нажав кнопку Pooled within-groups covariances & correlation мы увидим:
внутригрупповую матрицу ковариаций

и корреляций
2. Нажав кнопку Total covariances & correlation мы увидим:
полную матрицу ковариаций:
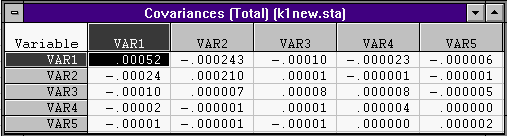
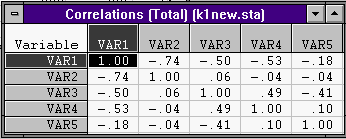
и корреляций
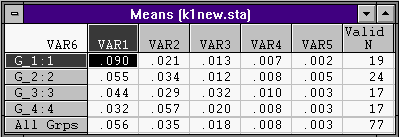
3. В кнопке Means & number cases:
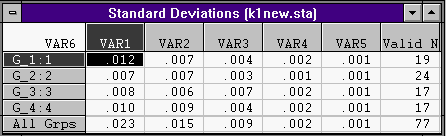
4. В кнопке Standard devilation:
5. В кнопке Categorized Histogram можно посмотреть распределение значений любой переменной относительно заданных групп. Например, для переменной VAR1 гистограмма будет иметь следующий вид:
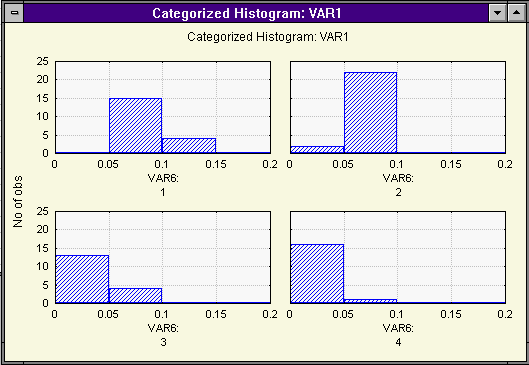
6. В кнопке Box & Whisker plot можно посмотреть диагрммы различных числовых характеристик. Например, для VAR1
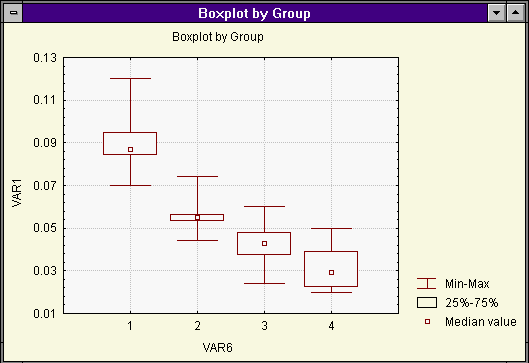
После задания необходимых переменных и просмотра числовых характеристик нашей выборки нажмем OK. Если параметры заданы верно (0=<F-исключения<F-включения), то перед нами откроется окно результатов дискриминантного анализа:
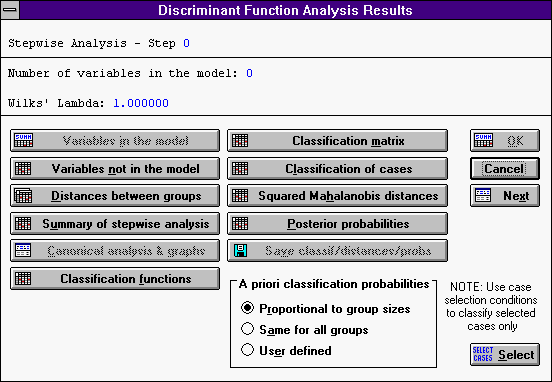
На 0 шаге прямого пошагового анализа все переменные находятся не в модели.
Кнопка Variables not in the model:




Зададим априорную вероятность равную для всех групп (same for all groups)
Выполним 1 шаг дискриминантного анализа - нажмем кнопку NEXT.
В модели VAR1 :


Не в модели:


Рассмотрим матрицу классификаций:

Из матрицы видно, что неверно классифицировано 19 ( не диагональные элементы ) из 77 элементов выборки.
Также это можно увидеть из таблицы апостериорных вероятностей:
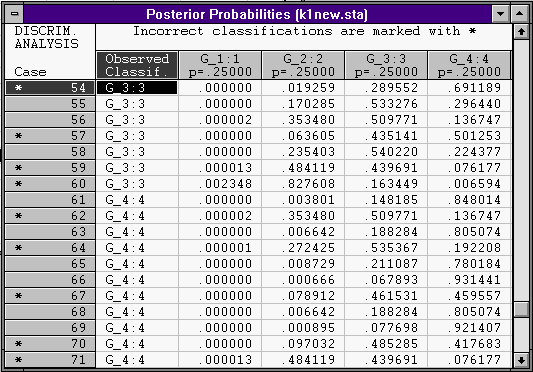
Звездочками обозначены неверно классифицированные элементы выборки.
Выполним все шаги дискриминантного анализа. В результате все переменные попадут в модель:

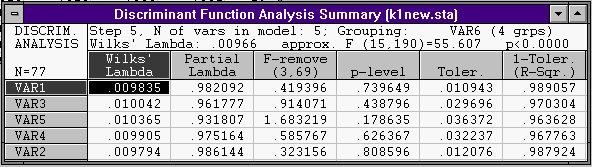
Значения Wilks’лямбда близки к 0, что говорит о хорошем различии между группами.
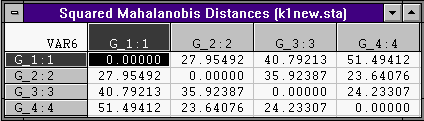
Расстояния между центрами групп также достаточно велико:
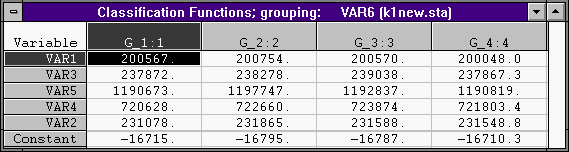
Функции классификации имеют следующий вид:
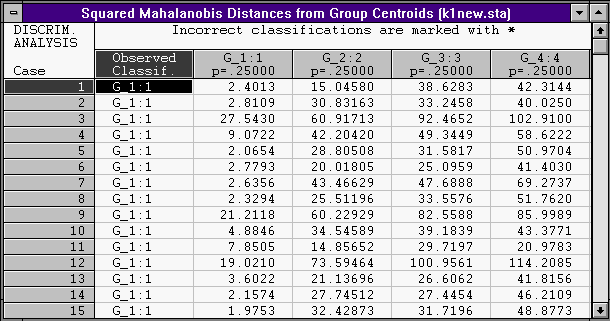
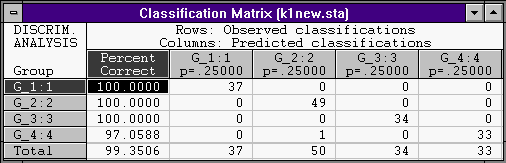
Классификационная матрица показывает, что все элементы выборки верно классифицированы:

Вычислены квадраты расстояний Махалонобиса до центров групп:
Апостериорные вероятности вычисляются пропорционально этим расстояниям:

Проведем тестирование построенной дискриминантной модели: для этого добавим к нашей выборке данные из файла k2new.sta, которые не участвовали в построение модели.
В результате получим следующие данные.
Матрица классификаций:
Из новой выборки только один элемент неверно классифицирован.
Это можно посмотреть в таблице апостериорных вероятностей:

Результаты классификации контрольных данных показывают, что построенная модель приемлима для обработки данных медицинских исследований.