

Мультипроцессорная система Power Scale.
В системах СМП существует планировщик задач. Это такая программа, которая запускает следующий разрешаемый вычислительный процесс на первом же освободившемся процессоре.
Поскольку мы стремимся к увеличению числа параллельных процессоров и в системе возрастает число процессоров, то в сложных многопроцессорных системах, становится высокая вероятность перемещения процессора с одного на другое. Возникает внутренняя миграция вычислительных процессоров.
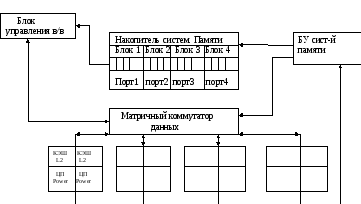
Этот эффект увеличивает информационный обмен между КЭШами, который снижает общую производительность системы. Поэтому стремятся обеспечить физическую реализацию когерентности КЭШа. Для этого на приведенной структурной схеме система Power Scale содержит разделяемую оперативную память. Эта память состоит из двух блоков: накопитель системной памяти и блок управления системной памятью.
В состав системы входят 4 производственных блока. Внутри каждого имеется по 2 процессора. Каждый со своим КЭШом. Основным средством доступа процессоров к разделяемой оперативной памяти – является сложная систематическая шина.
Эта шина состоит из 2-х частей. Внизу эта шина адресации и управления. 4 шины-от системного накопителя и 4- процессора. Шины соединены между собой скоростным матричным коммутатором данных. К коммутатору подключен порт со своим блоком управления.
Интересным является тот факт, что здесь применено расслоение памяти: каждый из 4-х блоков накопителя содержит 4 слоя памяти. Это расслоение позволяет обращаться к памяти нескольких процессоров одновременно. Каждый блок имеет свой выделенный порт памяти для пересылки данных. Общая шина адреса и управления обеспечивает, что на уровне системы все адреса памяти являются когерентными.
Архитектура вычислительных систем с распределенной разделяемой памятью.
В системе с симметричной мультипроцессорной архитектурой время обращения к общей памяти одинаково. Такие системы еще называются Uniform Memory Architecture. Помимо систем с широкой шиной, получила развитие концепция процесса разделения памяти Distributed Shared Memory. Здесь имеется физическая память с общим адресным пространством. Доступ к этой памяти осуществляется посредством команд «чтение-запись».
Системы с распределенной разделяемой памятью – являются развитием систем СМП и подразделяются на 3 класса:
-
NUMA (Non Uniform Memory Architecture )
-
COMA (Cache Only Memory Architecture )
-
RM (Reflective Memory )
Все приведенные классы систем, различаются организацией операционной памяти и организацией информационного обмена, разделенных процессоров через разделяемую память.
Архитектура numa.
При создании этой архитектуры разработчики стремились объединить достоинства от систем СМП.
Создатели архитектуры NUMA предложили набор кластеров, которые соединены в межкластерные шины.
Адресное пространство с помощью старших разрядов адреса делятся между кластерами. Когда процессор обращается к памяти, он посылает адрес к своему контроллеру памяти.
Резидентная память кластера связана с процессором через некоторую локальную шину. Контроллер анализирует старшие разряды адреса, и по ним определяет в каком модуле находится требуемая ячейка памяти. Если адрес локальный, то запрос выставляется на локальную шину, либо на кластерную шину.
Следует заметить, что локальный запрос выполняется быстрее, чем удаленный.
Здесь существует проблема обеспечения когерентности КЭШов, т.е. обеспечение идентичности всех копий данных в системе. В следующей архитектуре сделана попытка аппаратными средствами решить эту проблему.
СС- NUMA => Cache Coherent NUMA.
Отличием СС- NUMA является использование аппаратуры для связки механизма работы КЭШ памяти вычислительного модуля с удаленным блоком памяти других модулей.
Такая архитектура была применена разработчиками:
NUMA Q2000.
Р6 Р6 Р6 Р6 Вычислительный
модуль
Вход Выход
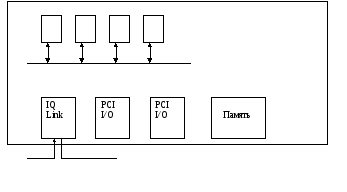
Каждый вычислительный модуль является системой СМП и содержит 4 процессора Pentium Pro. Основой модуля является системная шина, которой кроме процессора подключена память 4гб. Этот модуль содержит 2 моста с шинами PCI и адаптер IQ Link. Через мосты PCI к модулю подключено внешнее устройство. Адаптер IQ реализует протокол когерентности КЭШей . содержит блоки подключения входных и выходных Linkов при работе этого вычислительного модуля в составе системы.
Такой модуль может работать как самостоятельно, так и в составе системы.
В составе системы это выглядит следующим образом:
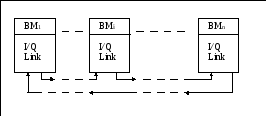
В адаптер вводится дополнительно удаленный КЭШ 3-го уровня. В этом КЭШе хранятся копии строк данных, загружаемых из удаленных блоков памяти. Этот КЭШ обслуживает обращение к данным при отсутствии требуемой строки, при отсутствии КЭШа и в блоке локальной памяти.
Локальная память вычислительного модуля отображается в единое для системы глобальное адресное пространство.
Попадание в определенный диапазон определяется идентификатором. Он используется для маршрутизации пакета, который доставляет требуемую строку КЭШ память.
Для быстрого определения строк используется специальный каталог.
Существенной особенностью организации памяти в системах NUMA, является то, что в ней объединены передача данных в течении когерентности от передач данных, связанных с в/в и обменом между процессором и памятью.
График в/в и график процессорной памяти выполняются параллельно. Существенным достоинством систем СМП является простота. Обеспечивается быстрый доступ ко всем частым оперативной памяти.
Архитектура СС- NUMA.
Одна из основных проблем при создании разделяемой памяти в мультипроцессорных системах, состоит в том, как извещать другие процессоры об изменениях, вызванных выполнением команд записи. Для идентификации удаленных копий данных используются 2 протокола: коммуникационный и протокол когерентности.
Коммуникационный протокол используется для доставки сообщений. Протокол когерентности используется для предотвращения использования копий тех данных, которые изменились в другом процессоре.
При разработке протоколов используются модели состоятельности памяти. Простейшей является модель строгой состоятельности. Операция чтения из разделяемой памяти в этом случае должна доставлять в процессор последнее записанное значение переменной. Поэтому когда одна из копий переменных модифицируется, то все остальные копии других переменных так же должны быть модифицированы. Для выполнения такой модели требуются дополнительные аппаратные средства. Использование этих средств снижает производительность системы. Это получается из-за того, что для синхронизации необходимо вводить единое глобальное время в многопроцессорную систему. Поэтому, в реальных системах чаще всего используются модели не полной состоятельности данных. В это случае допускается появление не согласованных копий данных в ходе параллельной обработки, при условии, что эта несогласованность не влияет на конечный результат.
При построении разделяемой памяти, существенными являются характеристики:
- способ реализации механизмов управления работой этой памяти. Эти механизмы бывают: аппаратными, программными, или смешанно аппаратно-проргаммные;
- размер минимально разделяемой единицы данных, может быть слово, строка, сегмент, объект;
- модуль состоятельности памяти;
- механизм управления разделением памяти.