

Список алгоритмов сортировки
В этой таблице n — это количество записей, которые необходимо упорядочить, а k — это количество уникальных ключей.
Алгоритмы устойчивой сортировки
-
Сортировка пузырьком (англ. Bubble sort ) — сложность алгоритма: O(n2); для каждой пары индексов производится обмен, если элементы расположены не по порядку.
-
Сортировка перемешиванием (Шейкерная, Cocktail sort, bidirectional bubble sort) — Сложность алгоритма: O(n2)
-
Сортировка вставками (Insertion sort) — Сложность алгоритма: O(n2); определяем где текущий элемент должен находиться в упорядоченном списке и вставляем его туда
-
Сортировка с помощью двоичного дерева (англ. Tree sort) — Сложность алгоритма: O(n log n); требуется O(n) дополнительной памяти
Алгоритмы неустойчивой сортировки
-
Сортировка выбором (Selection sort) — Сложность алгоритма: O(n2); поиск наименьшего или наибольшего элемента и помещения его в начало или конец упорядоченного списка
-
Сортировка Шелла (Shell sort) — Сложность алгоритма: O(n log2 n); попытка улучшить сортировку вставками
-
Быстрая сортировка (Quicksort) — Сложность алгоритма: O(n log n) — среднее время, O(n2) — худший случай; широко известен как быстрейший из известных для упорядочения больших случайных списков; с разбиением исходного набора данных на две половины так, что любой элемент первой половины упорядочен относительно любого элемента второй половины; затем алгоритм применяется рекурсивно к каждой половине
Сортировка вставками
С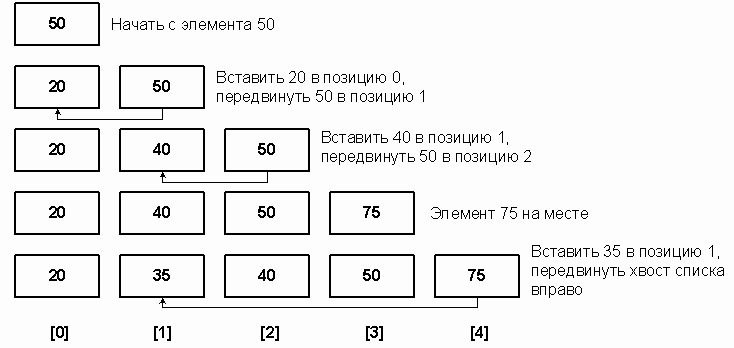 ортировка
вставками похожа на процесс тасования
карточек с именами. Регистратор заносит
каждое имя на карточку, а затем
упорядочивает карточки по алфавиту,
вставляя карточку в верхнюю часть стопки
в подходящее место. Опишем этот процесс
на примере нашего пятиэлементного
списка A = 50, 20, 40, 75, 35 (рисунок 1).
ортировка
вставками похожа на процесс тасования
карточек с именами. Регистратор заносит
каждое имя на карточку, а затем
упорядочивает карточки по алфавиту,
вставляя карточку в верхнюю часть стопки
в подходящее место. Опишем этот процесс
на примере нашего пятиэлементного
списка A = 50, 20, 40, 75, 35 (рисунок 1).
В функцию InsertionSort передается массив A и длина списка n. Рассмотрим i-ый проход (1<i<n-1). Подсписок от A[0] до A[i-1] уже отсортирован по возрастанию. В качестве вставляемого (TARGET) выберем элемент A[i] и будем продвигать его к началу списка, сравнивая с элементами A[i-1], A[i-2] и т.д. Просмотр заканчивается на элементе A[j], который меньше или равен TARGET, или находится в начале списка (j = 0). По мере продвижения к началу списка каждый элемент сдвигается вправо (A[j] = A[j-1]). Когда подходящее место для A[i] будет найдено, этот элемент вставляется в точку j.
Рис. 1
«Быстрая» сортировка
Итак, мы рассмотрели алгоритм сортировки массива, имеющий сложность порядка O(n2). Алгоритмы, использующие деревья (турнирная сортировка, сортировка посредством поискового дерева), обеспечивают значительно лучшую производительность O(n log2n). Несмотря на то, что они требуют копирования массива в дерево и обратно, эти затраты покрываются за счет большей эффективности самой сортировки.
Широко используемый метод пирамидальной сортировки также обрабатывает массив «на месте» и имеет эффективность O(n log2n). Однако «быстрая» сортировка, которую изобрел К.Хоар, для большинства приложений превосходит пирамидальную сортировку и является самой быстрой из известных до сих пор.
Описание «быстрой» сортировки Алгоритм QuickSort
-
выбрать элемент, называемый опорным.
-
сравнить все остальные элементы с опорным, на основании сравнения разбить множество на три — «меньшие опорного», «равные» и «большие», расположить их в порядке меньшие-равные-большие.
-
повторить рекурсивно для «меньших» и «больших».
Подробно:
-
Выбираем в массиве некоторый элемент, который будем называть опорным элементом. С точки зрения корректности алгоритма выбор опорного элемента безразличен. С точки зрения повышения эффективности алгоритма выбираться должна медиана, но без дополнительных сведений о сортируемых данных её обычно невозможно получить. Известные стратегии: выбирать постоянно один и тот же элемент, например, средний или последний по положению; выбирать элемент со случайно выбранным индексом.
-
Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы, меньшие или равные опорному элементу, оказались слева от него, а все элементы, большие опорного — справа от него. Обычный алгоритм операции:
-
Два индекса — l и r, приравниваются к минимальному и максимальному индексу разделяемого массива соответственно.
-
Вычисляется индекс опорного элемента m.
-
Индекс l последовательно увеличивается до m до тех пор, пока l-й элемент не превысит опорный.
-
Индекс r последовательно уменьшается до m до тех пор, пока r-й элемент не окажется меньше либо равен опорному.
-
Если r = l — найдена середина массива — операция разделения закончена, оба индекса указывают на опорный элемент.
-
Если l < r — найденную пару элементов нужно обменять местами и продолжить операцию разделения с тех значений l и r, которые были достигнуты. Следует учесть, что если какая-либо граница (l или r) дошла до опорного элемента, то при обмене значение m изменяется на r-й или l-й элемент соответственно.
-
-
Рекурсивно упорядочиваем подмассивы, лежащие слева и справа от опорного элемента.
-
Базой рекурсии являются наборы, состоящие из одного или двух элементов. Первый возвращается в исходном виде, во втором, при необходимости, сортировка сводится к перестановке двух элементов. Все такие отрезки уже упорядочены в процессе разделения.