

43.Подбор переменных в модели множественной регрессии на основе метода оценки информационной ёмкости.
Идея метода показателей информационной емкости сводится к выбору таких объясняющих переменных, которые сильно коррелированны с объясняемой, и одновременно, слабо коррелированны между собой. В качестве исходных точек этого метода рассматриваются вектор R0 и матрица R. Рассматриваются все комбинации потенциальных объясняющих переменных, общее количество которых составляет L=2m-1. Для каждой комбинации потенциальных объясняющих переменных рассчитываются индивидуальные и интегральные показатели информационной емкости. Индивидуальные показатели информационной емкости в рамках конкретной комбинации рассчитываются по формуле:
 Здесь
Здесь
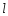 означает
номер переменной, а
означает
номер переменной, а
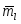 -
количество переменных в рассматриваемой
комбинации. Интервальные показатели
информационной емкости нормируются в
интервале [0;1].
И значения
оказываются тем больше, чем сильнее
объясняющие переменные коррелируют с
объясняемой переменной и чем слабее
они коррелируют между собой. В качестве
объясняющих выбирается такая комбинация
переменных, которой соответствует
максимальное значение интегрального
показателя информационной емкости.
-
количество переменных в рассматриваемой
комбинации. Интервальные показатели
информационной емкости нормируются в
интервале [0;1].
И значения
оказываются тем больше, чем сильнее
объясняющие переменные коррелируют с
объясняемой переменной и чем слабее
они коррелируют между собой. В качестве
объясняющих выбирается такая комбинация
переменных, которой соответствует
максимальное значение интегрального
показателя информационной емкости.
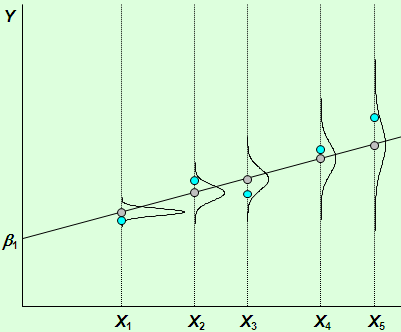
44.Понятие гомоскедастичности и гетероскедастичности случайных возмущений, их графическая интерпретация.
Независимость дисперсии возмущений от номера (момента) наблюдений – гомоскедантичность. Нарушение этого условия приято называть гетероскедантичностью.
Пусть имеется регрессионная модель Y = b1 + b2X + u для 5 наблюдений Х. Если нет случайного возмущения, то точки лежат на прямой линии. Наличие случайного возмущения приводит к размытости значений Y независимо от X. Для случайного возмущения предполагается выполнение ряда требований. Во-первых, среднее для в каждом наблюдении равно 0.
Во-вторых, u распределено по нормальному закону.
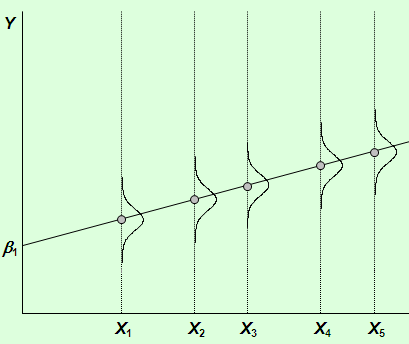
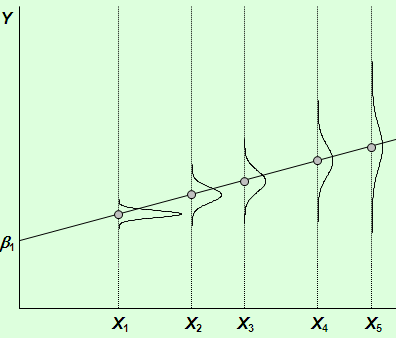
В-третьих, распределение одинаково для каждого наблюдения, как показано на рисунке 1. При соблюдении этих условий случайное возмущение называется гомоскедастичным. Их значения могут быть расположены ближе или дальше от среднего значения, но нет причин априори ожидать особенно больших отклонений. Нарушение гомоскедастичности показано на рис 2. Распределение u для каждого наблюдения имеет нормальное распределение и нулевое ожидание, но дисперсия распределений различна. Очевидно, наблюдения с низкой дисперсией u , например для X1, обеспечивают большую точность измерения параметров и большую эффективность регрессионных оценок, чем те, где дисперсия велика, как например для X5. (рис 3). В этом случае говорят о гетероскедастичности случайных возмущений. Гетероскедастичность приводит к неэффективности оценок регрессионных коэффициентов. То есть можно найти другие, отличные от МНК более эффективные оценки. Кроме того гетероскедастичность приводит к смещенности стандартных ошибок коэффициентов и неприменимости t и F критериев.
45.Порядок оценивания линейной модели множественной регрессии методом наименьших квадратов (мнк) в Excel
Модель линейной
множественной регрессии имеет вид:
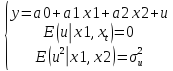 (1)
(1)
Порядок оценивания модели состоит из таких шагов:
1.В столбце А листа Эксель с первой строчки расположить значения эндогенной переменной у. В столбцах В и С, начиная с первой строки, записать значения экзогенных переменных соответственно х1t и x2t.
2. Активировать ячейку адресом A(n+1) и на стандартной панели инструментов щелкнуть мышью кнопку вставки функций.
3. В диалоговом окне «Категория» выбрать «Статистические», в диалоговом окне «Выберите функцию» - «Линейн», щелкнуть мышью по кнопке ОК.
4.в строке «Известные значения у» диалогового окна указать адрес А1:Аn диапазона значений эндогенной переменной yt, а в строчке «Известные значения х» - адрес B1:Cn диапазона известных значений предопределенных переменных x1,x2.
5.В строчку «Конст» диалогового окна занести слово «истина», либо цифру 1.
6.В строчку «Статистика» диалогового окна занести слово «истина» или цифру 1 и щелкнуть мышью по кнопке ОК.
7.Выделить мышью диапазон ячеек A(n+1):C(n+5)
8.Щелкнуть по строке формул.
9.Нажать Ctrl+Shift+Enter. В итоге, в выделенном диапазоне ячеек появятся результаты оценивания модели (1).