

Классификация интегральных схем (плис)
Микросхемы, программируемые пользователями, открыли новую страницу в истории современной микроэлектроники и вычислительной техники. Они сделали БИС/СБИС, предназначенные для решения специализированных задач, стандартной продукцией электронной промышленности со всеми вытекающими из этого положительными следствиями: массовое производство, снижение стоимости микросхем, сроков разработки и выхода на рынок продукции на их основе. ПЛИС можно классифицировать по многим признакам, в первую очередь: - по уровню интеграции и связанной с ним логической сложности; - по архитектуре (типу функциональных блоков, характеру системы межсоединений); - по числу допустимых циклов программирования; - по типу памяти конфигурации («теневой»памяти ); - по степени зависимости задержек сигналов от путей их распространения; - по системным свойствам; - по схемотехнологии (КМОП, ТТЛШ и др.); - по однородности или гибридности (по признаку наличия или отсутствия в микросхеме областей с различными по методам проектирования схемами, такими как ПЛИС, БМК, схемы на стандартных ячейках). Все перечисленные признаки имеют значение и отображают ту или иную сторону возможных классификаций. Выделяя основные признаки и укрупняя их, рассмотрим классификацию по трем, в том числе двум комплексным, признакам: - по архитектуре; - по уровню интеграции и однородности/гибридности; - по числу допустимых циклов программирования и связанному с этим типу памяти конфигурации.

Рис.: Классификация ПЛИС (а – поархитектуре, б – по уровню интеграции)
Первый из классов — SPLD, SimpleProgrammableLogicDevices, т. е. простые программируемые логические устройства. По архитектуре эти ПЛИС делятся на подклассы программируемых логических матриц ПЛМ (PLA, ProgrammableLogicArrays) и программируемой матричной логики ПМЛ (PAL, ProgrammableArraysLogic, или GAL, GenericArrayLogic). Оба эти подкласса микросхем реализуют дизъюнктивные нормальные формы (ДНФ) переключательных функций, а их основными блоками являются две матрицы: матрица элементов Ии матрица элементов ИЛИ, включенные последовательно. Такова структурная модель ПЛМ и ПМЛ. Технически они могут быть выполнены и как последовательность двух матриц элементов ИЛИ-НЕ, но варианты с последовательностью матриц И-ИЛИ и с последовательностью матриц ИЛИ-НЕ — ИЛИ-НЕ функционально эквивалентны, т. к. второй вариант согласно правилу де Моргана тоже реализует ДНФ, но для инверсных значений переменных.
T-триггеры.
Т-триггер – это счетный триггер. У Т-триггера имеется только один вход. После поступления на этот вход импульса, состояние Т-триггера меняется на прямо противоположное. Счётным он называется потому, что он как бы подсчитывает количество импульсов, поступивших на его вход. Жаль только, что считать этот триггер умеет только до одного. При поступлении второго импульса T-триггер снова сбрасывается в исходное состояние. Т-триггеры строятся только на базе двухступенчатых триггеров, подобных рассмотренному ранее D-триггеру. Использование двух триггеров позволяет избежать самовозбуждения схемы, так как счетные триггеры строятся при помощи схем с обратной связью Т-триггер можно синтезировать из любого двухступенчатого триггера. Рассмотрим пример синтеза Т-триггера из динамического D-триггера. Для того чтобы превратить D-триггер в счётный, необходимо ввести цепь обратной связи с инверсного выхода этого триггера на вход, как показано на рисунке 1.
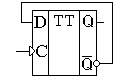
Временная диаграмма T-триггера приведена на рисунке 2.
При построении этой временной диаграммы был использован триггер, работающий по заднему фронту синхронизирующего сигнала.
 Т-триггеры
используются при построении схем
различных счётчиков, поэтому в составе
БИС различного назначения обычно есть
готовые модули этих триггеров.
Условно-графическое обозначение
T-триггера приведено на рисунке 3.
Т-триггеры
используются при построении схем
различных счётчиков, поэтому в составе
БИС различного назначения обычно есть
готовые модули этих триггеров.
Условно-графическое обозначение
T-триггера приведено на рисунке 3.

Комбинационные ПЛИС
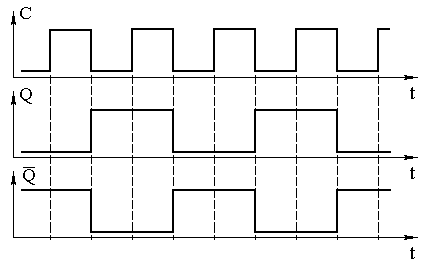
Стандартная логическая структура КПЛИС позволяет реализовать различные выходные функции. Структура связи КПЛИС представляет собой двумерную матрицу с программируемыми соединениями в точках пересечения. Данная схема имеет входы I0…In, а так же независимые выходы F0…Fm Количество входов и выходов может варьироваться в широких пределах.
Прошивка.
Данные могут быть программируемыми (исполняемый микрокод), а могут и нести другой смысл (калибровочные данные). Чтобы изготовить программируемый микрокод нужно написать управляемую микропрограмму. Далее с помощью программы-компилятора оттранслировать в исполняемый код понятный какому-либо процессору. Только после этого исполняемый микрокод можно поместить в какую-либо память. Размещение происходит либо в процессе прозводства кристалла, либо самим пользователем. Во втором случае способов несколько:
-
Через JTAG интерфейс
-
Через встроенные программно-аппаратные средства
-
С помощью программатора
Это зависит от типа микропроцессора или микроконтроллера
Профишка –
-
Файл с данными
-
Микросхема с данными
-
Исполняемый код
-
Микроконтроллер
JK-тригер
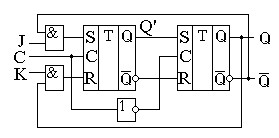
Прежде чем начать изучение JK-триггера, вспомним принципы работы RS-триггера. Напомню, что в этом триггере есть запрещённые комбинации входных сигналов. Одновременная подача единичных сигналов на входы R и S запрещены. Очень хотелось бы избавиться от этой неприятной ситуации.
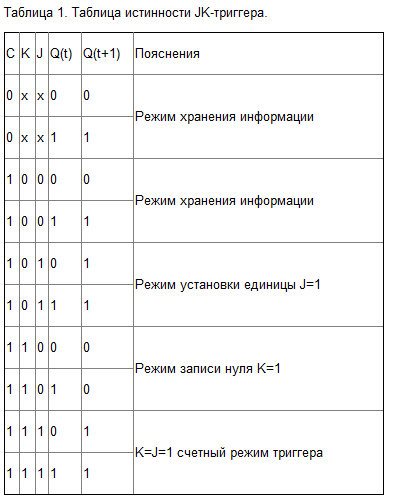
Таблица истинности JK-триггера практически совпадает с таблицей истинности синхронного RS-триггера. Для того чтобы исключить запрещённое состояние, схема триггера изменена таким образом, что при подаче двух единиц JK-триггер превращается в счётный триггер. Это означает, что при подаче на тактовый вход C импульсов JK-триггер изменяет своё состояние на противоположное. Таблица истинности JK-триггера приведена в таблице 1.
Для реализации счетного режима в схеме, приведенной на рисунке 8.22, введена перекрестная обратная связь с выходов второго триггера на входы R и S первого триггера. Благодаря этой обратной связи на входах R и S никогда не может возникнуть запрещенная комбинация.
Приводить временные диаграммы работы JK-триггера не имеет смысла, так как они совпадают с приведёнными ранее диаграммами RS- и T-триггера. Условно-графическое обозначение JK-триггера приведено на рисунке 2.
Системы на кристале
Система на кристалле (однокристальная система) — в микроэлектронике — электронная схема, выполняющая функции целого устройства (например, компьютера) и размещенная на одной интегральной схеме.
В англоязычной литературе называется System-on-a-Chip, SoC.
В зависимости от назначения она может оперировать как цифровыми сигналами, так и аналоговыми, аналого-цифровыми, а также частотами радиодиапазона. Как правило, применяются в портативных и встраиваемых системах.
Если разместить все необходимые цепи на одном полупроводниковом кристалле не удается, применяется схема из нескольких кристаллов, помещенных в единый корпус (Systemin a package, SiP). SoC считается более выгодной конструкцией, так как позволяет увеличить процент годных устройств при изготовлении и упростить конструкцию корпуса.
Типичная SoC содержит:
-
один или несколько микроконтроллеров, микропроцессоров или ядер цифровой обработки сигналов (DSP),
-
банк памяти, состоящий из модулей ПЗУ, ОЗУ, ППЗУ или флеш.
-
источники опорной частоты, например, кварцевые резонаторы и схемы ФАПЧ (фазовой автоподстройки частоты),
-
таймеры, счетчики, цепи задержки после включения,
-
стандартные интерфейсы для внешних устройств: USB, FireWire, Ethernet, USART, SPI.
-
входы и выходы цифро-аналоговых и аналого-цифровых преобразователей.
-
регуляторы напряжения и стабилизаторы питания.
Блоки могут быть соединены с помощью шины собственной разработки или стандартной конструкции, например AMBA в чипах компании ARM. Если в составе чипа есть контроллер прямого доступа к памяти (ПДП), то с его помощью можно заносить данные с большой скоростью из внешних устройств напрямую в память чипа, минуя процессорное ядро.
Системы-на-кристалле потребляют меньше энергии, стоят дешевле и работают надёжнее, чем наборы микросхем с той же функциональностью. Меньшее количество корпусов упрощает монтаж. Тем не менее, создание одной слишком большой и сложной системы на кристалле может оказаться более дорогим процессом, чем серии из маленьких из-за сложности разработки и отладки и снижения процента выхода годных изделий.
Синхронные и асинхронные счётчики
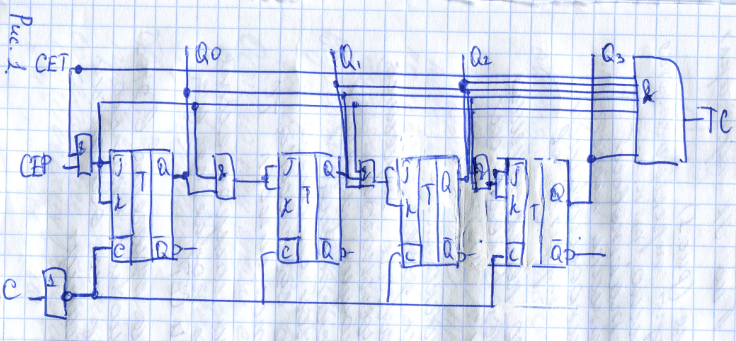
Принципиальная схема одного из вариантов синхронных двоичных счётчиков на JK-тригерах. В этой схеме все тригеры переключаются одновременно, т.к. выходной тактовый сигнал счётчика подаётся на вход синхронизации сразу всех тригеров. Разрешение переключения формируется схемами «И». При исполнении нескольких микросхем для формирования переноса, предназначенного для последующих разрядов двоичного счётчика в приведённой схеме синхронного счётчика формируется сигнал ТС.
В следующих микросхемах этот сигнал подаётся на выходы СЕР и СЕТ. Переключение тригеров в этой схеме возможно только при подаче на оба этих выхода единицы.
СФ-блоки
IP cores (IP-ядра) (от англ. IntellectualProperty — интеллектуальный продукт.Также IP-блоки; также англ. virtualcomponents, VC — виртуальные компоненты) — готовые блоки для проектирования микросхем (например, построения систем-на-кристалле).
Различают 3 основных класса блоков:
-
программные IP-блоки (англ. softblocks) — блоки, специфицированные на языке описания аппаратуры.
-
схемотехнические блоки (англ. firmblocks) — блоки, специфицированные на схемотехническом уровне, без привязки к конкретной топологической реализации.
-
физические (топологические) блоки (англ. hardsblocks) — блоки, специфицированные на физическом уровне реализации СБИС, например, GDSII для ASIC.
Hard IP-Core — сложно-функциональный блок, передаваемый потребителю в виде законченной схемотехнической конструкции, разработанной на основе базы данных для проектирования изготовителя микросхем и оптимизированной по размерам, потребляемой мощности и электрическим характеристикам.
Hard IP-Core — специализированные области кристалла, выделенные для определенных функций. В этих областях создаются блоки неизменной структуры, спроектированные по методологии ASIC (как области типа БМК или схем со стандартными ячейками), оптимизированные для заданной функции и не имеющие средств ее программирования[1].
В случае использования данного вида ядер размер площади используемой на кристалле — сокращается, улучшаются характеристики быстродействия, но в данном случае происходит потеря универсальности.
Построение комбинационных схем Любая логическая схема полностью описывается таблицей истинности. При этом не обязательно, чтобы все комбинации входных данных были полезными или нужными. Возможна ситуация, когда только часть входных комбинаций является полезной. Обычно при этом стараются выбирать выходные сигналы таким образом, чтобы схема получилась простейшая. Для реализации логической схемы с произвольной таблицей истинности используется сочетание простейших логических элементов «И», «ИЛИ», «НЕ». Существует много способов синтеза схем, реализующих произвольную таблицу истинности. Например: СКНФ, СДНФ. Алгоритм построения комбинационной схемы:
-
Формирование таблицы истинности
-
Минимизация функции (например с помощью Карт Карно)
-
После минимизации – непосредственно разработка принципиальной комбинационной схемы.
Системный уровень проектирования интегральных схем: Общий маршрут проектирования систем на кристалле состоит из следующих основных этапов:
-
концептуальное проектирование системы; основной задачей данного этапа является исследование проектируемой системы и получение исполняемых спецификаций на языке высокого уровня (стандартно на С/С++);
-
проектирование, то есть трансформация исполняемой спецификации проекта на уровень регистровых передач (получение спецификаций на языках Verilog/VHDL) и далее на вентильный уровень;
-
верификация проекта, то есть проверка проекта и проектных решений на соответствие исходной спецификации и другим требованиям в процессе проектирования и детализации;
-
физическое проектирование, начиная от выбора технологического и библиотечного базиса и заканчивая получением финального описания проекта в формате GDSII.
Системный уровень описания (system-leveldescription) проекта состоит из поведенческого описания в терминах функций, выражений, алгоритмов. На уровне регистровых передач (registertransferlevel) проект представляется совокупностью арифметических и логических узлов, элементов памяти и т.п
Основные задачи системного и архитектурного уровней проектирования следующие:
-
определение принципов организации системы;
-
выбор архитектуры, уточнение функций системы и их разделение на функции, реализуемые аппаратным и программным путем;
-
разработка структурной схемы, т.е. определение состава устройств и способов их взаимодействия;
-
определение требований к выходным параметрам устройств и формирование технических заданий (ТЗ) на разработку отдельных элементов системы
-
RISC-процессоры
RISC) — архитектура процессора, в которой быстродействие увеличивается за счёт упрощения команд, чтобы их декодирование было проще, а время выполнения — короче. Первые RISC-процессоры даже не имели команд умножения и деления. Это также облегчает повышение тактовой частоты и делает более эффективной суперскалярность (распараллеливание команд между несколькими исполнительными блоками).
В первых архитектурах, причисляемых к RISC, большинство команд для упрощения декодирования имеют одинаковую длину и похожую структуру, арифметические операции работают только с регистрами, а работа с памятью идёт через отдельные команды загрузки (load) и сохранения (store). Эти свойства и позволили лучше сбалансировать этапы конвейеризации, сделав конвейеры в RISC значительно более эффективными и позволив поднять тактовую частоту.
Поскольку многие реальные программы тратят большинство своего времени на выполнение простых операций, многие исследователи решили сфокусироваться на том, чтобы сделать эти операции максимально быстрыми. Тактовая частота процессора ограничена временем, которое процессор тратит на выполнение наиболее медленных шагов в процессе обработки любой команды; уменьшение длительности таких шагов даёт общее повышение частоты, а также зачастую ускоряет выполнение и других команд за счёт более эффективной конвейеризации.[4] Фокусирование на простых командах и ведёт к архитектуре RISC, цель которой — сделать команды настолько простыми, чтобы они легко конвейеризировались и тратили не более одного такта на каждом шаге конвейера на высоких частотах.
Позднее было отмечено, что наиболее значимая характеристика RISC в разделении команд для обработки данных и обращения к памяти — обращение к памяти идёт только через команды load и store, а все прочие команды ограничены внутренними регистрами. Это упростило архитектуру процессоров: позволило командам иметь фиксированную длину, упростило конвейеры и изолировало логику, имеющую дело с задержками при доступе к памяти, только в двух командах. В результате RISC-архитектуры стали называть также архитектурами load/store.
Характерные особенности:
-
Фиксированная длина машинных команд (например, 32 бита) и простой формат команды.
-
Специализированные команды для операций с памятью — чтения или записи. Операции вида «прочитать-изменить-записать» отсутствуют. Любые операции «изменить» выполняются только над содержимым регистров (т. н. архитектура load-and-store).
-
Большое количество регистров общего назначения (32 и более).
-
Отсутствие поддержки операций вида «изменить» над укороченными типами данных — байт, 16-битное слово. Так, например, система команд DEC Alpha содержала только операции над 64-битными словами, и требовала разработки и последующего вызова процедур для выполнения операций над байтами, 16- и 32-битными словами.
-
Отсутствие микропрограмм внутри самого процессора. То, что в CISC процессоре исполняется микропрограммами, в RISC процессоре исполняется как обыкновенный (хотя и помещённый в специальное хранилище) машинный код, не отличающийся принципиально от кода ядра ОС и приложений. Так, например, обработка отказов страниц в DEC Alpha и интерпретация таблиц страниц содержалась в так называемом PALCode (PrivilegedArchitectureLibrary), помещённом в ПЗУ. Заменой PALCode можно было превратить процессор Alpha из 64-битного в 32-битный, а также изменить порядок байтов в слове и формат входов таблиц страниц виртуальной памяти.
Системы счисления
Система счисления – способ записи чисел с помощью цифр (символов). Все цифры каждой системы счисления образуют алфавит системы счисления.
СС бывают позиционные и непозиционные.
В позиционных системах счисления один и тот же числовой знак (цифра) в записи числа имеет различные значения в зависимости от того места (разряда), где он расположен. Под позиционной системой счисления обычно понимается b-ричная система счисления, которая определяется целым числом b > 1, называемым основанием системы счисления. Целое число x в b-ричной системе счисления представляется в виде конечной линейной комбинации степеней числа b:
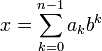 ,
где ak
— это целые числа, называемые цифрами,
удовлетворяющие неравенству
,
где ak
— это целые числа, называемые цифрами,
удовлетворяющие неравенству
![]() .
.
В непозиционной системе счисления каждая цифра алфавита имеет фиксированное значение. Самая известная непозиционная СС – римская СС. Пример: XXI = 2110
Арифметические и логические операции над двоичными числами
Арифметические:
Сложение: 1000+101=1101
Вычитание: 1101-101=1000
Умножение: a*b алгоритм: Берём левый бит b умножаем на a, результат сдвигаем на один бит влево и т.д.
Арифметический сдвиг – основная идея – старший бит сохраняет своё значение
Логические
Побитовое «И» 11001&10101=10001
Побитовое «ИЛИ» 11001|10101=11101
Побитовое «НЕ» !11001=00110
Побитовое «XOR» 11001 XOR 10101 = 01100
Логический сдвиг: пустая ячейка заполняется нулём
Принципы архитектуры Фон Неймана
-
Принцип двоичного кодирования.
Для представления данных и команд используется двоичная система счисления(0,1)
-
Принцип однородности памяти.
Как программы (команды), так и относящиеся к программам данные хранятся в одной и той же памяти (и кодируются в одной и той же системе счисления — чаще всего двоичной). Над командами можно выполнять такие же действия, как и над данными.
-
Принцип адресуемости памяти.
Структурно основная память состоит из пронумерованных ячеек; процессору в произвольный момент времени доступна любая ячейка; память внутренняя.
-
Принцип последовательного программного управления.
Все команды располагаются в памяти и выполняются последовательно, одна после завершения другой, в последовательности, определяемой программой.
-
Принцип жесткости архитектуры.
Неизменяемость в процессе работы топологии, архитектуры, списка команд.
Компьютеры, построенные на этих принципах, относят к типу фон-неймановских.
Гарвардская архитектура
Гарвардская архитектура — архитектура ЭВМ, отличительным признаком которой является раздельное хранение и обработка команд и данных. Архитектура была разработана ГовардомЭйкеном в конце 1930-х годов в Гарвардском университете.
Типичные операции (сложение и умножение) требуют от любого вычислительного устройства нескольких действий:
-
выборку двух операндов,
-
выбор инструкции и её выполнение,
-
и, наконец, сохранение результата.
Соответствующая схема реализации доступа к памяти имеет один очевидный недостаток — высокую стоимость. При разделении каналов передачи команд и данных на кристалле процессора последний должен иметь почти вдвое больше выводов, так как шина адреса и шина данных составляют основную часть выводов микропроцессора. Способом решения этой проблемы стала идея использовать общую шину данных и шину адреса для всех внешних данных, а внутри процессора использовать шину данных, шину команд и две шины адреса. Такую концепцию стали называть модифицированной Гарвардской архитектурой.
Такой подход применяется в современных сигнальных процессорах. Еще дальше по пути уменьшения стоимости пошли при создании однокристалльных ЭВМ — микроконтроллеров. В них одна шина команд и данных применяется и внутри кристалла.
Разделение шин в модифицированной Гарвардской структуре осуществляется при помощи раздельных управляющих сигналов: чтения, записи или выбора области памяти.
Постоянная память и временная
Постоянное запоминающее устройство (ПЗУ) — энергонезависимая память, используется для хранения массива неизменяемых данных.
Временная память – энергозависимая память. Бывает статической и динамической.
Статическая - память, которой для хранения информации достаточно сохранения питающего напряжения.
Динамическая - память, в которой информация со временем разрушается (деградирует), и, кроме подачи электропитания, необходимо производить её периодическое восстановление (регенерацию).
Алгоритм. Понятие алгоритма
Алгори́тм, от имени учёного аль-Хорезми — точный набор инструкций, описывающих порядок действий исполнителя для достижения результата решения задачи за конечное время. В старой трактовке вместо слова «порядок» использовалось слово «последовательность», но по мере развития параллельности в работе компьютеров слово «последовательность» стали заменять более общим словом «порядок». Это связано с тем, что работа каких-то инструкций алгоритма может быть зависима от других инструкций или результатов их работы. Таким образом, некоторые инструкции должны выполняться строго после завершения работы инструкций, от которых они зависят. Независимые инструкции или инструкции, ставшие независимыми из-за завершения работы инструкций, от которых они зависят, могут выполняться в произвольном порядке, параллельно или одновременно, если это позволяют используемые процессор и операционная система.
Некоторый алгоритм для нахождения значений функции, заданной в некотором алфавите, существует тогда и только тогда, когда функция исчисляется по Тьюрингу, то есть когда ее можно вычислить на машине Тьюринга. Этот тезис является аксиомой, постулатом, и не может быть доказан математическими методами, поскольку алгоритм не является точным математическим понятиям. (основная гипотеза алгоритмов)
Основная идея, лежащая в основе машины Тьюринга, очень проста. Машина Тьюринга — это абстрактная машина (автомат), работающая с лентой отдельных ячеек, в которых записаны символы. Машина также имеет головку для записи и чтения символов из ячеек, которая может двигаться вдоль ленты. На каждом шагу машина считывает символ из ячейки, на которую указывает головка, и, на основе считанного символа и внутреннего состояния, делает следующий шаг. При этом, машина может изменить свое состояние, записать другой символ в ячейку или передвинуть головку на одну ячейку вправо или влево.