

Случайные погрешности
Под случайной понимают погрешность, изменяющуюся случайным образом при повторных измерениях одной и той же величины. Она вызывается причинами, которые не могут быть определены при измерении и на которые нельзя оказать влияния. Присутствие случайных погрешностей можно обнаружить лишь при повторном измерении той же величины с одинаковой тщательностью. Если при повторении получаются одинаковые числовые значения, то это указывает не на отсутствие случайных погрешностей, а на недостаточную точность и чувствительность метода или средства измерений.
Случайные погрешности измерений непостоянны по значению и по знаку. Они не могут быть определены в отдельности и вызывают неточность результата. Однако с помощью теории вероятностей и методов статистики случайные погрешности измерений могут быть количественно определены и охарактеризованы в их совокупности, причем тем надежнее, чем больше число проведенных наблюдений.
Н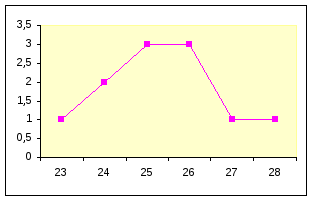 есмотря
на применение метрологических средств
повышенной точности и более совершенные
методы измерения, вследствие неизбежного
наличия случайных отклонений истинное
значение измеряемой величины остается
неизвестным и вместо него мы принимаем
некоторое среднее арифметическое
значение (математическое ожидание при
неограниченно большом числе опытов),
которое при большом числе измерений,
как показывает теория вероятностей и
математическая статистика, можно считать
наилучшим приближением к истинной
величине. (В математической статистике
и теории вероятностей среднее значение
величины при неограниченно большом
числе отдельных наблюдений, называют
математическим ожиданием.)
есмотря
на применение метрологических средств
повышенной точности и более совершенные
методы измерения, вследствие неизбежного
наличия случайных отклонений истинное
значение измеряемой величины остается
неизвестным и вместо него мы принимаем
некоторое среднее арифметическое
значение (математическое ожидание при
неограниченно большом числе опытов),
которое при большом числе измерений,
как показывает теория вероятностей и
математическая статистика, можно считать
наилучшим приближением к истинной
величине. (В математической статистике
и теории вероятностей среднее значение
величины при неограниченно большом
числе отдельных наблюдений, называют
математическим ожиданием.)
В дальнейшем при анализе измерительной информации, обработке результатов наблюдения и использовании методов теории погрешностей, будем считать, что измеренный массив не содержит систематических погрешностей, а также из них исключены грубые погрешности.
Рис.1 Распределение результатов измерительного опыта.
Пример. Было проведено 11 измерений и получены значения:24, 23, 25, 27, 26, 26, 28, 25, 24, 26, 25. Среднее значение X = 1/n * Σxi = 25.
Если на оси 0X (рис.1) нанести измеренные значения, а на оси 0Y количество результатов с такими значения и соединить точки отрезками линий, то мы получим график, вершина которого приближенно находится в значении 25 (среднее значение X), а при удалении от этой точки он спадает.
Теория случайных погрешностей, а вместе с тем и суждение о закономерностях, которым подчиняются случайные погрешности, основывается на двух аксиомах, базирующихся на опытных данных:
Аксиома случайности. При большом числе измерений случайные погрешности, равные по величине, но различные по знаку, встречаются одинаково часто, т. е. число отрицательных погрешностей равно числу положительных.
Аксиома распределения. Малые погрешности случаются чаще, чем большие.
Пусть неизвестное истинное значение некоторой неизменной величины есть X. При её измерении получено n независимых друг от друга результатов наблюдений x1, x2, ….xn. Измерения выполнены одним и тем же прибором и с одинаковой тщательностью, т. е. одинаково точными и свободными от систематической погрешности. Предположим, что каждому измерению сопутствует случайная погрешность δ1, δ2,… δn, — различная по значению и по знаку. Следовательно, для каждого результата наблюдений можно написать выражение вида δ1= x1 - X и затем получить совокупность уравнений для ряда измерений: δi= xi - X
Предположим, что массив данных подчиняется аксиоме случайности, т.е. число и сумма положительных случайных погрешностей приблизительно равны числу и сумме отрицательных, а если сложить все погрешности, то их сумма будет равна нулю:
Σδi = Σxi – ΣX = 0, откуда Σxi = ΣX и следовательно, X = Σxi/n
Это равенство позволяет считать, что среднее арифметическое значение X (или математическое ожидание М) является наиболее близким к истинному значению измеряемой величины X.
Случайное отклонение нельзя предвидеть в каждом конкретном измерении, но их можно оценить в совокупности. Поэтому в метрологии к ним применяют общие законы для случайных явлений (или величин), которые рассматриваются в теории вероятностей и математической статистике. В соответствии с этими науками появление случайных погрешностей при большом числе измерений можно описать следующим уравнением:
f(δ)=exp[- (xi –X)2/(2σn2)] / [σn √2π]
где f(δ) - плотность распределения вероятностей;
exp – экспоненциальная функция, е = 2,7183 – основание натуральных логарифмов;
σ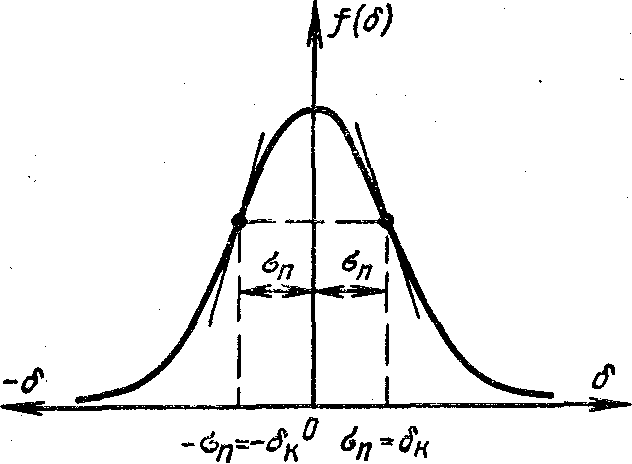 n
–среднее квадратическое отклонение
результата наблюдения при бесконечно
большом числе измерений (n
→∞).
n
–среднее квадратическое отклонение
результата наблюдения при бесконечно
большом числе измерений (n
→∞).
Плотность распределения f(δ) в соответствии с вышеприведенной формулой представляется симметричной кривой (рис.2), которую называют графиком нормального (гауссовского) распределения случайных погрешностей; как видно из рисунка, эта функция полностью соответствует обеим аксиомам. График из примера качественно соответствует этому закону; при увеличении числа экспериментов он все точнее будет совпадать с гладкой кривой нормального распределения.
При большом числе повторных измерений в одних и тех же условиях, частота появления случайных погрешностей подчиняется устойчивым закономерностям. Если через mi обозначить частоту появлений значения погрешности δi при общем их числе n , то отношение mi / n есть относительная частота появлений значения δi. При неограниченно большом числе наблюдений (n →∞); это отношение равнозначно понятию вероятности появления погрешности δi.
С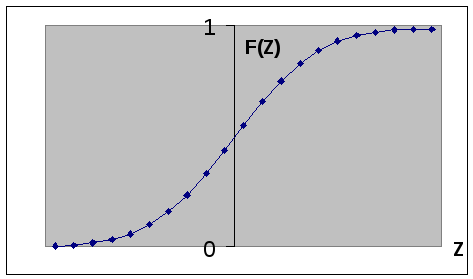 войства
случайной величины описываются функцией
распределения F(Z),
которая определяет вероятность того,
что случайная величина δi
будет меньше Z:
войства
случайной величины описываются функцией
распределения F(Z),
которая определяет вероятность того,
что случайная величина δi
будет меньше Z:
F(Z) = P{ δ < Z },
F(Z)
=
![]() {exp[-
( δ )2/(2σn2)
] dδ
} / [σn
√2π]
{exp[-
( δ )2/(2σn2)
] dδ
} / [σn
√2π]
Вычисление F(Z) при некотором фиксированном Z дает вероятность того, что ошибка измерения δ будет меньше величины Z
Для неограниченно большого ряда измерений 68,3% всех случайных погрешностей ряда лежит ниже данного значения σn и 31,7% выше его.
В таблице показана вероятность того, что измеряемая величина находится в коридоре, определяемом допусками:
|
Диапазон |
-⅔σ ÷ ⅔σ |
-σ ÷ σ |
-2σ ÷ 2σ |
-3σ ÷ 3σ |
-4σ ÷ 4σ |
|
Вероятность |
0,5 |
0,68 |
0,95 |
0,997 |
0,99993 |
Из таблицы видно, что вероятность превышения измеряемой величиной коридора ±4σ составляет 7 случаев на 100000 измерений.
Качественно возможные случайные погрешности измерительного прибора можно оценить с помощью σn .Среднее квадратическое отклонение результата наблюдения служит для оценки точности измерения, в теории вероятностей квадрат этой величины, т. е. σn2 называется рассеянием или дисперсией результата и обозначается обычно символом D. В реальных условиях мы имеем дело с конечными рядами наблюдаемых значений измеряемой величины, так что, определяя σ при ограниченном числе наблюдений, можем найти только приближенное значение или оценку этого отклонения, определяемого по формуле
σ = √[Σ(xi –X)2*1/(n-1)]
г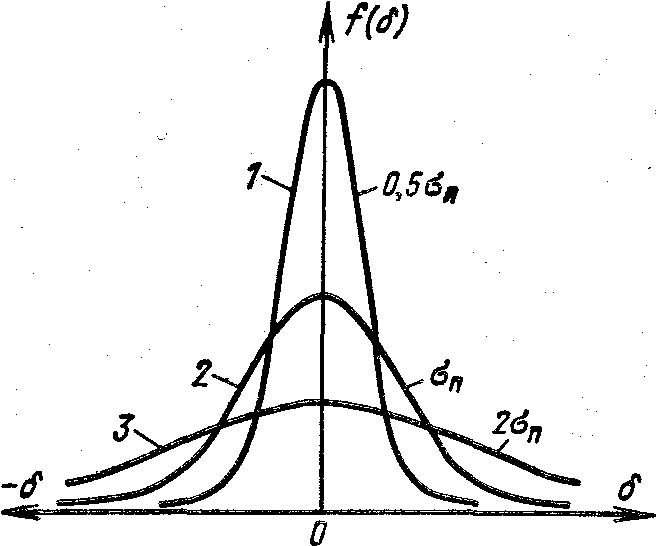 де
n
—число наблюдений; xi
—значение величины, полученное при i-м
наблюдении; X
– центр
измерения, среднее арифметическое
значение (математическое ожидание
измеряемой величины).
де
n
—число наблюдений; xi
—значение величины, полученное при i-м
наблюдении; X
– центр
измерения, среднее арифметическое
значение (математическое ожидание
измеряемой величины).
Параметр σn однозначно характеризует форму кривой распределения случайных погрешностей. Плотность распределения – частота появления случайных погрешностей - ордината f(δ) кривой распределения, соответствующая δ = 0 (нулевой погрешности), обратно пропорциональна σn; при увеличении σn ордината f(δ) уменьшается. Так как площадь под кривой распределения всегда равна единице, то при увеличении σn кривая распределения становится более плоской, растягиваясь вдоль оси абсцисс. С другой стороны, при уменьшении σn кривая распределения вытягивается вверх, одновременно сжимаясь вдоль оси абсцисс.
На рисунке показаны кривые нормального распределения случайных погрешностей, соответствующие трем различным значениям σ (0,5σn ,σn и 2σn) При малом σ. = 0,5σn фигура острая, преобладают малые погрешности, при увеличении σ погрешности увеличиваются.
Таким образом, малому значению σ соответствует преобладание малых случайных погрешностей, а вместе с тем и большая точность измерения данной величины; при большом же σ большие случайные погрешности встречаются значительно чаще, следовательно, точность измерения меньше.
Конечная цель анализа выполненных измерений состоит в определении погрешности результата наблюдения ряда значений измеряемой величины x1, x2, x3, xn,.. и их среднего арифметического значения, принимаемого как окончательный результат измерения, относительной частоты погрешностей и вероятности.
Т.о. случайная погрешность невозможно предвидеть, но можно определить «коридор», за пределы которого ошибка измерения не выйдет.