

Навчання нейронних мереж
Мережа навчається, щоб для деякої множини входів X давати бажану множину виходів Y. Кожна така вхідна (або вихідна) множина розглядається як вектор. Навчання здійснюється шляхом послідовного пред'явлення вхідних векторів з одночасним налагодженням ваг відповідно до певної процедури. В процесі навчання ваги мережі поступово стають такими, щоб кожен вхідний вектор виробляв вихідний вектор. Розрізняють алгоритми навчання з вчителем і без вчителя, детерміновані і стохастичні. Навчання з вчителем. Навчання з вчителем припускає, що для кожного вхідного вектора X існує цільовий вектор YT, що є необхідним виходом. Разом вони називаються навчальною парою. Звичайно мережа навчається для деякої кількості таких навчальних пар (навчальної множини). В ході навчання зчитується вхідний вектор X, обчислюється вихід мережі Y і порівнюється з відповідним цільовим вектором YT, різниця D ~ YT – Y за допомогою зворотного зв'язку подається в мережу і змінюються ваги W відповідно до алгоритму, прагнучого мінімізувати помилку ε. Зчитування векторів навчальної множини і налагодження ваг виконується до тих пір, поки сумарна помилка для всієї навчальної множини не досягне заданого низького рівня. Навчання без вчителя Не зважаючи на численні прикладні досягнення, навчання з вчителем критикувалося за свою біологічну неправдоподібність. Важко уявити навчальний механізм в мозку, який би порівнював бажані і дійсні значення виходів, виконуючи корекцію за допомогою зворотного зв'язку. Якщо допустити подібний механізм в мозку, то звідки тоді виникають бажані виходи? Навчання без вчителя є набагато правдоподібнішою моделлю навчання в біологічній системі. Розвинена Кохоненом і багатьма іншими, вона не потребує цільового вектора для виходів і, отже, не вимагає порівняння з ідеальними відповідями. Навчальна множина складається лише з вхідних векторів. Навчальний алгоритм налагоджує вагу мережі так, щоб виходили узгоджені вихідні вектори, тобто щоб пред'явлення досить близьких вхідних векторів давало однакові виходи. Процес навчання виділяє статистичні властивості навчальної множини і групує схожі вектори в класи. Алгоритми навчання Більшість сучасних алгоритмів навчання виросла з концепцій Хебба. Ним запропонована модель навчання без вчителя, в якій синаптична сила (вага) зростає, якщо активовані обидва нейрони, джерело і приймач. Таким чином, часто використовувані шляхи в мережі посилюються і феномен звички і навчання через повторення одержує пояснення. У штучній нейронній мережі, що використовує навчання по Хеббу, нарощування ваг визначається добутком рівнів збудження передаючого і приймаючого нейронів. Це можна записати як
wij(e+1) = w(e) + α OUTi OUTj,
де wij(e) - значення ваги від нейрона i до нейрона j до налагодження, wij(e+1) - значення ваги від нейрона i до нейрона j після налагодження, α - коефіцієнт швидкості навчання, OUTi - вихід нейрона i та вхід нейрона j, OUTj - вихід нейрона j; e – номер епохи (ітерації під час навчання). Для навчання нейромереж в багатьох випадках використовують алгоритм зворотного розповсюдження помилки. Розв’язок задачі за допомогою нейронної мережі зводиться до наступних етапів:
-
Вибрати відповідну модель мережі (наприклад, трьохшарову )
-
Визначити топологію мережі (кількість елементів та їх зв’язки)
-
Вказати спосіб навчання (наприклад, зі зворотним розповсюдженням помилок) і параметри навчання
Кількість прихованих елементів – не менша за кількість вхідних.
Как мы уже отмечали, для того чтобы нейросеть осуществляла требуемое отображение, т.е. на каждый вектор входных данных создавала требуемый вектор на выходе, требуется её настроить. Обычно процесс настройки называется "обучением" (далее мы всегда будем говорить обучение). Существуют два метода обучения: с наставником и на основе самоорганизации.
Рассмотрим общий для всех сетей принцип обучения с наставником. Пускай имеется некоторый набор пар следующего вида: входной вектор - выход сети (т.е. нам известно как точно должна работать сеть на некотором множестве входных векторов). Такое множество пар называют "обучающая выборка" (далее мы будем использовать именно этот термин). Процесс обучения выглядит следующим образом:
-
Предадим синаптическим весам некоторые начальные значения.
-
Предъявим сети вектор из обучающей выборки.
-
Вычислим отклонения выхода сети от желаемого.
-
По некоторому алгоритму (зависящему от конкретной архитектуры) подстроим синаптические веса, учитывая отклонение полученное на предыдущем шаге.
-
Повторим шаги 2-4 пока сеть не станет выдавать ожидаемый выход на векторах из обучающей выборки или пока отклонение не станет ниже некоторого порога.
Другими словами, подстроим веса сети так, чтобы сеть работала с приемлемой точностью на известных данных. Идея метода состоит в предположении, что при достаточно репрезентативной обучающей выборки, более-менее равномерно покрывающей всё множество возможных входных векторов, обученная нейросеть будет выдавать правильный или близкий к правильному результат на векторах которым её не обучали.
Отметим, что такое предположение вполне закономерно, ведь обученная сеть будет обрабатывать входные вектора схожим образом с векторами из обучающей выборки, следовательно если искомое преобразование в достаточной степени непрерывно и гладко, то результат должен быть вполне удовлетворительным.
Самоорганизация - это свойство небольшого количества нейронных сетей. Под самоорганизацией подразумевается способность сети приспособиться осуществлять желаемое отображение самостоятельно в процессе работы - то есть без обучающей выборки. Обычно такие сети применяются к задачам кластеризации некоторого множества. Для этого метода обучения трудно сформулировать некий общий абстрактный алгоритм, т.к. обычно метод обучения очень сильно зависит от архитектуры конкретной сети.
Далее, при описании конкретных архитектур, мы будем подробно говорить об алгоритмах обучения для каждой конкретной сети.
12/2.
Методы обучения нейросистем
По своей организации и функциональному назначению искусственная нейронная сеть (модель) с несколькими входами и выходами выполняет некоторое преобразование входных стимулов — сенсорной информации о внешнем мире — в выходные управляющие сигналы. Число преобразуемых стимулов равно n — числу входов сети, а число выходных сигналов соответствует числу выходов m. Совокупность всевозможных входных векторов размерности n образует векторное пространство X, которое мы будем называть признаковым пространством. Аналогично, выходные вектора также формируют признаковое пространство, которое будет обозначаться Y. Состояние, при котором нейронная сеть выполняет требуемую функцию, называют обученным состоянием сети W*.
Имеющиеся в распоряжении разработчика примеры соответствий между признаковыми пространствами некоторые авторы называют обучающей выборкой. Обучающая выборка определяется обычно заданием пар векторов, причем в каждой паре один вектор соответствует стимулу, а второй — требуемой реакции. Обучение нейронной сети состоит в приведении всех векторов стимулов из обучающей выборки требуемым реакциям путем выбора весовых коэффициентов нейронов. Процесс обучения с математической точки зрения является процессом поиска некоторого минимума функции. При этом разработчик НС может столкнуться с несколькими проблемами. Во-первых, минимум функции может быть не единственным или отсутствовать вовсе. Во-вторых, на практике часто необходимо найти глобальный, а не локальный минимум, однако обычно не ясно, нет ли у функции еще одного, более глубокого, чем найденный, минимума.
На этапе обучения кроме параметра качества подбора весов важную роль играет время обучения. Как правило, эти два параметра связаны обратной зависимостью и их приходится выбирать на основе компромисса.
В зависимости от применяемого метода обучения НС разделяются на синхронные и асинхронные. В первом случае в каждый момент времени свое состояние меняет лишь один нейрон. Во втором – состояние меняется сразу у целой группы нейронов, как правило, у всего слоя. Алгоритмически ход времени в НС задается итерационным выполнением однотипных действий над нейронами.
Метод обратного распространения
Основная идея обратного распространения состоит в том, как получить оценку ошибки для нейронов скрытых слоев. Заметим, что известные ошибки, делаемые нейронами выходного слоя, возникают вследствие неизвестных пока ошибок нейронов скрытых слоев. Чем больше значение синаптической связи между нейроном скрытого слоя и выходным нейроном, тем сильнее ошибка первого влияет на ошибку второго. Следовательно, оценку ошибки элементов скрытых слоев можно получить, как взвешенную сумму ошибок последующих слоев. При обучении информация распространяется от низших слоев иерархии к высшим, а оценки ошибок, делаемые сетью — в обратном направлении, что и отражено в названии метода. Перейдем к подробному рассмотрению этого алгоритма. Для упрощения обозначений ограничимся ситуацией, когда сеть имеет только один скрытый слой. Матрицу весовых коэффициентов от входов к скрытому слою обозначим W, а матрицу весов, соединяющих скрытый и выходной слой — как V. Для индексов примем следующие обозначения: входы будем нумеровать только индексом i, элементы скрытого слоя — индексом j, а выходы, соответственно, индексом k.
Пусть имеется набор пар векторов (x, y = 1..p, т.е. обучающая выборка. Будем называть нейронную сеть обученной на данной обучающей выборке, если при подаче на входы сети каждого вектора x), на выходах всякий раз получается соответствующий вектор y Алгоритм обучения проводится в следующей последовательности:
1. Начальные значения весов всех нейронов всех слоев V(t =0) и W(t =0) назначаются случайным образом.
2. На нейронную сеть подается первый стимул xα и на выходе наблюдается реакция yα. При этом нейроны последовательно от слоя к слою функционируют по следующим формулам в зависимости от принятой функции нелинейного преобразования f(x):
в скрытом слое
|
|
|
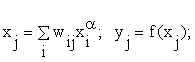
в выходном слое
|
|
|
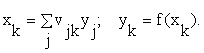
3. Вычисляется величина ошибки, делаемой сетью на выходе j слоя, начиная с последнего предъявленного стимула:
|
|
|
4. Используя градиентный метод минимизации функционала, находятся уточненные значения подстройки весов j слоев начиная с последнего:
|
|
|
где h – темп обучения (0 < h < 1).
На этом шаге необходимо учитывать следующее: а) уточняются только компоненты матрицы весов, отвечающие ненулевым значениям входов; б) знак приращения веса соответствует знаку ошибки, т.е. положительная ошибка ( > 0, значение выхода меньше требуемого) проводит к усилению связи; в) обучение каждого нейрона происходит независимо от обучения остальных нейронов, что соответствует важному с биологической точки зрения, принципу локальности обучения. О сходимости h необходимо сделать несколько дополнительных замечаний. Во-первых, практика показывает что сходимость метода обратного распространения весьма медленная. Невысокий темп сходимости является “генетической болезнью” всех градиентных методов, так как локальное направление градиента отнюдь не совпадает с направлением к минимуму. Во-вторых, подстройка весов выполняется независимо для каждой пары образов обучающей выборки. При этом улучшение функционирования на некоторой заданной паре может, вообще говоря, приводить к ухудшению работы на предыдущих образах. В этом смысле, нет достоверных (кроме весьма обширной практики применения метода) гарантий сходимости.
5. Шаги 2-4 повторяются для всех обучающих векторов (стимулов) до тех пор, пока не будет достигнут критерий оптимизации (точность, время и т.д.).
Рассмотренный алгоритм получил название «с учителем», поскольку известны как входные вектора, так и требуемые значения выходных векторов (имеется учитель, способный оценить правильность ответа ученика).
Алгоритм обучения «без учителя» характерен для сети Хемминга. Главная черта, делающая обучение без учителя привлекательным, – это его "самостоятельность". Процесс обучения, как и в случае обучения с учителем, заключается в подстраивании весов синапсов. Некоторые алгоритмы, правда, изменяют и структуру сети, то есть количество нейронов и их взаимосвязи, но такие преобразования правильнее назвать более широким термином – самоорганизацией. При обучении по данному методу усиливаются связи между возбужденными нейронами:
-
на стадии инициализации всем весовым коэффициентам присваиваются небольшие случайные значения;
-
на входы сети подается входной образ, и сигналы возбуждения распространяются по всем слоям согласно принципам классических прямопоточных сетей, то есть для каждого нейрона рассчитывается взвешенная сумма его входов, к которой затем применяется активационная (передаточная) функция нейрона;
-
на основании полученных выходных значений нейронов производится изменение весовых коэффициентов;
-
цикл с шага 2, пока выходные значения сети не застабилизируются с заданной точностью.
Применение этого нового способа определения завершения обучения, отличного от использовавшегося для сети обратного распространения, обусловлено тем, что подстраиваемые значения синапсов фактически не ограничены.
На втором шаге цикла попеременно предъявляются все образы из входного набора.
Кохонена мережі. (13)
нейронні мережі з прямим та зворотнім розповсюдженням сигналу.(14)
Етапи програмування нейромережі. (створення). (15)
Навчання з учителем.(нейромережі) (16)
Один з видів навчання штучних нейромереж:
Навчання з вчителем. Навчання з вчителем припускає, що для кожного вхідного вектора X існує цільовий вектор YT, що є необхідним виходом. Разом вони називаються навчальною парою. Звичайно мережа навчається для деякої кількості таких навчальних пар (навчальної множини). В ході навчання зчитується вхідний вектор X, обчислюється вихід мережі Y і порівнюється з відповідним цільовим вектором YT, різниця D ~ YT – Y за допомогою зворотного зв'язку подається в мережу і змінюються ваги W відповідно до алгоритму, прагнучого мінімізувати помилку ε. Зчитування векторів навчальної множини і налагодження ваг виконується до тих пір, поки сумарна помилка для всієї навчальної множини не досягне заданого низького рівня.
Вимоги до навчальної вибірки. (17)
Идеальной является ситуация, когда вы можете получить произвольно много различных данных для вашей задачи. В этом случае следует позаботиться об отсутствии систематических ошибок и уклонений в данных (если только именно этот вопрос не является предметом ваших исследований). Целесообразно включение в обучающую выборку прежде всего тех данных, которые описывают условия, близкие к условиям дальнейшего использования нейросистемы.
Для решения некоторых задач распознавания образов данные, если это возможно, следует представить в инвариантном виде.
Для практических целей следует часть обучающей выборки не использовать при обучении, а применить для последующего тестирования работы нейросети. Полезно понимать, что очень большая выборка обучающих данных сильно замедлит процесс обучения без существенного улучшения результата.
Если в вашем распоряжении имеется весьма ограниченный объем данных, то потребуется анализ его достаточности для решения вашей задачи. Обычно это оказывается весьма непростым вопросом. Одним из решений может быть уменьшение размерности признаковых пространств задачи. В любом случае, обучающих данных должно быть больше, чем обучаемых параметров нейросети.
Використання нейронної мережі.(18)
Нейронные сети - это адаптивные системы для обработки и анализа данных, которые представляют собой математическую структуру, имитирующую некоторые аспекты работы человеческого мозга и демонстрирующие такие его возможности, как способность к неформальному обучению, способность к обобщению и кластеризации неклассифицированной информации, способность самостоятельно строить прогнозы на основе уже предъявленных временных рядов. Главным их отличием от других методов, например таких, как экспертные системы, является то, что нейросети в принципе не нуждаются в заранее известной модели, а строят ее сами только на основе предъявляемой информации. Именно поэтому нейронные сети и генетические алгоритмы вошли в практику всюду, где нужно решать задачи прогнозирования, классификации, управления - иными словами, в области человеческой деятельности, где есть плохо алгоритмизуемые задачи, для решения которых необходимы либо постоянная работа группы квалифицированных экспертов, либо адаптивные системы автоматизации, каковыми и являются нейронные сети.